李宏毅深度学习笔记
图像分类
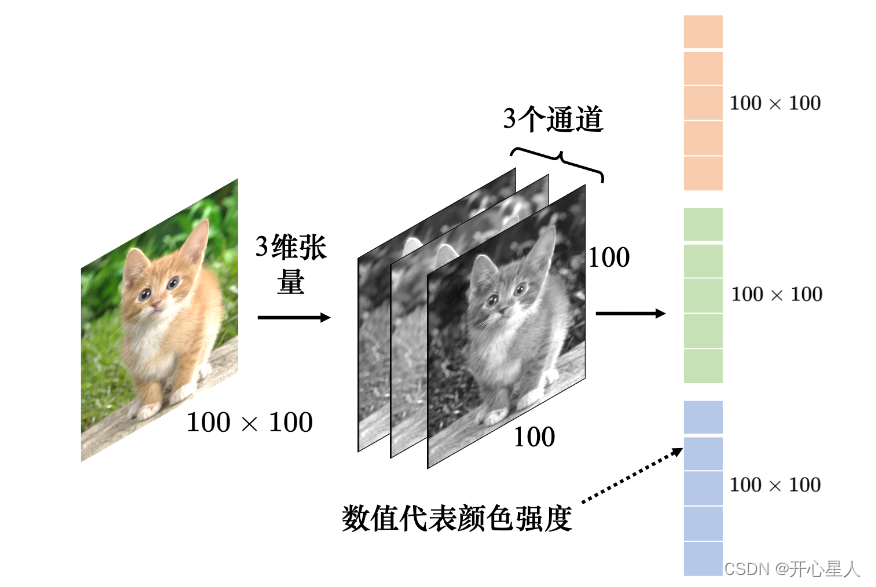
图像可以描述为三维张量(张量可以想成维度大于 2 的矩阵)。一张图像是一个三维的张量,其中一维代表图像的宽,另外一维代表图像的高,还有一维代表图像的通道(channel)的数目。
通道:彩色图像的每个像素都可以描述为红色(red)、绿色(green)、蓝色(blue)的组合,这 3 种颜色就称为图像的 3 个色彩通道。
如果把向量当做全连接网络的输入,输入的特征向量的长度就是 100 × 100 × 3。这是一个非常长的向量。由于每个神经元跟输入的向量中的每个数值都需要一个权重,所以当输入的向量长度是 100 × 100 × 3,且第 1 层有 1000 个神经元时,
第 1 层的权重就需要 1000 × 100 × 100 × 3 = 3 × 107 个权重。
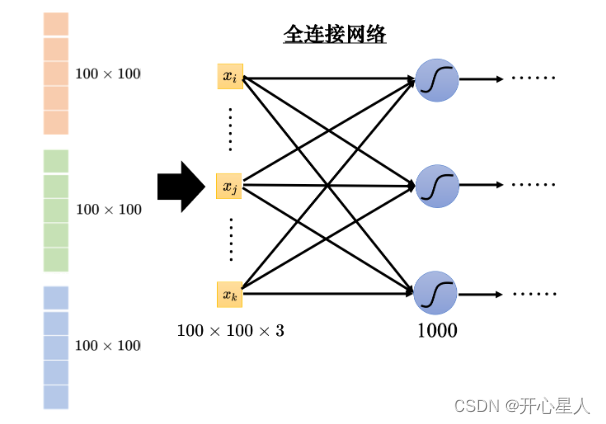
更多的参数为模型带来了更好的弹性和更强的能力,但也增加了过拟合的风险。模型的弹性越大,就越容易过拟合。为了避免过拟合,在做图像识别的时候,考虑到图像本身的特性,并不一定需要全连接,即不需要每个神经元跟输入的每个维度都有一个权重。
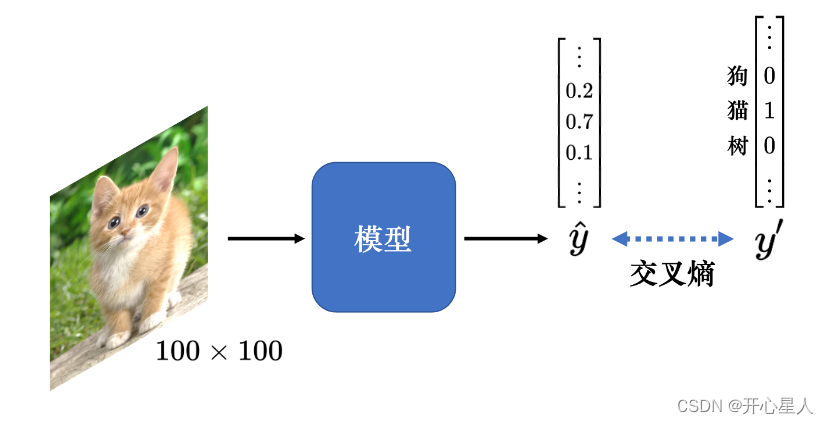
模型的目标是分类,因此可将不同的分类结果表示成不同的独热向量 y'。模型的输出通过 softmax 以后,输出是 ˆy。我们希望 y′ 和 ˆy 的交叉熵越小越好。
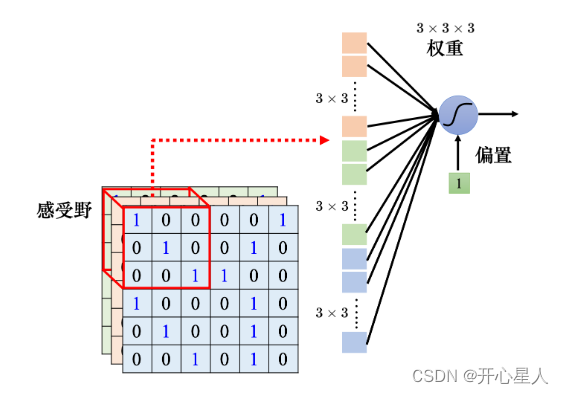
感受野
对一个图像识别的类神经网络里面的神经元而言,它要做的就是检测图像里面有没有出现一些特别重要的模式,这些模式是代表了某种物体的。比如有三个神经元分别看到鸟嘴、眼睛、鸟爪 3 个模式,这就代表类神经网络看到了一只鸟。
卷积神经网络会设定一个区域,即感受野(receptive field),每个神经元都只关心自己的感受野里面发生的事情,感受野是由我们自己决定的。
卷积核
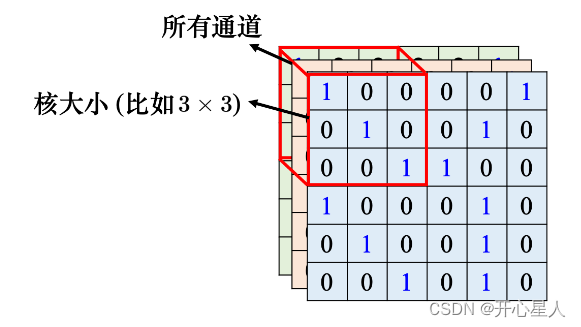
一般同一个感受野会有一组神经元去守备这个范围,比如 64 个或者是 128 个神经元去守备一个感受野的范围。图像里面每个位置都有一群神经元在检测那个地方,有没有出现某些模式
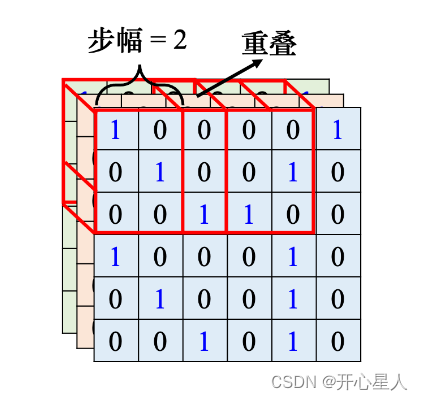
把左上角的感受野往右移一个步幅,就制造出一个新的守备范围,即新的感受野。移动的量称为步幅,步幅是一个超参数。因为希望感受野跟感受野之间是有重叠的,所以步幅往往不会设太大,一般设为 1 或 2。
Q: 为什么希望感受野之间是有重叠的呢?
A: 因为假设感受野完全没有重叠,如果有一个模式正好出现在两个感受野的交界上面,就没有任何神经元去检测它,这个模式可能会丢失,所以希望感受野彼此之间有高度的重叠。如令步幅 = 2,感受野就会重叠。
共享参数
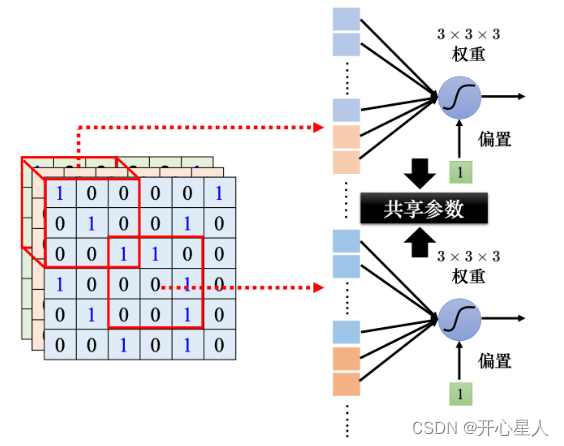
同样的模式可能会出现在图像的不同区域。比如检测鸟嘴的神经元做的事情是一样的,只是它们守备的范围不一样。如果不同的守备范围都要有一个检测鸟嘴的神经元,参数量会太多了。
所以可以让不同感受野的神经元共享参数,也就是做参数共享。所谓参数共享就是两个神经元的权重完全是一样的
卷积层
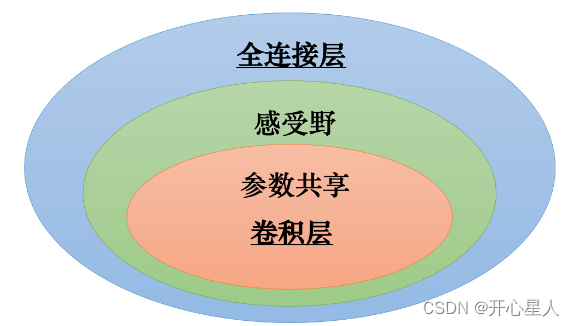
感受野加上参数共享就是卷积层(convolutional layer),用到卷积层的网络就叫卷积神经网络。卷积神经网络的偏差比较大。但模型偏差大不一定是坏事,因为当模型偏差大,模型的灵活性较低时,比较不容易过拟合。
卷积层是专门为图像设计的,感受野、参数共享都是为图像设计的
多卷积层
每个感受野都只有一组参数而已,这些参数称为滤波器。
一个卷积层里面就是有一排的滤波器,每个滤波器都是一个 3 × 3 × 通道,其作用是要去图像里面检测某个模式
卷积层是可以叠很多层的,第 2 层的卷积里面也有一堆的滤波器,每个滤波器的大小设成 3 × 3。其高度必须设为 64,因为滤波器的高度就是它要处理的图像的通道。(这个 64 是前一个卷积层的滤波器数目,前一个卷积层的滤波器数目是 64,输出以后就是 64 个通道。)
如果滤波器的大小一直设 3 × 3,会不会让网络没有办法看比较大范围的模式呢?
A:不会。如图 4.23 所示,如果在第 2 层卷积层滤波器的大小一样设 3 × 3,当我们看第 1 个卷积层输出的特征映射的 3 × 3 的范围的时候,在原来的图像上是考虑了一个5 × 5 的范围。虽然滤波器只有 3 × 3,但它在图像上考虑的范围是比较大的是 5 × 5。因此网络叠得越深,同样是 3 × 3 的大小的滤波器,它看的范围就会越来越大。所以网络够深,不用怕检测不到比较大的模式。
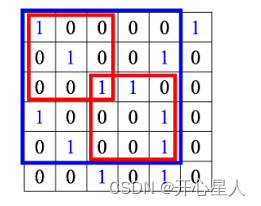
下采样和汇聚
把一张比较大的图像做下采样,把图像偶数的列都拿掉,奇数的行都拿掉,图像变成为原来的 1/4,但是不会影响里面是什么东西。
汇聚被用到了图像识别中。汇聚没有参数,所以它不是一个层,它里面没有权重,它没有要学习的东西,汇聚比较像 Sigmoid、ReLU 等激活函数。
汇聚有很多不同的版本:最大汇聚在每一组里面选一个代表,选的代表就是最大的一个;平均汇聚是取每一组的平均值。
做完卷积以后,往往后面还会搭配汇聚。汇聚就是把图像变小。做完卷积以后会得到一张图像,这张图像里面有很多的通道。做完汇聚以后,这张图像的通道不变。
一般在实践上,往往就是卷积跟汇聚交替使用,可能做几次卷积,做一次汇聚。比如两次卷积,一次汇聚。不过汇聚对于模型的性能可能会带来一点伤害。近年来图像的网络的设计往往也开始把汇聚丢掉,它会做这种全卷积的神经网络,整个网络里面都是卷积,完全都不用汇聚。汇聚最主要的作用是减少运算量,通过下采样把图像变小,从而减少运算量。
CNN
经典图像识别网络:
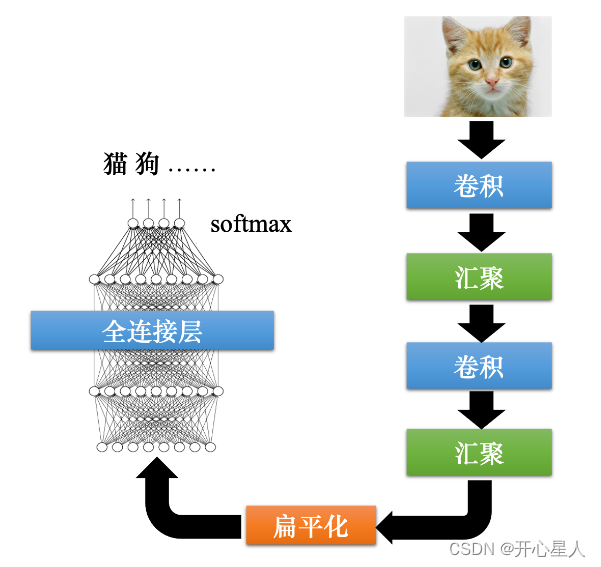
输入层:输入图像等信息
卷积层:用来提取图像的底层特征
池化层(汇聚):防止过拟合,将数据维度减小
全连接层:汇总卷积层和池化层得到的图像的底层特征和信息
输出层:根据全连接层的信息得到概率最大的结果