大家好,我是设计师阿威

(Stable diffusion生成的三上youya老师)
用AI进行画出不同人物,我们需要训练自己Lora模型。除了训练二次元人物之外,也常常要训练三次元人物。
比如福利姬老师可以训练自己然后穿上各种美美的衣服来拍照,减少自己的日常工作量。
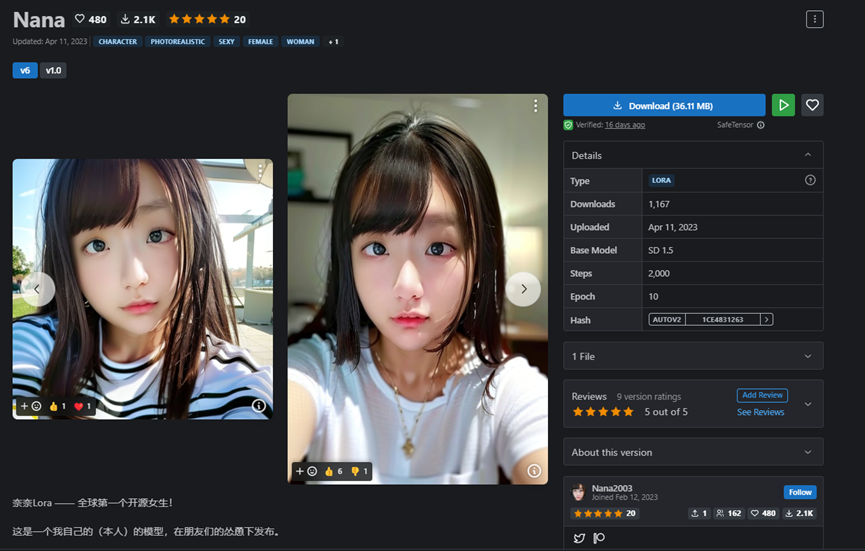
我们也可以训练模特人物之后,获得自己的AI模特。

还有的女生,也有用自己照片训练自己的lora,可以让这个电子替身在赛博世界,替自己穿上美美的衣服,去各种地方,还能保留自己最美的年华和最好的样子。
总之,三次元炼丹还是有蛮多应用场景的。
但是,三次元炼丹比二次元炼丹相对要复杂一些(难一些),因为三次元里面的人物,是三维的,比二次元人物多一维,也就代表着机器需要学习更多数据才能学会你的人物特征,也意味着如果有一点没学会或者没学对,都会让你的人物训练功亏一篑(不像,崩图,泛化性差等)。
下面,给大家分享一下我们这边的炼丹经验和步骤吧。
1.下载训练包
(1)下载星空大佬的 lora训练包(如果你已经有了秋叶大佬的一键训练包,可以直接使用。本文以星空训练包为教程),秋叶一键训练包、星空Lora训练安装包下载请扫描获取哦

下载完解压。记得路径里面不要有中文。
注意:该训练包需要自行配置Python环境,请务必确认自己的电脑安装有Python编译器
5.准备训练集(图片素材)
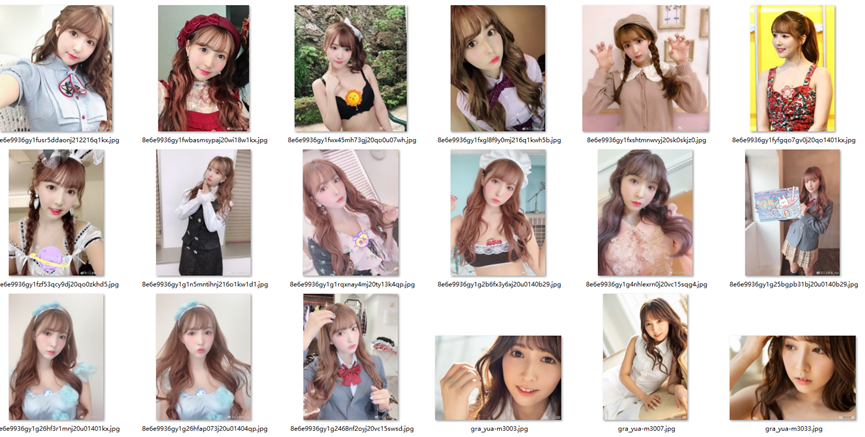
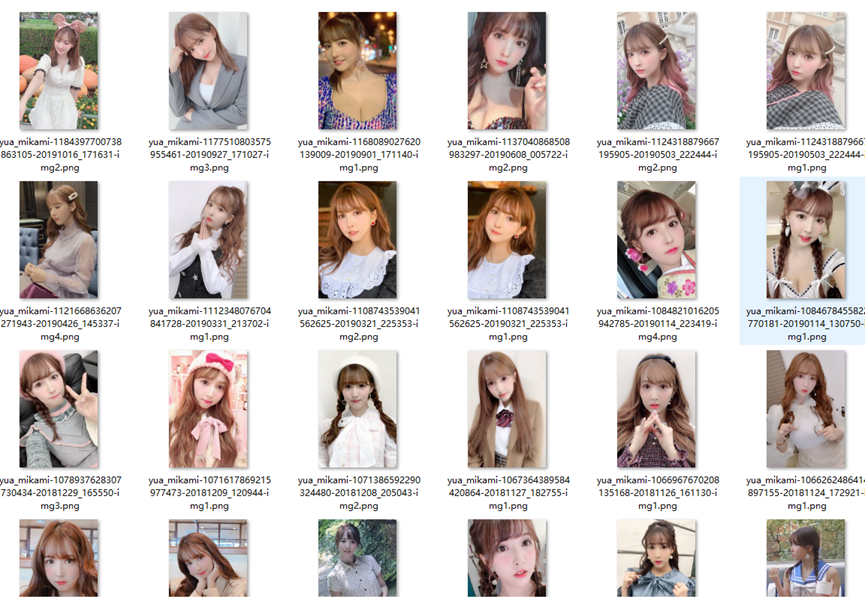
下面就以我们熟悉的三上Yua老师为例,来准备素材吧。
(1)准备好合适的照片集合,建议准备50张以上的照片素材,且分辨率需要是你目标训练分辨率的2倍以上(比如你想训练512x512的,那素材至少1024x1024),方便后续裁剪和加工。不要少于30张。要有不同的角度。不能都是正脸大头照。
注意:
脸部有遮挡的不要(比如麦克风,手指,杂物等),
背景太复杂的不要(比如广告板,上面一堆字,或者夜市背景太乱)
分辨率太低的不要(目标分辨率2倍以下的不要,方便裁切),
光影比较特殊的不要(比如暗光,背光等)。
不像本人特征的不要(比如大部分训练集都是长发,那么短发显脸大的不要)
化妆太浓重的,美颜太严重的不要。
(2)把图像裁剪成合适大小。
训练真人建议至少裁剪成512*768,如果显存够大,最好裁剪成1024像素以上。(图像越大,训练速度越慢,显存占用越高)
我们用photoshop,美图秀秀之类的软件手动裁剪图像。
6.Tag打标和tag整理
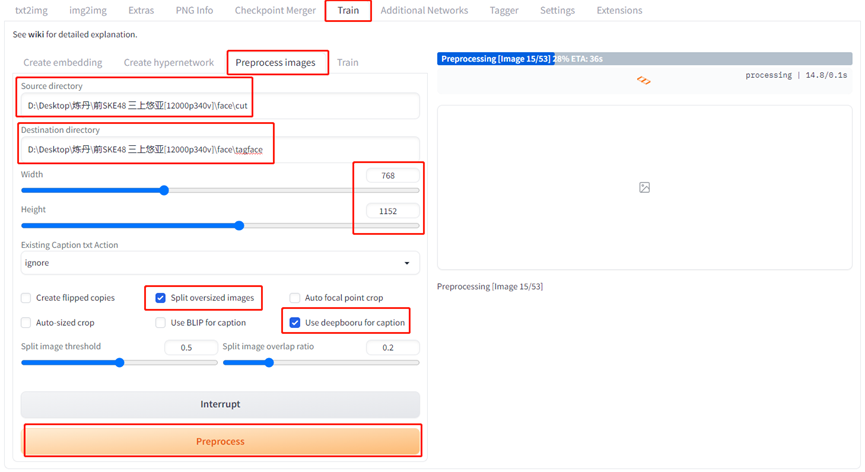
(1)在stable diffusion webui 的 train(训练)-preprocess images(图片预处理)下面,输入你裁剪后的图片地址和输出结果地址。
下面输入图片尺寸(或者你想裁剪成的图片尺寸。上面说的裁剪图片最懒最快的方法就是这里)。
接着选择split和use deepbooru for caption。
再点击preprocess开始对图片进行处理。
预处理完,你会发现目标文件夹里面每个图片旁边出现了一个txt文件,打开一看,里面是每张图片的tag(标签)

(2)整理每个图片的标签,每个图片对应的标签第一句加上你要训练的 trigger word(触发词),比如我要叫做 sanshangyua,就打开每一个tag文件(txt)文件,在最前面加入sanshangyua这个关键词。

部分专属人物特征需要从tag里面删除。
部分tag里面没体现的重要场景可以手工补充tag。也可以用类似tagger之类的工具再跑一次tag来优化。
7.设置训练文件夹
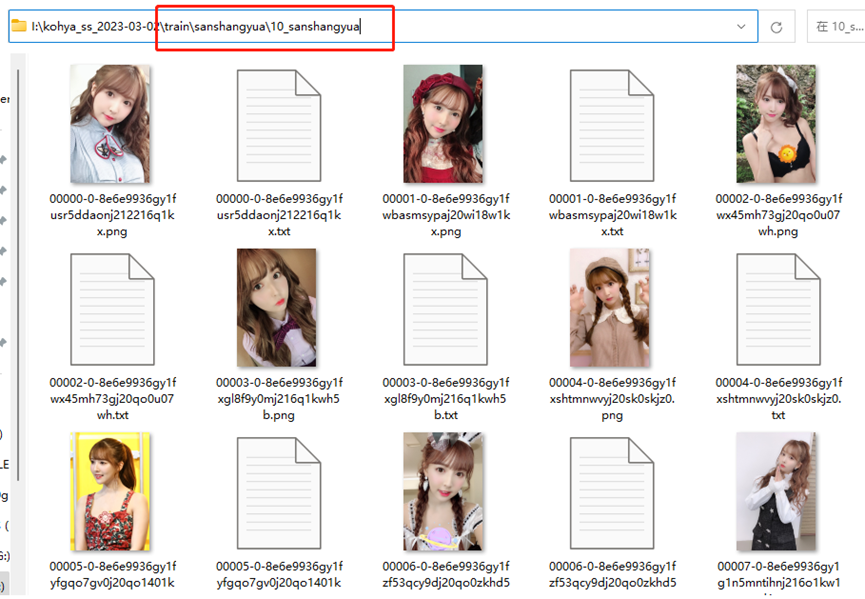
训练包里面新建一个train文件夹,里面放上你要训练的触发词,建一个文件夹。比如我就建一个sanshangyua文件夹,下面再建一个10_sanshangyua文件夹,里面放入刚刚处理完的图片文件和tag文件。
8.设置训练参数并开始训练。
(1)右键点击并用powershell运行训练包里面的run.ps1文件
(2)根据运行结果把提示的地址放浏览器地址栏打开
(2)选择训练基础模型,建议使用sd1.5或者chilloutmix系列模型。
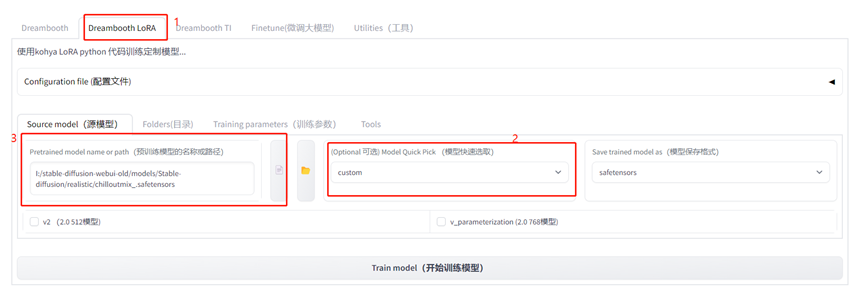
(3)设置训练集地址和输出地址以及训练的lora名字
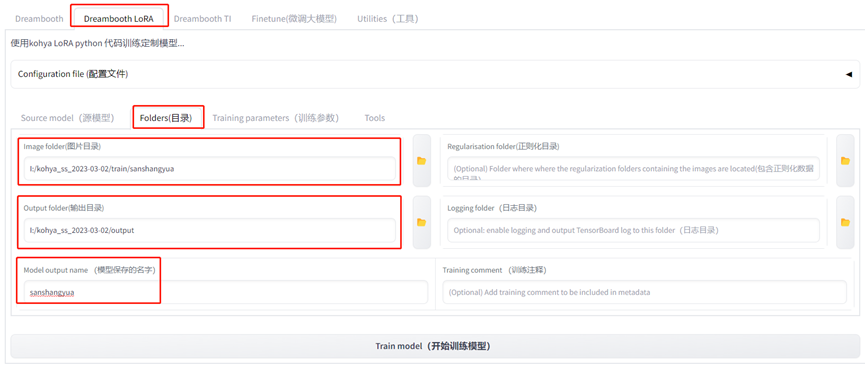
(4)打开训练参数(training paramenters)页面设置训练参数,没有标注的参数新手请按默认值。老手可以调着玩。

(5)训练参数-高级设置,use 8bit adam的勾记得去掉。其他的基本不用动。然后点击最下面的开始训练。

(注意,我这768x1152的分辨率在执行的时候报错了,显示说 assert max(resolution) <= max_bucket_reso,然后我把Enable buckets的勾去掉了就能正常运行。大家如果也报错分辨率相关问题,建议使用512*512或者512*768的经典分辨率,相对不容易出错。)
(6)等待训练结束
训练完成,接着可以去output文件夹找到相关的文件,sanshangyua-xxxx.safetensors就是我们的训练成果。
我分辨率比较大,训练了20轮,所以时间比较长,花了五个多小时。
大家如果图片分辨率小一些比如512x512,20-30张图片,20轮,大概1小时左右。如果显卡更好速度会更快。
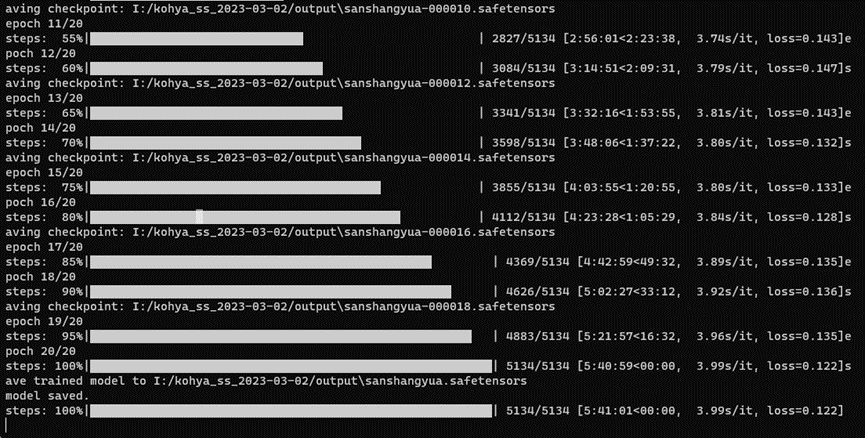
9.训练测试
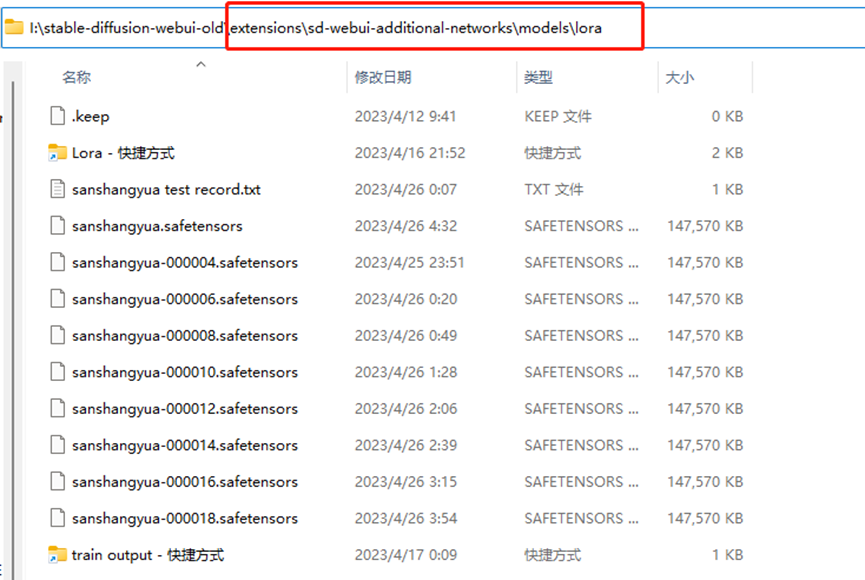
(1)把output文件夹中生成的几个safetensors文件,放到stable-diffusion-webui-old\extensions\sd-webui-additional-networks\models\lora文件夹里面。(注意,需要提前下载安装sd-webui-additional-networks插件。插件下载请看文末扫描获取哦)
(2)设置测试prompt参数
测试prompt这里有3个注意点,
a)基础模型要使用你的训练模型,比如你用的sd1.5或chilloutmix系列,那么你测试画图时要用的基础模型最后也用sd1.5或者chilloutmix系列基础模型。
b)记得在prompt区域加上你的trigger word触发词,比如我的是sanshangyua。Prompt区域还要加一个人物本来没有的特征,比如白发。以便测试泛用性。
c)本身因为我训练集的图片是1:1.5的,因此出图比例我也写1:1.5的512x768
(泛用性指的是,你训练的lora模型能否和其他模型很好的结合和拓展,比如你用chilloutmix训练的,那么用ralistic version模型能否跑出好图。比如换衣服是否自然顺畅,比如是否能自然顺畅出全身照等(前提是你没有训练全身照)。)
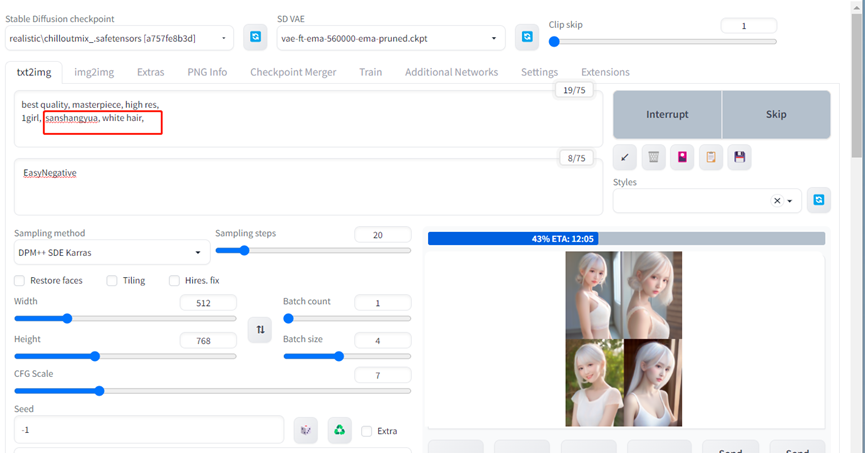
(3)设置xyz参数
a) additional networks随便选一个lora,激活additional networks插件。
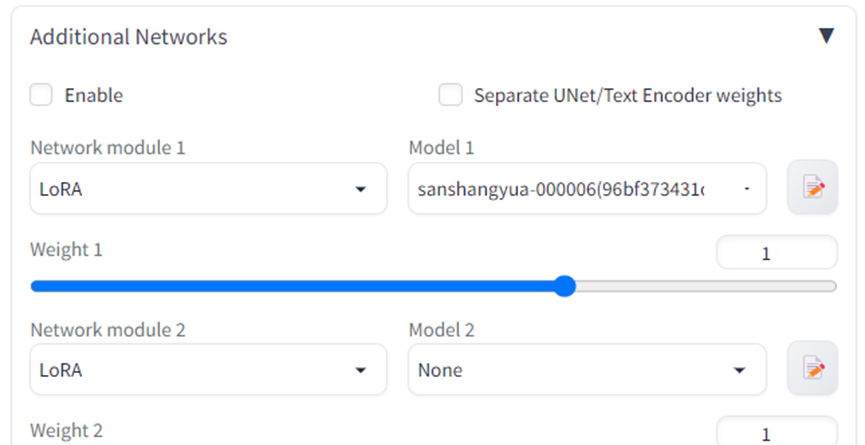
b)设置xyz参数
x轴设置为 addnet model 1,然后点击小黄笔记本,自动引入所有lora文件名。
Y轴设置为 addnet weight1,然后输入0.6-1.
设置xy让系统自动用不同的lora分别以0.6-1的权重跑prompt指令。
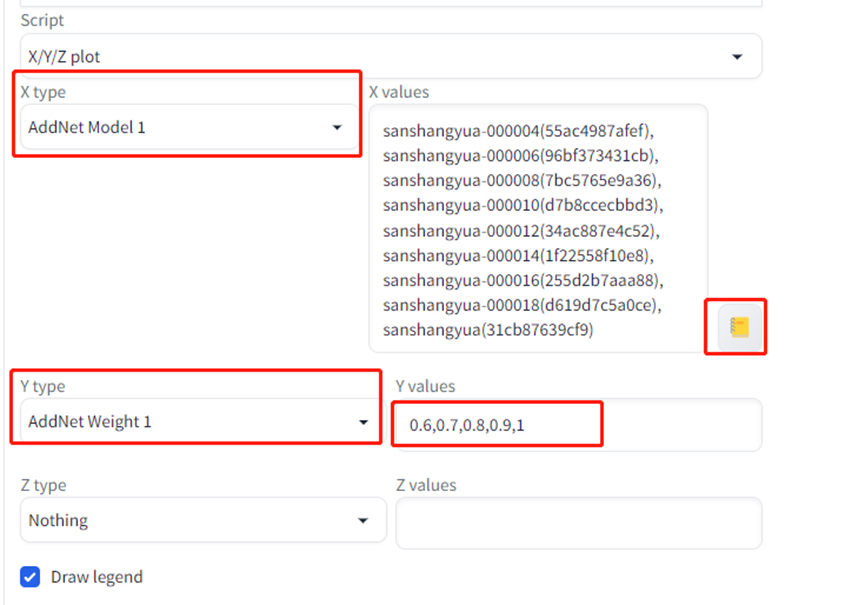
c)等待xyz出结果
10.对比结果,筛选表现好的lora进一步测试或回炉重造
(1)通过xyz对比图,看哪一个训练结果表现最好,最像的同时泛化性最好。
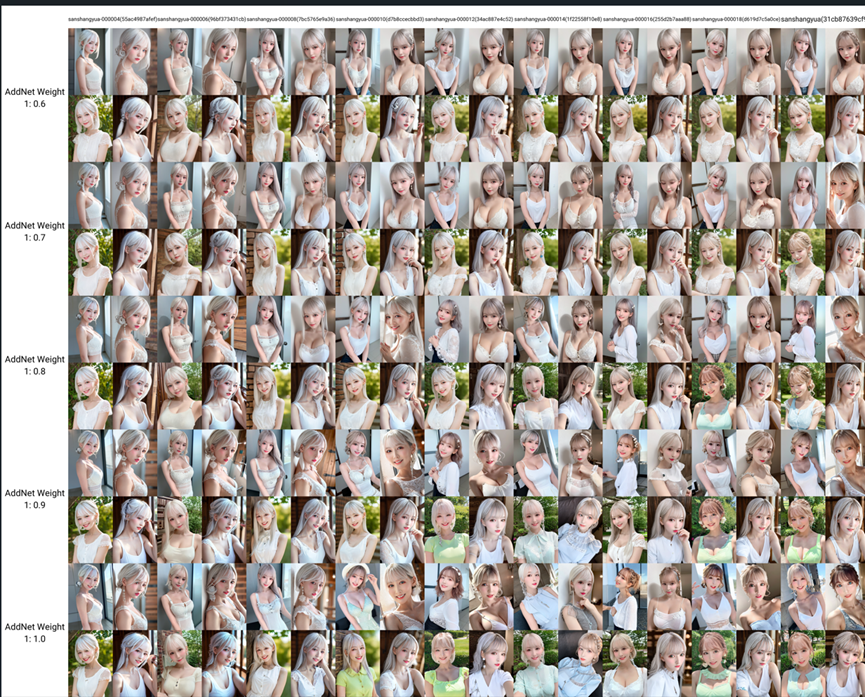
如果没有则回去调整训练参数重新训练。如果调整训练参数没用的话大概率是训练集问题,重新收集整理裁剪训练集,并优化tag。
(2)如果有表现比较好的lora,则复制出来,放到stable-diffusion-webui/models/lora文件夹下面。随机跑几张图再测试一下,没问题就修改lora名称,删掉多余lora,方便后续使用。
(3)*可选 如果有又像又不像的,可以把对应lora拉出来,再去重复训练一次,epoch设置5,每1 epoch保存一次。再优中选优。但是最好不要重复训练太多次,否则容易过拟合,要么图像崩坏,要么泛化性非常差。
(4)记录训练参数,数据,测试数据,便于下一次迭代。
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。

二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除