第1关:认识 Doc2vec
Doc2vec 算法简介
Doc2vec 又叫做 Paragraph2vec, Sentence embeddings,是一种非监督式算法,可以获得句子、段落、文档的向量表达,是 Word2vec 的拓展。学出来的向量可以通过计算距离来找句子、段落、文档之间的相似性,可以用于文本聚类,对于有标签的数据,还可以用监督学习的方法进行文本分类,例如经典的情感分析问题。
与 Word2vec 一样,Doc2Vec 有两种模型,分别为:Distributed Memory(DM)和 Distributed Bag of Words(DBOW)。DM 模型在给定上下文和文档向量的情况下预测单词的概率,DBOW 模型在给定文档向量的情况下预测文档中一组随机单词的概率。其中,在一个文档的训练过程中,文档向量共享,也就意味着在预测单词的概率时,都利用了整个文档的语义。
Doc2vec 算法模型
1、DM 模型 DM 模型在训练时,首先将每个文档的 ID 和语料库中的所有词初始化一个 K 维的向量,然后将文档向量和上下文词的向量输入模型,隐藏层将这些向量累加(或取均值、或直接拼接起来)得到中间向量,作为输出层 softmax 的输入。在一个文档的训练过程中,文档 ID 保持不变,共享着同一个文档向量,相当于在预测单词的概率时,都利用了整个句子的语义。DM 模型的结构如图1所示。
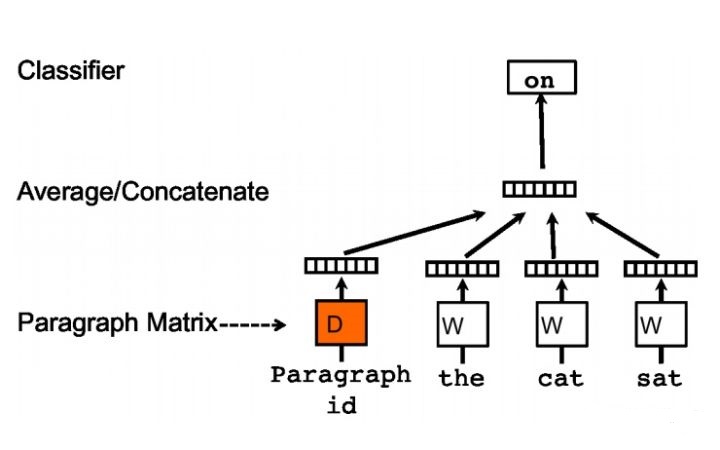
图 1 DM 模型
使用 gensim 实现 DM 模型: model = gensim.models.Doc2Vec(documents,dm = 1, alpha=0.1, size= 20, min_alpha=0.025)
函数的各个参数的具体含义为:
-
sentences 指代供训练的句子,可以使用简单的列表,但是对于大语料库,建议直接从磁盘/网络流迭代传输句子;
-
alpha 代表初始学习率;
-
size 表示向量的维度;
-
min_alpha 表示随着训练的进行,学习率线性下降到 min_alpha。
2、DBOW 模型 DBOW 模型的输入是文档的向量,预测的是该文档中随机抽样的词。这种模型的训练方法是忽略输入的上下文,让模型去预测段落中的随机一个单词,在每次迭代的时候,从文本中采样得到一个窗口,再从这个窗口中随机采样一个单词作为预测任务,让模型去预测,输入就是段落向量。
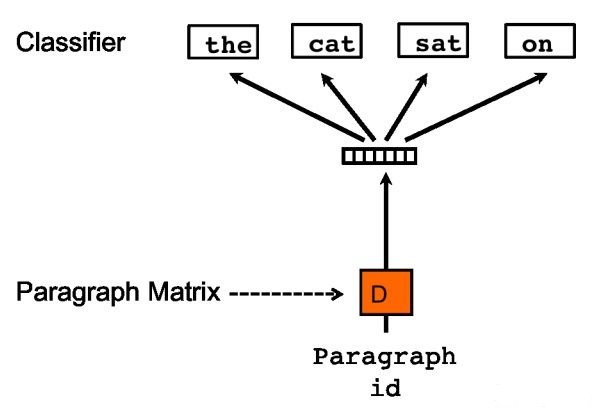
图 2 DBOW 模型
使用 gensim 实现 DBOW 模型: model = gensim.models.Doc2Vec(documents,dm = 0, alpha=0.1, size= 20, min_alpha=0.025)

第2关:Doc2vec 实战
Doc2vec 步骤简介
Doc2Vec 的目的是获得文档的一个固定长度的向量表达。在我们获得 Doc2Vec 模型之前,我们首先需要准备好数据,即多个文档,以及它们的标签(可以用标题作为标签)。
Doc2vec 算法的过程,主要有两步:
-
训练模型:在已知的训练数据中得到词向量 W ,softmax,以及段落向量/句向量;
-
推断过程:对于新的段落,得到其向量表达。在这个阶段中,可以呈现新文档,并且固定所有权重以计算文档向量。
其中,影响模型准确率的因素主要有:语料的大小,文档的数量,越多越高;文档的相似性,越相似越好。
Doc2vec 具体步骤
1、创建 Doc2vec
首先,我们使用 Gensim 的 Doc2Vec 创建一个模型,以备后面的训练。
import gensimLabeledSentence = gensim.models.doc2vec.LabeledSentence
我们需要先把所有文档的路径存进一个 array 中,以便后面读取文档数据。
from os import listdirfrom os.path import isfile, joindocLabels = []docLabels = [f for f in listdir("myDirPath") if f.endswith('.txt')] # 将文件路径存入array
把所有文档的内容存入到 data 中:
data = []for doc in docLabels: # 将数据存入到datadata.append(open("myDirPath/" + doc, 'r')
2、准备数据
如果是用句子集合来训练模型,我们可以:
class LabeledLineSentence(object):def __init__(self, filename):self.filename = filenamedef __iter__(self):for uid, line in enumerate(open(filename)):yield LabeledSentence(words=line.split(), labels=['SENT_%s' % uid])
在 gensim 中模型是以单词为单位训练的,所以不管是句子还是文档都得分解成单词。
3、训练模型,并保存以便使用
it = LabeledLineSentence(data, docLabels)model = gensim.models.Doc2Vec(size=300, window=10, min_count=5, workers=11,alpha=0.025, min_alpha=0.025) # 创建模型model.build_vocab(it)for epoch in range(10):model.train(it)model.alpha -= 0.002 # 降低学习率model.min_alpha = model.alpha # 调整学习率model.train(it)model.save("doc2vec.model") # 保存模型作为后续使用
编程要求
在右侧编辑器中的 Begin-End 之间补充 Python 代码,完成 Doc2vec 的模型训练过程,并保存模型。其中,训练集已由系统给出,文本内容通过 input 从后台获取。
测试说明
平台将使用测试集运行你编写的程序代码,若全部的运行结果正确,则通关。
测试输入: 自己
预期输出: ('可以', 0.999948263168335) Congratulate!
from gensim.models.doc2vec import Doc2Vec,TaggedDocument
import pandas as pd
def D2V():
article = pd.read_excel('data.xlsx') #data为训练集,繁体
sentences = article['内容'].tolist()
split_sentences = []
for i in sentences:
split_sentences.append(i.split(' '))
documents = [TaggedDocument(doc, [i]) for i, doc in enumerate(split_sentences)]
# 任务:基于 gensim 构建 doc2vec 模型并命名为doc2vec_stock进行保存
# ********** Begin *********#
model = Doc2Vec(documents, size=500, window=5, min_count=5, workers=4, epoch=5000)
model.save("doc2vec_stock.model")
# ********** End **********#