1. 使用requests获取网页内容
以巴鲁夫产品为例,可以用get请求获取内容:
https://www.balluff.com.cn/zh-cn/products/BES02YF
对应的网页为:
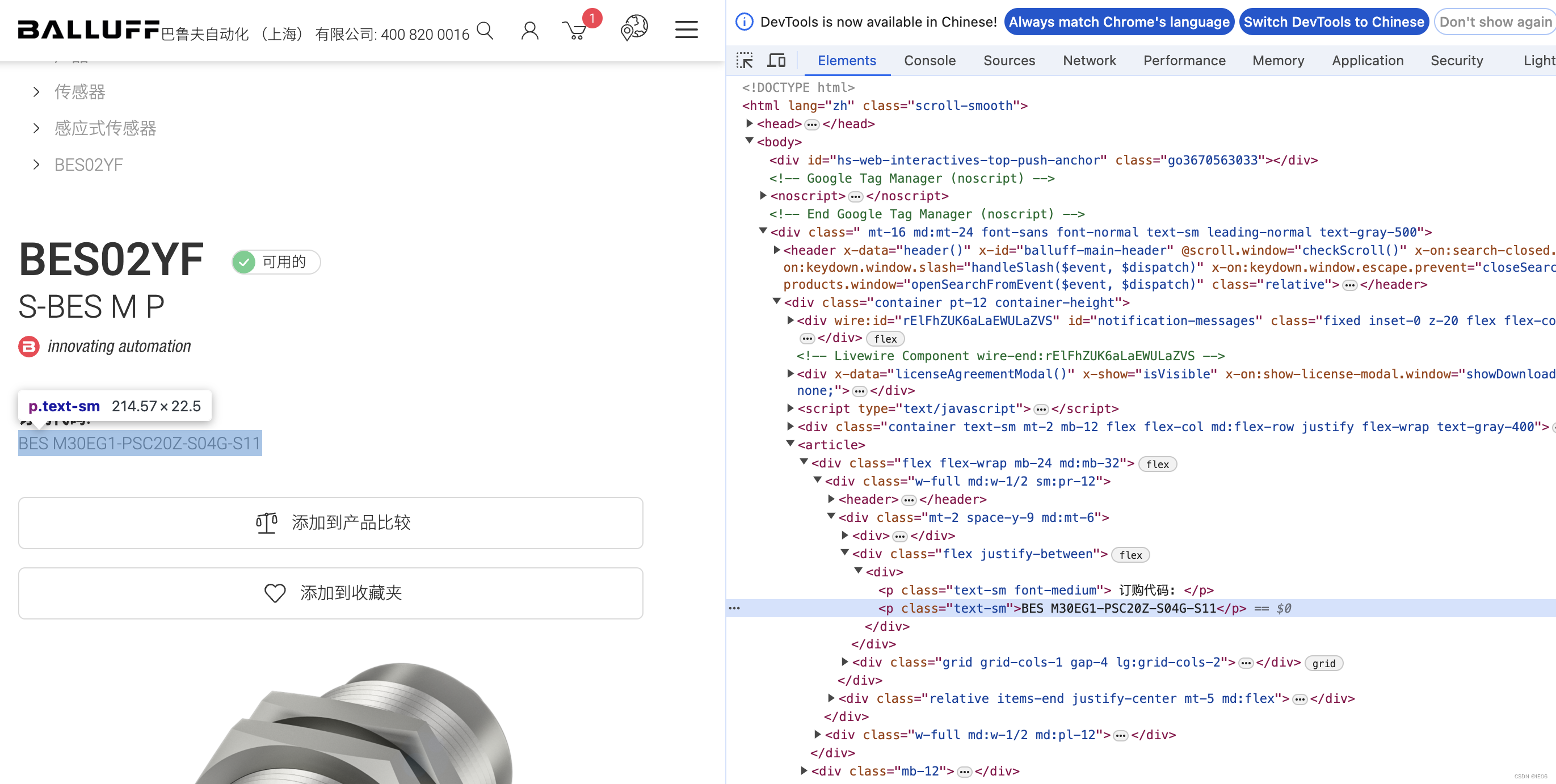
使用简单方法进行解析即可
import requests
r = 'BES02YF'
res = requests.get("https://www.balluff.com.cn/zh-cn/products/%s"%r).text
result = res.split("</title>")[0].split("<title>")[1]2. 添加多进程
使用multiprocessing进行加速,以上面的balluff为例:
from multiprocessing.dummy import Pool as ThreadPool
from tqdm import tqdm
import numpy as np
import os,json,requests,base64,struct
data = pd.read_excel("balluff.xlsx",sheet_name='all')
valuelist = list(data['Type'])
def getf(type_value):
try:
res = requests.get("https://www.balluff.com.cn/zh-cn/products/%s"%type_value).text
return res.split("</title>")[0].split("<title>")[1]
except:
return None
results = []
with ThreadPool(100) as p:
results = list(tqdm(p.imap(getf, valuelist), total=len(valuelist)))3. 加入header
有一些网站有防爬虫的功能,需要在请求中添加header,例如西门子的网站需要用如下的方法:
def getf(type_value):
try:
headers = {"user-agent": "Mizilla/5.0"}
res = requests.get("""https://mall.industry.siemens.com/mall/zh/CN/Catalog/Product/?mlfb=%s&SiepCountryCode=CN"""%type_value,headers=headers).text.split("""productIdentifier""")[1]
return res.split("""</span>""")[0].split('>')[-1]
except:
return None4. 使用selenium
以festo为例,会很讨厌的弹出对话框。
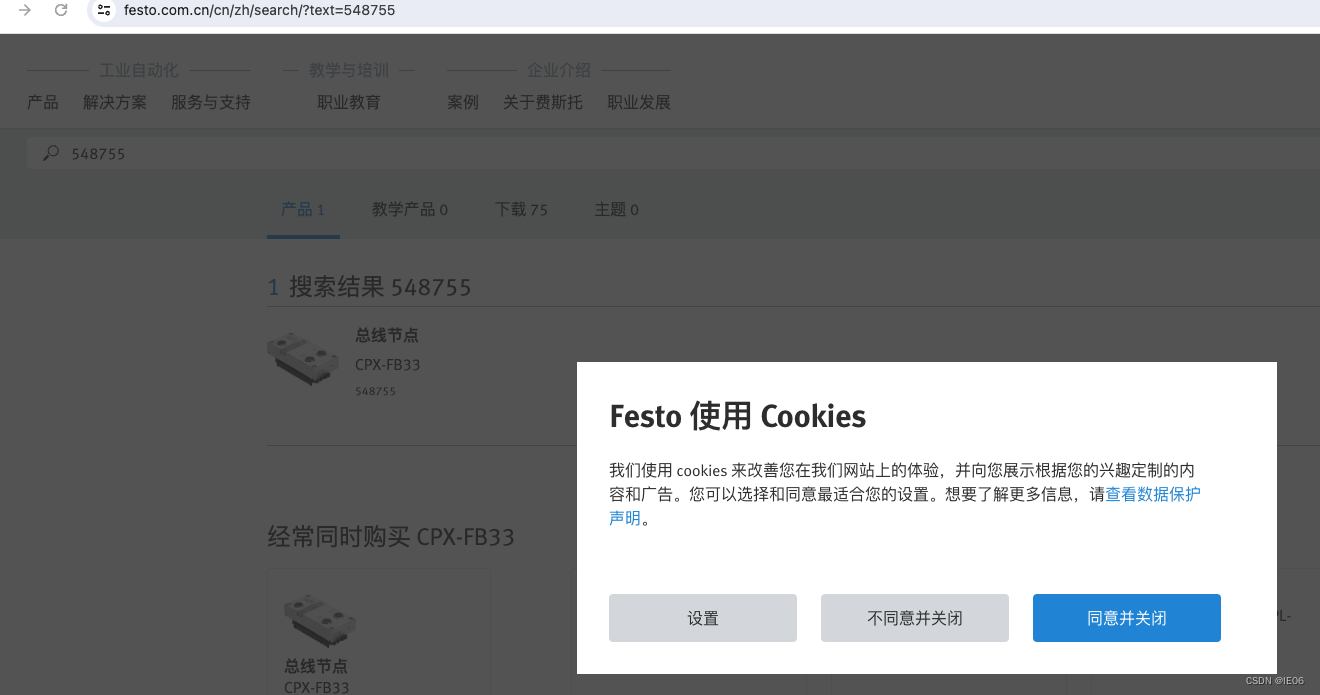
我们使用selenium模拟点击。并且用find_element找到元素:
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://www.festo.com.cn/cn/zh/search/?text=548755')
f1=driver.find_element(By.PARTIAL_LINK_TEXT,'接受')
f1.click()
from tqdm import tqdm
r1 = []
r2 = []
for type_value in tqdm(valuelist):
try:
driver.get('https://www.festo.com.cn/cn/zh/search/?text=%s'%type_value)
time.sleep(1)
r1.append(driver.find_element(By.CLASS_NAME,'product-code--NjIDg').text)
try:
r2.append(driver.find_element(By.CLASS_NAME,'ident-code--qx13c').text)
except:
r2.append(driver.find_element(By.CLASS_NAME,'product-order-code--TR15s').text)
except:
r1.append(None)
r2.append(None)5. 获取真实的requests地址
以keyence为例,查看网页源代码是无法获得产品清单的,需要在chrome的开发者工具中点击Network,选择Fetch/XHR,然后刷新页面,找到Type为fetch的链接:
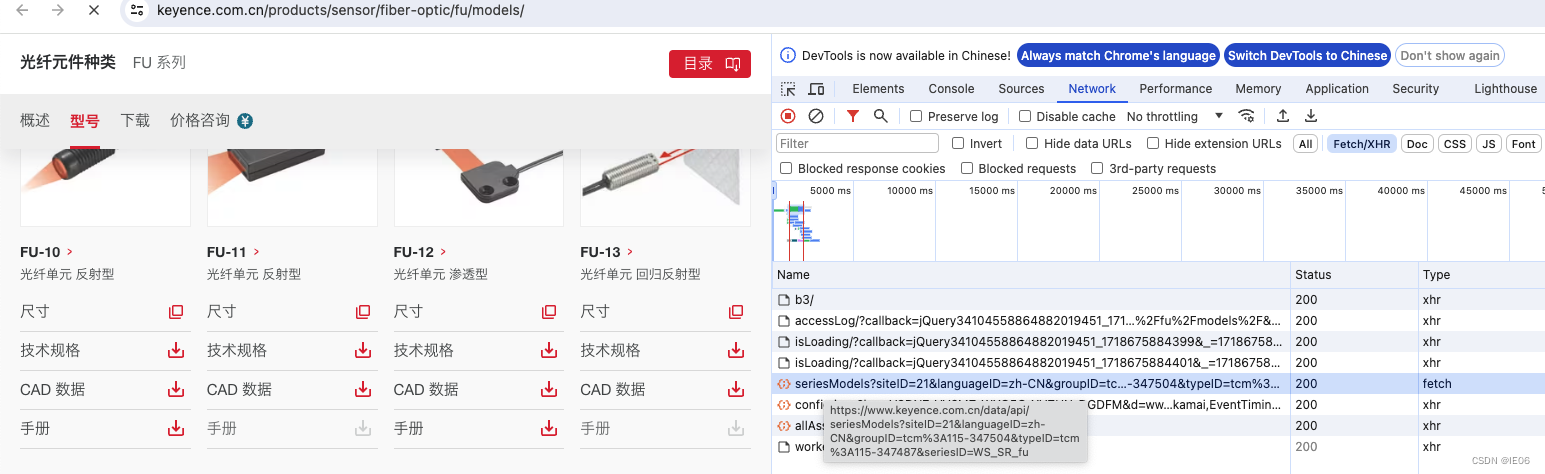
链接为/data/api/seriesModels?siteID=21&languageID=zh-CN&groupID=tcm%3A115-347504&typeID=tcm%3A115-347487&seriesID=WS_SR_fu,其中groupID开始的部分,可以从源代码中获得。具体代码为:
import json
from tqdm import tqdm
result = []
for r2i in tqdm(r2):
result += json.loads(requests.get('https://www.keyence.com.cn/data/api/seriesModels?siteID=21&languageID=zh-CN&'+\
list(filter(lambda x:'prd-seriesFooter-navLink of-support' in x,requests.get(r2i)\
.text.split('\n')))[0].split('?')[1].split('&modelId')[0].replace('Id','ID')).text)['models']如果找到的链接过于难处理(比如post请求带着一堆请求体),那可以直接右键,选择copy->copy curl,然后替换其中的关键字,用命令行执行即可。