零基础学 Python 爬虫:从原理到反爬,构建企业级爬虫系统

🌸你好呀!我是 lbb小魔仙
🌟 感谢陪伴~ 小白博主在线求友
🌿 跟着小白学Linux/Java/Python
📖 专栏汇总:
《Linux》专栏 | 《Java》专栏 | 《Python》专栏

- [零基础学 Python 爬虫:从原理到反爬,构建企业级爬虫系统](#零基础学 Python 爬虫:从原理到反爬,构建企业级爬虫系统)
- 一、爬虫基本原理:网页数据的"采集逻辑"
-
- [1.1 HTTP 请求:与网页服务器的"对话"](#1.1 HTTP 请求:与网页服务器的“对话”)
- [1.2 HTML 解析:从"杂乱代码"中找规律](#1.2 HTML 解析:从“杂乱代码”中找规律)
- [1.3 数据提取:获取目标信息并存储](#1.3 数据提取:获取目标信息并存储)
- [1.4 爬虫整体流程(流程图)](#1.4 爬虫整体流程(流程图))
- [二、实战:用 requests + BeautifulSoup 实现简单爬虫](#二、实战:用 requests + BeautifulSoup 实现简单爬虫)
-
- [2.1 环境准备](#2.1 环境准备)
- [2.2 完整爬虫代码(可直接运行)](#2.2 完整爬虫代码(可直接运行))
- [2.3 代码核心知识点解析](#2.3 代码核心知识点解析)
- 三、常见反爬机制及应对策略
-
- [3.1 三大常见反爬机制与应对](#3.1 三大常见反爬机制与应对)
- [3.2 反爬应对逻辑(流程图)](#3.2 反爬应对逻辑(流程图))
- 四、提升爬虫鲁棒性:代理池、请求头轮换与延时控制
-
- [4.1 代理池搭建与使用](#4.1 代理池搭建与使用)
-
- [4.1.1 代理 IP 分类](#4.1.1 代理 IP 分类)
- [4.1.2 代理池简单实现(代码示例)](#4.1.2 代理池简单实现(代码示例))
- [4.2 请求头轮换](#4.2 请求头轮换)
- [4.3 延时控制与请求频率限制](#4.3 延时控制与请求频率限制)
- 五、企业级爬虫系统架构思路
-
- [5.1 核心架构模块(流程图)](#5.1 核心架构模块(流程图))
- [5.2 各模块核心功能](#5.2 各模块核心功能)
-
- [5.2.1 任务调度模块](#5.2.1 任务调度模块)
- [5.2.2 分布式采集模块](#5.2.2 分布式采集模块)
- [5.2.3 数据预处理模块](#5.2.3 数据预处理模块)
- [5.2.4 数据存储模块](#5.2.4 数据存储模块)
- [5.2.5 日志与监控模块](#5.2.5 日志与监控模块)
- 六、零基础学习路径建议
- 七、注意事项:合法爬虫的边界
对于零基础编程学习者而言,Python 爬虫是入门编程的优质路径------它能快速带来"看得见的成果"(爬取数据),同时覆盖网络原理、数据处理、工程化思维等核心能力。本文将从底层原理讲起,逐步带领大家实现实战案例,突破反爬限制,最终触达企业级爬虫系统的构建思路,全程通俗易懂且兼顾实战深度。
一、爬虫基本原理:网页数据的"采集逻辑"
爬虫本质是"模拟浏览器行为,自动化获取网页数据并处理"的程序,核心流程可拆解为三大步骤:发送 HTTP 请求、解析 HTML 页面、提取目标数据。我们先搞懂每个环节的核心逻辑,再动手实践。
1.1 HTTP 请求:与网页服务器的"对话"
当你在浏览器输入网址并回车时,浏览器会向目标网站的服务器发送一个 HTTP 请求 (类似"我要获取这个页面的内容"的指令),服务器处理后返回 HTTP 响应(包含页面 HTML 代码、图片、视频等资源)。
HTTP 请求核心要素:
-
请求方法:最常用 GET(获取资源)和 POST(提交数据,如登录),爬虫初期以 GET 为主。
-
请求头:包含浏览器信息、Cookie、请求来源等,是服务器识别"请求者身份"的关键,也是反爬对抗的核心战场。
-
响应状态码:200 表示请求成功,403 表示拒绝访问(反爬触发),404 表示页面不存在,500 表示服务器错误。
1.2 HTML 解析:从"杂乱代码"中找规律
服务器返回的核心资源是 HTML 代码,它是一种标记语言,通过标签(如
、 、
)组织页面内容。爬虫需要从这些标签中"筛选"出有用数据,这就需要 HTML 解析工具。
举个简单 HTML 示例:
html
<div class="news-list">
<h3 class="news-title">Python 爬虫入门教程</h3>
<p class="news-time">2026-01-08</p>
<a href="https://example.com/news/1">查看详情</a>
</div>我们可通过"标签名+类名"定位到标题(Python 爬虫入门教程)、时间(2026-01-08)等目标数据。
1.3 数据提取:获取目标信息并存储
解析 HTML 后,提取目标数据(文本、链接、图片地址等),再根据需求存储为 TXT、CSV、数据库等格式,完成一次爬虫闭环。
1.4 爬虫整体流程(流程图)
否
是
是
否
确定目标网站与数据
发送 HTTP 请求获取响应
响应是否成功?
排查问题(反爬/链接错误)
解析 HTML 页面
提取目标数据
数据清洗与存储
是否需要多页爬取?
构造下一页请求链接
爬虫结束
二、实战:用 requests + BeautifulSoup 实现简单爬虫
掌握原理后,我们用 Python 最常用的两个库实现一个完整爬虫------爬取某静态新闻列表页的标题、时间和链接。这两个库轻量易上手,是零基础入门的首选。
2.1 环境准备
首先安装所需库,打开命令行输入以下命令:
bash
pip install requests beautifulsoup4-
requests:发送 HTTP 请求的工具,替代浏览器完成"对话"操作。
-
BeautifulSoup4:HTML 解析库,帮助我们快速定位和提取数据。
2.2 完整爬虫代码(可直接运行)
以爬取"中国科普网"新闻列表页为例(静态页面,适合入门),代码附带详细注释:
python
import requests
from bs4 import BeautifulSoup
import csv
# 1. 定义目标网址和请求头
url = "https://www.kepu.gov.cn/www/category/column10/index.shtml"
headers = {
# User-Agent 伪装成浏览器,避免被直接识别为爬虫
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
# 2. 发送 GET 请求获取响应
response = requests.get(url, headers=headers)
# 设置编码格式,避免中文乱码
response.encoding = "utf-8"
# 3. 解析 HTML 页面
soup = BeautifulSoup(response.text, "html.parser") # html.parser 是内置解析器
# 4. 提取目标数据:定位新闻列表容器
news_list = soup.find("div", class_="column_list") # 根据 div 标签和 class 定位
items = news_list.find_all("li") # 找到所有 li 标签(单个新闻项)
# 5. 存储数据到 CSV 文件
with open("kepu_news.csv", "w", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
# 写入表头
writer.writerow(["新闻标题", "发布时间", "详情链接"])
# 遍历每个新闻项提取数据
for item in items:
# 提取标题(text.strip() 去除空格和换行)
title = item.find("a").text.strip()
# 提取发布时间
time = item.find("span").text.strip()
# 提取详情链接(get("href") 获取标签属性值)
link = item.find("a").get("href")
# 补全完整链接(网站返回的可能是相对路径)
full_link = "https://www.kepu.gov.cn" + link if link.startswith("/") else link
# 写入数据
writer.writerow([title, time, full_link])
print("爬虫执行完成,数据已保存到 kepu_news.csv")2.3 代码核心知识点解析
-
请求头伪装:通过 User-Agent 告诉服务器"我是浏览器",而非爬虫,这是最基础的反反爬手段。
-
BeautifulSoup 方法:
-
find():查找第一个符合条件的标签(参数为标签名、class、id 等)。
-
find_all():查找所有符合条件的标签,返回列表。
-
text:获取标签内的文本内容。
-
get():获取标签的属性值(如 href、src)。
-
-
相对路径补全:部分网站返回的链接是相对路径(如 /www/news/1),需拼接域名得到完整链接才能访问。
三、常见反爬机制及应对策略
当爬虫频繁访问网站时,服务器会通过各种手段识别并限制访问,这就是反爬机制。我们需针对性采取应对策略,让爬虫更"隐蔽"。
3.1 三大常见反爬机制与应对
| 反爬机制 | 识别原理 | 应对策略 |
|---|---|---|
| User-Agent 检测 | 服务器检查请求头中的 User-Agent,拒绝非浏览器请求 | 1. 准备 User-Agent 列表,每次请求随机切换;2. 完整模拟浏览器请求头(添加 Cookie、Referer 等) |
| IP 封禁 | 同一 IP 频繁请求,服务器限制该 IP 访问 | 1. 使用代理 IP 池,每次请求切换 IP;2. 控制请求频率(添加延时);3. 分布式爬取(多 IP 并发) |
| 验证码(图形/滑块) | 检测到异常请求时,弹出验证码,需验证后才能继续访问 | 1. 简单图形验证码:使用 OCR 工具(如 pytesseract)识别;2. 复杂滑块验证码:使用自动化工具(如 Selenium)模拟滑动;3. 对接第三方打码平台 |
3.2 反爬应对逻辑(流程图)
否
是
User-Agent 检测
IP 封禁
验证码
发送请求
是否被反爬?
正常解析数据
反爬类型?
切换 User-Agent 重新请求
切换代理 IP 重新请求
验证码识别/人工验证
四、提升爬虫鲁棒性:代理池、请求头轮换与延时控制
鲁棒性指爬虫应对异常情况(反爬、网络波动)的能力。通过以下技术,可让爬虫更稳定、更难被识别。
4.1 代理池搭建与使用
代理 IP 相当于"中间桥梁",爬虫通过代理 IP 向服务器发送请求,服务器只能看到代理 IP,而非真实 IP,避免真实 IP 被封禁。
4.1.1 代理 IP 分类
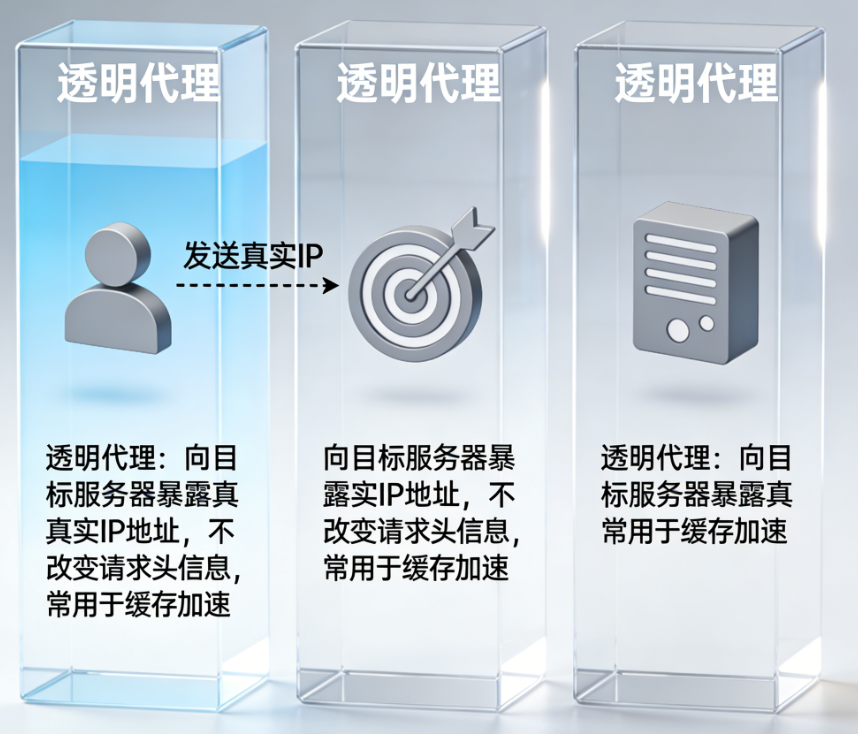
-
透明代理:服务器能识别真实 IP 和代理 IP,反爬效果差。
-
匿名代理:服务器无法识别真实 IP,只能看到代理 IP,常用。
-
高匿代理 :服务器无法识别真实 IP,也无法判断是代理请求,反爬效果最好(企业级爬虫首选)。
4.1.2 代理池简单实现(代码示例)
将代理 IP 放入列表,每次请求随机选择一个:
python
import requests
import random
# 代理 IP 列表(实际使用时需替换为有效代理,可从第三方平台获取)
proxies_list = [
{"http": "http://123.45.67.89:8080", "https": "https://123.45.67.89:8080"},
{"http": "http://98.76.54.32:8888", "https": "https://98.76.54.32:8888"},
{"http": "http://111.222.333.444:9090", "https": "https://111.222.333.444:9090"}
]
# User-Agent 列表
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 14_0) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.0 Safari/605.1.15",
"Mozilla/5.0 (Linux; Android 13; SM-G998B) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Mobile Safari/537.36"
]
def get_html(url):
try:
# 随机选择代理 IP 和 User-Agent
proxy = random.choice(proxies_list)
headers = {"User-Agent": random.choice(user_agents)}
# 发送请求(添加 timeout 防止请求卡死)
response = requests.get(url, headers=headers, proxies=proxy, timeout=10)
response.raise_for_status() # 若状态码非 200,抛出异常
response.encoding = "utf-8"
return response.text
except Exception as e:
print(f"请求失败:{e},更换代理重试")
# 递归重试(限制重试次数,避免死循环)
return get_html(url) if retry_count < 3 else None
# 调用函数
html = get_html("https://www.kepu.gov.cn/www/category/column10/index.shtml")注:实际生产环境中,代理池需动态维护(检测代理有效性、定时更新),可借助 Redis 存储代理 IP。
4.2 请求头轮换
仅伪装 User-Agent 不够,可模拟浏览器完整请求头,包含 Cookie、Referer、Accept 等字段,且每次请求随机组合:
python
def get_random_headers():
headers_list = [
{
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Referer": "https://www.baidu.com/", # 模拟从百度跳转过来
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Cookie": "xxx=xxx; yyy=yyy" # 可从浏览器复制真实 Cookie(注意时效性)
},
# 更多请求头组合...
]
return random.choice(headers_list)4.3 延时控制与请求频率限制
频繁请求是被识别为爬虫的重要特征,通过添加随机延时,模拟人类浏览速度:
python
import time
import random
# 遍历多页爬取时,添加随机延时
for page in range(1, 11):
url = f"https://www.kepu.gov.cn/www/category/column10/index_{page}.shtml"
html = get_html(url)
# 处理数据...
# 随机延时 1-3 秒(避免固定延时被识别)
time.sleep(random.uniform(1, 3))五、企业级爬虫系统架构思路
个人爬虫仅需满足单任务需求,而企业级爬虫需应对高并发、大规模数据采集、稳定性保障等问题,核心架构包含以下模块。
5.1 核心架构模块(流程图)
分配任务
采集数据
清洗/去重
监控状态
异常报警
异常数据
重新分配
任务调度模块
分布式采集模块
数据预处理模块
数据存储模块
日志与监控模块
重试队列
5.2 各模块核心功能
5.2.1 任务调度模块
核心是"合理分配爬取任务",避免重复爬取和任务堆积。常用工具:Celery(分布式任务队列)、Airflow(定时任务调度)。
功能:1. 维护待爬 URL 队列,按优先级分配任务;2. 定时触发爬虫(如每日凌晨爬取更新数据);3. 处理失败任务重试。
5.2.2 分布式采集模块
单台机器算力和 IP 有限,通过多机器、多进程并发采集提升效率。常用工具:Scrapy-Redis(基于 Scrapy 框架的分布式扩展)。
核心:通过 Redis 共享待爬队列和已爬集合,多台爬虫机器同时从队列获取任务,避免重复工作。
5.2.3 数据预处理模块
采集到的数据可能存在重复、乱码、无效值等问题,需预处理后再存储:
-
数据去重:用 Redis 集合存储已爬 URL 或数据指纹,避免重复采集。
-
数据清洗:去除 HTML 标签、空格、特殊字符,标准化数据格式(如时间、数值)。
5.2.4 数据存储模块
根据数据类型选择合适的存储方案,兼顾查询效率和扩展性:
-
关系型数据库:MySQL、PostgreSQL,适合结构化数据(如新闻标题、时间、作者)。
-
非关系型数据库:MongoDB,适合非结构化/半结构化数据(如完整 HTML 页面、评论内容)。
-
缓存数据库:Redis,存储待爬队列、已爬集合、热点数据,提升访问速度。
5.2.5 日志与监控模块
企业级爬虫需实时监控运行状态,及时排查问题:
-
日志记录:用 logging 模块记录请求状态、错误信息、爬取进度,便于问题回溯。
-
状态监控:监控爬虫进程存活、IP 有效性、请求成功率,异常时触发邮件/短信报警。
六、零基础学习路径建议
-
夯实 Python 基础:掌握列表、字典、函数、异常处理等核心语法,无需深入高级特性。
-
吃透爬虫原理:理解 HTTP 请求/响应、HTML 结构,这是应对复杂反爬和系统设计的核心。
-
从简单实战入手:先用 requests + BeautifulSoup 爬取静态页面,再尝试 Scrapy 框架(高效爬虫框架)。
-
突破反爬难关:针对性练习代理池、验证码识别、动态页面爬取(Selenium)。
-
进阶企业级能力:学习分布式、任务调度、数据库优化,理解架构设计思路。
七、注意事项:合法爬虫的边界
爬虫虽强大,但需遵守法律法规和网站规则,避免侵权:
-
查看网站 robots.txt 协议(如 https://www.baidu.com/robots.txt),遵守禁止爬取的内容。
-
控制请求频率,不影响网站正常运行,避免构成"网络骚扰"。
-
不得爬取涉密、隐私、 copyrighted 内容,禁止将爬取数据用于商业侵权行为。
结语:Python 爬虫是"技术+思维"的结合,零基础学习者无需畏惧,从简单案例起步,逐步攻克反爬和架构难题,就能实现从"爬取数据"到"构建系统"的跨越。坚持实战,你会发现爬虫不仅是工具,更是理解网络世界的一把钥匙。
📕个人领域 :Linux/C++/java/AI
🚀 个人主页 :有点流鼻涕 · CSDN
💬 座右铭 : "向光而行,沐光而生。"
