论文:MCS-SQL: Leveraging Multiple Prompts and Multiple-Choice Selection For Text-to-SQL Generation
⭐⭐⭐
arXiv:2405.07467
一、论文速读
已有研究指出,在使用 LLM 使用 ICL 时,ICL 的 few-shot exemplars 的内容、呈现顺序都会敏感地影响 LLM 的输出。基于此,本文提出通过使用多个 prompts 并利用 LLM 的 ICL exemplars 的敏感性,来扩大 LLM 的搜索空间,得到 LLM 的多个响应 SQL,然后再做一个多项选择,从中选出最终的 SQL 作为输出。
MCS-SQL 模型包含三个主要步骤:
- schema linking:筛选出相关的 DB schema
- multiple SQL generation:利用多个 prompts 来让 LLM 生成多个 SQL
- multiple choice selection:从多个 SQL 中选出最终的 SQL
二、MCS-SQL 模型
这里分别介绍这个模型的三个步骤。
2.1 Schema Linking
Schema Linking 就是识别出与 question 相关的 DB tables 和 columns。这里分成两步来做:先 table linking,再 column linking。
Table Linking :将 question、DB schema 给 LLM,让 LLM 以 JSON 格式输出选出的 tables 以及理由。一个 prompt 示例如下图。为了鲁棒性,这一步使用了 p t p_t pt 个 prompts,每个 prompt 让 LLM 生成 n 次响应,共得到 p t ⋅ n p_t \cdot n pt⋅n 个响应结果,然后取并集作为最终筛选结果。

Column Linking :也是 prompt LLM 来做,prompt 中只包含筛选后的 tables 的 schema。指示 LLM 输出 [table-name].[col-name] 格式的答案,以防止命名冲突。一个 prompt 示例如下图。具体上,也是有 p c p_c pc 个 prompts,每个让 LLM 生成 n 次响应,共得到 p c ⋅ n p_c \cdot n pc⋅n 个响应结果,然后取并集作为最终筛选结果。

2.2 Multiple SQL Generation
为了利用 LLM 对 ICL exemplars 的敏感性,这里通过变换 exemplars 的选择结果和呈现顺序,来得到多个 prompts。
这里先做 Few-shot Examples Selection,具体来说有两种 selection 方法:
- 利用 question similarity:将 question 作为 keyword 进行相似度检索,从而在 training set 中检索到 examples。
- 利用 masked question similarity:去掉 question 中的 schema-specific content 在进行相似度检索,这样能够让检索更加关注 question 的结构形式
这里会两种方法都使用,从而得到多个 prompts。
有了 prompt,就可以做 SQL Generation,prompt 中包含 few-shot examples、DB schema、rows 示例以及 user question,如下:
plain
### Generate the correct SQL query for a given DB schema and question.
### Gold Examples:
- Question: ...
- Gold SQL: ...
...
### DB Schema: ...
### Sample Table Contents: ...
### Question: ...
Your answer should be in the json format:
{
"reasoning": ".." # The reasoning steps behind the generated SQL query
"sql": ".." # The generated SQL query.
}
### Your answer:其中 rows 示例使用 CSV 格式来展示。在输出时,还引导 LLM 解释它生成 SQL 的推理步骤。
由于有多个 prompts,这里使用较高的采样温度来让 LLM 做生成,从而得到 p q ⋅ n p_q \cdot n pq⋅n 个候选 SQL。
2.3 Selection
这一步是从候选 SQL 中选出最准确的 SQL query。
整体的思路是:先基于 confidence score 从 candidate pool 做一次过滤,然后再使用 LLM 从 refined pool 中选出最精确的 SQL。
2.3.1 Candidate Filtering
这里先执行所有候选 SQL,然后将查询结果相同的被分组在一起,每组只保留查询最快的 SQL。
然后就再计算每个 SQL 的 confidence scores,N 个 SQL { q 1 , ... , q N } \{q_1, \dots, q_N \} {q1,...,qN} 的 scores 计算方式如下:
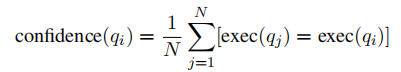
- 其中 exec(q) 指的是 SQL query q q q 的执行结果
计算出 scores 后,将低于阈值 T 的 SQL 排除掉。
2.3.2 Multiple-Choice Selection (MCS)
经过上一层过滤后,这一步再利用 LLM 通过做多项选择来从候选 SQL 中选出最准确的 SQL。所使用的 prompt 如下:
plain
### For a given DB schema and question, select the most accurate query among the candidate SQL queries.
### DB schema: ...
### Question: ...
### Candidate SQLs:
1. SQL1
2. SQL2
3. SQL3
Your answer should be in the json format:
{
"reasoning": ".." # The reasoning steps for selecting the correct SQL query.
"sql": ".." # The selected SQL query.
}
### Your answer:在这里,LLM 不仅需要选择出 SQL query,还需要提供选择这个 SQL 的原因。
使用这一个 prompt 来让 LLM 生成 n 个响应,然后通过多数投票确定最终的 SQL query 结果。
三、总结
本文通过多个 prompts 让 LLM 多次生成,并通过过滤选择得到最终 SQL,效果在 BIRD 数据集上表现很好。
ompt 来让 LLM 生成 n 个响应,然后通过多数投票确定最终的 SQL query 结果。
三、总结
本文通过多个 prompts 让 LLM 多次生成,并通过过滤选择得到最终 SQL,效果在 BIRD 数据集上表现很好。
但是本文方法有个明显缺点:调用 LLM 的次数实在是太多了,这需要进一步优化。