为了学习分类特征,以某国成年人收入数据集(adult)为例,adult数据集的任务是预测一名工人的收入是高于50k还是低于50k,这个数据集的特征包括工人的年龄、雇佣方式、教育水平、性别、每周工作时长、职业等。

这个任务属于分类任务,两个类别分别是<=50k和>50k。如果预测具体收入,那就变成了一个回归任务。
在这个数据集中,age和hours_per_week是连续特征 。但workclass、education、gender、occupation(职业)都是分类特征。它们都是来自一系列固定的可能取值,而不是一个范围,表示的是定性属性。
首先,假设我们想要的在这个数据上学习一个Logistic回归分类器。
到目前为止,表示分类向量最常用的方法是使用one-hot编码 或N取一编码 ,也叫虚拟变量。虚拟变量背后的思想是将一个分类变量替换为一个或多个新特征,新特征的取值为0和1,对于线性二分类的公式而言,0和1这两个值是有意义的,我们可以像这样对每个类别引入一个新特征,从而表示任意数量的类别。
比如说,workclass特征的可能取值包括'Government Employee','Private Employee','Self Employed','Self Employed Incorporated',为了编码这4个可能的取值,我们创建了4个新特征,分别叫做'Government Employee','Private Employee','Self Employed','Self Employed Incorporated'。如果一个人的workclass取某个值,那么对应的特征取1,其他特征均取0。因此,对于每个数据点来说,4个新特征中之后一个取值为1。这就是它叫做one-hot编码或者N取一编码的原因。
将数据转换成分类变量的one-hot编码有两种方法,一种是使用pandas,一种是使用scikit-learn。
先尝试用pandas:
python
import pandas as pd
from IPython.display import display
data=pd.read_csv(
'data/adult.data',header=None,index_col=False,
names=['age','workclass','fniwgt','education','education-num',
'marital-status','occupation','relationship','race','gender',
'capital-gain','capital-loss','hours-per-week','native-country','income']
)
data=data[['age','workclass','education','gender','hours-per-week','occupation','income']]
display(data.head())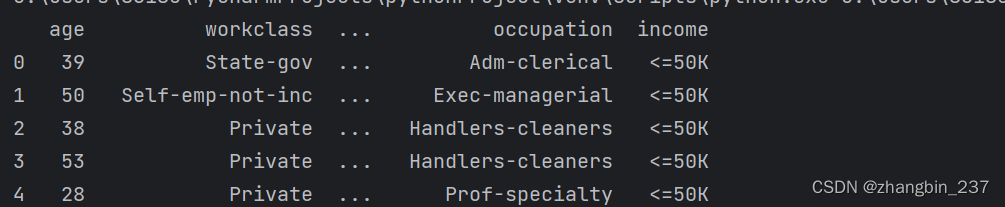
检查编码后的分类数据:
读取完这样的数据集之后,最好先检查每一列时候包含有意义的分类数据,可以使用pandas Series的value_counts函数,以先是唯一值及其出现的次数:
python
print(data.gender.value_counts())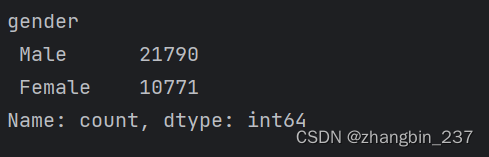
可以看到,在这个数据集中性别刚好有2个值:Male和Female,这说明数据格式已经很好,可以用one-hot编码来表示。在实际应用中,应该查看并检查所有列的值。
用pandas编码数据有一种非常简单的方法,就是用get_dummies函数,get_dummies函数自动变换所有具有对象类型(比如字符串)的列或所有分类的列:
python
print('Driginal feature:\n',list(data.columns),'\n')
data_dummies=pd.get_dummies(data)
print('Feature after get_dummies:\n',list(data_dummies.columns))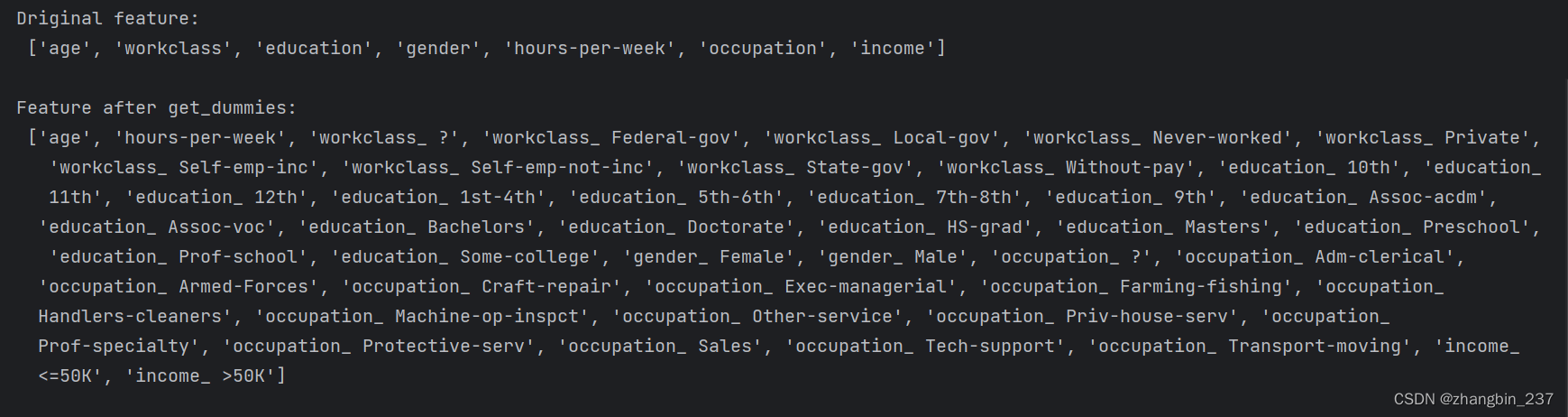
可以看到,连续特征age和hours_per_week没有发生变化,而分类特征的每个可能取值都被扩展为一个新特征。
python
print(data_dummies.head())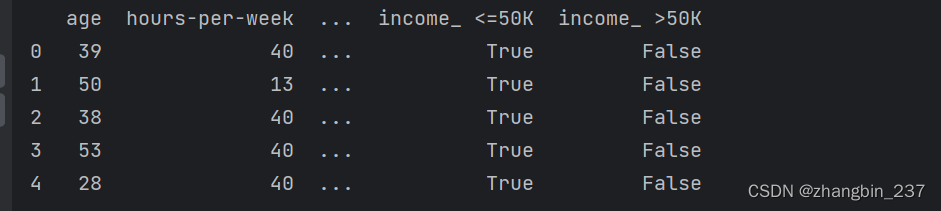
下面可以使用values属性将data_dummies数据框(DataFrame)转换为NumPy数组,然后在其上训练一个机器学习模型。在训练模型之前,主要要把目标变量从数据中分离出来。将输出变量或输出变量的一些导出属性包含在特征表示中,这是构建机器学习模型时一个非常常见的错误。
python
features=data_dummies.loc[:,'age':'occupation_ Transport-moving']
X=features.values
y=data_dummies['income_ >50K'].values
print('X.shape:{} y.shape:{}'.format(X.shape,y.shape))
现在数据的表示方式可以被scikitlkearn处理,可以像之前一样继续下一步:
python
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=0)
logreg=LogisticRegression()
logreg.fit(X_train,y_train)
print('测试集score:{:.2f}'.format(logreg.score(X_test,y_test)))