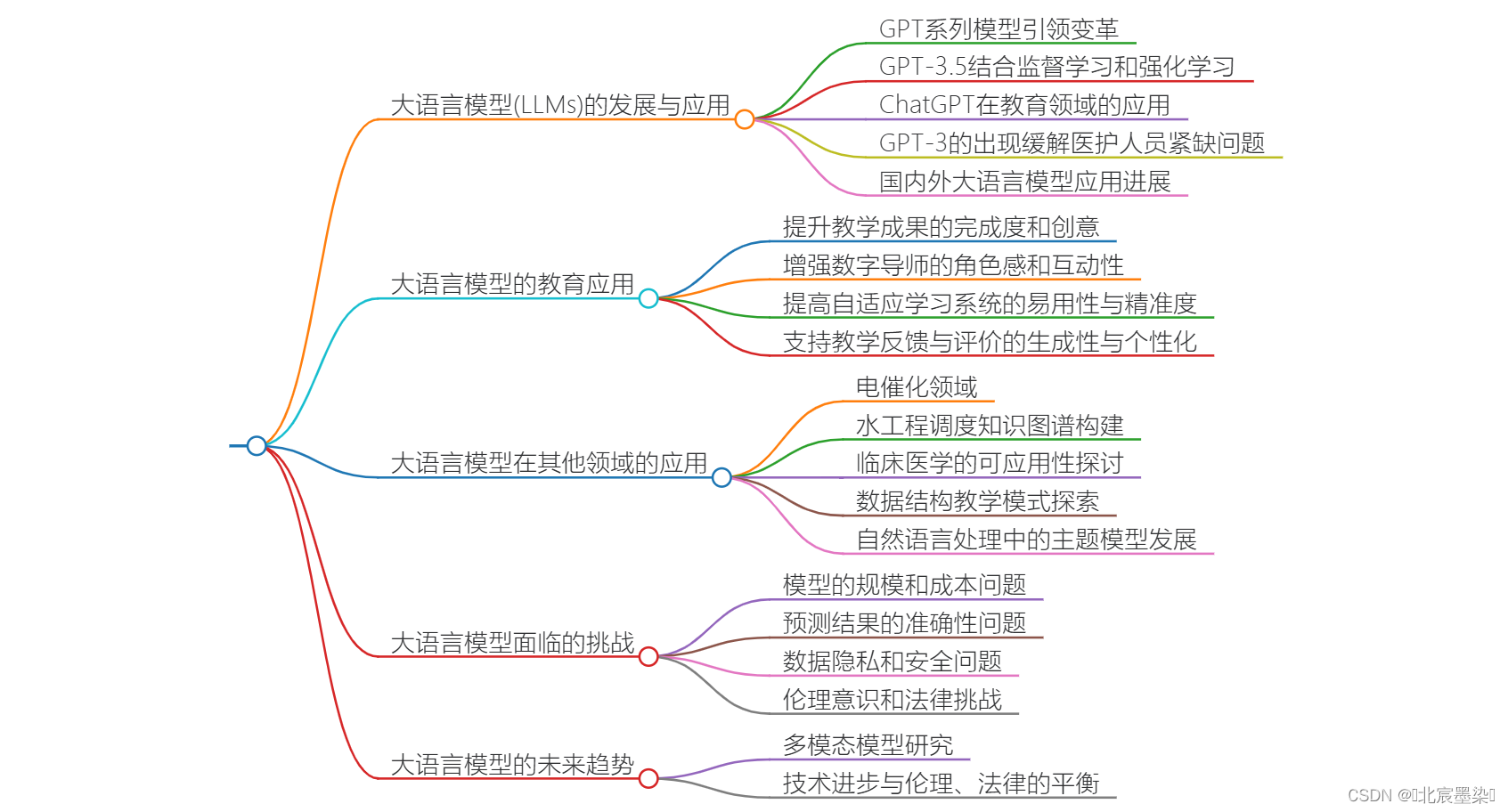
大语言模型的发展与挑战
前言
大语言模型 (Large Language Models, LLM) 是近年来自然语言处理 (NLP) 领域的突破性进展,它改变了我们与机器交互的方式,并打开了智能应用的新篇章。本文将深入探讨大语言模型的概念、关键技术、应用场景、挑战和未来发展趋势。

什么是大语言模型?
大语言模型是一种基于深度学习的 NLP 模型,它通过学习大规模语料库中的语言模式,能够理解和生成复杂的语言结构,具备记忆和推理能力,并能够进行上下文理解。与传统 NLP 模型相比,大语言模型具有更强的泛化能力和迁移能力,可以应用于多种 NLP 任务,如文本分类、信息抽取、情感分析、机器翻译、对话生成等。
大语言模型的关键技术:
- 深度神经网络架构:大语言模型通常基于复杂的深度神经网络架构,如Transformer模型。Transformer模型通过自注意力机制(Self-Attention Mechanism)能够在处理长文本时捕捉到远距离的依赖关系,这是大语言模型能够生成高质量文本的关键。
- 预训练与微调:大语言模型首先在大量文本上进行预训练(Pre-training),以学习语言的一般规律。预训练完成后,模型可以通过微调(Fine-tuning)适应特定的任务,如文本分类、机器翻译等。
- 自监督学习:由于大量的文本数据是未标注的,大语言模型通常采用自监督学习(Self-supervised Learning)的方法进行预训练。例如,掩码语言建模(Masked Language Modeling)任务要求模型预测被掩码的单词,这是一种有效的自监督学习方法。
- 上下文学习:大语言模型能够根据给定的上下文生成响应,这种能力被称为上下文学习(Context Learning)。通过这种方式,模型能够理解对话的上下文,生成更加相关和连贯的回答。
- 无监督和半监督学习:大语言模型在预训练阶段主要采用无监督学习方法,但在微调阶段可以使用有限的标注数据进行半监督学习,以提高模型的性能。
- 稀疏注意力机制:为了处理非常长的文本序列,一些大语言模型采用了稀疏注意力机制,如Longformer和BigBird。这些机制通过只关注序列中的部分重要部分来减少计算复杂度。
- 多模态学习:最新的一些大语言模型不仅能够处理文本数据,还能够处理图像、声音等其他类型的数据,实现多模态学习(Multimodal Learning)。
- 伦理和安全性:随着大语言模型能力的增强,确保它们的输出符合伦理标准和使用安全变得越来越重要。这涉及到模型偏差的减少、对抗性攻击的防御以及滥用模型的预防。
- 模型压缩和优化:由于大语言模型通常具有数十亿到千亿级别的参数,模型压缩和优化技术(如知识蒸馏、参数共享等)被用于减少模型的体积,使其能够在资源有限的设备上运行。
- 跨语言学习:大语言模型能够处理多种语言,它们通过跨语言学习(Cross-lingual Learning)共享不同语言之间的信息,提高在低资源语言上的性能。
这些关键技术的不断进步推动了大语言模型的发展,使它们成为NLP领域的重要工具,并在多个实际应用中展现出强大的能力。随着研究的深入,未来大语言模型将会在更多领域发挥重要作用,并可能带来新的技术突破。
大语言模型发展历史
- 2020年9月,OpenAI授权微软使用GPT-3模型,微软成为全球首个享用GPT-3能力的公司。2022年,Open AI发布ChatGPT模型用于生成自然语言文本。2023年3月15日,Open AI发布了多模态预训练大模型GPT4.0。
- 2023年2月,谷歌发布会公布了聊天机器人Bard,它由谷歌的大语言模型LaMDA驱动。2023年3月22日,谷歌开放Bard的公测,首先面向美国和英国地区启动,未来逐步在其它地区上线。
- 2023年2月7日,百度正式宣布将推出文心一言,3月16日正式上线。文心一言的底层技术基础为文心大模型,底层逻辑是通过百度智能云提供服务,吸引企业和机构客户使用API和基础设施,共同搭建AI模型、开发应用,实现产业AI普惠。
- 2023年4月13日,亚马逊云服务部门在官方博客宣布推出Bedrock生成式人工智能服务,以及自有的大语言模型泰坦(Titan)。
- 2024年3月,Databricks 推出大语言模型 DBRX,号称"现阶段最强开源 AI"。
- 2024年4月,在瑞士举行的第27届联合国科技大会上,世界数字技术院(WDTA)发布了《生成式人工智能应用安全测试标准》和《大语言模型安全测试方法》两项国际标准,是由OpenAI、蚂蚁集团、科大讯飞、谷歌、微软、英伟达、百度、腾讯等数十家单位的多名专家学者共同编制而成。
大语言模型的应用场景
大语言模型已经在各个领域得到广泛应用,例如:
- 智能客服: 理解客户需求,提供自动化回复,进行情感分析。
- 智能写作: 生成文章、新闻报道、文案、诗歌等文本内容。
- 文本翻译: 实现不同语言之间的文本翻译。
- 个性化推荐: 分析用户行为和喜好,进行个性化推荐和广告投放。
- 自动驾驶: 对车辆行驶状态和环境进行实时感知和理解,实现车辆控制和智能导航。
- 内容过滤: 分析大量内容,过滤掉不良信息。
大语言模型的挑战
尽管大语言模型取得了巨大进步,但也面临着一些挑战,例如:
- 数据稀疏性: 标注数据稀缺,导致模型训练效果不佳。
- 计算资源需求: 训练大语言模型需要大量的计算资源。
- 可解释性不足: 模型决策过程缺乏透明度,难以理解和解释。
- 安全与隐私 : 处理敏感信息时可能引发安全与隐私问题。
为了克服这些挑战,研究人员正在探索各种解决方案,例如: - 半监督学习: 利用少量标注数据和大量未标注数据进行训练。
- 小样本学习: 使模型能够从少量样本中学习。
- 知识蒸馏: 将大型模型的知识迁移到小型模型中。
- 模型解释性研究: 开发更有效的可解释性算法和技术。
- 安全与隐私保护技术: 保证用户数据的安全和隐私。
大语言模型未来发展趋势
未来,大语言模型将继续朝着以下方向发展:
- 模型规模持续增大: 模型参数量将持续增加,以提供更强大的语言处理能力和更高的性能。
- 应用场景不断拓展: 大语言模型将在各个垂直领域得到广泛应用,并实现跨领域融合。
- 模型可解释性增强: 研究人员将致力于开发更有效的可解释性算法和技术。
- 技术开源与标准化: 大语言模型的开源平台将得到进一步发展和完善,相关机构将制定一系列的标准和评估指标。
结语
总而言之,大语言模型是 NLP 领域的重要突破,它具有巨大的潜力,并将改变我们与机器交互的方式。随着技术的不断发展和完善,大语言模型将在各个领域发挥更大的作用,为人类社会带来更多便利和福祉。