目录
[4.1 BEV-LaneDet](#4.1 BEV-LaneDet)
[4.2 BEVFormer v2](#4.2 BEVFormer v2)
一、多传感器融合技术概述
为什么需要多传感器融合?
- 自动驾驶需要:传感器 + 智能算法,算法能力的提升较难,传感器上做些增强是可行的
- 单一传感器测量结果不够全面,不够精准,适用场景不够广,智能算法还不够智能
- 多个传感器相互配合共同构成汽⻋的感知系统。不同传感器的优势各不相同,主要解决不同的问题
二、基于传统方法的多传感器融合
- 基于规则和模型:传统的传感器融合方法通常基于预定义的规则和物理模型。它们利用几何关系和统计方法来融合来自不同传感器的数据。例如,卡尔曼滤波和粒子滤波在融合多传感器数据(如雷达和摄像机)方面非常常见。
- 特征手工设计:传统方法依赖于手工设计的特征提取和匹配算法。这些特征提取过程需要专家知识,并且对于复杂场景可能表现不佳。
三、基于深度学习的视觉和LiDAR的目标级融合
定义:
目标级融合方法是在各自传感器数据已经处理并生成高层次目标检测结果后进行的融合。这意味着,视觉和LiDAR数据各自独立进行目标检测,然后将检测结果进行融合。
流程:
- 独立检测:使用深度学习模型分别处理视觉数据(如摄像机图像)和LiDAR数据,生成目标检测结果(例如物体的类别和位置)。
- 结果融合:将来自视觉和LiDAR的检测结果进行融合。这通常涉及匹配和整合两个传感器的检测结果,如通过最近邻匹配或IoU阈值进行匹配,然后综合这些结果以获得最终的检测结果。
优点:
- 模块化处理:可以分别优化视觉和LiDAR的检测模型。
- 简单高效:融合过程较为简单,因为只需处理少量的检测结果。
缺点:
- 信息利用不充分:无法在早期阶段结合两个传感器的数据,可能会错过一些有用的信息。
- 精度有限:独立处理可能导致一些目标在一个传感器上检测到而另一个传感器未能检测到,从而影响最终融合结果的准确性。
四、基于深度学习的视觉和LiDAR数据的前融合方法
概念介绍
定义:
前融合方法是在对各自传感器数据进行目标检测之前,将视觉和LiDAR数据在特征提取阶段就进行融合。这样可以在早期阶段就结合两个传感器的数据,利用多模态数据的互补性来提高检测性能。
流程:
- 数据预处理:将视觉数据和LiDAR数据进行同步和配准(对齐),使它们在空间和时间上对应。
- 特征提取与融合:使用深度学习模型提取和融合来自视觉和LiDAR的特征。可以通过多模态神经网络同时处理这两种数据,生成联合特征表示。
- 目标检测:基于融合后的特征进行目标检测,生成最终的检测结果。
优点:
- 信息最大化利用:在早期阶段结合多模态数据,能够更全面地利用来自视觉和LiDAR的信息,提高检测性能。
- 更高的检测精度:通过联合特征表示,模型能够更好地理解场景中的目标,从而提高检测精度。
缺点:
- 计算复杂度高:需要更多的计算资源,因为必须同时处理和融合两个传感器的数据。
- 模型复杂度高:设计和训练多模态融合网络更加复杂。
同步和配准
时间同步
时间同步是指对来自不同传感器的数据进行时间对齐,使它们的时间戳在同一时间参考系下同步。
标定
标定是空间同步的前提。通过标定确定各传感器的内参和外参后,可以实现空间同步,确定各传感器相对于一个公共参考系的位置和方向的过程。标定通常包括内参标定(传感器自身参数)和外参标定(传感器之间的相对位置和方向)。
摄像机内参标定(使用OpenCV)
- 摄像机内参标定:使用棋盘格或其他标定板,拍摄多张图像,利用标定算法(如OpenCV中的张正友标定法)计算摄像机的内参矩阵和畸变系数。
- LiDAR内参标定:LiDAR通常不需要复杂的内参标定,但需要确保LiDAR的安装角度和扫描范围正确。
python
import cv2
import numpy as np
# 读取标定图像
images = [cv2.imread(image_path) for image_path in image_paths]
# 设置棋盘格大小
pattern_size = (9, 6)
obj_points = []
img_points = []
# 准备棋盘格的世界坐标系下的点
objp = np.zeros((np.prod(pattern_size), 3), np.float32)
objp[:, :2] = np.mgrid[0:pattern_size[0], 0:pattern_size[1]].T.reshape(-1, 2)
# 提取角点
for img in images:
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, corners = cv2.findChessboardCorners(gray, pattern_size)
if ret:
img_points.append(corners)
obj_points.append(objp)
# 进行标定
ret, camera_matrix, dist_coeffs, rvecs, tvecs = cv2.calibrateCamera(obj_points, img_points, gray.shape[::-1], None, None)
print("相机内参矩阵:", camera_matrix)
print("畸变系数:", dist_coeffs)摄像机与LiDAR外参标定
- 使用ROS采集数据。
- 使用PCL库处理LiDAR点云数据。
- 通过ICP算法配准特征点。
cpp
#include <pcl/point_cloud.h>
#include <pcl/io/pcd_io.h>
#include <pcl/registration/icp.h>
pcl::PointCloud<pcl::PointXYZ>::Ptr cloud_source (new pcl::PointCloud<pcl::PointXYZ>);
pcl::PointCloud<pcl::PointXYZ>::Ptr cloud_target (new pcl::PointCloud<pcl::PointXYZ>);
// 加载点云数据
pcl::io::loadPCDFile ("source.pcd", *cloud_source);
pcl::io::loadPCDFile ("target.pcd", *cloud_target);
// ICP配准
pcl::IterativeClosestPoint<pcl::PointXYZ, pcl::PointXYZ> icp;
icp.setInputSource(cloud_source);
icp.setInputTarget(cloud_target);
pcl::PointCloud<pcl::PointXYZ> Final;
icp.align(Final);
std::cout << "Has converged: " << icp.hasConverged() << " score: " <<
icp.getFitnessScore() << std::endl;
std::cout << "变换矩阵:\n" << icp.getFinalTransformation() << std::endl;空间同步
空间同步是指将不同传感器的数据转换到同一坐标系下,使它们在空间上对齐。
具体应用
BEV(Bird's-Eye View,鸟瞰视角)技术属于基于深度学习的前融合(Early Fusion)方法。具体来说,BEV方法在对各自传感器数据进行目标检测之前,将视觉(摄像机)和LiDAR数据在特征提取阶段就进行融合。
4.1 BEV-LaneDet
a Simple and Effective 3D Lane Detection Baseline
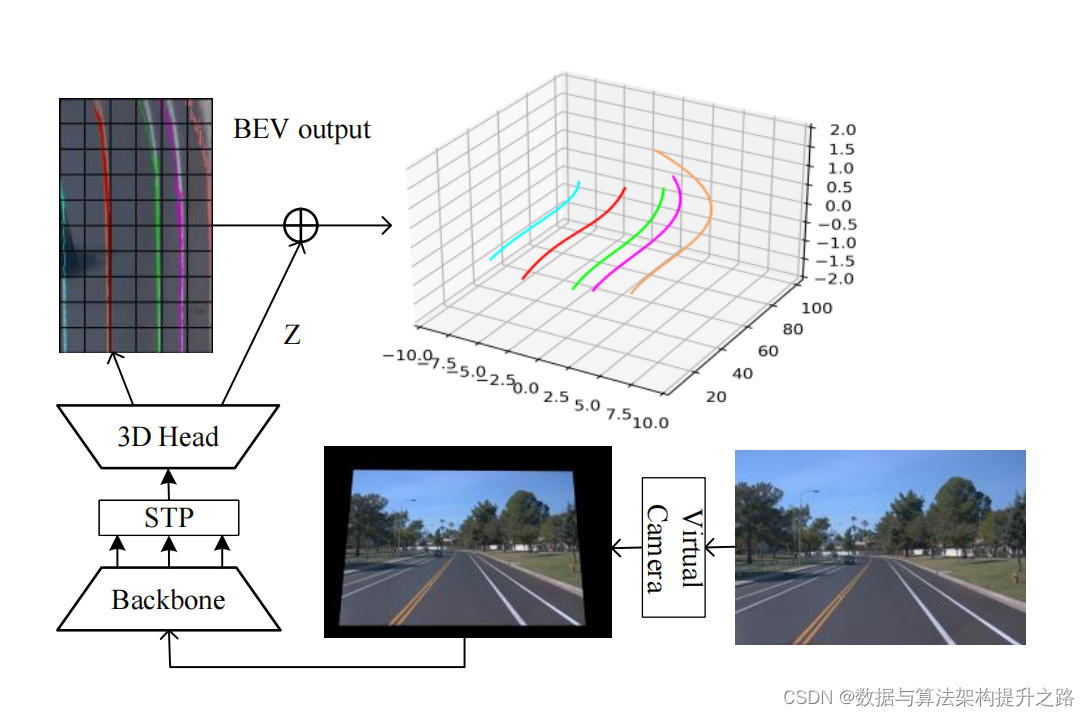
这篇文章的主要观点是介绍了一种名为Bev-lanedet的高效且强大的单目3D车道检测方法。这种方法主要包括三个创新点:
- 虚拟摄像机模块:该模块通过统一不同车辆摄像机的内外参数,确保了摄像机之间空间关系的一致性,从而促进了学习过程。
- 关键点表示:提出了一种简单但高效的3D车道表示方式,更适合表示复杂多样的3D车道结构。
- 空间变换金字塔模块:这是一个轻量级且易于部署的模块,用于将多尺度前视特征转换为鸟瞰视角(BEV)特征。
实验结果表明,Bev-lanedet在F-score方面优于最先进的方法,在OpenLane数据集上高出10.6%,在Apollo 3D合成数据集上高出5.9%,且检测速度达到185 FPS。文章还强调了该方法的实时性和计算效率,适合在自动驾驶中进行部署。
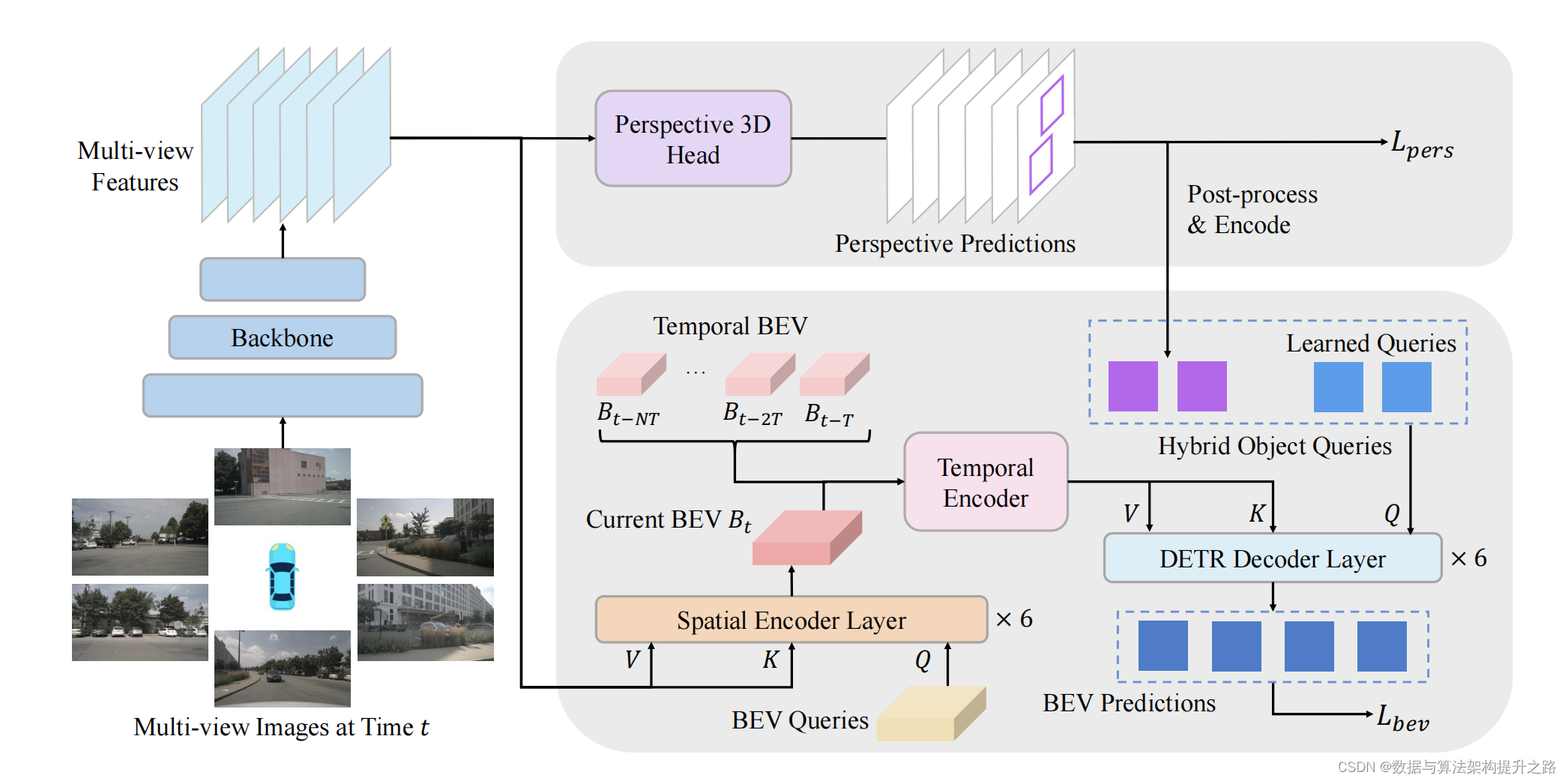
4.2 BEVFormer v2
Adapting Modern Image Backbones to Bird's-Eye-View Recognition via Perspective Supervision
-
鸟瞰视角(BEV)检测器的优化:论文介绍了一种新的鸟瞰视角(BEV)检测器,称为BEVFormer v2,通过引入透视监督来更好地适应现代图像骨干网络。这种方法旨在克服现有BEV检测器在优化过程中遇到的问题,并实现更快的收敛。
-
透视监督的引入:论文提出了通过透视监督(perspective supervision)来指导图像骨干网络学习3D知识,从而克服BEV检测器的复杂结构问题。这种监督方式直接应用于骨干网络,帮助其适应3D场景。
-
两阶段BEV检测器:论文提出了一种两阶段的BEV检测器BEVFormer v2。第一阶段的透视检测头生成物体提案,这些提案被编码为对象查询,然后与第二阶段的BEV检测头的学习对象查询结合,进行最终预测。
-
实验验证与性能提升:通过在nuScenes数据集上的广泛实验,验证了提出方法的有效性。结果表明,使用透视监督的BEVFormer v2在检测性能和模型收敛速度方面都有显著提升。