在当今科技飞速发展的时代,人工智能在各个领域不断展现出令人惊叹的创新能力。音频生成领域也不例外,其中 AudioLM 音频生成模型的出现引起了广泛的关注。
一、AudioLM 模型简介
AudioLM 是一种前沿的音频生成模型,它旨在通过学习大量的音频数据,生成具有高度逼真度和连贯性的新音频内容。
二、关键要点
(一)强大的学习能力
AudioLM 能够从海量的音频样本中提取特征和模式,从而理解不同类型音频的结构和规律。无论是音乐、语音还是环境音效,它都能进行深入学习。
实践中,这意味着模型可以生成与给定的输入音频风格相似的新音频,例如,基于一段古典音乐片段生成一段新的古典音乐。
(二)高保真度和连贯性
生成的音频具有出色的音质和连贯的旋律、节奏。它不仅仅是简单的拼凑,而是能够在时间维度上保持音频元素的合理过渡和发展。
例如,在生成语音时,能够保持语调的自然流畅,避免突兀的中断或不自然的变化。
(三)多模态融合
AudioLM 可以结合文本、图像等多模态信息来指导音频生成。这为音频创作带来了更多的可能性和创意空间。
比如,根据一段描述性的文字生成相应氛围的背景音乐,或者根据一张图片的主题生成适配的音效。
(四)潜在应用广泛
- 音乐创作
辅助音乐家创作新的旋律、编曲,为他们提供灵感和创新的起点。 - 影视和游戏音频制作
快速生成符合特定场景需求的音效和背景音乐,提高制作效率。 - 语音合成
生成自然流畅的语音,应用于有声读物、智能客服等领域。
三、技术原理
AudioLM 基于深度学习技术,特别是 Transformer 架构。它通过对音频的频谱图或其他特征表示进行建模,学习音频的长期依赖关系和结构。
在训练过程中,模型使用了大量的无标签音频数据,通过自监督学习的方式来捕捉音频的内在规律。
四、模型结构和原理
模型结构和原理(语音到语音)
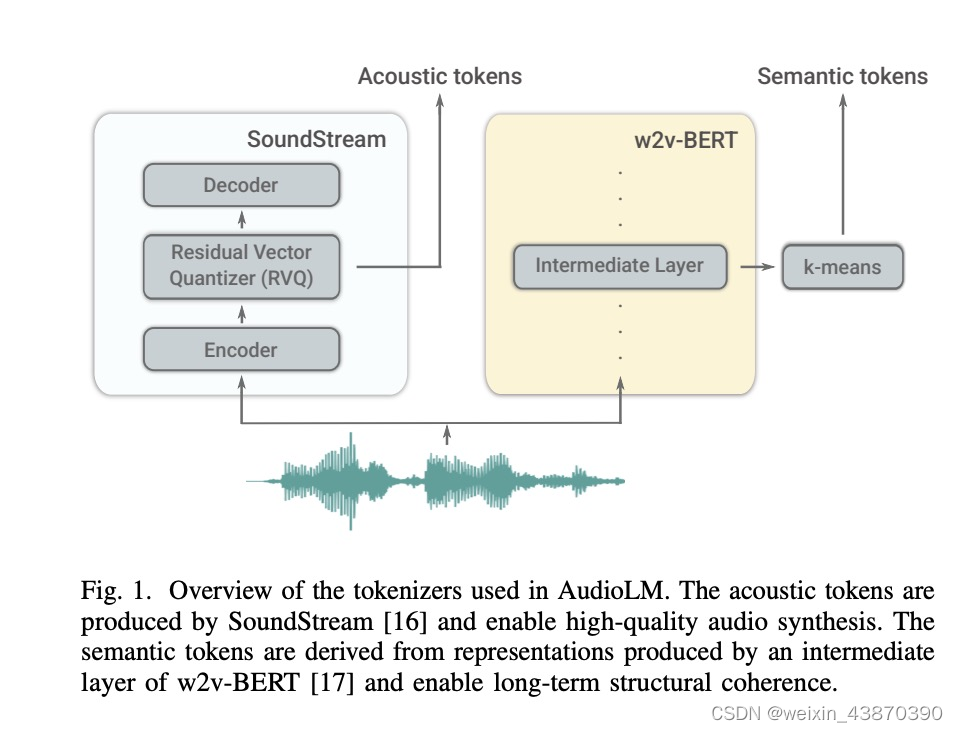
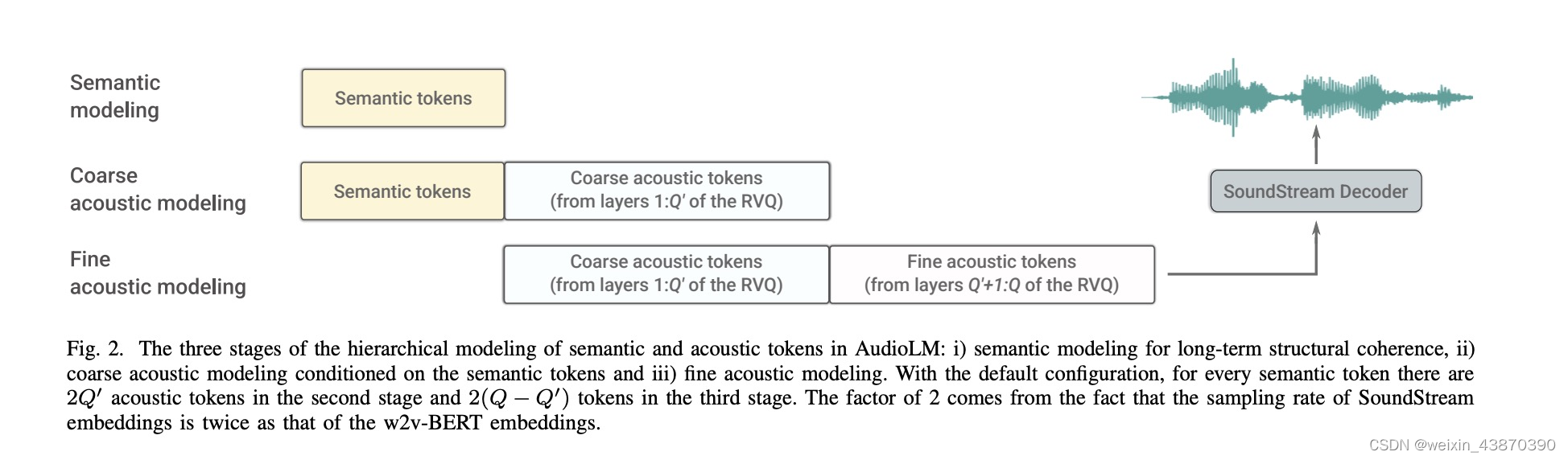


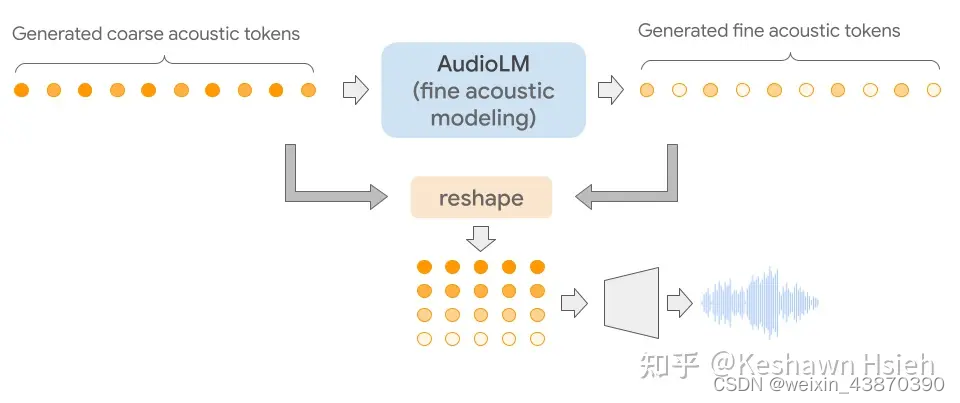
- 整体思路,语音到语音,语音续写。
- 两个前处理模块:第一张图中将一个语音处理成semantic tokens(w2v-bert)以及acoustic tokens(soundstream前部分模块)
- 三个核心模块:即最后三张图。Semantic modeling用于将语义信息进一步生成,生成新的语义,可以理解成续写的内容;Coarse acoustic modeling用于语音信息的生成,它的输入结合了前面生成的语义信息,生成新的语音信息包含了语义信息;Fine acoustic modeling模块将语音信息进一步精修,生成新的语音信息;精修的语音信息和精修之前的语音信息合在一起进行进行decoder,解码为wav。
- 上面第二张图,是论文中的原图,展示了三个模块和数据流向,看完最后三个图再理解这个图就很容易懂了。
适合任务
适合任务1:自由生成。随机输入一些semantic tokens。
适合任务2:语音续写。
适合任务3:钢琴曲学写。
适合任务4:speaker转换。也就是保持说的内容是given的,然后生成不同说话人音色的音频。
外接gpt模型t5,让audiolm具有tts的能力。
inference阶段
-
unconditional generation
这里可以理解为就是生成随机的内容,也不控制speaker音色。
这里的输入描述是we sample unconditionally all semantic tokens。
我的理解就是随机给一些semantic tokens作为输入,来启动semantic transformer的自回归输出
不过这里没有提到第二阶段要用到的acoustic tokens这个输入从哪里来?
- 1
- 2
- 3
- 4
知乎中这段文字,我理解acoustic tokens也来自随机。
-
acoustic generation
semantic tokens这次直接由某个固定的wav过w2v-bert得到。
这样可以实现合成和这个wav同样的内容但是音色和风格不同的其他说话人的语音。
相对第一种模式,这个模式下感觉就不需要用到semantic modeling这个过程了。
但是还是存在一个疑问,就是coarse acoustic modeling的过程中,acoustic tokens这个输入从哪里来?
- 1
- 2
- 3
- 4
知乎中这段文字,我理解acoustic tokens是来自外部给定的wav,可以参考这个wav的风格生成语音。
-
generating continuations
这个模式是相对比较符合实际应用的,这个模式下会给定一个wav的prompt。
然后从prompt可以得到semantic tokens和acoustic tokens。
分别被用在第一阶段和第二阶段,最后可以实现一个语音续写的效果。
不过续写的内容是来自模型本身产生,无法人为控制。