大家好,我是刘明,明志科技创始人,华为昇思MindSpore布道师。
技术上主攻前端开发、鸿蒙开发和AI算法研究。
努力为大家带来持续的技术分享,如果你也喜欢我的文章,就点个关注吧
shuffle性能优化
shuffle操作主要是对有序的数据集或者进行过repeat的数据集进行混洗,MindSpore专门为用户提供了shuffle函数,它是基于内存缓存实现的,其中设定的buffer_size参数越大,混洗程度越大,但内存空间、时间消耗也会更大。该接口支持用户在整个pipeline的任何时候都可以对数据进行混洗,具体内容请参考shuffle处理。
但是因为它是基于内存缓存方式实现,该方式的性能不如直接在数据集加载操作中设置shuffle=True(默认值:True)参数直接对数据进行混洗。
shuffle方案选择参考如下:
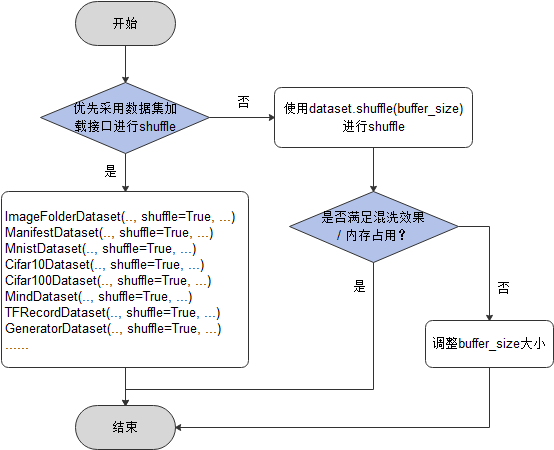
shuffle性能优化建议如下:
-
直接使用数据集加载接口中的shuffle=True参数进行数据的混洗;
-
如果使用的是shuffle函数,当混洗效果无法满足需求,可通过调大buffer_size参数的值来优化混洗效果;当机器内存占用率过高时,可通过调小buffer_size参数的值来降低内存占用率。
基于以上的shuffle方案建议,本次体验分别使用数据集加载操作Cifar10Dataset类的shuffle参数和shuffle函数进行数据的混洗,代码演示如下:
- 使用数据集加载接口Cifar10Dataset类加载CIFAR-10数据集,这里使用的是CIFAR-10二进制格式的数据集,并且设置shuffle参数为True来进行数据混洗,最后对数据创建了字典迭代器,并通过迭代器读取了一条数据记录。
python
cifar10_path = "./datasets/cifar-10-batches-bin/train"
# create Cifar10Dataset for reading data
cifar10_dataset = ds.Cifar10Dataset(cifar10_path, shuffle=True)
# create a dictionary iterator and read a data record through the iterator
print(next(cifar10_dataset.create_dict_iterator()))- 使用shuffle函数进行数据混洗,参数buffer_size设置为3,数据采用GeneratorDataset类自定义生成。
python
def generator_func():
for i in range(5):
yield (np.array([i, i+1, i+2, i+3, i+4]),)
ds1 = ds.GeneratorDataset(source=generator_func, column_names=["data"])
print("before shuffle:")
for data in ds1.create_dict_iterator():
print(data["data"])
ds2 = ds1.shuffle(buffer_size=3)
print("after shuffle:")
for data in ds2.create_dict_iterator():
print(data["data"])数据增强性能优化
在训练任务中,尤其是当数据集比较小的时候,用户可以使用数据增强的方法来预处理图片,达到丰富数据集的目的。MindSpore为用户提供了多种数据增强操作,其中包括:
-
Vision类数据增强操作,主要基于C++实现,见Vision数据增强。
-
NLP类数据增强操作,主要基于C++实现,见NLP数据增强。
-
Audio类数据增强操作,主要基于C++实现,见Audio数据增强。
-
并且用户可根据特定的需求,自定义Python数据增强函数(Python实现)。
数据增强操作选择参考:
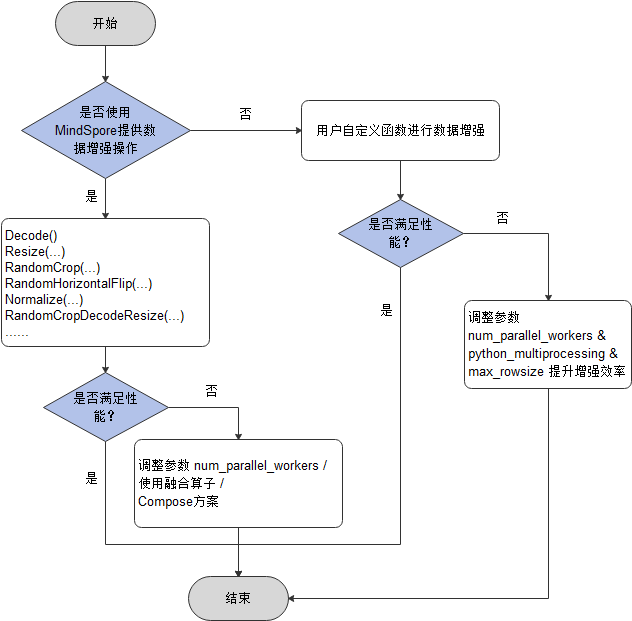
数据增强性能优化建议如下:
- 优先使用MindSpore提供的数据增强操作,能获得更好的性能,如果性能仍无法满足需求,可采取如下方式进行优化:
- 多线程优化
增大map接口的参数num_parallel_workers(默认值:8)来取得更好的性能。
- 融合算子优化
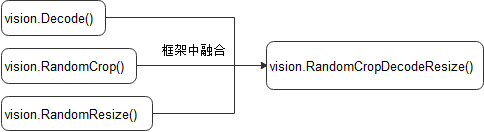
在当前CPU占用率比较高时(如:单机多卡训练),使用融合操作(将两个或多个操作的功能聚合到一个操作中)来降低CPU占用会获得更好性能,可以通过配置环境变量export OPTIMIZE=true来使其生效。融合示例如下:
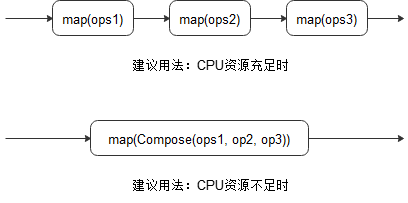
- Compose优化
在当前CPU占用率比较高时(如:单机多卡训练),通过一个map操作接收多个增强操作(会按照顺序应用这些操作)来降低CPU降低竞争以取得更好性能。示例如下:
- 如果用户使用自定义Python函数进行数据增强,当性能仍无法满足需求,则可采取多进程/多线程并发方案,参考如下,但如果还是无法提升性能,就需要对自定义的Python函数进行优化。
-
增大map接口的参数num_parallel_workers(默认值:8)来提升并发度;
-
将map接口的参数python_multiprocessing设置为True/False(默认值)来启动多进程模式/多线程模式,多进程模式适用于cpu计算密集型任务,多线程适用于IO密集型任务;
-
如果有Using shared memory queue, but rowsize is larger than allocated memory ...日志提示,那么将map接口的参数max_rowsize(默认值:6M)按日志提示进行增大来提升进程间数据传递的效率。
基于以上的数据增强性能优化建议,本次体验分别使用实现在C++层的数据增强操作和自定义Python函数进行数据增强,演示代码如下所示:
- 使用实现在C++层的数据增强操作,采用多线程优化方案,开启了4个线程并发完成任务,并且采用了融合算子优化方案,框架中使用RandomResizedCrop融合类替代RandomResize类和RandomCrop类。
python
import mindspore.dataset.vision as vision
import matplotlib.pyplot as plt
cifar10_path = "./datasets/cifar-10-batches-bin/train"
# create Cifar10Dataset for reading data
cifar10_dataset = ds.Cifar10Dataset(cifar10_path, num_parallel_workers=4)
transforms = vision.RandomResizedCrop((800, 800))
# apply the transform to the dataset through dataset.map()
cifar10_dataset = cifar10_dataset.map(operations=transforms, input_columns="image", num_parallel_workers=4)
data = next(cifar10_dataset.create_dict_iterator())
plt.imshow(data["image"].asnumpy())
plt.show()- 使用自定义Python函数进行数据增强,数据增强时采用多进程优化方案,开启了4个进程并发完成任务。
python
def generator_func():
for i in range(5):
yield (np.array([i, i+1, i+2, i+3, i+4]),)
ds3 = ds.GeneratorDataset(source=generator_func, column_names=["data"])
print("before map:")
for data in ds3.create_dict_iterator():
print(data["data"])
def preprocess(x):
return (x**2,)
ds4 = ds3.map(operations=preprocess, input_columns="data", python_multiprocessing=True, num_parallel_workers=4)
print("after map:")
for data in ds4.create_dict_iterator():
print(data["data"])batch操作性能优化
在数据处理的最后阶段,会使用batch操作将多条数据组织成一个batch,然后再传递给网络用于训练。对于batch操作的性能优化建议如下:
-
如果仅配置了batch_size和drop_remainder,且batch_size比较大时,建议增大num_parallel_workers(默认值:8)来取得更好的性能;
-
如果使用了per_batch_map功能,那么建议配置如下:
-
增大参数num_parallel_workers(默认值:8)来提升并发度;
-
将参数python_multiprocessing设置为True/False(默认值)来启动多进程模式/多线程模式,多进程模式适用于cpu计算密集型任务,多线程适用于IO密集型任务;
-
如果有Using shared memory queue, but rowsize is larger than allocated memory ...日志提示,那么将batch接口的参数max_rowsize(默认值:6M)按日志提示进行增大来提升进程间数据传递的效率。