Qwen2的web搭建(streamlit)
千问2前段时间发布了,个人觉得千问系列是我用过最好的中文开源大模型,所以这里基于streamlit进行一个千问2的web搭建,来进行模型的测试
一、硬件要求
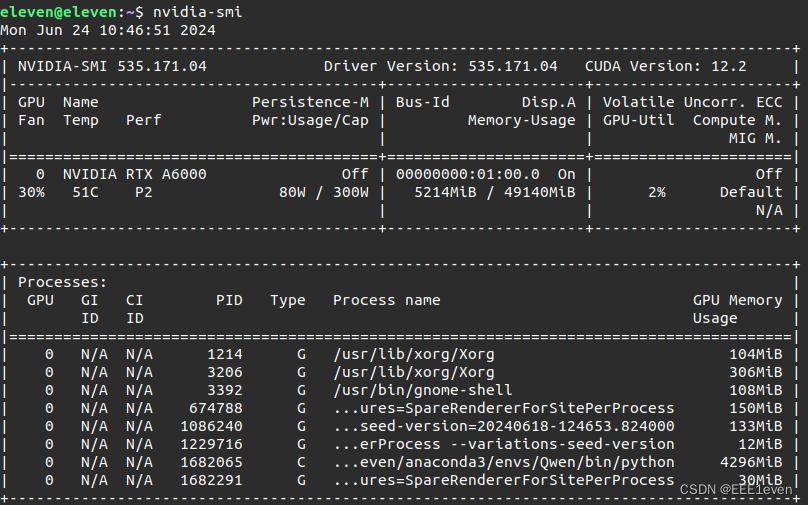
该文档中使用的千问模型为7B-Instruct,需要5g以上的显存,如果是轻薄本不建议进行本地测试(下图为测试时的实际显存占用)
二、环境准备
对于环境的基本要求
bash
transformers
torch
streamlit
sentencepiece
accelerate
transformers_stream_generator上述是基础的环境准备,可以用conda创建一个新的环境来进行配置。在下载库时可以使用清华大学的镜像进行加速,如下所示
bash
pip install transformers -i https://pypi.tuna.tsinghua.edu.cn/simple三、模型下载
这里推荐使用huggingface镜像网站进行下载,因为在下载中断后,再次请求时会从上次中断的地方继续,而不是重新下载。
以千问为例,在终端的下载请求为
bash
huggingface-cli download --resume-download Qwen/Qwen2-7B-Instruct --local-dir ./qwen2四、web代码编写
python
from transformers import AutoTokenizer,AutoModelForCausalLM
import torch
import streamlit as st
#在侧边栏创建标题
with st.sidebar:
st.markdown("qwen2")
"hello world"
#创建滑块,默认值为512,范围在0到1024之间
max_length = st.slider("max_length",0,1024,512,step=1)
#创建标题和副标题
st.title("qwen2 chatbot")
st.caption("test")
#你下载到本地的模型路径
model_path = "../models/qwen2-1.5b-Instruct"
#@streamlit.cache_resource 是一个用于缓存昂贵或频繁调用的资源(如大型文件、网络资源、或数据库连接)的装饰器。这个装饰器可以帮助你提高应用的性能,通过缓存那些不经常变更但加载需要大量时间或计算资源的数据。
#定义的函数来获取tokenizer和model
@st.cache_resource
def get_model():
tokenizer = AutoTokenizer.from_pretrained(model_path,use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_path,torch_dtype=torch.float16,device_map='auto')
return tokenizer,model
tokenizer,model = get_model()
#如果没有消息,则创建默认的消息列表
if "messages" not in st.session_state:
st.session_state['messages'] = [{'role':"assistant","content":"有什么可以帮到您?"}]
#便利session_state中的消息并显示在聊天界面上
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
## 如果用户在聊天输入框中输入了内容,则执行下述操作
if prompt := st.chat_input():
#将用户输入添加到message列表中
st.session_state.messages.append({"role":"user","content":prompt})
#在聊天界面上显示用户输入
st.chat_message("user").write(prompt)
#构建输入
input_ids = tokenizer.apply_chat_template(st.session_state.messages,tokenize=False,add_generation_prompt=True)
model_inputs = tokenizer([input_ids],return_tensors='pt').to('cuda')
#模型生成输出id
generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512)
generated_ids = [
output_ids[len(input_ids):] for input_ids,output_ids in zip(model_inputs.input_ids,generated_ids)
]
#将生成的id转换成文字
response = tokenizer.batch_decode(generated_ids,skip_special_tokens=True)[0]
st.session_state.messages.append({"role":"assistant","content":response})
#在界面上显示输出
st.chat_message("assistant").write(response)由于qwen2模型并没有自带流式输出函数,会报错
AttributeError: 'Qwen2Model' object has no attribute 'stream_chat',后续改进考虑对其进行流式输出增强用户可读性
五、终端启动
在该文件目录下,终端输入
bash
streamlit run your_file_name.py之后就会进入web界面
六、调试
streamlit这样的web形式不能直接通过打断点进行debug,所以需要进行一些处理:
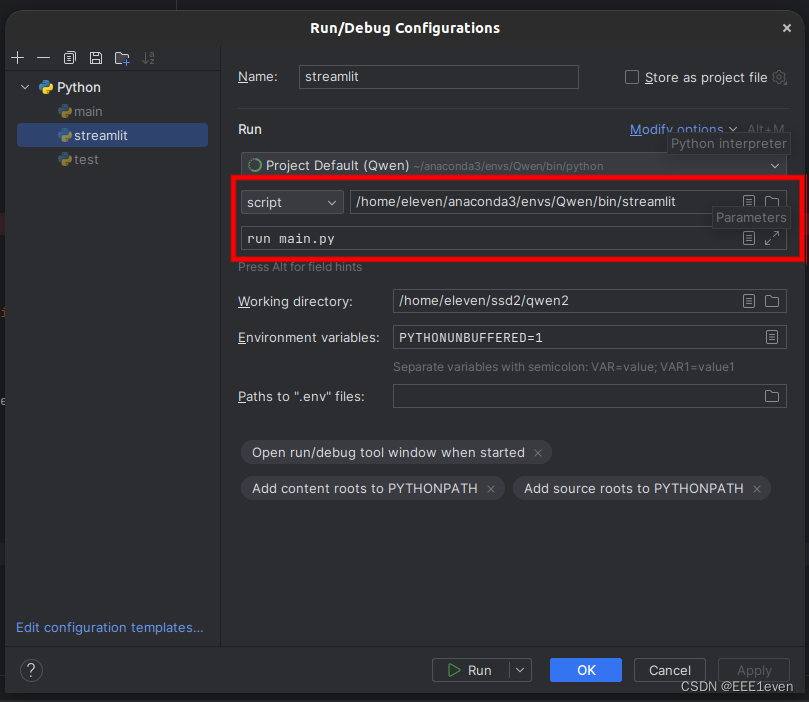
红框中进行下图配置,script框中的路径是你配置的模型环境中,streamlit所在的绝对路径;parameters框就是run your_file_name.py,这样处理后就是终端输入streamlit run your_file_name.py的效果,之后就能进行断点调试了
Reference
1 qwen官方文档