1 概念
- 产生与发展:人工管理阶段 → \to → 文件系统阶段 → \to → 数据库系统阶段。
- 数据库系统特点:数据的管理者(DBMS);数据结构化;数据共享性高,冗余度低,易于扩充;数据独立性高。
- DBMS 对数据的控制功能:数据的安全性保护;数据的完整性检查;并发控制;数据库恢复。
- 数据库技术研究领域:数据库管理系统软件的研发;数据库设计;数据库理论。
- 数据模型要素
- 数据结构:描述数据库的组成对象及对象之间的联系。
- 数据操作:堆数据库中对象(型)的实例(值)允许执行的操作的集合,包括操作及有关的操作规则。
- 数据的约束条件:一组完整性规则。
- 概念模型
- 实体:客观存在并可相互区别的事物。
- 属性:实体所具有的某一特性。
- 码:唯一标识实体的属性集。
- 实体型:用实体名及其属性名集合来抽象和刻画同类实体。
- 实体集:同一类型实体的集合。
- 联系:实体型内部的联系,组成实体的各属性之间的联系;实体型之间的联系,不同实体集之间的联系。
- 1:1:实体集 A 中每个实体在实体集 B 中至多有一个实体与之对应;反之亦然。
- 1:n:实体集 A 中每个实体在实体集 B 中有 n 个实体与之对应;反之至多有一个。
- n:m:实体集 A 中每个实体在实体集 B 中有 n 个实体与之对应;反之有 m 个。
- E-R 图:矩形标识实体;椭圆表示属性;菱形表示实体间联系;连段连接。
- 层次模型
- 概念:有且只有一个结点没有双亲结点 - 根节点;每个结点表示一个记录类型,记录类型间联系为父子间一对多联系;倒立的树,结点的双亲唯一。
- 优点:自然直观容易理解;数据结构简单清晰;查询效率高;提供了良好的完整性支持。
- 缺点:现实世界中很多联系非层次性;不变处理需要具有多个双亲结点的结点;查询子女结点必须经过双亲结点;层次命令趋于程序化。
- 网状模型
- 概念:允许一个以上的结点无双新,一个结点可以有多于一个双亲结点;有向图。
- 优点:能能够更为直接地描述现实世界;拥有良好性能,存取效率高。
- 缺点:结构复杂,不利于最终用户掌握;数据定义和数据操纵复杂,嵌入高级语言中不易使用;访问数据时必须选择合适的存取路径,加重编程负担。
- 关系模型
- 关系(标):对应一张表。
- 元组(行):表中一行。
- 属性(列):表中一列,每个属性有属性名。
- 码(键):表中某个属性组,可以唯一确定一个元组。
- 域(取值范围):具有相同数据类型的值的集合;属性取值范围来自某个域。
- 分量(属性值):元组中的某个属性值。
- 关系模式: R ( U , D , D O M , F ) R(U,D,{\rm DOM},F) R(U,D,DOM,F); R R R 关系名, U U U 属性名集, D D D 属性域, D O M {\rm DOM} DOM 属性向域的映像集, F F F 属性间数据的依赖关系集。
- 基本关系(基本表):实际存储数据的逻辑表示;列是同质的,不同的列可以出自同一个域,列的顺序无所谓;任意两行不能完全相同,行的顺序无所谓;分量必须取原子值。
- 查询表:查询结果对应的表。
- 视图表:由基本表或其他视图导出的虚表,非实际存储的数据。
- 数据操纵:操作对象和操作结构都是关系;存储路径向用户隐蔽。
- 优点:建立在严格的数学概念基础上;概念单一,数据结构简单清晰易懂;存取路径对用户透明,更高的数据独立性、更好的安全保密性、简化编程和开发工作。
- 缺点:存取路径对用户隐蔽;查询效率不如格式化数据库;为提高性能需堆用户查询请求优化,增加开发数据库管理系统难度。
- 关系完整性
- 候选码:能够唯一标识一个元组的最小属性组。
- 主码:候选码中选择一个作为主码。
- 主属性:候选码中的所有属性。
- 非主属性(非码属性):不包含在任何候选码中的属性。
- 全码:关系模式的所有属性都是候选码。
- 外码:关系的非码与参照/目标关系主码相对应。
- 实体完整性:主属性不能为空值(NULL)。
- 参照完整性:外码值必须为空值或参照关系的主码值。
- 用户定义的完整性:具体数据必须满足的语义要求;如值唯一、非空值、取值范围等。
- 数据库模式:三级模式;二级映像。
- 模式:数据库逻辑结构和特征的描述;型的描述;反映数据的结构及联系;相对稳定。
- 实例:模式的一个具体值;反映数据库某一时刻的状态;同个模式可以有多个实例;随数据库中的数据更新而变动。
- 外模式(用户/子模式):数据库用户使用的局部数据的逻辑结构和特征的描述;数据库用户的数据视图,与某一应用有关的数据的逻辑表示;保证数据库安全性(用户只能能看到和访问对应外模式中的数据);保证数据独立性。
- 模式:数据库中全体数据的逻辑结构和特征的描述;所有用户的公共数据视图;数据库的逻辑结构(数据项的名字、类型、取值范围);数据之间的联系;数据有关的安全性、完整性要求。
- 内模式(存储模式):数据物理结构和存储方式的描述,数据在数据库内部的组织方式。
- 外模式/模式映像:应用程序依据外模式编写,模式改变时只需改变映像而无需修改应用程序;保证了数据与程序的逻辑独立性。
- 模式/内模式映像:数据库存储结构改变时,只需改变映像而无需改变模式,从而无需修改应用程序;保证了数据与程序的物理独立性。
- 外部体系结构(最终用户角度)
- 单用户结构:应用程序、DBMS、数据库在同一台机器上,由一个用户独占。
- 主从式结构:应用程序、DBMS、数据库都在主机上,终端仅作为 I/O 设备。
- 分布式结构:数据物理上分布,逻辑上相关联。
- 客户端/服务器结构:DBMS位于服务器上,应用程序在客户端上。
- 管理系统功能与组成
- 数据定义:定义构成数据库结构的模式、存储模式、外模式、各模式间的映射及有关的约束条件。
- 数据操纵;数据库运行管理;数据组织、存储、管理;数据库的建立和维护。
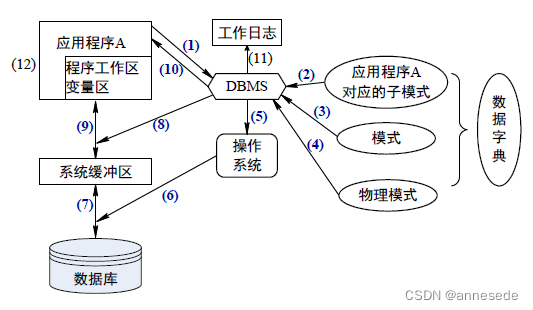
存取数据库数据时协同工作方面:应用程序;DBMS;操作系统;硬件。
- 数据库设计
- 目标:结构(数据)设计 - 设计数据库框架或数据库;行为(处理)设计 - 设计应用程序、事务处理。
- 逻辑数据库:根绝用户要求和特定数据库管理系统的具体特点,以数据库设计理论为依据,设计数据库的全局逻辑结构和每个用户的局部逻辑结构。
- 物理数据库:在逻辑结构确定后,设计数据库的存储结构及其他实现细节。
- 步骤:需求分析 → \to → 概念模型设计 → \to → 逻辑结构设计 → \to → 物理结构设计 → \to → 数据库物理设计 → \to → 数据库实施 → \to → 数据库运行和维护。
- 应用:用户;应用程序员;DBA(数据库管理员);系统分析员;数据库设计人员。
DBA:设计与定义数据库系统;帮助最终用户使用数据库系统;监督与控制数据库系统的使用和运行;改进和重组数据库系统,调整优化数据库系统性能;转储与恢复数据库;重构数据库。
- 非关系型数据库(NoSQL):旨在处理大规模、高并发的数据访问需求;不依赖于固定数据结构,采用了键值对、文档、列族、图形等模型存储和查询数据。
- 国产数据库举例:TiDB;openGuass;OceanBase;达梦;GuassDB;TDSQL;PolarDB;GBase;人大金仓;AnalyticDB;GoldenDB;SequoiaDB;TcaplusDB;EsgymDB。
2 安全
- 计算机系统的三类安全问题:实体;环境;信息。
- 数据库安全
- 非授权用户对数据库的恶意存取和破坏。
- 数据库中重要或敏感的数据被泄露。
- 安全环境的脆弱性。
- TCSES/TDI 安全等级划分:D - 最小保护;C1 - 自主安全保护;C2 - 受控的存取保护;B1 - 标记安全保护;B2 - 结构化保护;B3 - 安全域;A1 - 验证设计。
- 规范化
- 目的:判断好的模式的标准,逐步消除数据依赖中不合适的部分;不会发生插入、删除、更新异常同时减少数据冗余。
- 函数依赖: R ( U ) R(U) R(U) 为属性集 U U U 上关系模式, X , Y ∈ U X,Y\in U X,Y∈U, ∀ r ∈ R ( U ) \forall r\in R(U) ∀r∈R(U), ∀ n , m ∈ R \forall n,m\in R ∀n,m∈R, n X = m X ⟹ n Y = m Y nX=mX\implies nY=mY nX=mX⟹nY=mY;则称 Y Y Y 依赖于 X X X 或 X X X 确定 Y Y Y,记 X → Y X\to Y X→Y。
- 完全依赖: X → Y X\to Y X→Y,但 ∀ X ′ ⊂ X \forall X'\subset X ∀X′⊂X, X ′ ↛ Y X'\not\to Y X′→Y;记 X F → Y X{F \atop \to} Y X→FY。
- 部分依赖: X → Y X\to Y X→Y,但 ∃ X ′ ⊂ X \exists X'\subset X ∃X′⊂X, X ′ → Y X'\to Y X′→Y;记 X P → Y X{P \atop \to} Y X→PY。
- 传递依赖: X → Y X\to Y X→Y, Y ⊄ X Y\not\subset X Y⊂X, Y ↛ X Y\not\to X Y→X, Y → Z Y\to Z Y→Z, Z ⊄ Y Z\not\subset Y Z⊂Y;记 X T → Z X{T \atop \to} Z X→TZ。
- 1NF:属性均为原子属性;存在操纵异常和数据冗余。
- 2NF:1NF,且每个非主属性完全依赖于任何一个候选码;存在删除和插入异常。
- 3NF:1NF,且非主属性既不传递依赖于码,也不部分依赖于码。
- BCNF:1NF,且每个决定因素都包含码。
- 存储过程:一组 SQL 语句集,经编译后存储在数据库。
- 优点:减少网络流量;提高系统性能;安全性高;可重用性;可自动完成需要预先执行的任务。
- 类别:带参数,加密,组;系统,扩展,用户自定义。
- 触发器:用户定义在关系表上的一类由事件驱动特殊的存储过程;事件-条件-动作规则。
- 功能:强化约束;跟踪变化;级联运行;调用存储过程。
- 组成:触发器名;表名;触发事件(INSERT/DELET/UPDATE);触发器类型(ROW/STATEMENT);触发条件;触发动作体。
- DML 触发器:执行 DML 语句;系统将触发器及触发语句作为单个事务,发生错误时整个事务回滚。
- DDL 触发器:响应 DDL 事件激发;用于执行管理任务。
- after:在记录修改后触发,用于变更后处理或检查。
- instead of:一个表只能创建一个;取代原本操作,在记录变更前被触发。
- I 表:inserted;保存 insert 和 update 修改后的数据的虚拟表。
- D 表:deleted;保存 delete 和 update 修改前的数据的虚拟表。
- 并发控制
- 事务(ACID):原子性(一个整体全部提交或全部回滚);一致性(不一致不会保存);隔离性(事务之间相互不可见);持久性(提交后不可撤销)。
- 并发:交叉并发 - 单处理机系统中并行事务的并行操作轮流交叉运行;同时并发 - 多处理机系统同时运行多个事务。
- 正确调度准则:可串行化;一致性的充分非必要条件。
- 数据不一致性:丢失修改(两事务操纵重合);不可重复读(读后另一事务更新/删除/插入后再读);读"脏"数据(读后另一事务回滚后再读)。
- X 锁/排他锁/写锁:只允许本事务读写,其他任何事务不能加任何类型的锁,直到本事务释放。
- S 锁/共享锁/读锁:本事务可以读但不能写,其他任何事务可以加 S 锁但不能加 X 锁,直到本事务释放。
- 一级锁:事务修改数据前加 X 锁,结束时释放;防止丢失修改,保证可回滚。
- 二级锁:一级锁基础上,事务读取数据前加 S 锁,读完后时释放;防止读"脏"数据。
- 三级锁:一级锁基础上,事务读取数据前加 S 锁,结束时释放;防止不可重复读。
- 活锁:封锁请求永远等待;可采用先来先服务策略避免。
- 死锁:两个封锁请求互相永远等待;可采用一次封锁或顺序封锁避免;可采用超时法或等待图法诊断。
- 一次封锁:每个事务一次性将所有要使用的数据全部加锁。
- 顺序封锁:预先对数据对象规定封锁顺序。
- 2PL(两段锁):严格区分为扩展阶段和收缩阶段;扩展阶段只能获得封锁,收缩阶段只能释放封锁;可串行化的充分非必要条件。
- 粒度:粒度越小,封锁对象越小,并发度越高,系统开销越低。
- 多粒度锁:多粒度树;对一个结点加锁意味着所有后代结点均加同样类的锁。
- 显式锁:应事务要求直接加到数据对象上。
- 隐式锁:该独立对象没有被独立加锁,而由于上级结点加锁。
- 意向锁:对结点加意向锁说明下层结点正在被加锁;提高并发度,减少加锁/解锁开销。
- IS 锁:表示后代结点预加 S 锁。
- IX 锁:表示后代结点预加 X 锁。
- SIX 锁:对本结点加 S 锁,表示后代结点预加 X 锁。
- 恢复
- 故障:事务故障;系统故障;介质故障(硬件)。
- 备份/转储:完全(海量);差量;增量;静态;动态。
- 日志:记录事务对数据库更新操作。
- 以记录为单位:事务开始标记;事务更新操作;事务结束标记。
- 以数据块为单位:事务标识;操作类型;操作对象;更新前旧值;更新后新值。
- 作用:事务故障和系统故障恢复;动态转储中恢复;静态转储中可提高恢复效率。
- 原则:登记次序严格按并发事务执行的时间次序;先写日志再写数据库。
- 事务故障恢复:反向扫描日志查找故障事务;对事务更新操作进行逆操作;直到事务开始标记。
- 系统故障恢复:正向扫描日志,所有故障发生前的事务标记记入重做(REDO)队列,故障发生时尚未发成的事务标记记入撤销(UNDO)队列;对撤销队列事务进行撤销;对重做队列事务进行重做。
- 介质故障恢复:装入最新的数据库后备副本(动态转储还需装入转储开始时刻日志副本,利用 UNDO+REDO 恢复一致性);转入日志副本,重做事务。
- 权限控制:基于角色;操作系统用户 > > > 登录用户 > > > 数据库使用用户 > > > 数据库对象使用用户。
- 审计:将用户对数据库所有操作记录;审计员可利用审计日志监控并重现事件,找出非法操作。
- 事件:服务器事件;系统权限;语句事件;模式对象事件。
- 功能:基本功能 - 审计查阅;审计规则;审计分析和报表;审计日志管理;审计查询用的专门视图。
- "三权分立"
- 系统管理员:DDL 权限。
- 安全管理员:授权的权限。
- 审计管理员:配置审计。
3 关系运算
- 关系代数
交: R ∩ S = { t ∣ t ∈ R ∧ t ∈ S } R\cap S=\{t|t\in R\wedge t\in S\} R∩S={t∣t∈R∧t∈S}。
并: R ∪ S = { t ∣ t ∈ R ∨ t ∈ S } R\cup S=\{t|t\in R\vee t\in S\} R∪S={t∣t∈R∨t∈S}。
差: R − S = { t ∣ t ∈ R ∧ t ∉ S } R-S=\{t|t\in R\wedge t\not\in S\} R−S={t∣t∈R∧t∈S}。
选择: σ F ( R ) = { t ∣ t ∈ R ∧ F ( t ) } \sigma_F(R)=\{t|t\in R\wedge F(t)\} σF(R)={t∣t∈R∧F(t)}。
投影: ∏ A ( R ) = { t A ∣ t ∈ R } \prod_A(R)=\{tA|t\in R\} ∏A(R)={tA∣t∈R}。
联结: R ⋈ S θ = { t r t s ⌢ ∣ t r ∈ R ∧ t s ∈ S ∧ θ ( t r A , t s B ) } \mathop{R\Join S}\limits_{\theta}=\{\overset\frown{t_rt_s}|t_r\in R\wedge t_s\in S\wedge \theta(t_rA,t_sB)\} θR⋈S={trts⌢∣tr∈R∧ts∈S∧θ(trA,tsB)}。
等值联结: R ⋈ S = = { t r t s ⌢ ∣ t r ∈ R ∧ t s ∈ S ∧ t r A = t s B } \mathop{R\Join S}\limits_{=}=\{\overset\frown{t_rt_s}|t_r\in R\wedge t_s\in S\wedge t_rA=t_sB\} =R⋈S={trts⌢∣tr∈R∧ts∈S∧trA=tsB}。
自然联结(内联结): R ⋈ S = { t r t s ⌢ U − C ∣ t r ∈ R ∧ t s ∈ S ∧ t r A = t s B } R\Join S=\{\overset\frown{t_rt_s}U-C|t_r\in R\wedge t_s\in S\wedge t_rA=t_sB\} R⋈S={trts⌢U−C∣tr∈R∧ts∈S∧trA=tsB}。
外联结(全联结): R ⋈ ‾ S = { t r t s ⌢ U − C ∣ t r ∈ R ∧ t s ∈ S ∧ ( t r A = t s B ∨ t r A = N U L L ∨ t s B = N U L L ) } = ( R ⋉ S ) ∪ ( R ⋊ S ) R\overline{\Join}S=\{\overset\frown{t_rt_s}U-C|t_r\in R\wedge t_s\in S\wedge (t_rA=t_sB\vee t_rA={\rm NULL}\vee t_sB={\rm NULL})\}=(R{\large\ltimes}S)\cup(R{\large\rtimes}S) R⋈S={trts⌢U−C∣tr∈R∧ts∈S∧(trA=tsB∨trA=NULL∨tsB=NULL)}=(R⋉S)∪(R⋊S)。
左外联结: R ⋉ S = { t r t s ⌢ U − B ∣ t r ∈ R ∧ t s ∈ S ∧ ( t r A = t s B ∨ t s B = N U L L ) } R{\large\ltimes} S=\{\overset\frown{t_rt_s}U-B|t_r\in R\wedge t_s\in S\wedge (t_rA=t_sB\vee t_sB={\rm NULL})\} R⋉S={trts⌢U−B∣tr∈R∧ts∈S∧(trA=tsB∨tsB=NULL)}。
右外联结: R ⋊ S = { t r t s ⌢ U − A ∣ t r ∈ R ∧ t s ∈ S ∧ ( t r A = t s B ∨ t r A = N U L L ) } R{\large\rtimes} S=\{\overset\frown{t_rt_s}U-A|t_r\in R\wedge t_s\in S\wedge (t_rA=t_sB\vee t_rA={\rm NULL})\} R⋊S={trts⌢U−A∣tr∈R∧ts∈S∧(trA=tsB∨trA=NULL)}。
笛卡尔积(交叉联结): R × S = { t r t s ⌢ ∣ t r ∈ R ∧ t s ∈ S } R\times S=\{\overset\frown{t_rt_s}|t_r\in R\wedge t_s\in S\} R×S={trts⌢∣tr∈R∧ts∈S}。
除: R ÷ S = { t r X ∣ t r ∈ R ∧ ∏ Y ( S ) ⊂ Y x } R\div S=\{t_rX|t_r\in R\wedge \prod_Y(S)\subset Y_x\} R÷S={trX∣tr∈R∧∏Y(S)⊂Yx}。 - 元组关系演算: { t ∣ ϕ ( t ) } \{t|\phi(t)\} {t∣ϕ(t)}。
原子公式: R ( t ) R(t) R(t), t i θ c ti\theta c tiθc, t i θ u j ti\theta uj tiθuj。
谓词逻辑: ∧ \wedge ∧, ∨ \vee ∨, ¬ \neg ¬, ∃ \exists ∃, ∀ \forall ∀, ⟹ \implies ⟹。
4 SQL
sql
SELECT <col> AS <tag> FROM <tab> <tag>
JOIN(RIGHT JOIN; LEFT JOIN; CROSS JOIN) <tab> ON <condition>
WHERE <condition> GROUP BY <col> HAVING <condition> ORDER BY <condition>
UNION(INTERSECT; EXCEPT) ...;
UPDATE <tab> SET <col> = <val> WHERE <condition>;
DELETE FROM <tab> WHERE <condition>;
INSERT INTO <tab> VALUES(<val>);
CREATE VIEW <name>(<col>) AS SELECT ...;
DROP VIEW <name>;- 排序:ASC - 升序(默认);DESC - 降序。
- 比较:=;>;<;>=;<=;<>;BETWEEN AND;IS NULL。
- 逻辑:AND;OR;NOT。
- LIKE:% 匹配 0 个或多个字符;_ 匹配一个字符; 匹配一个限定字符;\^ 不匹配一个限定字符;\ ESCAPE '' 转义字符。
- 集函数:COUNT;SUM;AVG;MAX;MIN;ALL - 不去重(默认);DISTINCT - 去重。
- 谓词:IN;ANY;ALL;EXISTS。
5 T-SQL(暂略)
- 存储过程:PROCEDURE;WITH ENCRYPTION;EXEC
- 触发器:TRIGGER
- 约束:RULE;DEFUALT;CONSTRAINT
- 事务:TRANSACTION;READ UNCOMMITED,READ COMMITED,SERIALIZEABLE, SNAPSHOT;COMMIT;ROLLBACK
- 备份恢复:BACKUP;RESTORE
- 权限控制:GRANT;REVOKE
- 审计:AUDIT