1、数据变换
数据变换,字面意思,就是将我们在实际项目中获取的数据进行相应的操作,方便后期处理。数据变换的方法很多,例如归一化、标准化等。
为什么要进行数据变换?(1)我们采集到的数据,可能存在机器学习无法识别的格式,尺寸等。在神经网络中,大部分的模型对输入图像格式有相应的要求。(2)采集到的数据内容太多,也可以理解为占用内存大,在处理的过程中会影响运行的效率。(3)采集到的数据包含其他影响元素,比如噪音等。
此模块用于通用数据增强,其中一部分增强操作是用C++实现的,具有较好的高性能,另一部分是基于Python实现,使用了NumPy模块作为支持。
2、Transforms
MindSpore提供不同种类的数据变换(Transforms),配合数据处理Pipeline来实现数据预处理。所有的Transforms均可通过map方法传入,实现对指定数据列的处理。
mindspore.dataset提供了面向图像、文本、音频等不同数据类型的Transforms,同时也支持使用Lambda函数。
3、安装相应库
常用的模块导入方法。
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset4、Common Transform
mindspore.dataset.transforms.Compose(transforms)
将多个数据增强操作组合使用。
【参数】
- transforms (list) - 一个数据增强的列表。
以Mnist数据集为例。
image, label = next(train_dataset.create_tuple_iterator())
#next(),它通过调用其next ()方法从迭代器中检索下一个项目。
#如果给定了默认值,则在迭代器耗尽返回此默认值,否则会引发StopIteration。 该方法可用于从文件对象读取下一个输入行。
# next(iterator[,default])
# 参数
# iterator − 要读取行的文件对象
# default − 如果迭代器耗尽则返回此默认值。 如果没有给出此默认值,则抛出 StopIteration 异常
print(image.shape)【运行结果】

composed = transforms.Compose(
[
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=(0.1307,), std=(0.3081,)),
vision.HWC2CHW()
]
)
train_dataset = train_dataset.map(composed, 'image')
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape)【运行结果】

5、Vision Transform
mindspore.dataset.vision模块提供一系列针对图像数据的Transforms。在Mnist数据处理过程中,使用了Rescale、Normalize和HWC2CHW变换。
5.1 Rescale
mindspore.dataset.vision.Rescale(rescale , shift)
基于给定的缩放和平移因子调整图像的像素大小。输出图像的像素大小为:output = image * rescale + shift。
【参数】
-
rescale (float) - 缩放因子。
-
shift (float) - 平移因子。
使用numpy随机生成一个像素值在0, 255的图像,将其像素值进行缩放。
random_np = np.random.randint(0, 255, (48, 48), np.uint8)
random_image = Image.fromarray(random_np)
#Image.fromarray(obj, mode = L)
#obj (numpy.ndarray): 一个二维numpy数组, 表示要转换为图像的数组。
#mode (str): 一个字符串, 表示输出图像的模式。
#"L" (灰度图), "RGB" (彩色图), "CMYK" (Cyan, Magenta, Yellow, blacK)。
print(random_np)【运行结果】

根据运行结果可以看出,构造了一个48*48的图像。
rescale = vision.Rescale(1.0 / 255.0, 0)
rescaled_image = rescale(random_image)
print(rescaled_image)【运行结果】

对比上面构造的图像,可以发现原图像的像素值为0-255,通过Rescale后,像素值为0-1,每个像素值都除以255。
5.2 Normalize
mindspore.dataset.vision.Normalize(mean , std , is_hwc=True)
根据均值和标准差对输入图像进行归一化。此处理将使用以下公式对输入图像进行归一化:
outputchannel = (inputchannel - meanchannel) / stdchannel,
其中 channel 代表通道索引,channel >= 1。
【参数】
-
mean (sequence) - 图像每个通道的均值组成的列表或元组。平均值必须在 0.0, 255.0 范围内。
-
std (sequence) - 图像每个通道的标准差组成的列表或元组。标准差值必须在 (0.0, 255.0] 范围内。
-
is_hwc (bool, 可选) - 表示输入图像是否为HWC格式,
True为HWC格式,False为CHW格式。默认值:True。bool值,输入图像的格式。True为(height, width, channel),False为(channel, height, width)。normalize = vision.Normalize(mean=(0.1307,), std=(0.3081,))
normalized_image = normalize(rescaled_image)#调用上面的图像,需要从上运行下来。
print(normalized_image)
【运行结果】

5.3 HWC2CHW
HWC格式是指按照高度、宽度和通道数的顺序排列图像尺寸的格式。125*125*3的RGB图像为125,125,3,125(h)*125(W)的3通道图像。
CHW格式是指按照通道数、高度和宽度的顺序排列图像尺寸的格式。3*125*125的RGB图像为3,125,125,3通道125(h)*125(W)的图像。
HWC2CHW变换用于转换图像格式。在不同的硬件设备中可能会对(height, width, channel)或(channel, height, width)两种不同格式有针对性优化。MindSpore设置HWC为默认图像格式,在有CHW格式需求时,可使用该变换进行处理。
hwc_image = np.expand_dims(normalized_image, -1)
hwc2chw = vision.HWC2CHW()
chw_image = hwc2chw(hwc_image)
print(hwc_image.shape, chw_image.shape)【运行结果】

6、Text Transforms
mindspore.dataset.text模块提供一系列针对文本数据的Transforms。与图像数据不同,文本数据需要有分词(Tokenize)、构建词表、Token转Index等操作。这里简单介绍其使用方法。
首先定义三段文本,作为待处理的数据,并使用GeneratorDataset进行加载。
texts = ['Welcome to Beijing']
test_dataset = GeneratorDataset(texts, 'text')6.1 PythonTokenizer
mindspore.dataset.text.PythonTokenizer(tokenizer)
使用用户自定义的分词器对输入字符串进行分词。
【参数】
-
tokenizer (Callable) - Python可调用对象,要求接收一个string参数作为输入,并返回一个包含多个string的列表作为返回值。
def my_tokenizer(content):
return content.split()str.split(str="",num=string.count(str))[n]
函数拆分字符串。通过指定分隔符对字符串进行切片,
并返回分割后的字符串列表(list)
str:表示为分隔符,默认为空格,但是不能为空('')。若字符串中没有分隔符,则把整个字符串作为列表的一个元素
num:表示分割次数。如果存在参数num,则仅分隔成 num+1 个子字符串,并且每一个子字符串可以赋给新的变量。默认为 -1, 即分隔所有。
[n]:表示选取第n个分片
test_dataset = test_dataset.map(text.PythonTokenizer(my_tokenizer))
print(next(test_dataset.create_tuple_iterator()))
【运行结果】

6.2 Lookup
Lookup为词表映射变换,用来将Token转换为Index。在使用Lookup前,需要构造词表,一般可以加载已有的词表,或使用Vocab生成词表。这里我们选择使用Vocab.from_dataset方法从数据集中生成词表。
mindspore.dataset.text.Lookup(vocab , unknown_token=None , data_type=mstype.int32)
根据词表,将分词标记(token)映射到其索引值(id)。
【参数】
-
vocab (Vocab) - 词表对象,用于存储分词和索引的映射。
-
unknown_token (str, 可选) - 备用词汇,用于要查找的单词不在词汇表时进行替换。 如果单词不在词汇表中,则查找结果将替换为 unknown_token 的值。 如果单词不在词汇表中,且未指定 unknown_token ,将抛出运行时错误。默认值:
None,不指定该参数。 -
data_type (mindspore.dtype, 可选) - Lookup输出的数据类型。默认值:
mstype.int32。vocab = text.Vocab.from_dataset(test_dataset)
print(vocab.vocab())
【运行结果】

生成词表后,可以配合map方法进行词表映射变换,将Token转为Index。
test_dataset = test_dataset.map(text.Lookup(vocab))
print(next(test_dataset.create_tuple_iterator()))【运行结果】

6.3 Lambda Transforns
Lambda函数是一种不需要名字、由一个单独表达式组成的匿名函数,表达式会在调用时被求值。Lambda Transforms可以加载任意定义的Lambda函数,提供足够的灵活度。在这里,我们首先使用一个简单的Lambda函数,对输入数据乘2:
test_dataset = GeneratorDataset([1, 2, 3], 'data', shuffle=False)
test_dataset = test_dataset.map(lambda x: x * 2)
print(list(test_dataset.create_tuple_iterator()))【运行结果】
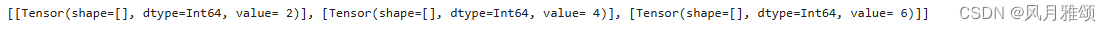
可以看到map传入Lambda函数后,迭代获得数据进行了乘2操作。也可以定义较复杂的函数,配合Lambda函数实现复杂数据处理:
def func(x):
return x * x + 2
test_dataset = test_dataset.map(lambda x: func(x))
print(list(test_dataset.create_tuple_iterator()))【运行结果】

