一、背景
云文档转HTML邮件
基于公司内部的飞书办公套件,早在去年6月,我们就建设了将飞书云文档转译成HTML邮件的能力,方便同学们在编写邮件文档和发送邮件时,都能有较好的体验和较高的效率。
当下问题
要被邮件客户端识别,飞书云文档内容需要转译成HtmlEmail格式,该格式为了兼容各种版本的邮箱客户端(特别是Windows Outlook),对于现代HTML5和CSS3的很多特性是不支持的,飞书云文档的多种富文本块格式都需要转译,且部分格式完全不支持,造成编辑和预览发送不一致的情况。
因此,我们对转译工具做了一次大改版和升级,对大部分常用文档块做了高度还原。
实现效果
经过我们的不懈努力,最终实现了较为不错的还原效果:

二、系统架构改版
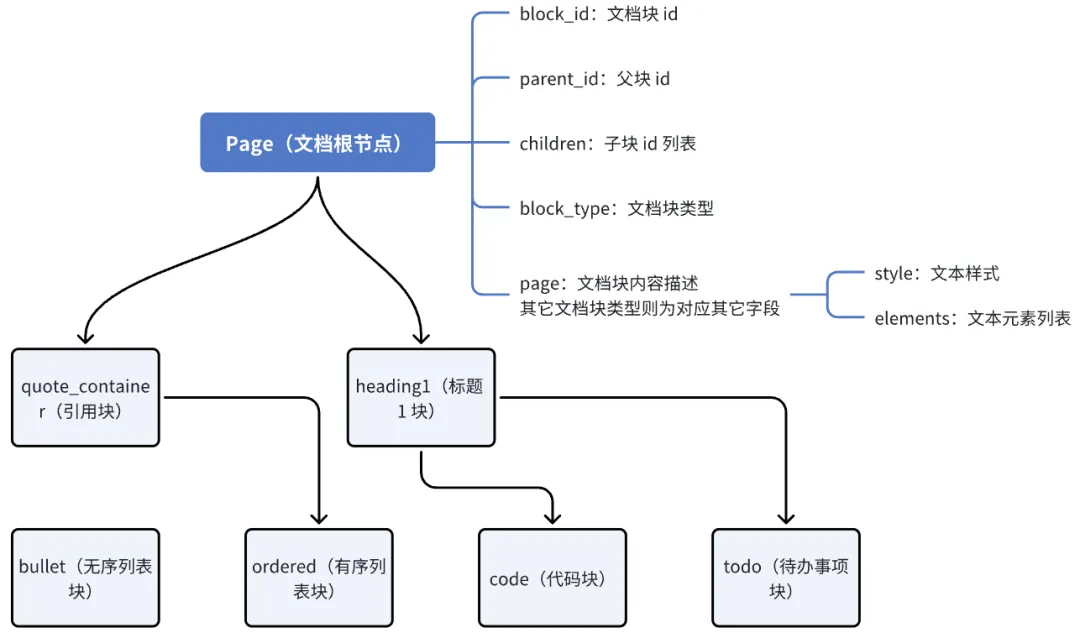
飞书云文档结构
在展开我们如何做升级之前,先要简单了解下飞书云文档的信息结构(详情可参考官方API),在此仅做简单阐述。
TypeScript简要定义,一个平铺的文档块数组,根据block_id和parent_id确定各块的父子关系,从而形成一个树:
{
/** 文档块唯一标识。*/
block_id: string;
/** 父块 ID。*/
parent_id: string;
/** 子块 ID 列表。*/
children: string[];
/** 文档块类型。*/
block_type: BlockType;
/** 页面块内容描述。*/
page?: { ... };
/** 文本块内容描述。*/
text?: { ... };
/** 标题 1 块内容描述。*/
heading1?: { ... };
/** 有序列表块内容描述。*/
ordered?: { ... };
/** 表格块内容描述。*/
table?: { ... };
// 总计 43 个块定义。
...
}[];我们用思维导图简单举例,整个文档块的树结构大致是这样的,有些块根据缩进递进,会形成父子关系,有些块天然就会成为父块(比如表格、引用等):
旧版架构
那么我们初版转译工具是怎么做的呢,比较遗憾的是,由于当时需求的还原度诉求较低,我们的代码主要是复用现有部分实现,整体的架构设计可以用一个词概括,基本是面向过程编程:
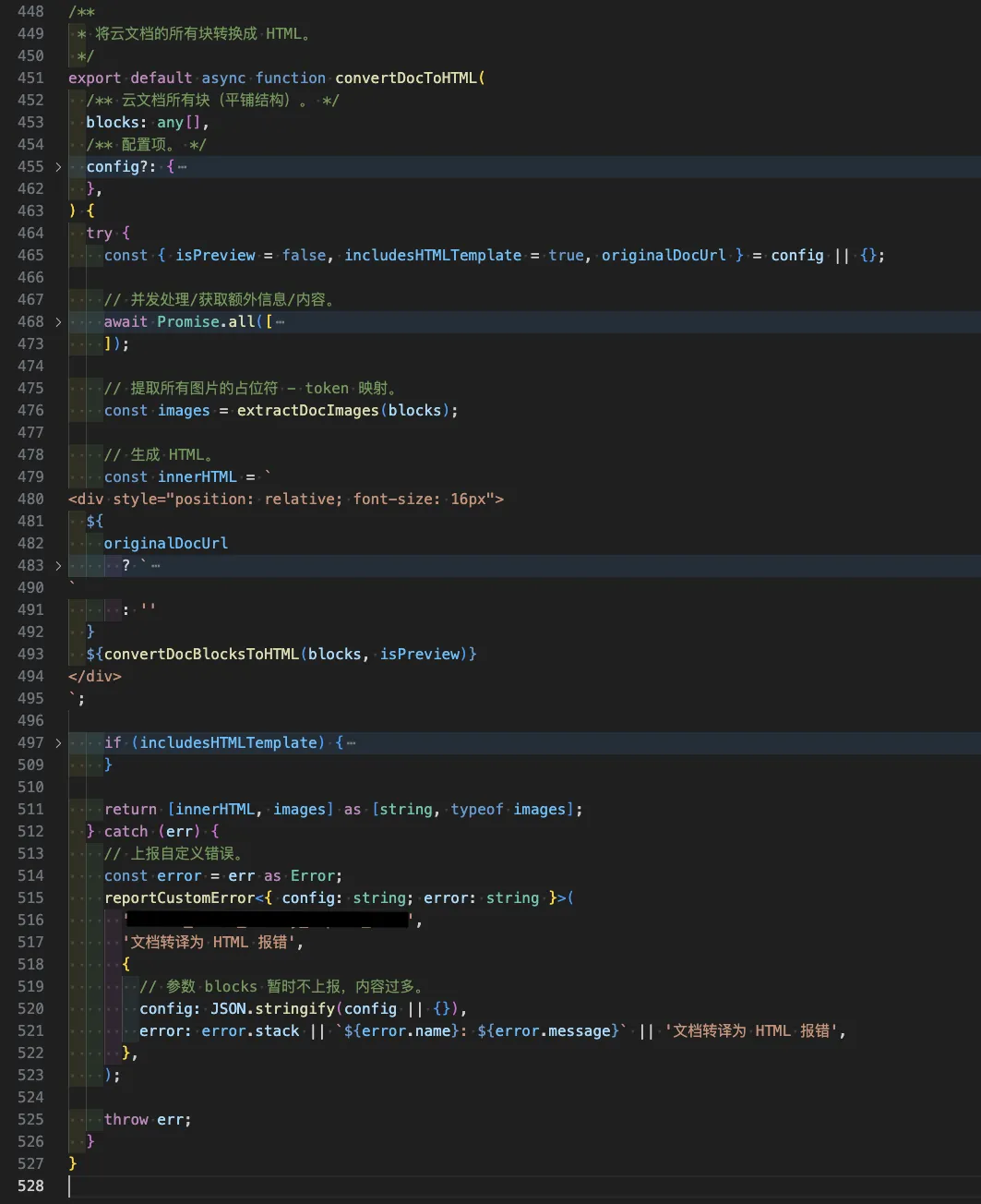
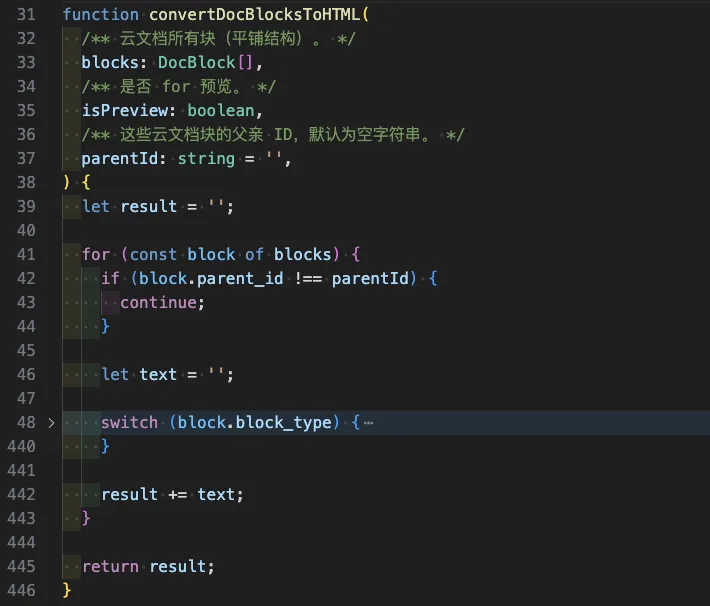
上方的图:经过了一些抽取和封装,主流程核心代码仍有528行;下方的图:文档块核心转译渲染代码,基本没有写任何还原样式,通过Switch、Case来一个个渲染文档块。
新版架构设计
这次我们痛定思痛,势必要将转译工具的转译效果做到尽可能还原,也有了多位同学一起投入。因此首要思考和急需解决的问题来了:在老旧的架构下,如何才能做好代码扩展、多人协同、高效样式编写以及样式还原?
IoC 与DI
是的,几乎一刹那,凭借过往丰富的多人协同以及项目经验,很快我们就想到了,这个事需要基于IoC的设计原则,并通过DI的方式来实现。
那么什么是IoC和DI呢,根据维基百科的解释:控制反转(Inversion of Control,缩写为IoC),是面向对象编程中的一种设计原则,可以用来减低计算机代码之间的耦合度,其中最常见的方式叫做依赖注入(Dependency Injection,缩写为DI)。
这么说可能有点抽象,我们可以看下新版的架构设计,从中便能窥见其精妙:
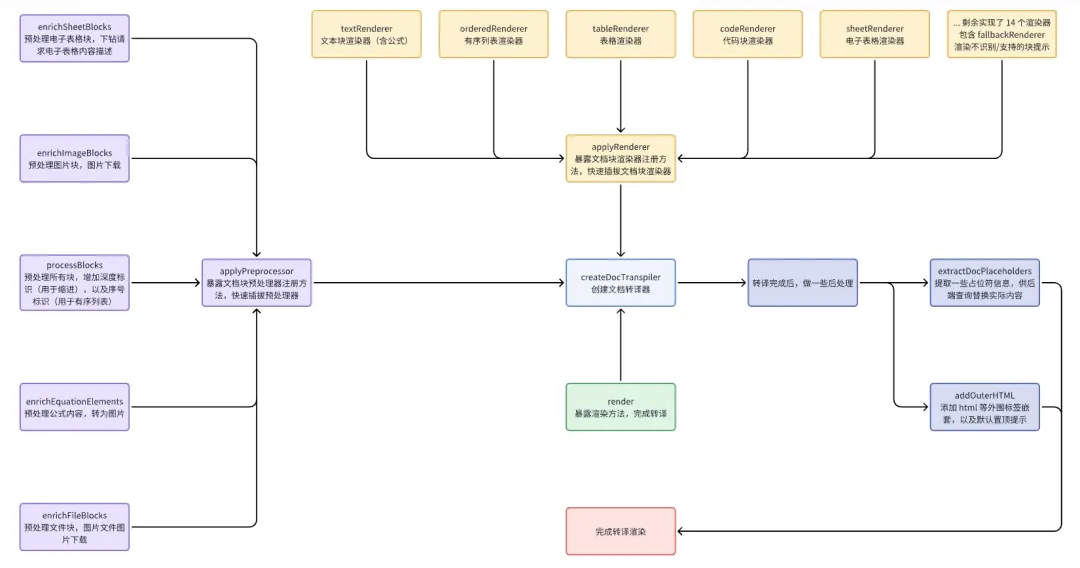
可以看到,关键的文档块预处理和渲染器,在该架构中是反向依赖核心的createDocTranspiler了,与我们常识中的理解(文档转译渲染依赖各个块的预处理和渲染器)是相反的,这就是控制反转(IoC),通过这样的依赖倒置,我们能够把多人协同过程中,由各个同学负责开发的预处理器和渲染器的开发调试解耦出去,互不影响、互不依赖,且合码过程中基本没有代码冲突,大大提效了多人协同合作开发。同时由于实现的方式是依赖注入(DI),或者说注册,未来我们想要支持更加深水区的文档块,比如「画板」、「文档小组件」等,可以很方便地注册新的预处理器和渲染器,做增量且解耦的代码开发;如果想要取消对某一个文档块的渲染,直接unregister即可,由此也实现了文档块渲染的快速插拔和极高的可拓展性。
整个转译主干代码如下:
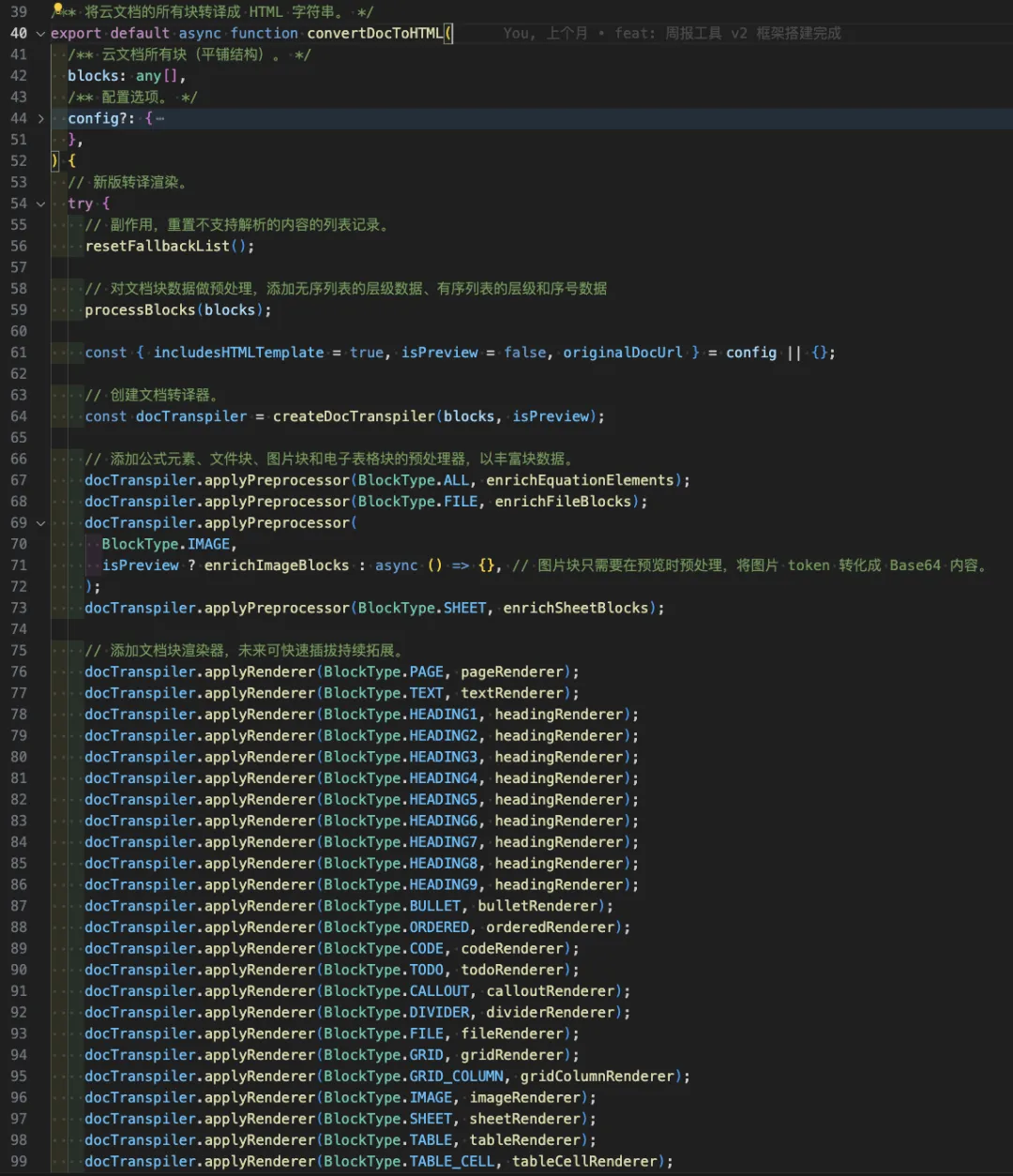
创建转译器,注册预处理器,注册渲染器
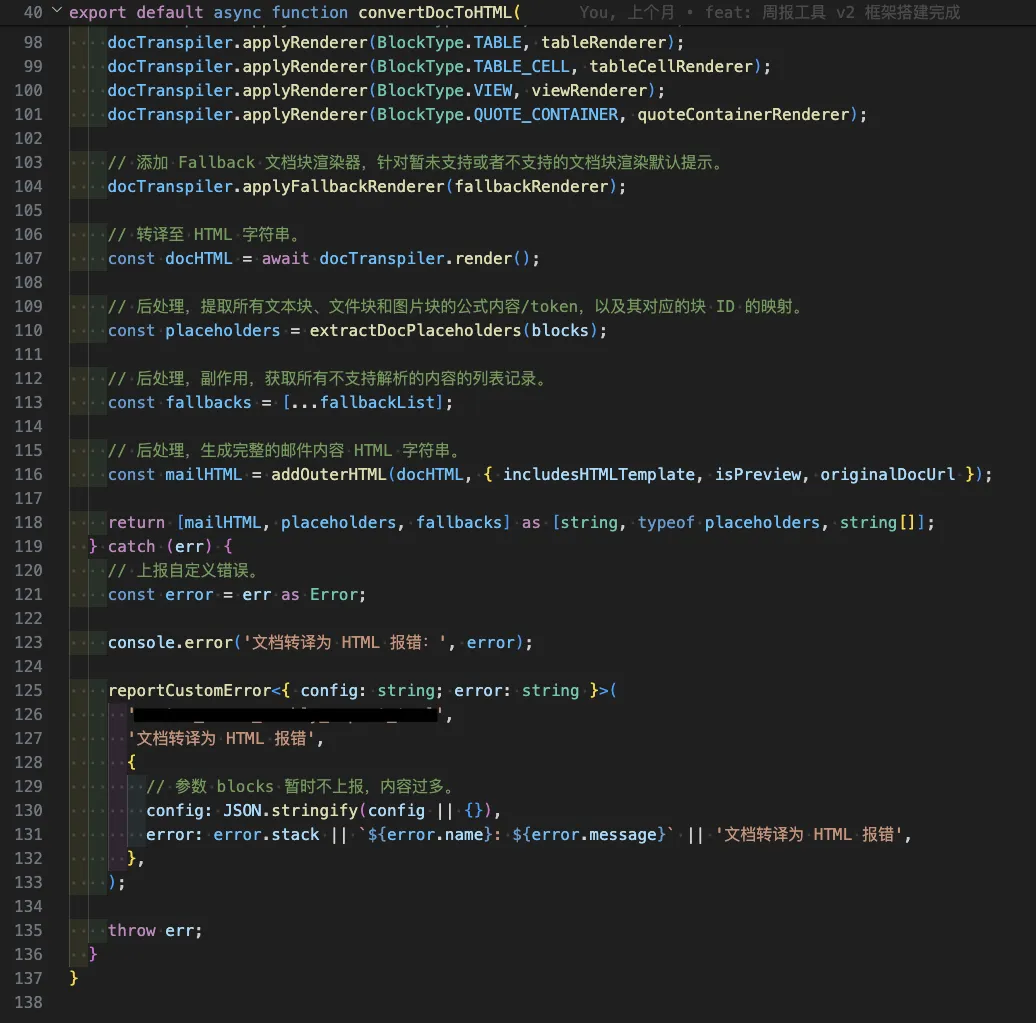
转译渲染,后处理,完成渲染。代码行数缩减到只有138行。
函数式编程
接下来我们将目光聚焦到核心函数createDocTranspiler中,这块是IoC架构的核心实现,根据维基百科描述,IoC是面向对象编程中的一种设计原则,那么我们真的是用面向对象的编程方式吗?
显然不是,我们是高标准的前端同学,在JavaScript编程中,面向对象编程显然不是社区推崇的设计原则,以React框架为例,早在React 16.8版本,就推出了函数组件和Hooks编程,以取代较为臃肿的类组件编程,这些都是前端老生常谈的理念了,大家可以去Google深入学习函数式编程理念,在此不再赘述。
这里说一下为什么核心代码createDocTranspiler我要用函数式编程,说一下我的理解:第一是非常优雅,用起来很舒服;第二是得益于JavaScript函数闭包,一些局部(想要private化)的变量或者方法,直接在函数内声明和定义即可,不用担心像类一样会暴露出去(尽管TS有private关键字,但只是约束,不代表你不能用);第三是简单,无需维护类的实例,若有主动销毁场景,返回的结构中暴露销毁函数即可。
整个核心代码如下:
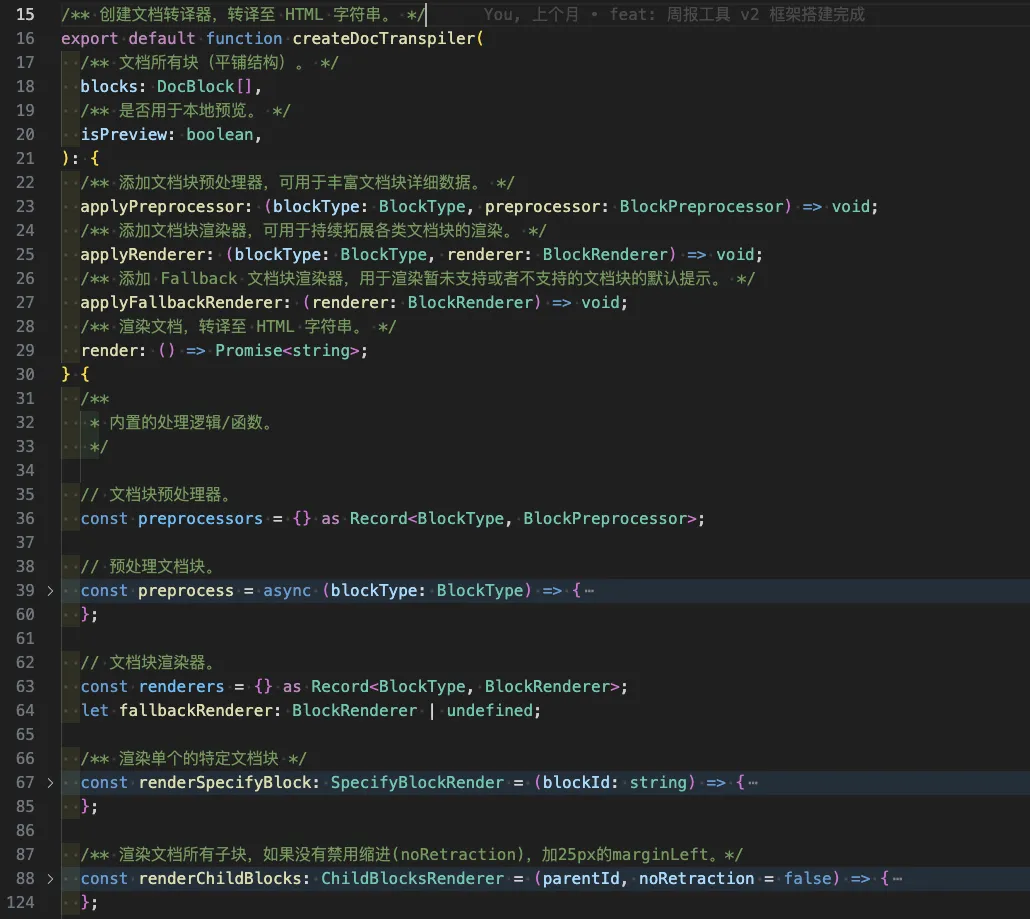
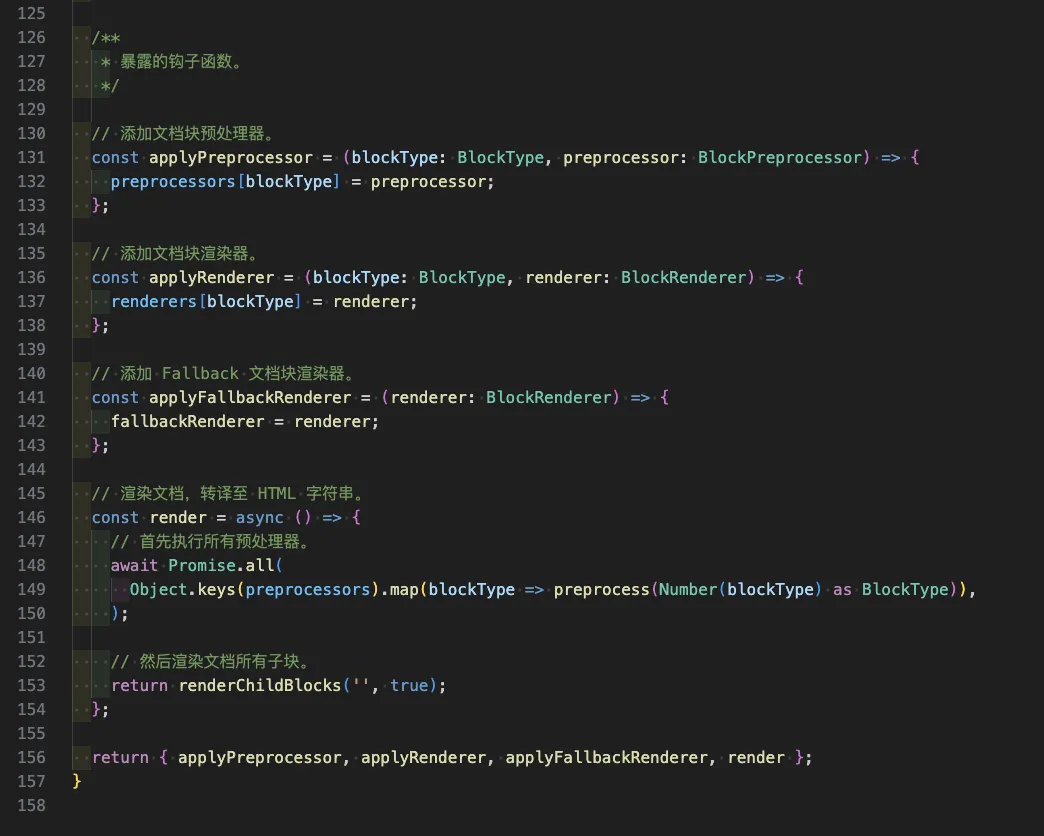
上方的图:内置的变量和函数,用于存储各种预处理器和渲染器,并实现文档树的递归渲染;下方的图:返回并暴露出去的函数,用于注册各种预处理器、渲染器,以及转译渲染。整个核心代码只有158行,非常精炼。
"CSS-in-JS"
然后再来说一下如此大量的样式还原工作,我们是如何实现的。由于我们要把文档树转译成最终的一个完整的HTML字符串,在模板字符串中写内联样式(style="width: 100px;...")会非常痛苦,代码可读性会很差,开发调试的效率也会很低。
为了解决这个问题,我们立即想到了React CSSProperties的写法,并调研了一下它的源码实现,其实就是将CSSProperties中的驼峰属性名,转换成内联样式中连字符属性名,并额外处理了Webkit、ms、Moz、O等浏览器属性前缀,同时针对number 类型的部分属性的值,转换时自动加上了px后缀。详细代码如下:
// 样式处理工具函数库。
import { CSSProperties } from 'react';
/* 是否是,值可能是数字类型,且不需要指定 px 为单位的 CSSProperties 属性。*/
const isUnitlessNumber: Record<string, boolean> = {
// ...
fontWeight: true,
lineClamp: true,
lineHeight: true,
// ...
// SVG-related properties.
fillOpacity: true,
floodOpacity: true,
stopOpacity: true,
// ...
};
// 各浏览器 CSS 属性名前缀。
const cssPropertyPrefixes = ['Webkit', 'ms', 'Moz', 'O'];
// 针对 isUnitlessNumber,填充各浏览器 CSS 属性名前缀。
Object.keys(isUnitlessNumber).forEach(property => {
cssPropertyPrefixes.forEach(prefix => {
isUnitlessNumber[`${prefix}${property.charAt(0).toUpperCase()}${property.substring(1)}`] =
isUnitlessNumber[property];
});
});
export { isUnitlessNumber };
/** 针对 CSSProperties 属性值,可能添加单位 px,并返回合法的值。*/
export function addCSSPropertyUnit<T extends keyof CSSProperties>(property: T, value: CSSProperties[T]) {
if (typeof value === 'number' && !isUnitlessNumber[property]) {
// 值是数字类型,且需要添加单位 px,则添加单位 px。
return `${value}px`;
}
return value;
}然后再编写createInlineStyles方法,入参即为Record<string, CSSProperties>大样式对象:
/* 将 CSSProperties 转为内联 style 字符串,e.g. { width: 100, flex: 1 } => style="width: 100px; flex: 1;"。*/
export function convertCSSPropertiesToInlineStyle(style: CSSProperties) {
const upperCaseReg = /[A-Z]/g;
const inlineStyle = Object.keys(style)
.map(
property =>
`${property.replace(
upperCaseReg,
matchLetter => `-${matchLetter.toLowerCase()}`,
)}: ${addCSSPropertyUnit(property as keyof CSSProperties, style[property])};`,
)
.join(' ');
if (inlineStyle) {
return `style="${inlineStyle}"`;
}
return '';
}
/** 根据输入的样式表(CSSProperties 格式),输出内联样式表(格式为 style="..." 的字符串),e.g. { container: { position: 'relative' }, title: { fontSize: 18 } } => { container: 'style="position: relative;"', title: 'style="font-size: 18px;"' }。*/
export function createInlineStyles<T extends string>(styles: { [P in T]: CSSProperties }) {
const inlineStyles = {} as { [P in T]: string };
Object.keys(styles).forEach(name => {
inlineStyles[name] = convertCSSPropertiesToInlineStyle(styles[name]);
});
return inlineStyles;
}至此架构优化的差不多了,整个项目组进入了高度协同、紧密沟通合作的开发中,整个开发过程其实并不是特别顺利,尤其是在对Windows Outlook邮箱客户端的支持上,各种样式兼容问题Case层出不穷,以至于我们的开发同学不得不去对邮箱HTML和CSS开发进行"考古"。
三、Outlook麻烦的兼容性问题
在改版系统架构后,我们先试着实现了一版有序列表和无序列表的解决方案,结果在测试中,我们得到了出乎所有人意料之外的结果:

原本文档的样子

网页版Outlook中的样子

Windows的Outlook中的样子
在网页版Outlook中,通过开发工具可以看到每一项的justify-content样式消失了,而在Windows Outlook中,基本没什么样式还留着了。
Outlook糟糕的兼容性
我们之前从未编写过HTML邮件,也就完全没考虑过各个邮件客户端对HTML的兼容性问题。在网上找到一些资料后,我们被Outlook对HTML的兼容性之差所震惊。
首先,Windows Outlook并没有一个自己的HTML渲染引擎,而是使用Word的渲染引擎去解析HTML。它不支持HTML5和CSS3,也就是说我们为了保证最大的兼容性,所有的飞书文档样式还原和文本解析都要用极为陈旧的技术去实现。
据官方文档所示,display、position、max-width、max-height等样式全都不兼容。
总的来说:
-
不能使用任何CSS3新特性,比如flex、grid等;
-
和布局有关的组件,只能使用table来进行布局;
-
只能使用行内样式;尽量只使用table、tr、td、span、img、a、div这几个标签;
-
只有div的margin会偶尔被正确地识别,其它标签都有可能让padding和margin消失;
-
如果一个div内部含有table,它的margin会让table背景色和边框混乱;无法使用line-height;
-
小心使用div,Outlook有时候会把他转换为p,具体逻辑还不明确;
-
图片唯一能够控制大小的方法就是使用img标签上的width属性和height属性。
技术上的限制如此苛刻,就意味着在后面的开发中,我们还会遇到很多特定情况的兼容性问题。在这种情况下,为了最大限度地保证兼容性,我们决定及时止损,重新设计后面各个组件的实现方式,并将无序列表和有序列表的渲染方法推倒重来,再次编写。
四、各类型文档块的还原
首先,我们将转译工具原有的「一级标题」到「九级标题」美化为接近飞书文档的样子。我们需要梳理下将会获得的数据,来看看如何将它们转译为HTML。
标题块(heading 1-9)
标题组件应该是实现难度最低的一个,一个标题组件的数据结构如下:
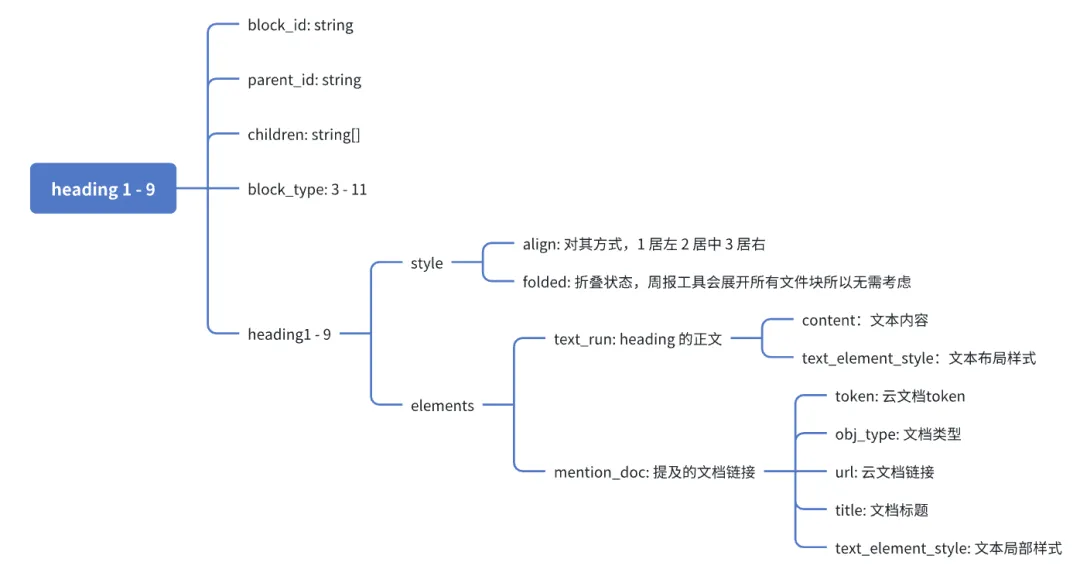
原版实现方式
在原版的转译工具中,我们编写了通用方法来处理文本内容的下划线、删除线、斜体、粗体、高亮色等进行处理,生成行间元素,然后在外部框上h1-h9。最终在后面加上它的子节点渲染结果。
新版实现方式
由于默认的heading样式无法满足还原度,且并没有处理对齐方式。我们将使用
制作heading组件,自行添加样式来还原飞书文档:
case BlockType.HEADING1: {
const blockH1 = block as HeadingBlock;
const align = blockH1.heading1.style.align;
const styles = makeHeadingStyles({ type: block.block_type, align });
text += `<div ${styles.headingStyles}>${transpileTextElements(
blockH1.block_id,
blockH1.heading1.elements,
isPreview,
)}</div>`;
// renderChildBlocks 方法来渲染当前块的所有子节点。
text += renderChildBlocks(blockH1.block_id);
break;
}其中makeHeadingStyles是我们生成样式的方法,这样可以将各个组件的样式写成配置项,方便后续修改。新的样式中,我们着重对行高、行距、下划线距文字距离、对齐方式进行了调整:
// makeHeadingStyles 方法的部分截取。
export function makeHeadingStyles(params: MakeHeadingStylesParams) {
const { type, align } = params;
const basicStyle: CSSProperties = {
lineHeight: 1.4,
letterSpacing: '-.02em',
fontWeight: 500,
color: '#1f2329',
textAlign: getTextAlignStyle(align || 1),
};
let headingStyles: CSSProperties = {};
switch (type) {
case BlockType.HEADING1:
headingStyles = {
fontSize: 26,
marginTop: 26,
marginBottom: 10,
...basicStyle,
};
break;
// 对Heading2-9的样式进行定义...
// ......
// 将样式对象转成行间样式字符串。
return createInlineStyles<'headingStyles'>({ headingStyles: headingStyles });
}最后发邮件,测试一下生成的HTML的效果:

改版之前

改版之后
无序列表(bullet)与有序列表(ordered)
原版实现方式
列表的数据结构与标题块大致相同,在此不再赘述。在原来的转译工具中,我们使用原生的"ul"和"li"来直接渲染无序列表,"ol""li"来渲染有序列表。我们顺序遍历兄弟节点的列表,为连续的bullet文档块的前后加上"ul""/ul",连续的ordered块前后加上"ol"和"/ol"。列表中的每一项,则渲染成"li"。
由于原生"ul"和"ol"的marker样式较丑,我们无法使用伪类元素等手段改善它的样式,为了方便,我们这次改版将自己维护列表的层级关系。
新版实现方式
在飞书文档中,不同层级的列表,marker长得完全不同:

无序列表

有序列表
为了判断我们每个列表项要使用什么样的marker,首先我们需要对飞书给我们的数据进行预处理,为每个列表块标注它的层级和序号。
- 数据预处理器
由于飞书API没有提供有序列表的序号,这个序号用户又可以随便更改,所以我们的思路是:如果有序列表中间被非空文档块以外的文本块截断,序号则重新开始计算。具体方法如下:
/** 判断文本块是否为空白文本类型的快。*/
export function isEmptyTextBlock(block: DocBlockText | undefined) {
if (文档块的类型为text且不为空 || 文档块类型不为text) {返回false;}
else {返回true;}
}
/** 为每个文本块计算它到文本树根节点的深度,为有序列表块找到它的序号。*/
export function processBlocks(blocks: DocBlock[]) {
const blockDepths = {}; // 记录各节点距根节点的深度。
const blockOrder = {}; // 记录各节点在同类兄弟节点中的顺序,被其他类型的块打断的时候将重新计数。
function calcBlockFields(block: DocBlock, depth: number) {
blockDepths[block.block_id] = depth;
// 为有序列表找到它的序号。
if (文本块类型为 ordered) {
1. 找到同级兄弟节点列表 brotherBlocks 与同类型同级兄弟节点列表 similarBrotherBlocks;
2. 找到当前节点在上述两个列表中的索引 brotherBlocksIndex,similarBrotherBlocksIndex;
3. 找到兄弟节点列表中的前一个节点 prevBrotherBlock。以及同类兄弟列表的前一个节点 prevSimilarBrotherBlock;
if (当前节点是兄弟节点列表中的第一个节点 || 当前节点是同类兄弟节点列表中的第一个节点 || 前一个兄弟节点不是同类兄弟节点,且前一个兄弟节点是非空的文本块) {
blockOrder[block.block_id] = 1;
} else {
blockOrder[block.block_id] = 上一个同类兄弟的编号 + 1
}
}
递归处理子节点。如果当前节点的类型为 grid_column、tabel_cell、callout、quoter_container 的时候,深度重置为 1(calcBlockFields(childrenBlock, 1)),其他情况 calcBlockFields(childrenBlock, depth + 1);
}
从根节点开始递归处理。calcBlockFields(rootBlock, 0);
将记录的序号和深度(blockOrder, blockDepths)添加到每个节点中(block.depth, block.order);
}这样,每个列表项都知道了自己在文档中的层级,有序列表也知道了自己的序号。
由于原来的方法中完全没有处理过文本块的缩进,我们根据飞书缩进的规律,为普通的文本块(表格、栅格等以外的文本块)在渲染子节点时为子节点的容器添加25px的padding-left。
接下来我们使用一个通用的方法为有序列表和无序列表渲染它们的marker。
-
列表标号渲染器
/** 渲染列表的标签。*/
export const listMarkRender = (type: ListType, block: DocBlock) => {
const { depth = 1, order = 1 } = block;if (type === ListType.BULLET) { const styles = makeMarkerStyles(ListType.BULLET); let marker: string; marker = 按照深度,每三个一循环,依次为 '•'、'◦'、'▪'; return `<span ${styles.markContainerStyle}>${marker}</span>`; } else { const styles = makeMarkerStyles(ListType.ORDERED); let markerGenerator: (num: number) => number | string; markerGenerator = 按照深度,每三个一循环,依次为数字、数字转小写字母、数字转罗马数字; return `<span ${styles.markContainerStyle}>${markerGenerator(order)}.</span>`; }};
对于无序列表,标号每三层一循环,顺序为 '•'、'◦'、'▪'。对于有序列表,标号格式也是每三层一循环,顺序为阿拉伯数字、小写字母、罗马数字。
使用列表的标号渲染器渲染标号部分,然后简单的在
中将标号 和处理过样式的正文组合。
-
无序列表与有序列表渲染器
-
新版有序列表渲染器
- 渲染器:
const orderedRenderer: BlockRenderer = (block, isPreview, renderChildBlocks) => {
const orderedBlock = block as OrderedBlock;
const align = orderedBlock.ordered.style.align;
const styles = makeOrderedStyles(align);let text = '';
text +=<div ${styles.listWrapper}> ${listMarkRender(ListType.ORDERED, orderedBlock,)} <span ${styles.listContent}> ${transpileTextElements(orderedBlock.block_id, orderedBlock.ordered.elements, isPreview,)} </span> </div>;
text += renderChildBlocks(orderedBlock.block_id, false);return text;
};
-
-
无序列表渲染器
-
渲染器
const bulletRenderer: BlockRenderer = (block, isPreview, renderChildBlocks) => {
const bulletBlock = block as BulletBlock;
const align = bulletBlock.bullet.style.align;
const styles = makeBulletStyles(align);let text = '';
text +=<div ${styles.listWrapper}> ${listMarkRender(ListType.BULLET, bulletBlock,)} <span ${styles.listContent}>${transpileTextElements( bulletBlock.block_id, bulletBlock.bullet.elements, isPreview, )}</span> </div>;
text += renderChildBlocks(bulletBlock.block_id, false);return text;
};
-
-
最终呈现结果


可以看到,我们在满足使用的前提下以最高的兼容性比较完美的还原了飞书文档中的有序列表和无序列表。
待办事项
既然漂亮地还原了有序列表和无序列表,待办事项块就简单得多了。代办事项的具体的数据结构如下:
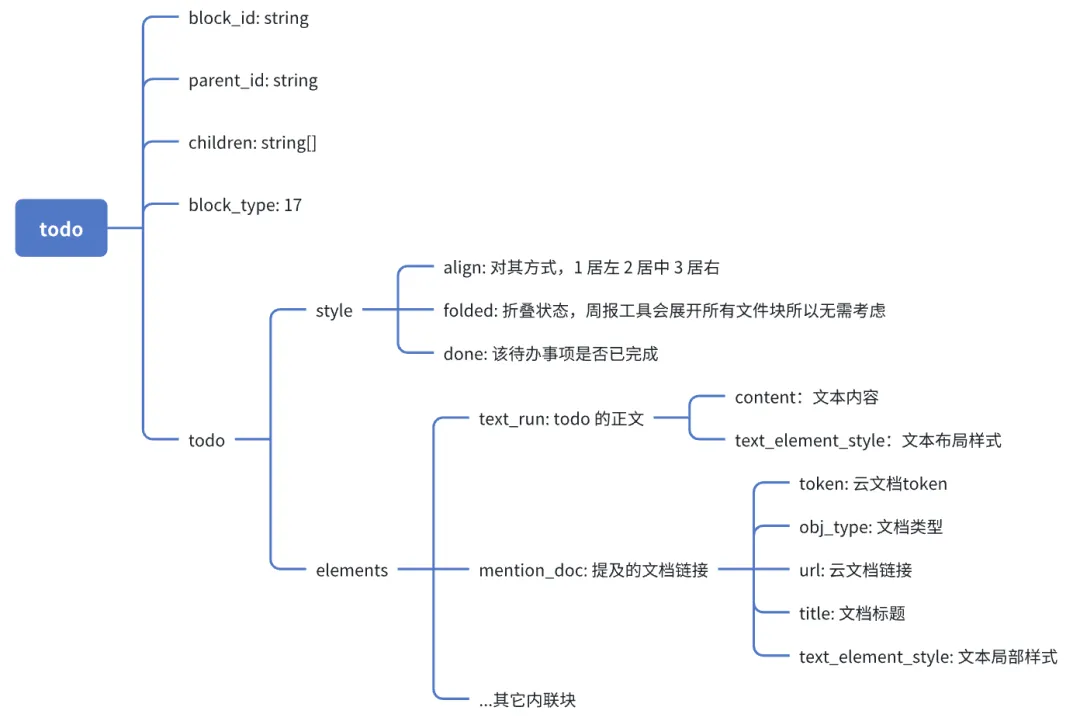
可以看到,待办事项的数据中包含了该条待办事项是否已完成的数据,从飞书文档的样式可以看出,已完成的条目会统一被划上删除线,并删除下划线样式。最终的渲染器和样式生成方法如下:
待办事项渲染器
-
渲染器:
const todoRenderer: BlockRenderer = (block, isPreview, renderChildBlocks, _blocks) => {
const todoBlock = block as TodoBlock;
const { align, done } = todoBlock.todo.style;
const originTodoElements = todoBlock.todo.elements;
const markerSrc = done ? '已完成标记图片地址' : '未完成标记图片地址';
const styles = makeTodoStyles(align || 1, done);const checkedTodoElements = cloneDeep(originTodoElements); checkedTodoElements.forEach(element => { 为所有文本元素去掉下划线,添加删除线 }); let text = ''; text += ` <div ${styles.todoWrapperStyles}> <img width="18" height="18" ${styles.todoMarkerStyles} src="${markerSrc}" alt="todo_mark"/> <span> </span> <span ${styles.todoContentStyles}>${transpileTextElements( todoBlock.block_id, done ? checkedTodoElements : originTodoElements, isPreview, )}</span> </div>`; text += renderChildBlocks(todoBlock.block_id, false); return text;};
最终呈现效果

表格(非电子表格)块
文档中另一个最重要的模块就是表格。表格是另一类比较特殊的文本块,他内部并不包含正文。整个表格实际上由三层文档块组合而成,它们的数据结构如下:
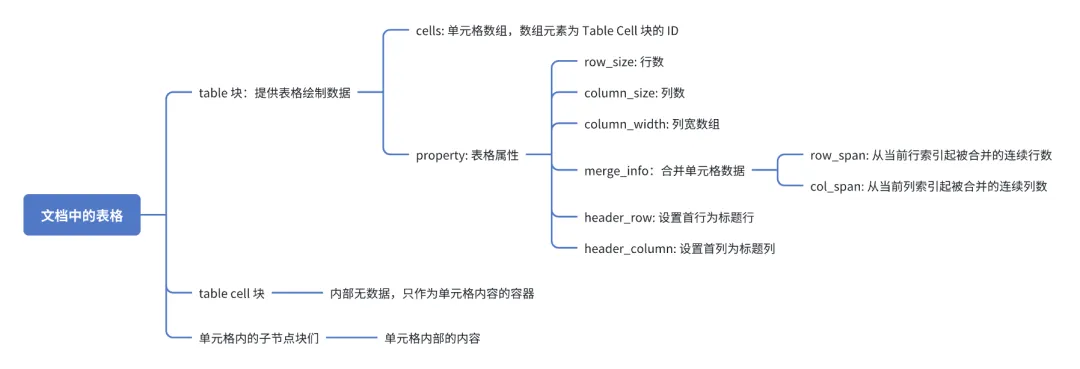
依据数据结构和我们的代码模式设计,我们需要使用嵌套的渲染器来实现表格的绘制。
表格渲染器(table块)
由于飞书API中清楚地提供了行数、列数以及列宽,我们可以较为轻松地绘制出大致的表格。这里的重点是要准确地处理合并单元格数据,将它们精准地使用在表格的每个 标签上。表格渲染器的代码如下:
-
渲染器:
const tableRenderer: BlockRenderer = (block, renderSpecifyBlock) => {
const blockTable = block as TableBlock;
const children = blockTable.table.cells;
const tableStyles = makeTableStyles();const { column_size, row_size, column_width, merge_info } = blockTable.table.property; // 计算出整个表格的整体宽度。 const totalWidth = column_width.reduce((acc, cur) => acc + cur, 0); let text = ` <div ${tableStyles.tableWrapperStyles}> <table width="${totalWidth}" ${tableStyles.tableStyles}> `; // 初始化单元格处理标记数组,记录哪些单元格已被处理过数据。 const processed = Array.from({ length: row_size }, () => Array(column_size).fill(false)); let mergeIndex = 0; // 追踪当前 merge_info 索引。 for (let i = 0; i < row_size; i++) { text += '<tr>'; for (let j = 0; j < column_size; ) { 从 merge_info[mergeIndex] 获取当前合并信息 col_span 与 row_span,确保 col_span 和 row_span 至少为 1; // 如果当前单元格未处理过,则进行处理。 if (!processed[i][j]) { const tDStyles = makeTDStyles(column_width[j]); const colspanAttr = col_span > 1 ? `colspan="${col_span}"` : ''; const rowspanAttr = row_span > 1 ? `rowspan="${row_span}"` : ''; text += ` <td valign="top" width="${column_width[j]}" ${colspanAttr} ${rowspanAttr} ${ tDStyles.tDStyles }> // 与之前的文档块直接渲染所有的子节点不同,表格需要在单元格内精准的渲染对应的 table cell 块,所以此处使用 renderSpecifyBlock 方法。 ${renderSpecifyBlock(children[i * column_size + j])} </td> `; // 更新处理标记数组,标记当前单元格及其被合并的单元格为已处理, for (let m = i; m < Math.min(i + row_span, row_size); m++) { for (let n = j; n < Math.min(j + col_span, column_size); n++) { processed[m][n] = true; } } j += col_span; // 跳过被合并的单元格。 mergeIndex += col_span; // 跳过被合并的单元格对应的 merge_info。 } else { j++; mergeIndex++; } } text += '</tr>'; } text += '</table></div>'; return text;};
为了处理合并单元格数据,我们维护了一个已处理标记数组processed,处理完一个单元格后,我们将当前单元格与被它合并的单元格都标记为已处理,来跳过他们的处理与渲染。这里需要特别注意,飞书文档的接口偶尔会返回错误的合并单元格数据:{ row_span: 0, col_span: 0 },这个现象已经反馈给飞书,我们在34-37行做了兼容处理。
为了最大限度的兼容性,我们坚持能用标签属性设置的样式,就不使用CSS来设置。与列表的渲染不同,在表格中我们没有像列表渲染一样先预处理数据再生成DOM字符串,而是使用了在遍历中边处理数据边生成DOM字符串的方法。
在表格的渲染中,我们没有像之前的代码一样使用renderChildBlocks把所有子文档块都渲染出来添加进HTML字符串中,而是使用了新的renderSpecifyBlock方法,给定block_id来渲染特定的子文档块。
单元格容器渲染器(table cell块)
单元格容器的渲染器则简单的多,他没有任何数据处理,只绘制一个容器用于承载内部的所有子节点,并在内部将单元格内的子节点渲染出来
-
渲染器:
const tableCellRenderer: BlockRenderer = (block, isPreview, renderChildBlocks, _blocks) => {
const styles = makeTableCellStyles();return ` <div ${styles.tableCellWrapperStyle}> ${renderChildBlocks(block.block_id, true)} </div>`;};
最终呈现效果
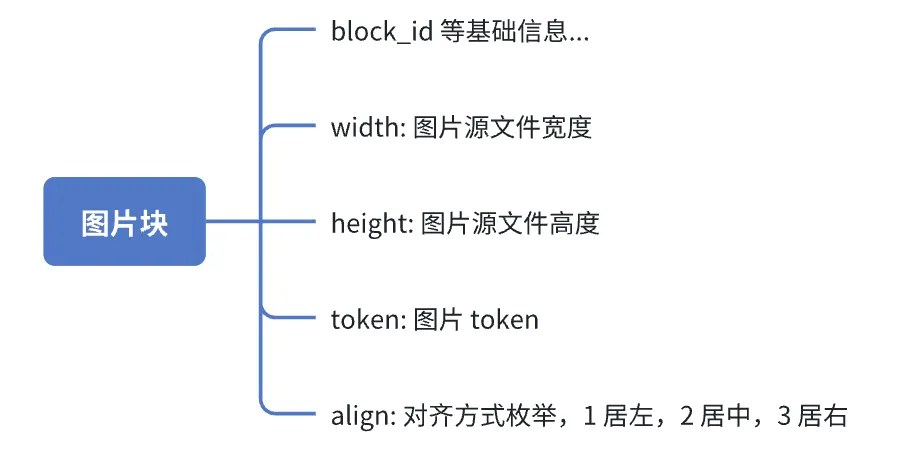
图片块
图片块理应也是一个很容易实现的文档块。但在实际处理过程中,由于飞书的API只提供图片源文件的宽高,并没有提供云文档中用户缩放过后的图片宽高,我们需要实现一个能满足绝大多数使用场景的图片缩放算法来尽可能还原文档中的图片样式。
图片块的数据结构如下:
限制图片大小
源文件的宽高一般都远大于图片在云文档中的实际宽高。我决定使用以下的方法来限制住图片在文档中的宽高:
-
若图片处于类似表格的文档块中,则宽度撑满父容器;
-
若图片不在类似表格的文档块中,则按照maxHeight: 780(限制最大高度避免长图过长),maxWidth: 820(飞书文档最大宽度),使用如下的算法来计算缩放后的图片大小:
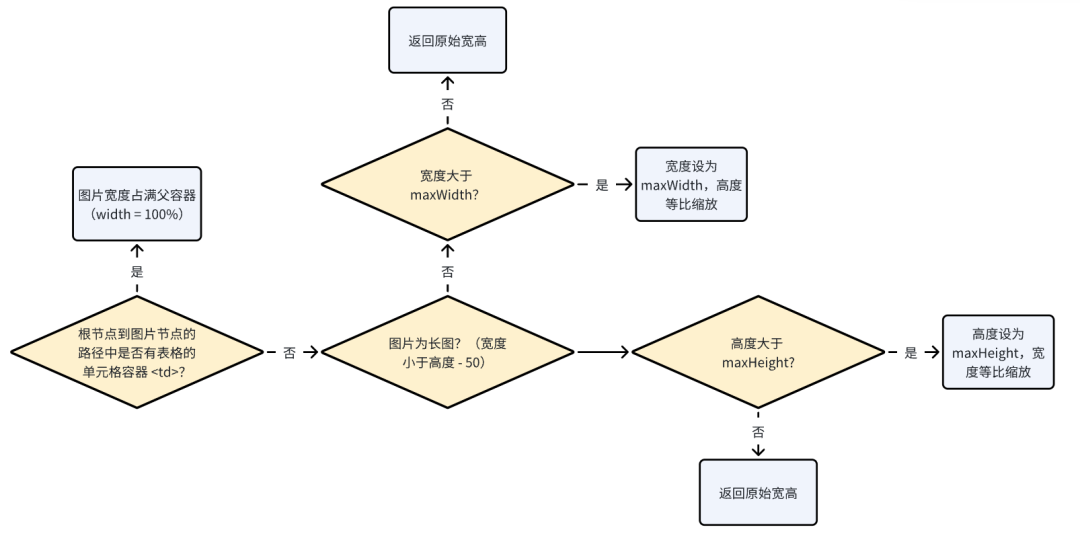
- 最后我们在样式中设置maxWidth = 100%(在Windows的Outlook中不会生效)来在大多数客户端中保证图片宽度不会撑出父容器。
上述算法的代码实现如下:
-
查找父容器中是否有表格容器:
/** 根据 id 找到块。*/
function findNodeById(blocks: DocBlock[], id: string) {
return blocks.find(b => b.block_id === id);
}/** 检查当前块的父节点中有没有表格或栅格块。*/
function checkIsInTable(blocks: DocBlock[], parentId: string) {
const parentNode = findNodeById(blocks, parentId);
if (parentNode) {
if (WRAPPERS_LIKE_TABLE.includes(parentNode.block_type)) {
return true;
}
return checkIsInTable(blocks, parentNode.parent_id);
}
return false;
} -
限制图片宽高:
function restrictImageSize(
width: number,
height: number,
maxWidth: number = 820,
maxHeight: number = 780,
): [number, number] {
// 宽和高按照长边缩放(高度大于宽度 50px 视为长图),并为缩放后的宽高向上取整。
if (width >= height - 50) {
if (width > maxWidth) {
return [maxWidth, Math.ceil(height * divide(maxWidth, width))];
}
} else {
if (height > maxHeight) {
return [Math.ceil(width * divide(maxHeight, height)), maxHeight];
}
}
return [width, height];
}
图片渲染器
-
渲染器:
const imageRenderer: BlockRenderer = (block, isPreview, _renderChildBlocks, blocks) => {
let text = '';
const blockImage = block as DocBlockImage;
const align = blockImage.image.align;
const src ="${ isPreview ? blockImage.image.base64Url :${{blockImage.block_id}\}` // 实际发送时,用 {block_id} 作为占位符,给到服务端填充图片附件地址。
}"`;
const [width] = restrictImageSize(blockImage.image.width, blockImage.image.height);
const isInTable = checkIsInTable(blocks, blockImage.parent_id);
const styles = makeImageStyles({ width, align, isInTable });text += ` <div ${styles.imgWrapperStyle}> <img width="${isInTable ? '100%' : width}" ${styles.imgStyle} src=${src}> </div>`;
return text;};
在预览的时候,我们将图片地址设为图片的base64,直接展示。最后传给后端的HTML字符串中,我们将图片地址设为一个占位符,供后端解析并转化为邮件附件地址。
使用表格来布局的几个文档块
由于Windows Outlook对CSS的支持程度很差,我们在对一些复杂文档块进行排版布局的时候不能使用flex、grid等。且display和position属性在大多情况下也不会像预期那样正常生效。我们为了最大的兼容性只能使用表格来解决一切排版问题。代码块、高亮块、栅格等几个文档块就都遵循了这个思路,使用表格来解决排版。我们以最复杂的代码块作为代表来进行介绍。
代码块
飞书云文档中免不了会出现代码,所以较好的进行代码块的还原也是个重要的工作。代码块还原的一个难点就是数据的处理,首先介绍下代码块的数据结构:
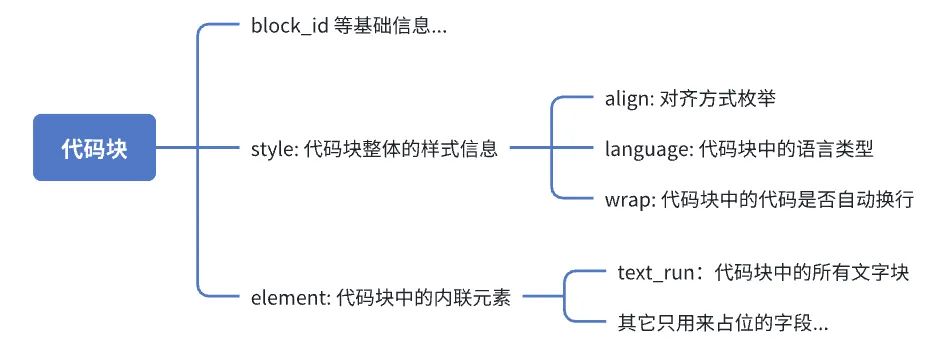
理想的话,我们希望element中每一项为一行代码,我们挨个进行渲染即可。但实际上,element的内容和普通文本类似,只要文本的样式不变(比如设为斜体、加粗等),这些文本就都会被塞到同一个element项中。
举例说明,对于下列文档中的代码块,实际飞书API返回的代码只有两项element:

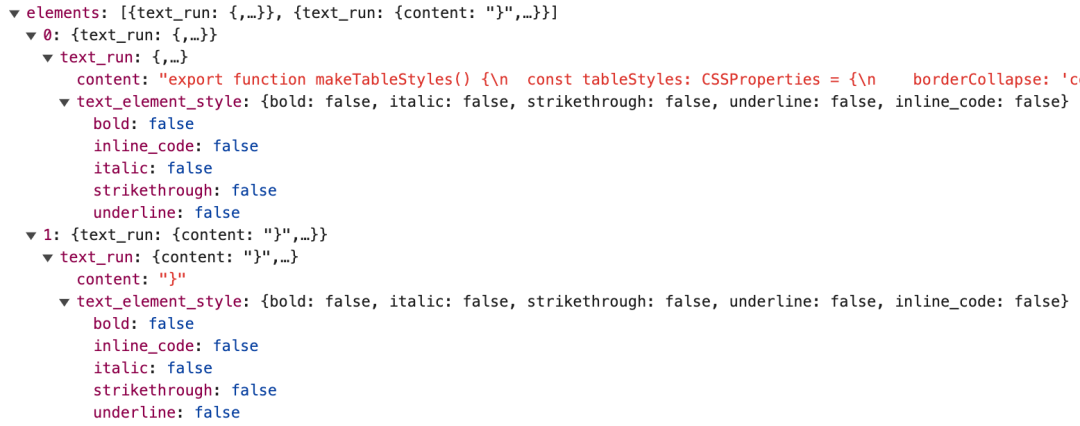
其中,最后一个大括号被单独拆成一项令人费解,不过好在代码块中,只要一项element的后面出现了另一项,那就一定意味着换行。这减少了我们的处理难度。
- 数据处理
我们的大体思路,是将代码拆分成一个二维数组。第一维中的每一维度为一行代码,每行代码中的每一维度为拆分后零碎的代码块。我们先将所有的element中的内容根据换行符\n拆分成一个个细小的子块,同时将与HTML有关的字符替换成HTML编码,避免这些字符混入HTML字符串中被当做标签解析:
elements.forEach(element => {
const textStyles = element.text_run?.text_element_style;
const elementSplit = (element.text_run?.content || '')
.replaceAll('&', '&')
.replaceAll('<', '<')
.replaceAll('>', '>')
.replaceAll('"', '"')
.replaceAll("'", ''')
.match(/(.*?\n|.+)/g);
elementSplit &&
elementSplit.forEach(line => {
codeList.push({
text_run: {
content: line,
text_element_style: textStyles as TextElementStyle,
},
});
});
});然后将这些子块按照换行符进行分组,变成我们需要的二维数组:
/** 将拆分好的代码块列表按行进行分组。*/
const groupingCodeList = (list: TextElement[] = []) => {
const result: TextElement[][] = [];
let currentGroup: TextElement[] = [];
list.forEach(item => {
// 将当前字符串添加到当前分组。
currentGroup.push(item);
// 如果字符串包含 '\n',则结束当前分组,并准备开始新的分组。
if (item.text_run?.content.includes('\n')) {
result.push(currentGroup);
currentGroup = [];
}
});
// 最后将 currentGroup 中剩余的项目加入 result。
if (currentGroup.length > 0) {
result.push(currentGroup);
}
return result;
};至此,我们知道了代码行数n和每行代码中的小代码块有哪些。我们要做的就是将它们放进一个n行2列的表格中
- 代码块渲染器
最终,代码块渲染器的代码如下。为了保证最大的兼容性,我们使用空的表格行作为内边距,尽量避免CSS解析问题:
-
渲染器:
const codeRenderer: BlockRenderer = (block, isPreview, renderChildBlocks, _blocks) => {
const styles = makeCodeStyles();const blockCode = block as DocBlockCode; const codeLanguage = blockCode.code.style.language || 0; // 将代码块中的正文将带 \n 的分割开。 const codeList: TextElement[] = []; const elements = blockCode.code.elements; // 分割的时候把 HTML 有关的字符换成 HTML 编码,避免这些正文直接被当成 HTML 渲染。 上文中提到的对elements的处理... const groupedCodeLines = groupingCodeList(codeList); // 将按行分类好的代码块填入 td。 const codeTr = groupedCodeLines .map((line, index) => { return ` <tr bgcolor="f5f6f7"> <td width="46" align="right" valign="top"> <pre ${styles.codeIndexStyles}>${index + 1}</pre> </td> <td> <pre ${styles.codePreStyles}>${transpileTextElements(blockCode.block_id, line, isPreview,)}</pre> </td> </tr> `; }) .join(''); const emptyTr = ` <tr bgcolor="f5f6f7"> <td width="46" align="right"><span> </span></td> <td><pre ${styles.codePreStyles}> </pre></td> </tr> `; let text = ` <div ${styles.codeWrapperStyles}> <table width="100%" ${styles.codeTableStyles}> ${emptyTr} ${codeTr} ${emptyTr} </table> </div> `;text += renderChildBlocks(blockCode.block_id, false);
return text;
}; -
样式生成:
我们本次不会实现代码的高亮,只会显示同一种颜色的代码。对表格中的每个单元格,我们使用pre标签包裹来保留代码中的制表符、空格,并将fontFamily设置为'Courier New', Courier, monospace,使用等宽字体来呈现代码。
- 最终呈现效果:

行间公式
飞书云文档除文本外支持多种行间元素的插入,比如@文档、内联文件、内联公式等,在此我们介绍下最为复杂的内联公式是怎么处理的。
行间公式的数据位于各个文档块的内联块中,以文本块为例,具体数据如下:
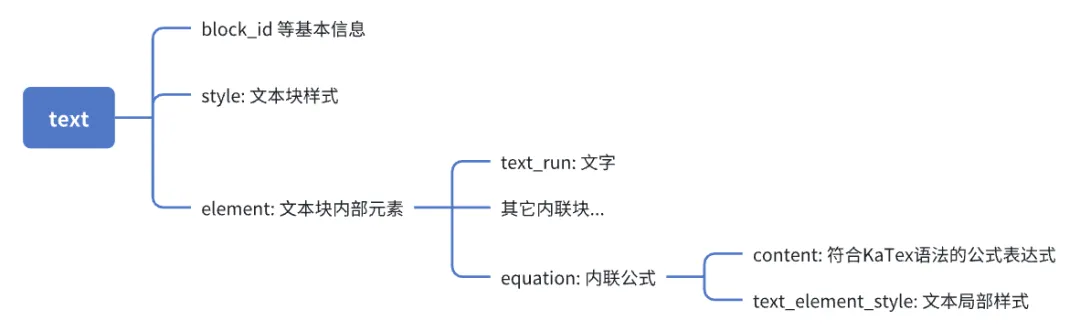
我们要做的,就是将公式转换为图片,然后在邮件中将公式作为图片附件来处理。
- 公式数据的预处理
我们将使用MathJax来将公式表达式转换为svg,用于用户预览。在发送时,我们将MathJax生成的svg通过cavans转化为png图片,上传到CDN,并将CDN地址给到后端,进行邮件附件转换。
公式的预处理方法如下:
// 公式发送时,后端渲染完成的图片,其展示的高度的系数。
const equationCoefficient = 8.421;
const enrichEquationElements: BlockPreprocessor = async (blocks, isPreview) => {
if (!window.MathJax) {
await loadScript('https://cdn.dewu.com/node-common/bc7b5cfc-1c7c-e649-710a-929f109e505e.js');
}
const equationSVGList: SvgObj[] = []; // 待上传的公式列表。
const equationElementList: TextElement[] = []; // 带有公式的元素列表。
blocks.forEach(block => {
const elements = getBlockElements(block);
let equationIndex = 0;
elements.forEach(textEl => {
// 文本块内容中包含公式时,转译为 SVG HTML。
if (textEl.equation) {
equationElementList.push(textEl);
const equationId = `${block.block_id}_equation_${++equationIndex}`;
const svgEl = window.MathJax.tex2svg(textEl.equation.content).children[0];
// 由于生成的公式 svg 的高度使用 ex 单位,这里乘以一个参数来转成近似的 px 单位。
const svgHeight = svgEl的ex高度 * equationCoefficient;
const svgWidth = svgEl的ex宽度 * equationCoefficient;
textEl.equation.svgHTML = svgEl.outerHTML;
textEl.equation.imageHeight = svgHeight;
textEl.equation.imageWidth = svgWidth;
textEl.equation.id = equationId;
equationSVGList.push({
id: equationId,
svg: svgEl.outerHTML,
height: svgHeight,
width: svgWidth,
});
}
});
});
// 非本地预览的时候进行公式转图片并上传 CDN(本地环境由于跨域无法上传 CDN)。
if (!isPreview) {
OSS 上传配置...
// 公式 svg 转图片文件然后上传 OSS。
const res = await allSvgsToImgThenUpload(equationSVGList);
equationElementList.forEach(element => {
从res中找到当前公式元素对应的图片,放入element.equation.imageUrl中
});
}
};我们先找出所有文档块中的内联公式,将其转换为svg,存储到公式块中。如果当前是发送模式,不是预览模式,我们就做进一步处理,使用allSvgsToImgThenUpload 将svg再转化为图片的CDN地址,此处的allSvgsToImgThenUpload方法让我们并行处理所有的公式图片,具体如下:
function allSvgsToImgThenUpload(svgObjList: SvgObj[]) {
// 将每个 SVG 字符串映射到转换函数的调用上。
const conversionPromises = svgObjList.map(svgObj => svgToImgThenUpload(svgObj));
// 使用 Promise.all 等待所有图片完成转换和上传。
return Promise.all(conversionPromises);
}核心的svgToImgThenUpload方法如下,它负责将svg转化为图片,并上传CDN:
/** svg 转图片,并上传到 OSS。*/
function svgToImgThenUpload(svgObj: SvgObj): Promise<{ id: string; url: string }> {
return new Promise((resolve, reject) => {
const { width, height, id } = svgObj;
const svgString = svgObj.svg;
if (!width || !height) {
reject(`公式svg大小获取失败: ${id}`);
return;
}
// 生成 svg 的 base64 编码。
const encodedString = encodeURIComponent(svgString).replace(/'/g, '%27').replace(/"/g, '%22');
const dataUrl = 'data:image/svg+xml,' + encodedString;
// 使用 canvas 渲染 svg 并转为图片。
const image = new Image();
image.onload = () => {
const canvas = document.createElement('canvas');
// 为了保证图片清晰,渲染使用三倍宽高,实际大小使用两倍宽高。
canvas.width = width * 3;
canvas.height = height * 3;
canvas.style.width = `${width * 2}px`;
canvas.style.height = `${height * 2}px`;
const ctx = canvas.getContext('2d');
ctx && ctx.drawImage(image, 0, 0, width * 3, height * 3);
// 将 canvas 内容导出为 Blob。
canvas.toBlob(async blob => {
创建 File 对象并上传 CDN,返回 CDN 链接;
}, 'image/png');
};
image.onerror = reject;
image.src = dataUrl;
});
}为了保证图片清晰,渲染使用三倍宽高,实际大小使用两倍宽高。
至此,我们让公式块带上了图片CDN地址。在发送时交给后端,转为邮件附件,即可正常显示了。
最终呈现效果

五、向前一步
好在最终我们克服了重重困难,终于来到了转译工具升级的Showcase环节。之前有提到我们有fallbackRenderer,主要用于针对未识别或者未支持的文档块,渲染其默认提示,最初我们渲染的效果只是一个简单的提示,比如:【画板暂不支持解析】这样的文案提示。
但是我们很快发现:1. 这些提示并不明显,可以做一个类似Antd Alert的提示;2. 在发送时要过滤掉这些提示,因为是无效信息;3. 在预览时需要让用户能够看到实际的发送效果,需要有开关能隐藏这些提示;4. 发送时存在这些不支持的块时,需要拦截提示用户是否去调整文档内容,以达到信息更全效果更好的发送效果。往往是这些细枝末节的体验与引导,能够真正抓住用户的心,让用户觉得这个转译工具是真的贴心、好用。
因此,我们快速增加了这些具体的引导与提示优化,具体效果如下:

六、大功告成
经过这一番波折,我们最终成功地将飞书云文档转译为兼容大多数客户端的HTML邮件。这不仅仅是一项技术上的挑战,更是一次心态和耐心的考验。
在这个过程中,我们深刻体会到在前端开发中,面对各种浏览器和客户端的不一致性时,需要的不仅仅是技术能力,还需要灵活应变和坚持不懈的精神。希望本文能为同样遇到这些问题的开发者提供一些思路和帮助。
未来,我们还将继续优化我们的解决方案,并探索更多高效的方法,期待与大家分享更多经验。如果有任何问题或建议,欢迎在评论区留言讨论!
感谢阅读!
引用:
https://open.feishu.cn/document/server-docs/docs/docs/docx-v1/document/list
*文/ Nicolas、Asher
本文属得物技术原创,更多精彩文章请看:得物技术
未经得物技术许可严禁转载,否则依法追究法律责任!