要下载m3u8视频文件,首先得找到m3u8地址,按下F12键,看网络-fetch/xhr,然后找网址中包括m3u8的地址,再预览或者看下相应


如果类似类似上面,就说明这是一个M3U8格式的视频流媒体播放列表文件。M3U8是一种基于HTTP Live Streaming (HLS) 技术的播放列表格式,常用于流媒体服务。下面是对这个文件内容的解析:
#EXTM3U: 表示这是一个M3U格式的播放列表文件。
#EXT-X-VERSION:3: 指定M3U8文件的版本。
#EXT-X-PLAYLIST-TYPE:VOD: 表示这是一个点播(Video On Demand)播放列表,意味着内容是预先录制的,可以随时开始播放。
#EXT-X-MEDIA-SEQUENCE:0: 表示第一个媒体文件的序列号是0。
#EXT-X-TARGETDURATION:10: 表示每个媒体文件的最大持续时间为10秒。
#EXTINF:10.000,: 表示每个媒体文件的持续时间为10秒。
后面的每一行都是一个媒体文件的URL,格式为 <filename>.ts,后面跟着一些参数,如签名(sign)、时间戳(t)和用户标识(us)。
#EXT-X-ENDLIST: 表示播放列表结束,没有更多的媒体文件。
这个播放列表包含了从 1420095_2_0.ts 到 1420095_2_105.ts 的媒体文件,每个文件持续10秒,除了最后一个文件 1420095_2_105.ts 持续1.84秒。这些文件可以被用于流媒体播放,客户端会按照顺序请求这些文件来播放视频内容。
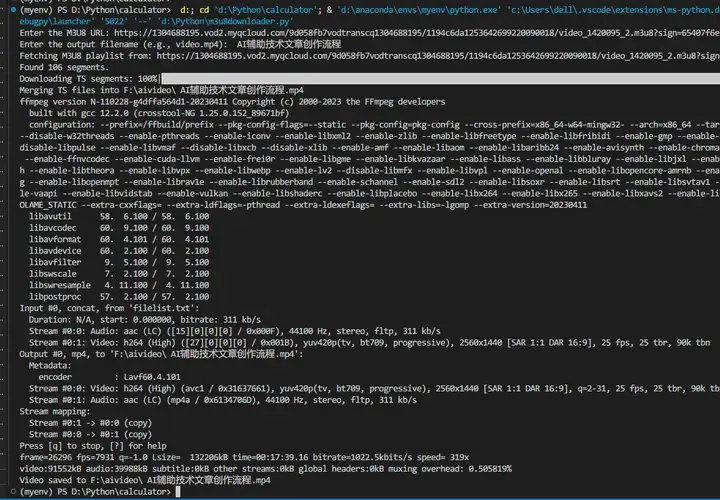
在ChatGPT中输入提示词:
你是一个Python编程专家,写一个m3u8视频下载的Python脚本,具体步骤如下:
用户输入一个m3u8地址,接受到这个输入;
解析m3u8文件并获取其中的ts片段链接,发送网络请求下载这些文件;
将下载好的ts片段按顺序合并成一个完整的视频文件,可以使用ffmpeg进行转码和合并;
合并后的视频文件格式为mp4,保存到文件夹:F:\aivideo
注意:每一步都要输出信息到屏幕上
显示下载进度;
多线程加快下载
M3U8播放列表可能包含没有指定基础URL的相对URL,为了解决这个问题,我们需要手动将M3U8文件的基础URL与每个片段的相对路径结合起来,构建每个.ts片段的完整URL。
合并完成后,删除全部ts文件;
源代码:
import os
import requests
import m3u8
import concurrent.futures
import subprocess
from tqdm import tqdm
from urllib.parse import urljoin
Output folder
output_folder = "F:\\aivideo"
Ensure output folder exists
os.makedirs(output_folder, exist_ok=True)
def download_ts_segment(url, output_path):
"""
Downloads a single .ts segment.
"""
response = requests.get(url, stream=True)
with open(output_path, 'wb') as file:
for chunk in response.iter_content(chunk_size=8192):
file.write(chunk)
return output_path
def merge_ts_files(ts_files, output_file):
"""
Merges .ts files using ffmpeg.
"""
with open("filelist.txt", 'w') as f:
for ts_file in ts_files:
f.write(f"file '{ts_file}'\n")
Merge using ffmpeg
subprocess.run('ffmpeg', '-f', 'concat', '-safe', '0', '-i', 'filelist.txt', '-c', 'copy', output_file)
os.remove("filelist.txt")
def download_and_merge_m3u8(m3u8_url, output_filename):
"""
Downloads and merges M3U8 video segments.
"""
if not output_filename.endswith(('.mp4', '.mkv', '.avi')):
output_filename += ".mp4" # Default to mp4 if no extension provided
print(f"Fetching M3U8 playlist from: {m3u8_url}")
response = requests.get(m3u8_url)
playlist = m3u8.loads(response.text)
base_uri = m3u8_url.rsplit('/', 1)0 + '/'
ts_urls = urljoin(base_uri, segment.uri) for segment in playlist.segments
print(f"Found {len(ts_urls)} segments.")
Download TS segments with progress bar
ts_files = \[\]
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
future_to_url = {executor.submit(download_ts_segment, url, os.path.join(output_folder, f"{i}.ts")): url for i, url in enumerate(ts_urls)}
for future in tqdm(concurrent.futures.as_completed(future_to_url), total=len(ts_urls), desc="Downloading TS segments"):
ts_file = future.result()
ts_files.append(ts_file)
Sort files to ensure correct order
ts_files.sort(key=lambda x: int(os.path.basename(x).split('.')0))
Merge TS files
output_path = os.path.join(output_folder, output_filename)
print(f"Merging TS files into {output_path}")
merge_ts_files(ts_files, output_path)
print(f"Video saved to {output_path}")
if name == "main":
m3u8_url = input("Enter the M3U8 URL: ")
output_filename = input("Enter the output filename (e.g., video.mp4): ")
download_and_merge_m3u8(m3u8_url, output_filename)