Flink作业执行之 4.JobGraph
1. 入口
前文了解了由Transformation到StreamGraph的过程,StreamGraph即作业的逻辑拓扑结构。
生成逻辑结构后,接下来的操作往往是对逻辑结构的优化。在很多组件中都是这样的处理,如hive、spark等都会执行"逻辑计划->优化计划->物理计划"的处理过程。
从StreamGraph到JobGraph的过程中很重要的事情是将节点组成节点链。
在env.execute()方法中调用executeAsync方法完成JobGraph实例的生成。
java
@Internal
public JobClient executeAsync(StreamGraph streamGraph) throws Exception {
checkNotNull(streamGraph, "StreamGraph cannot be null.");
// 根据启动方式得到具体的PipelineExecutor子实例
final PipelineExecutor executor = getPipelineExecutor();
CompletableFuture<JobClient> jobClientFuture =
// execute方法内生成JobGraph,并提到了JobManager中
executor.execute(streamGraph, configuration, userClassloader);
// ...
}PipelineExecutor接口根据提供的配置执行管道。接口内只有一个execute方法。execute方法负责两件事,首先创建JobGraph,然后提交JobGraph到JobManager。
接口实现体系如下,分别对应不同的作业提交方式。
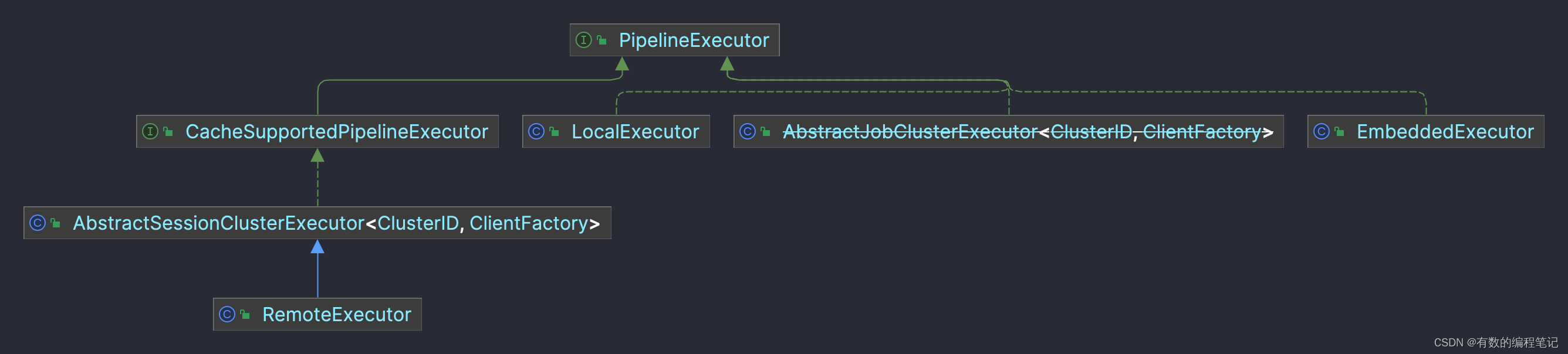
在IDEA中启动作业时,使用的是LocalExecutor,其execute方法实现如下。
java
@Override
public CompletableFuture<JobClient> execute(
Pipeline pipeline, Configuration configuration, ClassLoader userCodeClassloader)
throws Exception {
// ...
// 生成JobGraph实例
final JobGraph jobGraph = getJobGraph(pipeline, effectiveConfig, userCodeClassloader);
// 将JobGraph提交到集群中
return PerJobMiniClusterFactory.createWithFactory(effectiveConfig, miniClusterFactory)
.submitJob(jobGraph, userCodeClassloader);
}不同的ipelineExecutor实现,提交JobGraph的方式所有不同,但是创建JobGrpah的方式是相同。均使用FlinkPipelineTranslator的translateToJobGraph方式完成。
2. StreamGraphTranslator
FlinkPipelineTranslator接口负责将Pipeline转化为JobGraph。根据批或流场景分别有不同的实现。
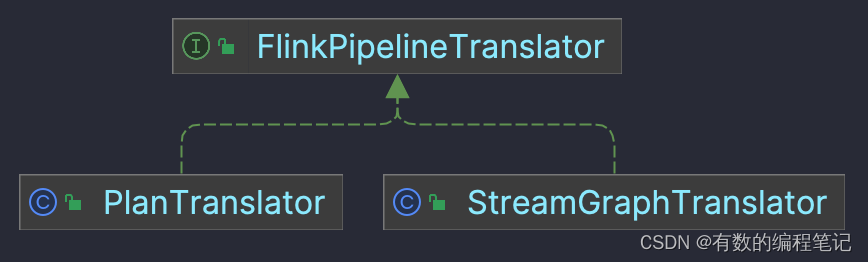
StreamingJobGraphGenerator负责完成StreamGraph到JobGraph的转换。
java
// FlinkPipelineTranslator(StreamGraphTranslator)
public JobGraph translateToJobGraph(
Pipeline pipeline, Configuration optimizerConfiguration, int defaultParallelism) {
checkArgument(
pipeline instanceof StreamGraph, "Given pipeline is not a DataStream StreamGraph.");
//调用StreamGraph方法
StreamGraph streamGraph = (StreamGraph) pipeline;
return streamGraph.getJobGraph(userClassloader, null);
}
// StreamGraph
public JobGraph getJobGraph(ClassLoader userClassLoader, @Nullable JobID jobID) {
return StreamingJobGraphGenerator.createJobGraph(userClassLoader, this, jobID);
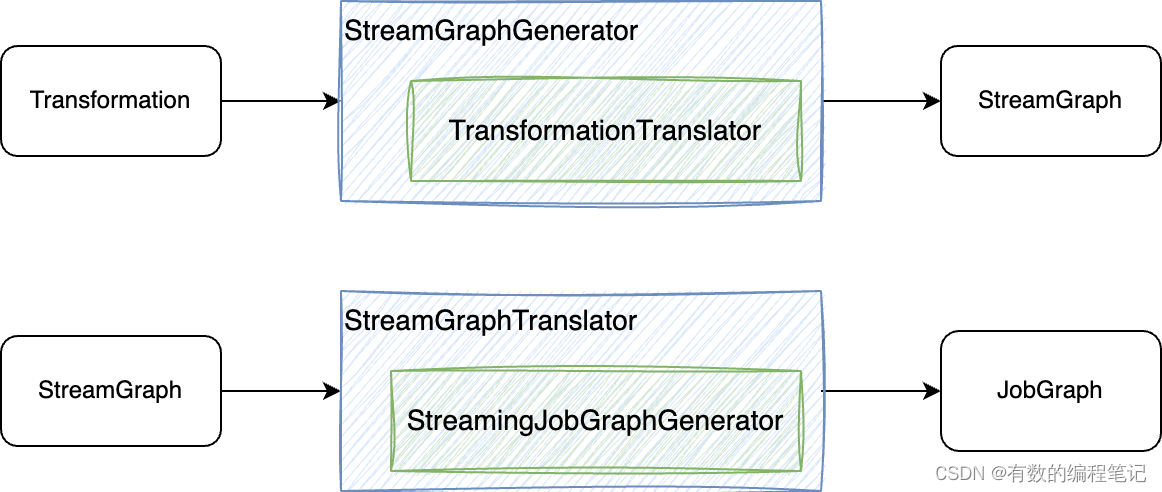
}回顾TransformationTranslator负责Transformation到StreamGraph转换,可以暂时归纳为,一般使用AaTranslator的封装完成由Aa到Bb的转换。方便对源码中某些类的理解。
StreamGraph和JobGraph生成过程封装类的相似之处,二者都提供了相应的Generator和Translator封装类,不同之处在于调用顺序的不同。
3. JobGraph
JobGraph表示flink数据流程序,处于JobManager接受的低级别。来自更高级别所API的所有程序都将转化为JobGraph。
JobGraph是从Client端到JobManager的最后一层封装,无论批或流作业都会转成JobGraph之后提交到JobManager。目的是为了统一处理批和流处理。
JobGraph同样表示DAG,包含节点JobVertex和边JobEdge。与StreamGraph相比,还多了表示中间结果集的IntermediateDataSet。因此本质上是将节点和中间结果集相连得到DAG。
IntermediateDataSet由JobVertex产生,由JobEdge消费其中的数据。
JobGraph中节点、边和中间结果集的关系示意如下。
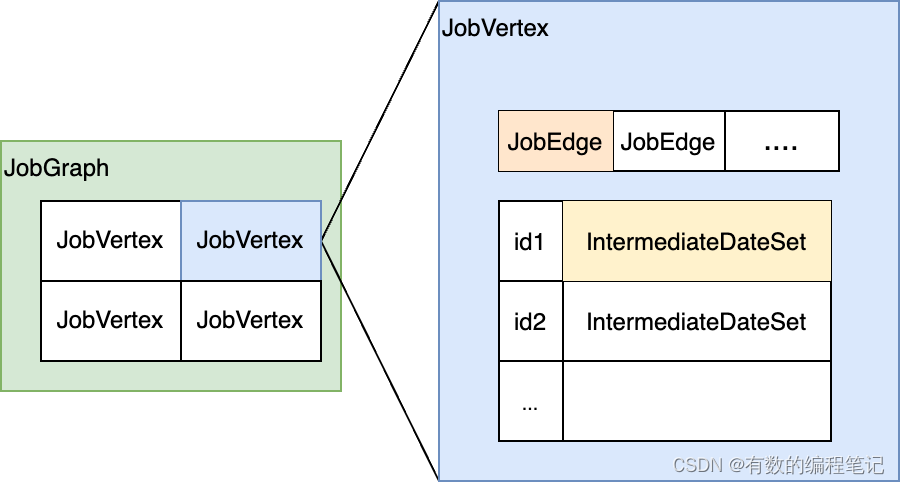
节点之间的联系如下。

JobGraph中重要属性如下。
java
// job id和名称
private JobID jobID;
private final String jobName;
// 作业类型,流或批
private JobType jobType = JobType.BATCH;
// JobGraph中包含的节点
private final Map<JobVertexID, JobVertex> taskVertices = new LinkedHashMap<JobVertexID, JobVertex>();3.1. JobVertex
JobGraph中的节点,会将符合条件的多个StreamNode链接在一起生成一个JobVertex。
JobVertex中重要属性如下。
java
// id,使用hash值表示,区别于StreamNode的id,StreamNode的id直接使用Transformation的id,是自增数字。
private final JobVertexID id;
// 名称
private String name;
// 输入,节点所有的输入边
private final ArrayList<JobEdge> inputs = new ArrayList<>();
// 输出,节点输出的中间结果集
private final Map<IntermediateDataSetID, IntermediateDataSet> results = new LinkedHashMap<>();
// 节点中包含的全部算子id,按深度优先的顺序对节点进行存储
private final List<OperatorIDPair> operatorIDs;
// taskManager根据该类名创建执行任务的类的对象(反射)。取StreamNode中vertexClass值,即StreamTask子类。
private String invokableClassName;JobVertex使用JobEdge表示输入,使用IntermediateDataSet表示输出。这点区别于StreamNode,StreamNode并没有严格的输入输出概念,只有上下游概念。
operatorIDs中元素个数等于JobVertex中包含的StreamNede节点个数。
OperatorIDPair类用于维护JobVertex中的节点信息,包含两个属性,表示节点id。
java
// 节点hash值
private final OperatorID generatedOperatorID;
private final OperatorID userDefinedOperatorID;3.2. IntermediateDataSet
逻辑结构,表示JobVertex的输出,JobVertex产生结果集的个数与对应SteamNode的出边相同。
java
// id,类型同JobVertexID
private final IntermediateDataSetID id;
// 产生该结果集的JobVertex,在构造方法中完成赋值
private final JobVertex producer;
// 下游消费结果集的JobEdge,产生JobEdge后调用其addConsumer方法赋值
private final List<JobEdge> consumers = new ArrayList<>();3.3. JobEdge
JobGraph中的JobEdge除表示边含义,连接上游生产的中间数据集和下游的JobVertex之外,更多的表示一种通信通道,上游JobVertex生产的中间结果集,由JobEdge消费数据至下游JobVertex。
java
// 下游节点
private final JobVertex target;
// 上游结果集
private final IntermediateDataSet source;
// 边的分布模式,决定生产任务的哪些子任务连接到那些消费子任务,
// ALL_TO_ALL:每个下游任务都消费这条边的数据,每个下游任务都消费这条边的数据,
// POINTWISE:一个或多个下游任务消费这条边的数据
private final DistributionPattern distributionPattern;4. 生成JobGraph
4.1. StreamingJobGraphGenerator
上文提到在流场景中,StreamingJobGraphGenerator负责完成StreamGraph到JobGraph的转换。接下来重点了解下实现过程。
StreamingJobGraphGenerator中关键字段如下,主要为表示链接的信息。
java
// 生成JobGraph的streamGraph
private final StreamGraph streamGraph;
// 结果JobGraph
private final JobGraph jobGraph;
// JobGraph中的节点集合,key=StreamNode id
private final Map<Integer, JobVertex> jobVertices;
// 已经处理完成的StreamNode id
private final Collection<Integer> builtVertices;
// 物理边,无法连接的两个StreaNode之间的边将成为物理边
private final List<StreamEdge> physicalEdgesInOrder;
// 保存链接信息
private final Map<Integer, Map<Integer, StreamConfig>> chainedConfigs;
// 保存链接的名称
private final Map<Integer, String> chainedNames;
// 保存节点信息
private final Map<Integer, StreamConfig> vertexConfigs;在createJobGraph方法中完成JobGraph的转换,该方法中涉及的内容较多。节点、边和中间结果集的创建将由setChaining方法完成。
4.1.1. 创建JobVertex
而StreamNode的id直接使用Transformation的id是自增数字,而JobVertex使用根StreamNode生成的hash值作为id,这点有所不同。因此首先会计算全部StreamNode的hash值,并维护StreamNode id和hash值的映射关系。为了向后兼容,还会为每个节点生成老版本的Hash值。
在代码中可以看到hashes和legacyHashes两个集合变量,分别存储新和老的hash值映射关系。
以StreamNode中的Source节点作为起点,通过递归方式处理全部节点。将连续且可进行连接的节点组合在一起生成一个JobVertex节点。举个例子,假如有上下游关系为1->2->3->4->5的节点,且3到4之间进行keyBy等操作,则1、2和3将链接在一起生成一个JobVertex节点,4和5将生成一个JobVertex节点。
通过Map<Integer, OperatorChainInfo>集合维护每个JobVertex中全部StreamNode的节点关系。
key为起点StreamNode id,key个数将和作业中生成算子链个数一致,初始时会将Source节点加入到集合中。
value放入一个封装类,用于createChain方法递归调用期间帮助维护operator chain的信息。
OperatorChainInfo类是定义在StreamingJobGraphGenerator中的内部类,其chainedOperatorHashes属性表示同一个算子链中全部的算子连接关系。
java
private static class OperatorChainInfo {
// OperatorChain的起点id
private final Integer startNodeId;
// 上文提到的StreamNode id和hash值的映射关系
private final Map<Integer, byte[]> hashes;
// 老版本的hash值映射关系
private final List<Map<Integer, byte[]>> legacyHashes;
// 链接到一起的算子关系,key是算子链的开始节点,list部分存放链接关系
// f0是当前节点的hash值,f1是legacyHashes相关的数据,大多数为null
private final Map<Integer, List<Tuple2<byte[], byte[]>>> chainedOperatorHashes;
private final Map<Integer, ChainedSourceInfo> chainedSources;
private final List<OperatorCoordinator.Provider> coordinatorProviders;
private final StreamGraph streamGraph;
private OperatorChainInfo(
int startNodeId,
Map<Integer, byte[]> hashes,
List<Map<Integer, byte[]>> legacyHashes,
Map<Integer, ChainedSourceInfo> chainedSources,
StreamGraph streamGraph) {
this.startNodeId = startNodeId;
this.hashes = hashes;
this.legacyHashes = legacyHashes;
this.chainedOperatorHashes = new HashMap<>();
this.coordinatorProviders = new ArrayList<>();
this.chainedSources = chainedSources;
this.streamGraph = streamGraph;
}
}createChain方法负责递归操作,递归过程为后序位置的处理方式,后序位置指的是先向下进行递归调用,直到不满足继续递归条件为止,然后按照递归过程由内向外方向执行每个节点的处理逻辑,后序位置的递归示意如下。
java
public void recursion(){
if(condition == true){
// 递归调用
recursion();
}
// 处理逻辑
// ...
}在createChain方法内部通过3个集合变量来维护节点下游信息。
每次递归处理时,依次判断与当前节点直接相连的下游节点是否可以与当前节点连接到一起,并分别加入到各自的集合中。然后对各自集合进行遍历递归处理。
java
private List<StreamEdge> createChain(StreamNode) {
// 物理出边,即算子链和算子链之间的边,算子链内部不存在边,一个算子链是一个整体。
// 物流出边,只有存在无法和前节点链接的节点时,当前边才会成为出边
List<StreamEdge> transitiveOutEdges = new ArrayList<StreamEdge>();
// 可以被链接的出边
List<StreamEdge> chainableOutputs = new ArrayList<StreamEdge>();
// 不可以被链接的出边
List<StreamEdge> nonChainableOutputs = new ArrayList<StreamEdge>();
StreanNode currentNode = ;
// 遍历当前节点全部出边,判断是否可链接
for (SteamEdge outEdge : 当前节点的全部出边) {
if (isChainable(outEdge)) {
// 可链接的边加入到chainableOutputs集合中
chainableOutputs.add(outEdge);
} else {
// 无法连接的边加入到nonChainableOutputs集合中
nonChainableOutputs.add(outEdege);
}
}
for (StreamEdge chainable : chainableOutputs) {
// 递归调用
transitiveOutEdges.addAll(createChain(StreamNode));
}
for (StreamEdge nonChainable : nonChainableOutputs) {
// 无法连接的将生成物理边,链接JobVertext节点
transitiveOutEdges.add(nonChainable);
// 递归调用
createChain(StreamNode);
}
// ===下面逻辑为节点具体的转化逻辑===
// 生成链接名称,并加入到chainedNames中
chainedNames.put(key,name);
// 将当前StreamNode加入到OperatorChainInfo的chainedOperatorHashes集合中
chainedOperatorHashes.put(startNodeId,list);
StreamConfig config = currentNodeId.equals(startNodeId)
// 当处理到算子链的第一个节点时,生成JobVertex
? createJobVertex(startNodeId, chainInfo)
: new StreamConfig(new Configuration());
// StreamConfig设置
config.set...;
// 算子链的起点时
if (currentNodeId.equals(startNodeId)) {
// 遍历出边,在connect方法中生成jobEdge和ntermediateDataSet
for (StreamEdge edge : transitiveOutEdges) {
NonChainedOutput output =
opIntermediateOutputs.get(edge.getSourceId()).get(edge);
connect(startNodeId, edge, output);
}
}
return transitiveOutEdges
}判断下游节点是否可以与当前节点进行链接由isChainable方法完成,首先需满足下游节点的入边为1的前提条件,满足该条件时,再根据上下游节点是否在相同slot、算子类型、上游算子ChainingStrategy类型、分区器、执行模型、并行度、StreamGraph是否允许链接等信息进行判断。
从每个算子链的最后一个节点开始处理链接关系。当处理到算子链的起点时,执行createJobVertex(startNodeId, chainInfo)逻辑来生成JobVertex,将JobVertex加入到JobGraph的jobVertices集合中。
4.1.2. 构键JobEdge和IntermediateDataSet
处理到算子链的起点时,遍历物理出边,依次生成JobEdge和IntermediateDataSet。connect方法完成此逻辑,核心逻辑如下伪代码所示。
java
private void connect(Integer headOfChain, StreamEdge edge, NonChainedOutput output) {
// 将边加入到physicalEdgesInOrder集合中
physicalEdgesInOrder.add(edge);
// 上游算子链
JobVertex headVertex = jobVertices.get(headOfChain);
// 下游算子链
JobVertex downStreamVertex = jobVertices.get(edge.getTargetId());
// JobEdge
JobEdge jobEdge = downStreamVertex.connectNewDataSetAsInput(
headVertex,
DistributionPattern.POINTWISE,
resultPartitionType,
opIntermediateOutputs.get(edge.getSourceId()).get(edge).getDataSetId(),
partitioner.isBroadcast());
}
// 生成IntermediateDataSet和边,并将二者加入到JobVextex中相应的集合中
public JobEdge connectNewDataSetAsInput(
JobVertex input,
DistributionPattern distPattern,
ResultPartitionType partitionType,
IntermediateDataSetID intermediateDataSetId,
boolean isBroadcast) {
// 生成结果集的同时,将节点作为结果集的生产者
IntermediateDataSet dataSet =
input.getOrCreateResultDataSet(intermediateDataSetId, partitionType);
JobEdge edge = new JobEdge(dataSet, this, distPattern, isBroadcast);
this.inputs.add(edge);
// 边加入到结果集的消费者中
dataSet.addConsumer(edge);
return edge;
}将JobVextex添加到IntermediateDataSet的produder属性中,将JobEdge加入到consumer属性中,分别作为中间结果集的生产者和消费者。
以上即为JobGrpah、JobVertex、JobEdge和IntermediateDataSet生成的简要逻辑。
4.1.3. 举个例子
生成JobGraph的代码逻辑比较复杂,生成各自实例后,还有相应的环境、配置等信息。本文主要对骨架逻辑进行了简要说明。通过一个稍复杂一些的示例来理解下上述过程。
假如有如下结构的StreamGraph,示例中边上存在红色X标记表示节点之间无法连接成算子链。
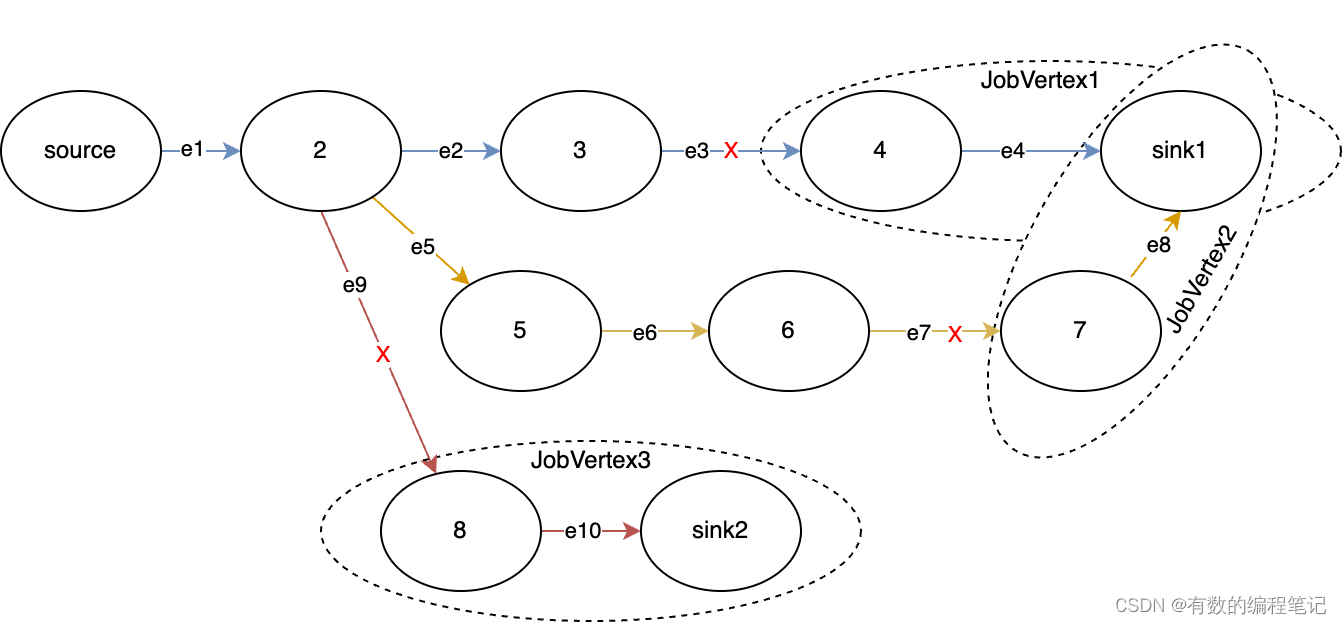
- 从source节点开始递归处理,当递归到节点2时,节点2存在3条出边,节点8无法与节点2链接,因此e2、e5加入到chainableOutputs,e9加入到nonChainableOutputs。然后分别遍历两个集合。
- e2方向当递归到节点3,节点4无法与节点3进行连接,e3将会成为一条物理边,并从节点4开始生成新的JobVertex,4->sink1节点生成JobVertex1。
- e5方向同理,e7将成为物理边,7->sink1节点生成JobVertex2。
- e9方向,e9为物理边,8->sink2节点生成JobVertex3。
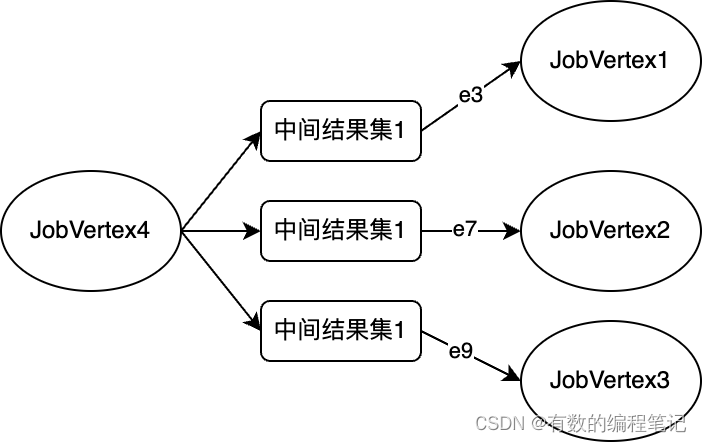
- 当节点2的下游节点全部处理完成,回到e2节点,再回到Source节点时,Source作为最开始算子链的起点,将开始生成最后一个JobVertex4,包含source、2、3、5、6节点。JobVertex4包含3条出边,因此将生成3个中件结果集和3条边,链接上面生成的JobVertex1、JobVertex2、JobVertex3。
最终生成的JobGrhap示例如下所示。