ruby 基础
1、each、map、collect的区别
each: 仅遍历数组,并做相应操作,数组本身不发生改变。
map:遍历数组,并做相应操作后,返回新数组(处理),原数组不变。
collect: 跟map作用一样。
collect! map!: 多了一个作用,改变原数组。
ruby
// 终端打开 irb
// each
a = [ "a", "b", "c", "d" ]
b = a.each { |x| x + "!" } // a == b == [ "a", "b", "c", "d" ]
// map map!
a = [ "a", "b", "c", "d" ]
b = a.map { |x| x + "!" }
a // ["a", "b", "c", "d"]
b // ["a!", "b!", "c!", "d!"]
c = a.map! { |x| x + "!" }
a // ["a!", "b!", "c!", "d!"]
c // ["a!", "b!", "c!", "d!"]
// collect collect!
a = [ "a", "b", "c", "d" ]
b = a.collect { |x| x + "!" }
a // ["a", "b", "c", "d"]
b // ["a!", "b!", "c!", "d!"]
c = a.collect! { |x| x + "!" }
a // ["a!", "b!", "c!", "d!"]
c // ["a!", "b!", "c!", "d!"]2、Block, lambda, Proc 的区别
-
proc和lambda都是对象,而block不是
-
block是proc的实例,proc可以重复使用,函数参数只能有一个block,但可以有多个proc
ruby# 说明block是proc的一个实例 def what_am_i(&block) block.class end puts what_am_i {} # =< Proc def multiple_procs(proc1, proc2) proc1.call proc2.call end a = Proc.new { puts "First proc" } b = Proc.new { puts "Second proc" } multiple_procs(a,b) -
lambda会检查参数个数,proc不会。
rubylam = lambda { |x| puts x } # creates a lambda that takes 1 argument lam.call(2) # prints out 2 lam.call # ArgumentError: wrong number of arguments lam.call(1,2,3) pro = Proc.new { |x| puts x } # creates a proc that takes 1 argument pro.call(2) # 2 pro.call # returns nil pro.call(1,2,3) # 1 -
lambda和proc对于return处理方式不同
lambda:一个函数调用lambda,lambda里return后返回函数接着执行。
proc: 一个函数调用proc,proc里return后, 函数也会return。
rubydef lambda_test lam = lambda { return } lam.call puts "Hello world" end lambda_test def proc_test proc = Proc.new { return } proc.call puts "Hello world" end proc_test
参考资料:
What Is the Difference Between a Block, a Proc, and a Lambda in Ruby?
浅谈Ruby中的block, proc, lambda, method object的区别
ruby中闭包
在Ruby里,如果该方法返回一个代码块,而该代码块获得了局部变量的引用,则这些局部变量将在方法返回后依然可以访问。
def show(name)
count = 1;
return proc do |value|
puts count +=1;
puts name + '我是闭包' + value
end
end
sh = show("ruby")
sh.call('213')
sh.call('kkk')参考:
Ruby的4种闭包:blocks, Procs, lambdas 和 Methods
3、alias 的用法, alias 与 alias_method 的区别
alias: 给已经存在的方法或变量设置一个别名,在重新定义已存在的方法时,还可以通过别名来调用原来的方法。
alias_method: 和alias类似,但只能给方法起别名,是Module的一个私有实例方法。
ruby
class Demo
def hello
puts "old_hell0"
end
# 给hello方法取别名
# alias old_hello hello
alias_method :old_hello, :hello
def hello
puts "new_hello"
end
end
obj = Demo.new
obj.hello
obj.old_hello参考:
https://www.cnblogs.com/smallbottle/p/3968704.html
https://ruby-china.org/topics/27747
4、Ruby的对象体系
+------------+
| BasicObject|
+------------+
^
|superclass
|
+----+-----+ superclass-----------+
| Object | ^----------| Module |
+----+-----+------+ +-+---------+
^ | ^
|superclass | |Superclass
| | |
+---------+ +-+-------+ +---> +-+-------+
| 'hello' | class | String | class | Class |
| +---------->+ +--------->+ +------>
+---------+ +---------+ +----+----+ |
^ |
| class |
<-----------+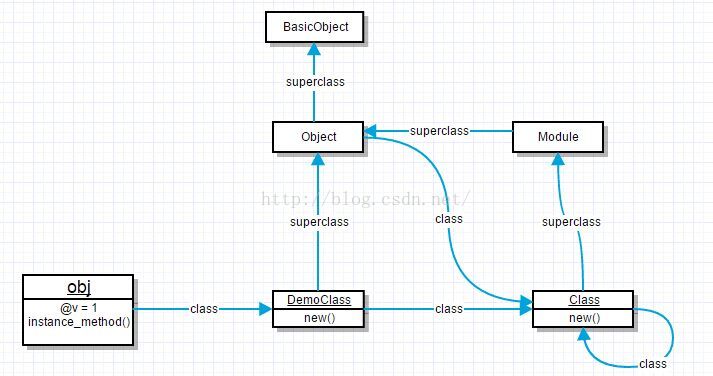
ruby
'hello'.class # String
String.class # Class
String.superclass # Object
Class.class # Class
Class.superclass # Module
Module.class # Class
Module.superclass # Object
Object.class # Object
Object.superclass # BasicObject
BasicObject.class # Class
BasicObject.superclass # nilModule是Class的父类,Class和Module的差别是Class是一个增强的Module,它比Module多了一个new,allocate方法,除了这一个区别,当然这个区别特别重要,Class和Module基本是一样的。
参考: https://blog.csdn.net/feigeswjtu/article/details/51040006
5、 Include, Extend, Load, Require 的使用区别
- include和extend用于在类中引入模块,区别:
include:把模块中的方法作为类的实例方法
extend: 把模块中的方法作为类的类方法
ruby
module A
def class_type
puts "This class is of type:#{self.class}"
end
end
class B extend A end
class C include A end
B.class_type
C.new.class_type-
require、load用于加载库,如
.rb文件,区别:require: 加载一个库,并且只加载一次,如果多次加载会返回false。文件不需要扩展名
load: 加载一个库,可多次加载。需要指定文件扩展名。
ruby# 在当前目录中有一个 two.rb文件 require './two'; load './two.rb';
6、yield、yield self
所有的方法(methods)都会隐式的带一个块(block)参数。
-
yield用来执行块参数,也可以通过call()方法执行。
yield 相当于是 block.call() 方法的调用,所以参数个数也需要对应, method 定义中 &block 参数必须在最后
rubydef foo1() yield 1,2,3 # 这里的 1 2 3 就是传递的参数 end def foo2(time, &block) yield 1, 2, 3 block.call(5, 6, 7) puts time end foo1 {|x,y,z| puts z} # => 3 foo2('2018') {|x,y,z| puts z} # => 3 7 2018 -
yield self
在一个对象中,self 表示是一个当前对象的引用。
yield self if block_given?相当于如果有块参数,那个调用快参数,参数是自己。rubydef foo(&block) puts self yield self if block_given? yield "AAAAAAAAA" end foo {|x| puts x} foo
参考链接:https://www.cnblogs.com/licongyu/p/5522027.html
7、 Ruby中的元编程
Ruby中的元编程,是可以在运行时动态地操作语言结构(如类、模块、实例变量等)的技术。你甚至于可以在不用重启的情况下,在运行时直接键入一段新的Ruby代码,并执行它。
Ruby的元编程,也具有"利用代码来编写代码"的作用。例如,常见的attr_accessor等方法就是如此。
7.1 实例变量、方法、类
- 同一个类的实例可以有不同的实例变量,因为实例变量只有使用的时候才会被建立。
- 匿名类:对一个具体对象添加方法是,ruby会插入一个新的匿名类来容纳新建的方法,匿名类不可见。
def initialize(*args): 方法可以通过参数不同执行不同的操作
7.2 send、eval、respond_to?
-
send
send是Object类的实例方法。第一个参数是方法名,后面是方法的参数使用
send方法,你所想要调用的方法就顺理成章的变成了一个普通的参数。你可以在运行时,直至最后一刻自由决定到底调用哪个方法。rubyclass Rubyist def welcome(*args) "Welcome " + args.join(' ') end end obj = Rubyist.new puts(obj.send(:welcome, "hello", "world")) eval("obj.welcome('123')") -
eval
用于执行一个用字符串表示的代码,
eval方法可以计算多行代码,使得将整个程序代码嵌入到字符串中并执行成为了可能。eval方法很慢,在执行字符串前最好对其预先求值。str = "Hello" puts eval("str + ' world'") # => "Hello world" -
respond_to?
所有的对象都有此方法,使用
respond_to?方法,你可以确定对象是否能使用指定的方法。rubyobj = Object.new if obj.respond_to?(:program) obj.program else puts "Sorry, the object doesn't understand the 'program' message." end参考资料:http://deathking.github.io/metaprogramming-in-ruby/chapter04.html
参考资料:
8、全局变量,实例变量,局部变量,类变量,Symbol
| 格式 | 名称 | 作用范围 | 举例 |
|---|---|---|---|
$开头 |
全局变量 | 从定义到程序结束 | $name |
@开头 |
实例变量 | self | @name |
@@开头 |
类变量 | 内部直接用,外部用类名::变量名 |
@@name |
[a-z_]开头 |
局部变量 | 定义的类、模块、方法内部,在类、模块、方法间不能共享 | name |
[A-Z] |
常量 | 内部、外部均可,外部访问类名::常量名 |
NAME |
:开头 |
Symbol | 内外 | :name |
参考资料:https://blog.csdn.net/emerald0106/article/details/7358766
9、ruby的特点
- 解释型执行,方便快捷:Ruby是解释型语言,其程序无需编译即可执行
- 语法简单、优雅:
- 完全面向对象: Ruby从一开始就被设计成纯粹的面向对象语言,因此所有东西都是对象,例如整数等基本数据类型。
- 内置正则式引擎,适合文本处理:Ruby支持功能强大的字符串操作和正则表达式检索功能,可以方便的对字符串进行处理。
- 自动垃圾收集: 具有垃圾回收(Garbage Collect,GC)功能,能自动回收不再使用的对象。不需要用户对内存进行管理。
- 跨平台和高度可移植性:Ruby支持多种平台,在Windows, Unix, Linux, MacOS上都可以运行。Ruby程序的可移植性非常好,绝大多数程序可以不加修改的在各种平台上加以运行。
- 有优雅、完善的异常处理机制: Ruby提供了一整套异常处理机制,可以方便优雅地处理代码处理出错的情况。
缺点:
- 解释型语言,所以速度较慢
- 静态检查比较少
rails
active record
创建、查询、修改、删除
ruby
class Product < ApplicationRecord
end
# 创建
# create 方法会创建一个新记录,并将其存入数据库:
user = User.create(name: "David", occupation: "Code Artist")
# new 方法实例化一个新对象,但不保存:
user = User.new
user.name = "David"
# 读取
users = User.all # 返回所有用户组成的集合
user = User.first # 返回第一个用户
david = User.find_by(name: 'David') # 返回第一个名为 David 的用户
# 查找所有名为 David,职业为 Code Artists 的用户,而且按照 created_at 反向排列
users = User.where(name: 'David', occupation: 'Code Artist').order(created_at: :desc)
# 更新
user.name = 'Dave'
user.save #
user.update(name: 'Dave')
# 删除
user.destroy
# https://ruby-china.github.io/rails-guides/active_record_basics.html#create上面的代码会创建 Product 模型,对应于数据库中的 products 表。同时,products 表中的字段也映射到 Product 模型实例的属性上。
关联模型
关联原因: 操作两个有关系的表时简化操作。
如果两个表有关联,比如一个作者表,一个图书表,一个作者对应多本书,如果此时删除一个作者前要先把作者对应的书删除,然后在删除作者。但是关联后,只需要在模型中删除作者语句即可,删除书的动作active_record会自动完成。
-
belongs_to:一对一关系
belongs_to关联创建两个模型之间一对一的关系,声明所在的模型实例属于另一个模型的实例。写belongs_to的模型里的一条记录相对于另一个表里有唯一一条记录,叫一对一。
例如有作者和图书两个模型,而且每本书只能指定给一位作者,在图书表中写上:
class Book < ApplicationRecord belongs_to :author end -
has_one:一对一关系
has_one关联也建立两个模型之间的一对一关系,但语义和结果有点不一样。这种关联表示模型的实例包含或拥有另一个模型的实例。例如,应用中每个供应商只有一个账户,可以这么定义供应商模型:class Supplier < ApplicationRecord has_one :account endhas_one与belongs_to的选择:
-
has_many :一对多
has_many关联表示模型的实例有零个或多个另一模型的实例。例如,对应用中的作者和图书模型来说,作者模型可以这样声明:class Author < ApplicationRecord has_many :books end -
:through: 通过第三张表来关联has_many :through这种关联表示一个模型的实例可以借由第三个模型,拥有零个和多个另一模型的实例。例如,在医疗锻炼中,病人要和医生约定练习时间。这中间的关联声明如下:
rubyclass Physician < ApplicationRecord has_many :appointments has_many :patients, through: :appointments end class Appointment < ApplicationRecord belongs_to :physician belongs_to :patient end class Patient < ApplicationRecord has_many :appointments has_many :physicians, through: :appointments endhas_one :through这种关联表示一个模型通过第三个模型拥有另一模型的实例。例如,每个供应商只有一个账户,而且每个账户都有一个账户历史,那么可以这么定义模型:
class Supplier < ApplicationRecord has_one :account has_one :account_history, through: :account end class Account < ApplicationRecord belongs_to :supplier has_one :account_history end class AccountHistory < ApplicationRecord belongs_to :account end -
has_and_belongs_to_many
直接建立两个模型之间的多对多关系,不借由第三个模型。例如,应用中有装配体和零件两个模型,每个装配体有多个零件,每个零件又可用于多个装配体,这时可以按照下面的方式定义模型:
rubyclass Assembly < ApplicationRecord has_and_belongs_to_many :parts end class Part < ApplicationRecord has_and_belongs_to_many :assemblies end
参考资料: https://ruby-china.github.io/rails-guides/association_basics.html
查询接口
-
检索对象
rubyfind # 检索指定主键对应的对象,没有记录find方法抛出 ActiveRecord::RecordNotFound 异常。 client = Client.find(10) # 查找主键(ID)为 10 的客户 take # 检索一条记录而不考虑排序,没有记录take方法返回 nil,而不抛出异常。 client = Client.take # SELECT * FROM clients LIMIT 1 first # 默认查找按主键排序的第一条记录。如果没有记录,first 方法返回 nil,而不抛出异常 client = Client.first # SELECT * FROM clients ORDER BY clients.id ASC LIMIT 1 last # 默认查找按主键排序的最后一条记录。没有记录last方法返回nil,而不抛出异常。 client = Client.last # SELECT * FROM clients ORDER BY clients.id DESC LIMIT 1 client = Client.last(3) # 返回不超过指定数量的查询结果。 client = Client.order(:first_name).last # 返回按照指定属性排序的最后一条记录。 client = Client.last! # 和 last 方法类似,区别是没有记录会抛出 ActiveRecord::RecordNotFound 异常。 find_by # 查找匹配指定条件的第一条记录。 Client.find_by first_name: 'Lifo' # Client.where(first_name: 'Lifo').take find_each # 批量检索记录,每条记录传入块, User.find_each do |user| NewsMailer.weekly(user).deliver_now end -
条件查询
where方法用于指明限制返回记录所使用的条件,相当于 SQL 语句的WHERE部分。条件可以使用字符串、数组或散列指定。ruby纯字符串条件:容易受到 SQL 注入攻击的风险。 Client.where("orders_count = '2'") # 查找所有 orders_count 字段的值为 2 的客户记录。 数组条件: 后面的参数会替换前面的问号(?) Client.where("orders_count = ?", params[:orders]) Client.where("orders_count = ? AND locked = ?", params[:orders], false) 条件中的占位符 Client.where("created_at >= :start_date AND created_at <= :end_date", {start_date: params[:start_date], end_date: params[:end_date]}) 散列条件 Client.where(locked: true) # SELECT * FROM clients WHERE (clients.locked = 1) NOT 条件:先调用没有参数的 where 方法,然后马上链式调用 not 方法,就可以生成这个查询。 Client.where.not(locked: true) # SELECT * FROM clients WHERE (clients.locked != 1) -
排序
ruby按 created_at 字段的升序方式取回记录: Client.order(:created_at) 还可以使用 ASC(升序) 或 DESC(降序) 指定排序方式: Client.order(created_at: :desc) Client.order(created_at: :asc) Client.order(orders_count: :asc, created_at: :desc)
数据库基本操作
-
插入数据
insert into <tablename> (field1,field2,field3..) values (value1,value2,value3); -
查询
select * from <tablename>; select <*/filed> select from <tablename> where <field>=<key>; select <*/field> form <tablename> where <field> like '%value%'; // 模糊查询 -
删除(Delete)
delete from <tablename> where <条件(和查询时条件类似)> -
更新(update)
update <tablename> set <field>=<value> where <条件(和查询时类似)>;
参考链接:https://blog.csdn.net/yuanmxiang/article/details/51683232
https://www.cnblogs.com/daxueshan/p/6687521.html