今日继续学习树莓派4B 4G:(Raspberry Pi,简称RPi或RasPi)
本人所用树莓派4B 装载的系统与版本如下:
版本可用命令 (lsb_release -a) 查询:
Opencv 版本是4.5.1:

今日学习树莓派与Python的多进程编程_线程间同步通信
文章提供测试代码讲解,整体代码贴出、测试效果图
目录
建立简单的多线程:
创建一个新的线程对象:
threading.Thread类用于创建一个新的线程对象。这个类接受几个参数,其中最重要的是
target和argstarget
target参数是一个可调用的对象(如函数或方法),当线程启动时,这个对象会被线程执行。在这个例子中,target被设置为counter函数,所以新创建的线程会执行counter函数。args
args参数是一个元组,用于给target函数传递参数。在这个例子中,args是一个只包含一个元素的元组,即字符串"计数A"。当t1线程启动并调用counter函数时,它会传递这个字符串作为参数。需要注意的是,由于
args需要是一个元组,所以即使只传递一个参数,也需要用逗号,来表明它是一个元组(在只有一个元素的元组后面加上逗号是一个常见的约定)。代码示例:
以下代码简单示例了如何编写一个简单的多线程程序:
python# -*- coding: utf-8 -*- import time import threading def counter(name): for i in range(5): print(name, i) time.sleep(1) t1 = threading.Thread(target=counter, args=("计数A",)) t2 = threading.Thread(target=counter, args=("计数B",)) t1.start() t2.start() print("主线程完成")

测试效果与解释:
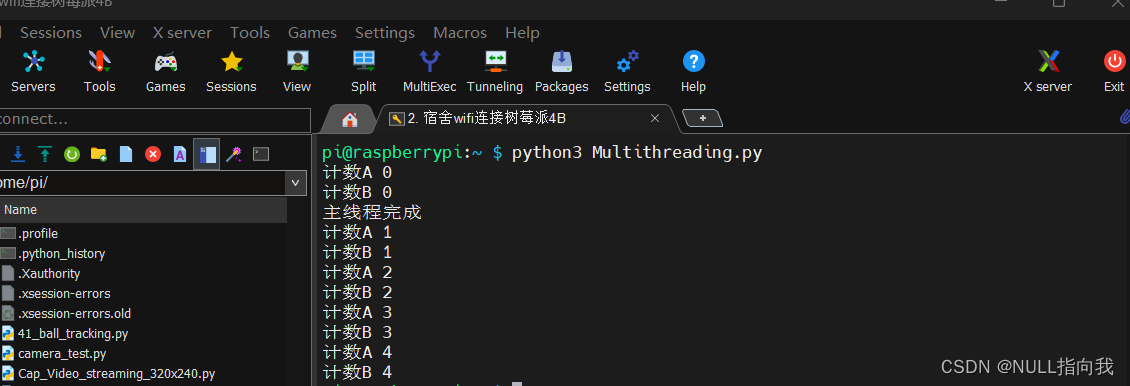
我们发现这个程序中一共三条线程:t1、t2、主线程
主线程因为只有一句prtint,因此在t1、t2计数第一次后就结束了
同时:t1、t2俩个线程是一起运行的
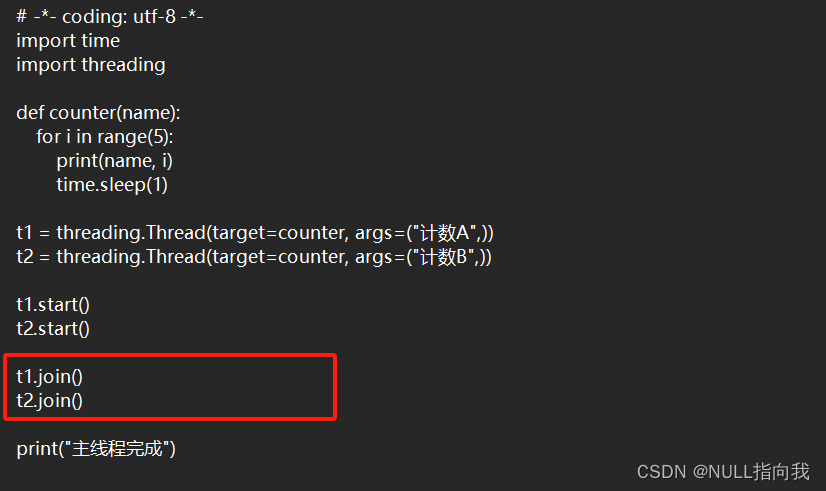
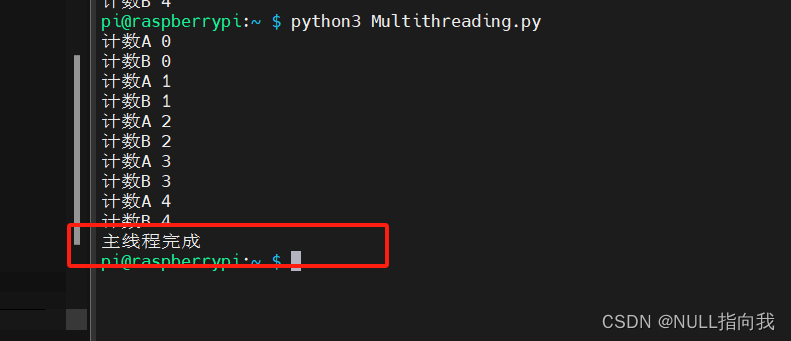
join方法的使用:
如果想主线程等待其余线程执行完,则可以使用join方法:
这样主线程就会在俩个子线程结束后才执行:
线程间的同步与通信:
问题代码与说明:
下面展示一段问题代码,该段代码有个全局变量N,程序试图通过多个线程对其进行加操作
从而达到快速加到某个值的效果:
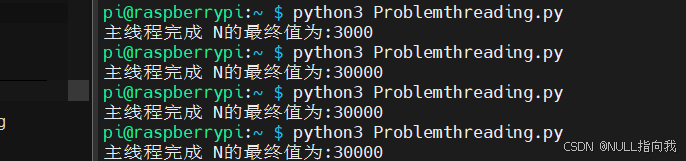
python# -*- coding: utf-8 -*- import time import threading # 定义一个全局变量,整数类型 N=0 def Add(name): global N # 如果想在函数内部修改全局变量的值,需要使用global关键字 for i in range(10000): N += 1 # 使用 += 来递增全局变量 t1 = threading.Thread(target=Add, args=("累加1",)) t2 = threading.Thread(target=Add, args=("累加2",)) t3 = threading.Thread(target=Add, args=("累加3",)) t1.start() t2.start() t3.start() t1.join() t2.join() t3.join() print("主线程完成 N的最终值为:{}".format(N))虽然我们发现这个操作结果是预期的30000,并未出现更改全局变量
N冲突的情况,主要是因为线程间对N的增加操作是原子的(atomic)。在Python中,对于整数类型(int)和不可变类型(如元组、字符串等),在CPython实现中,简单的赋值和算术操作通常是原子的。但是,请注意,这种情况并不意味着多线程环境下对全局变量的修改总是安全的。对于更复杂的操作或可变类型(如列表、字典等),多线程访问和修改可能会出现问题,例如数据竞争(data race)、死锁(deadlock)或条件竞争(condition race)。
竞态条件:
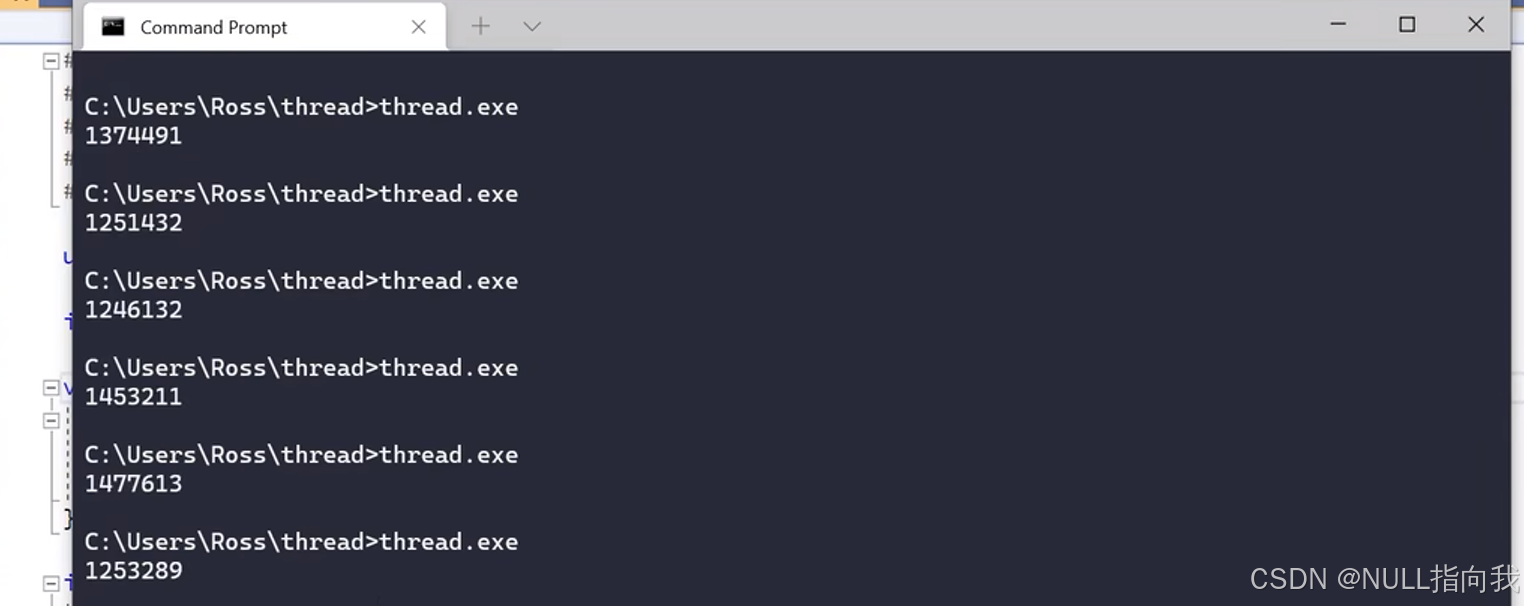
在以下给出的网址中的视频内就展示了对全局变量的非原子操作导致的加减输出混乱的情况
多线程编程:一次性搞懂线程同步机制_哔哩哔哩_bilibili
我们发现他的多线程程序并未累加全局变量到预期的值10万,而是运行出了六次不同的结果

使用锁同步对共享资源的访问:
threading.Lock
Lock对象提供了一种方法来同步线程,以确保在任何时候只有一个线程可以访问共享资源。下面是修改后的代码,其中添加了
Lock来保护对全局变量N的访问:
python# -*- coding: utf-8 -*- import time import threading # 定义一个全局变量,整数类型 N = 0 # 定义一个全局锁 lock = threading.Lock() def Add(name): global N, lock for i in range(10000): # 在修改N之前先获取锁 with lock: N += 1 # 使用 += 来递增全局变量 t1 = threading.Thread(target=Add, args=("累加1",)) t2 = threading.Thread(target=Add, args=("累加2",)) t3 = threading.Thread(target=Add, args=("累加3",)) t1.start() t2.start() t3.start() t1.join() t2.join() t3.join() print("主线程完成 N的最终值为:{}".format(N))添加了一个名为
lock的threading.Lock对象。在
Add函数中,我使用with lock:语句块来确保在修改N时锁是获取的。这个
with语句块会在进入时自动调用lock.acquire()来获取锁,并在退出时自动调用lock.release()来释放锁。这样,在任何时候只有一个线程可以执行
N += 1这行代码。现在,即使你运行多个线程来同时修改
N,也不会出现数据不一致的问题,因为每个线程在修改N之前都会先获取锁,确保其他线程在此期间不会修改N。运行效果展示:

代码改进提示:
但频繁地上锁解锁十分浪费资源,可以先定义一个局部变量代为运算,最后赋值给全局:
这样我们只需一次上锁与释放的操作就可以做到目标结果:
修改前繁琐的部分:
会进行高达10000次的:获取锁、释放锁的操作
修改的部分:
只进行了一次获取、释放锁的操作
整体代码:
python# -*- coding: utf-8 -*- import time import threading # 定义一个全局变量,整数类型 N = 0 # 定义一个全局锁 lock = threading.Lock() def Add(name): global N, lock n=0 for i in range(10000): n+=1 # 在修改N之前先获取锁 with lock: N += n # 使用 += 来递增全局变量 t1 = threading.Thread(target=Add, args=("累加1",)) t2 = threading.Thread(target=Add, args=("累加2",)) t3 = threading.Thread(target=Add, args=("累加3",)) t1.start() t2.start() t3.start() t1.join() t2.join() t3.join() print("主线程完成 N的最终值为:{}".format(N))运行结果:




网上学习网址贴出:
100秒学会Python多线程threading_哔哩哔哩_bilibili
多线程编程:一次性搞懂线程同步机制_哔哩哔哩_bilibili