学习目标:熟练掌握mindspore.dataset
mindspore.dataset中有常用的视觉、文本、音频开源数据集供下载,点赞、关注+收藏哦
- 了解
mindspore.dataset -
mindspore.dataset应用实践 - 拓展自定义数据集
昇思平台学习时间记录:

一、关于mindspore.dataset
mindspore.dataset模块提供了加载和处理各种通用数据集的API,如MNIST、CIFAR-10、CIFAR-100、VOC、COCO、ImageNet、CelebA、CLUE等, 也支持加载业界标准格式的数据集,包括MindRecord、TFRecord、Manifest等。此外,用户还可以使用此模块定义和加载自己的数据集。

1.1 常用数据集下载资源地址
开源数据集地址url如下 :
1.加载MNIST:url= "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/MNIST_Data.zip"
2.加载CIFAR-10:"url=https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/cifar-10-binary.tar.gz"
2.加载CIFAR-100:"url=https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets cifar-100-python.tar.gz"
3.加载ImageNet:url= https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/vit_imagenet_dataset.zip
4.加载狗与牛角包分类数据集DogCroissants:url=https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/beginner/DogCroissants.zip
- 数据集coco2017
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/ssd_datasets.zip"
1.2 数据集地址程序下载方式
方式一:from download import download
安装依赖库download
pip install download
方式二:from mindvision.dataset import DownLoad
安装依赖库:mindvision
pip install mindvision
示例如下:
python
# Begin to show your code!
from download import download
from mindvision.dataset import DownLoad
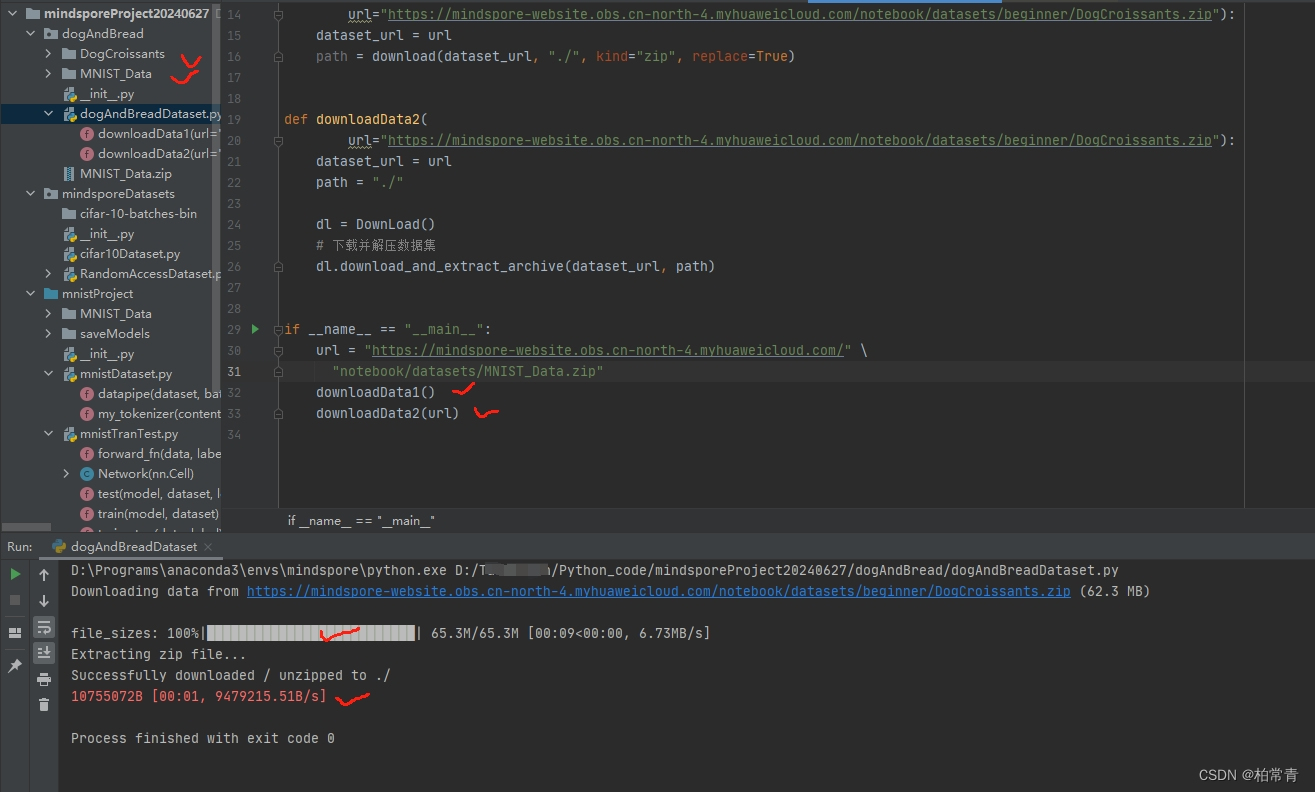
def downloadData1(url="https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/beginner/DogCroissants.zip"):
dataset_url = url
path = download(dataset_url, "./datasets", kind="zip", replace=True) # 当前文件夹下保存DogCroissants数据集
def downloadData2(url):
dataset_url = url
path = "./"
dl = DownLoad()
# 下载并解压数据集
dl.download_and_extract_archive(dataset_url, path)
if __name__ == "__main__":
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
downloadData1() # 方式一,下载DogCroissants
downloadData2(url) # 方式二,下载MNIST运行结果:成功下载数据集
方式三:from mindvision.dataset import Mnist
使用方法:
python
from mindvision.dataset import Mnist
download_train = Mnist(path="./mnist", split="train", batch_size=32, shuffle=True, resize=32, download=True)
download_eval = Mnist(path="./mnist", split="test", batch_size=32, resize=32, download=True)
dataset_train = download_train.run()
dataset_eval = download_eval.run()1.3 常用数据集生成Mindspore格式数据集生成器接口
(1) 常用开源视觉数据集-数据集接口
python
mindspore.dataset.Caltech101Dataset
mindspore.dataset.Caltech256Dataset
mindspore.dataset.CelebADataset
mindspore.dataset.Cifar10Dataset
mindspore.dataset.Cifar100Dataset
mindspore.dataset.CityscapesDataset
mindspore.dataset.CocoDataset
mindspore.dataset.DIV2KDataset
mindspore.dataset.EMnistDataset
mindspore.dataset.FakeImageDataset
mindspore.dataset.FashionMnistDataset
mindspore.dataset.FlickrDataset
mindspore.dataset.Flowers102Dataset
mindspore.dataset.Food101Dataset
mindspore.dataset.ImageFolderDataset
mindspore.dataset.KITTIDataset
mindspore.dataset.KMnistDataset
mindspore.dataset.LFWDataset
mindspore.dataset.LSUNDataset
mindspore.dataset.ManifestDataset
mindspore.dataset.MnistDataset
mindspore.dataset.OmniglotDataset
mindspore.dataset.PhotoTourDataset
mindspore.dataset.Places365Dataset
mindspore.dataset.QMnistDataset
mindspore.dataset.RenderedSST2Dataset
mindspore.dataset.SBDataset
mindspore.dataset.SBUDataset
mindspore.dataset.SemeionDataset
mindspore.dataset.STL10Dataset
mindspore.dataset.SUN397Dataset
mindspore.dataset.SVHNDataset
mindspore.dataset.USPSDataset
mindspore.dataset.VOCDataset
mindspore.dataset.WIDERFaceDataset(2)标准格式数据集接口
python
mindspore.dataset.ImageFolderDataset
mindspore.dataset.CSVDataset
mindspore.dataset.MindDataset
mindspore.dataset.OBSMindDataset
mindspore.dataset.TFRecordDataset(3)自定义数据集接口
python
mindspore.dataset.GeneratorDataset
mindspore.dataset.NumpySlicesDataset
mindspore.dataset.PaddedDataset
mindspore.dataset.RandomDataset1.4 开源数据实践实例
利用下载的数据集,数据集标准格式
python
import mindspore.dataset as ds
import mindspore.dataset.vision as vision
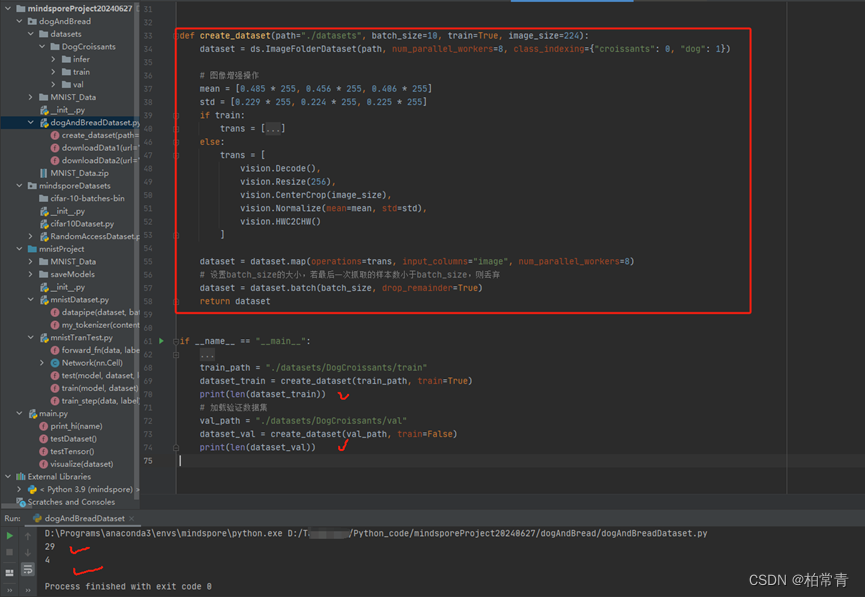
def create_dataset(path="./datasets", batch_size=10, train=True, image_size=224):
dataset = ds.ImageFolderDataset(path, num_parallel_workers=8, class_indexing={"croissants": 0, "dog": 1})
# 图像增强操作
mean = [0.485 * 255, 0.456 * 255, 0.406 * 255]
std = [0.229 * 255, 0.224 * 255, 0.225 * 255]
if train:
trans = [
vision.RandomCropDecodeResize(image_size, scale=(0.08, 1.0), ratio=(0.75, 1.333)),
vision.RandomHorizontalFlip(prob=0.5),
#vision.Normalize(mean=mean, std=std),
#vision.HWC2CHW()
]
else:
trans = [
vision.Decode(),
vision.Resize(256),
vision.CenterCrop(image_size),
vision.Normalize(mean=mean, std=std),
vision.HWC2CHW()
]
dataset = dataset.map(operations=trans, input_columns="image", num_parallel_workers=8)
# 设置batch_size的大小,若最后一次抓取的样本数小于batch_size,则丢弃
dataset = dataset.batch(batch_size, drop_remainder=True)
return dataset
if __name__ == "__main__":
# 加载训练数据集
train_path = "./datasets/DogCroissants/train"
dataset_train = create_dataset(train_path, train=True)
print(len(dataset_train))
# 加载验证数据集
val_path = "./datasets/DogCroissants/val"
dataset_val = create_dataset(val_path, train=False)
print(len(dataset_val))执行结果:成功加载数据集
1.5 数据集图像可视化
定义可视化函数import matplotlib.pyplot as plt
python
import matplotlib.pyplot as plt
def visualize(dataset):
figure = plt.figure(figsize=(4, 4))
cols, rows = 3, 3
plt.subplots_adjust(wspace=0.5, hspace=0.5)
for idx, (image, label) in enumerate(dataset.create_tuple_iterator()):
figure.add_subplot(rows, cols, idx + 1)
# plt.title(int(label))
plt.axis("off")
plt.imshow(image[0].asnumpy().squeeze().squeeze()) # 默认彩色,设置灰色cmap="gray"
if idx == cols * rows - 1:
break
plt.show()
if __name__ == "__main__":
# 加载训练数据集
train_path = "./datasets/DogCroissants/train"
dataset_train = create_dataset(train_path, train=True)
print(len(dataset_train))
visualize(dataset_train)运行结果:(成功)

自定义数据集
python
import time
import numpy as np
from mindspore.dataset import MnistDataset, GeneratorDataset, transforms, vision, text
# Random-accessible object as input source
class RandomAccessDataset:
def __init__(self):
self._data = np.ones((5, 2))
self._label = np.zeros((5, 1))
def __getitem__(self, index):
return self._data[index], self._label[index]
def __len__(self):
return len(self._data)
loader = RandomAccessDataset()
dataset = GeneratorDataset(source=loader, column_names=["data", "label"])
for data in dataset:
print(data)运行结果:成功
