一、字符串函数
- CONCAT(s1, s2):连接两个字符串s1和s2。
sql
SELECT CONCAT('Hello', ' World') FROM DUAL-- 结果:'Hello World'
--或者使用 || 操作符
SELECT 'Hello' || ' World' FROM DUAL -- 结果:'Hello World'- INITCAP(s):将字符串s中每个单词的首字母变为大写,其余字母变为小写。
sql
SELECT INITCAP('hello world') FROM DUAL; -- 结果:'Hello World'
SELECT INITCAP('helloworld') FROM DUAL -- 结果:'Helloworld'-
INSTR(s1, s2, start, \[nth_appearance]):在字符串s1中搜索s2,返回s2首次(或第n次)出现的位置。
SELECT INSTR('aaaaaa','a') FROM dual -- 结果: 1
SELECT INSTR('aaaaaa','a',1) FROM dual -- 结果: 1
SELECT INSTR('aaaaaa','a',2) FROM dual -- 结果: 2
SELECT INSTR('aaaaaa','a',3) FROM dual -- 结果: 3SELECT INSTR('abcabcabc','abc') FROM dual -- 结果: 1
SELECT INSTR('abcabcabc','abc',1) FROM dual-- 结果: 1
SELECT INSTR('abcabcabc','abc',2) FROM dual-- 结果: 4
SELECT INSTR('abcabcabc','abc',3) FROM dual-- 结果: 4
SELECT INSTR('abcabcabc','abc',4) FROM dual-- 结果: 4
SELECT INSTR('abcabcabc','abc',5) FROM dual-- 结果: 7SELECT INSTR('abcabcabc','abc',1,1) FROM dual-- 结果: 1
SELECT INSTR('abcabcabc','abc',1,2) FROM dual-- 结果: 4
SELECT INSTR('abcabcabc','abc',1,3) FROM dual-- 结果: 7 -
LENGTH(s):返回字符串s的长度。
sql
SELECT LENGTH('Hello World') FROM DUAL -- 结果:11
SELECT LENGTH('HelloWorld') FROM DUAL -- 结果:10- LOWER(s):将字符串s中的所有字符转换为小写。
sql
SELECT LOWER('HELLO WORLD') FROM DUAL; -- 结果:'hello world'- UPPER(s):将字符串s中的所有字符转换为小写。
- LPAD(s, length, pad_string) :在字符串s的左边填充字符,直到总长度为length。
sql
SELECT LPAD('abc',10,'*') FROM DUAL -- 结果:'*******abc'
SELECT LPAD('abc',10) FROM DUAL -- 结果:' abc'
SELECT LPAD('abc',10,' ') FROM DUAL -- 结果:' abc'
// 第二句和第三句sql执行结果相同
sql
SELECT LPAD('abc',10,null) FROM DUAL
SELECT LPAD('abc',10,'') FROM DUAL 
- LTRIM(s, trim_characters) :从字符串s的左边删除指定的字符(默认为空格)。
sql
SELECT LTRIM('abcdefg','ab') FROM dual -- cdefg
SELECT LTRIM('abcdefg','abcdef') FROM dual -- g
SELECT LTRIM('abcdefg','efg') FROM dual -- cdefg
SELECT LTRIM('abcdefg') FROM dual -- abcdefg
SELECT LTRIM(' abcdefg') FROM dual -- abcdefg- RPAD(s, length, pad_string) :在字符串s的右边填充字符,直到总长度为length。
- RTRIM(s, trim_characters) :从字符串s的右边删除指定的字符(默认为空格)。
- SUBSTR(s, start, length):从字符串s的start位置开始截取length个字符。
sql
SELECT SUBSTR('Hello World', 1, 5) FROM DUAL -- 结果:'Hello'- REPLACE(s, search_string, replace_string):在字符串s中替换所有的search_string为replace_string。
sql
SELECT REPLACE('abcdefg','a','*') FROM dual -- *bcdefg
SELECT REPLACE('abcdefg','b','*') FROM dual -- a*cdefg
SELECT REPLACE('abcdefg','ab','*') FROM dual -- *cdefg
SELECT REPLACE('abcdefg','x','*') FROM dual -- abcdefg
SELECT REPLACE('aabb','a','*') FROM dual -- **bb
SELECT REPLACE('aabb','aa','*') FROM dual -- *bb二、数值函数
- ABS(n):返回n的绝对值。
sql
SELECT ABS(-10) FROM DUAL; -- 结果:10- CEIL(n):返回大于或等于n的最小整数。
- FLOOR(n):返回小于或等于n的最大整数。
- MOD(m, n):返回m除以n的余数。
- POWER(m, n):返回m的n次幂。
- ROUND(n, m):将n四舍五入到小数点后m位。
- SIGN(n):如果n是正数返回1,是负数返回-1,否则返回0。
- SQRT(n):返回n的平方根。
- TRUNC(n, m):根据m的值截取n。如果m为正,则截去小数点后的m位;如果m为负,则截去小数点前的m位。
sql
SELECT TRUNC(123.456, 2) FROM DUAL -- 结果:123.45
SELECT TRUNC(123.456, 1) FROM DUAL -- 结果:123.4
SELECT TRUNC(123.456, 0) FROM DUAL -- 结果:123
SELECT TRUNC(123.456, -1) FROM DUAL -- 结果:120
SELECT TRUNC(123.456, -2) FROM DUAL -- 结果:100三、日期函数
- SYSDATE:返回当前系统日期和时间。
sql
SELECT SYSDATE FROM DUAL -- 返回当前日期和时间 2024-06-28- ADD_MONTHS(date, number):返回date之后number个月的日期。
sql
SELECT ADD_MONTHS(SYSDATE, 1) FROM DUAL -- 返回当前日期后一个月的日期 2024-07-28
SELECT ADD_MONTHS(SYSDATE, 2) FROM DUAL -- 返回当前日期后一个月的日期 2024-08-28
SELECT ADD_MONTHS(SYSDATE, 12) FROM DUAL -- 返回当前日期后一个月的日期 2025-06-28- LAST_DAY(date):返回date所在月份的最后一天的日期。
sql
SELECT LAST_DAY(SYSDATE) FROM DUAL -- 返回当前月份的最后一天 2024-06-30
SELECT LAST_DAY(ADD_MONTHS(SYSDATE,1)) FROM DUAL -- 2024-07-31- MONTHS_BETWEEN(date1, date2):返回date1和date2之间相差的月数。
sql
SELECT MONTHS_BETWEEN(SYSDATE, ADD_MONTHS(SYSDATE, -1)) FROM DUAL -- 结果:1- NEXT_DAY(date, day_of_week):返回date之后的第一个day_of_week的日期。
sql
SELECT SYSDATE FROM DUAL -- 结果:2024-06-28
SELECT NEXT_DAY(SYSDATE,1) FROM DUAL -- 查找2024-6-28之后的下一个星期日的日期 结果:2024-06-30
SELECT NEXT_DAY(SYSDATE,2) FROM DUAL -- 查找2024-6-28之后的下一个星期三的日期 结果:2024-07-01
SELECT NEXT_DAY(SYSDATE,5) FROM DUAL -- 结果:查找2024-6-28之后的下一个星期四的日期 2024-07-04
SELECT NEXT_DAY(SYSDATE,7) FROM DUAL -- 结果:查找2024-6-28之后的下一个星期六的日期 2024-06-29
// 1,2,3,4,5,6,7分别代表周日,周一,周二,周三,周四,周五,周六
- TO_CHAR(date, 'format'):将日期date转换为指定'format'格式的字符串。
sql
SELECT TO_CHAR(SYSDATE,'yyyy-MM-dd') FROM DUAL -- 结果:2024-06-28
SELECT TO_CHAR(SYSDATE,'yyyy-MM') FROM DUAL -- 结果:2024-06
SELECT TO_CHAR(SYSDATE,'yyyy-MM-dd') FROM DUAL -- 结果:2024-06-28
SELECT TO_CHAR(SYSDATE,'yyyy-MM-dd hh:mm:ss') FROM DUAL -- 结果:2024-06-28 07:06:29- TO_DATE(string, 'format'):将字符串string按照指定'format'格式转换为日期。
sql
SELECT TO_DATE('2023-10-23', 'YYYY-MM-DD') AS converted_date FROM DUAL;--2023-10-23
SELECT TO_DATE('2024-5-20 23:59:59', 'yyyy-MM-dd HH24:mi:ss') FROM dual-- 结果:2024-05-20需要注意format格式:
正确格式:yyyy-MM-dd HH24:mi:ss或yyyy-MM-dd HH:mi:ss
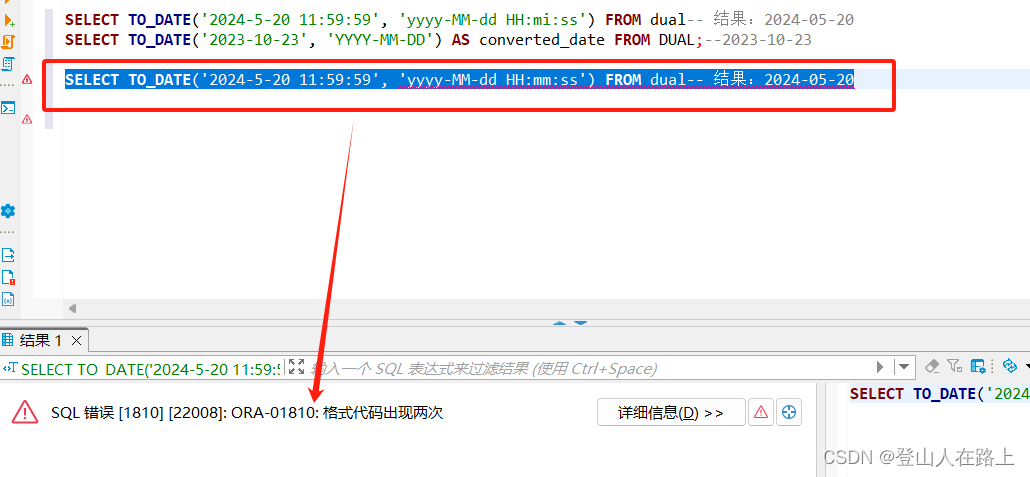
四、转换函数
- TO_CHAR(x, 'format'):将数字x或日期转换为指定'format'格式的字符串。
- TO_DATE(s, 'format'):将字符串s按照指定'format'格式转换为日期。
- TO_NUMBER(s, 'format'):将字符串s按照指定'format'格式转换为数字。
sql
SELECT TO_NUMBER('123') FROM DUAL; -- 结果:123五、统计函数(聚合函数)
- AVG(columnName):返回columnName的平均值。
sql
SELECT AVG(salary) FROM employees; -- 返回员工的平均工资- COUNT(columnName):返回columnName的记录数。
- MAX(columnName):返回columnName的最大值。
- MIN(columnName):返回columnName的最小值。
- SUM(columnName):返回columnName的总和。
六、其他函数
- NVL(expression1, expression2):如果expression1为NULL,则返回expression2的值;否则返回expression1的值。
sql
SELECT NVL('abc', 'No Value') FROM DUAL -- 结果:abc
SELECT NVL(NULL, 'No Value') FROM DUAL -- 结果:'No Value'
SELECT NVL(NULL, '没有值') FROM DUAL -- 结果:没有值
SELECT NVL('', '没有值') FROM DUAL -- 结果:没有值- DECODE(expression, search1, result1, search2, result2, ..., default):类似于其他编程语言中的switch-case语句,根据expression的值返回对应的结果。
sql
SELECT DECODE(5000, 5000, 'Low', 10000, 'High', 'Medium') AS salary_range FROM dual -- 结果: Low
SELECT DECODE(10000, 5000, 'Low', 10000, 'High', 'Medium') AS salary_range FROM dual -- 结果: High
SELECT DECODE(123, 5000, 'Low', 10000, 'High', 'Medium') AS salary_range FROM dual -- 结果: Medium
// 将传入的第一个值与5000,10000相比较,第一个参数的值等于5000,输出low,第一个参数的值等于10000输出high,第一个参数的值既不等于5000也不等于10000则输出medium注意事项:
- 从Oracle 11g开始,虽然DECODE函数仍然可用,但Oracle官方推荐使用CASE语句代替DECODE函数,因为CASE语句在某些情况下可能具有更好的可读性和灵活性。
- 每个
search_valueN只能出现一次,但可以有多个连续的result_valueN作为条件判断的结果。 - 如果
expression的值为NULL,它将与NULLsearch_valueN匹配(如果存在)。