目录
1)普通字符普通字符)
2)特殊字符特殊字符)
1)" . ":" . ":)
2)" ^ ":" ^ ":)
[3)" ":](#3)" ":)
[3. 字符类 ](#3. 字符类 [ ])
1)abc[abc])
2)a-z[a-z])
3)\^[^])
1) " * " " * ")
2)" + "" + ")
3)" ? "" ? ")
4){n}{n})
5){n,}{n,})
6){n,m}{n,m})
1)(exp)(exp))
2)引用引用)
3)(?:exp)(?:exp))
[6. 标志](#6. 标志)
1)" i "" i ")
2)" m "" m ")
3)" s "" s ")
一.正则表达式是什么?
正则表达式 (Regular Expression,简称 Regex 或 Regexp )是一种用来描述字符串模式的工具,它可以用来匹配、查找以及替换文本中的特定文本片段。正则表达式由普通字符(例如字母、数字等)和特殊字符(元字符)组成,这些特殊字符具有特定的含义和用途。
二.正则表达式的使用场景
1.文本搜索和匹配
- 验证输入格式:例如验证邮箱地址、电话号码、密码复杂度等。
- 查找特定模式:从文本中提取符合特定格式的信息,比如查找网页中的链接、提取日期、找出所有匹配的单词等。
- 过滤和清洗文本:用于从文本中过滤出特定内容,或者进行敏感信息的替换。
2.编程中的字符串操作
- 文本处理:在编程中,正则表达式常用于字符串的匹配、替换和分割操作,例如在 Java、Python、JavaScript 等语言中,通过正则表达式对字符串进行复杂的处理操作。
3.日志分析和数据处理
- 日志提取:在大数据处理中,可以使用正则表达式从日志文件中提取特定信息,例如提取访问日志中的IP地址、请求路径等。
- 数据清洗:用于清洗和预处理数据,去除不需要的内容或者格式化数据。
4.文本编辑器和集成开发环境(IDE)
- 搜索和替换:现代文本编辑器和IDE通常支持正则表达式进行高级搜索和替换操作,帮助程序员快速定位和修改代码中的特定模式。
5.网络爬虫和数据抓取
- 网页内容提取:爬虫程序可以使用正则表达式从网页源代码中提取所需的信息,如抓取新闻标题、价格数据等。
6.数据库查询和数据处理
- 数据提取和过滤 :在数据库查询中,可以使用正则表达式进行数据的精确提取和过滤,如在 SQL 查询中使用
REGEXP条件进行复杂的数据筛选。
7.命令行工具和脚本
- 批量处理 :在 Unix/Linux 环境中,正则表达式常用于命令行工具如
grep、sed、awk等中,用来筛选、转换和处理文本数据
三.正则表达式的基本语法
1.字符的基本匹配
1)普通字符
大多数字符(如
a、X、9)在正则表达式中表示它们自己。
示例如下:
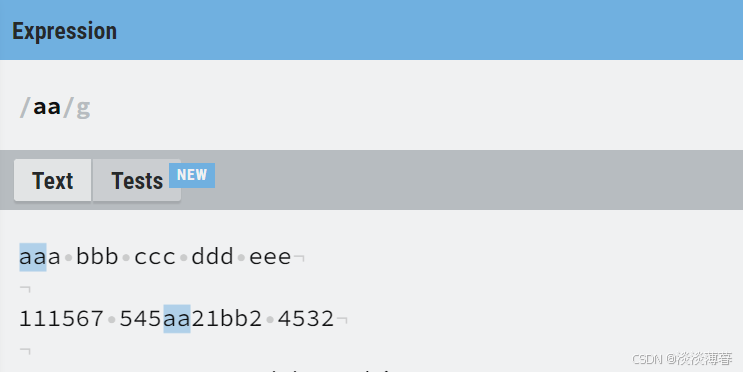
当我在表达式输入 'aa' 后,会自动匹配文中的 'aa'
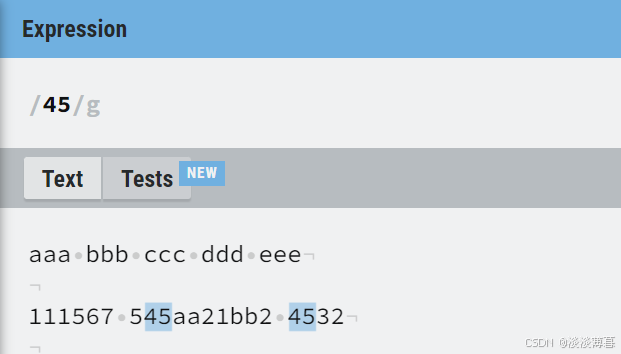
在表达式中输入数字 '45'
2)特殊字符
有特殊意义的字符,如
.、$、^、*、+、?、{}、[]、|、()、\,它们在正则表达式中有独特的含义,需要用反斜杠\进行转义,例如\.和\+
示例如下:

在表达式输入 '255\.' 后,会自动匹配文中的 '255.'
2.正则表达式的特殊字符
1)" . ":
匹配除换行符以外的任意单个字符
示例如下:
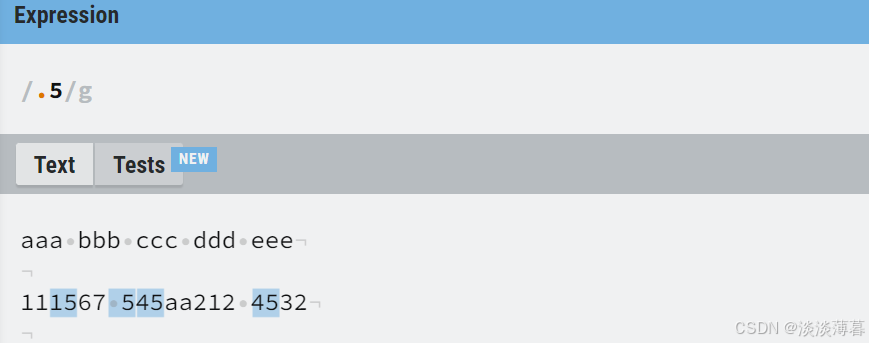
在表达式输入 '.5' 后,会自动匹配文中的5和它前面的任意一个字符 ,包括空白字符
2)" ^ ":
匹配输入字符串的开始位置
示例如下:
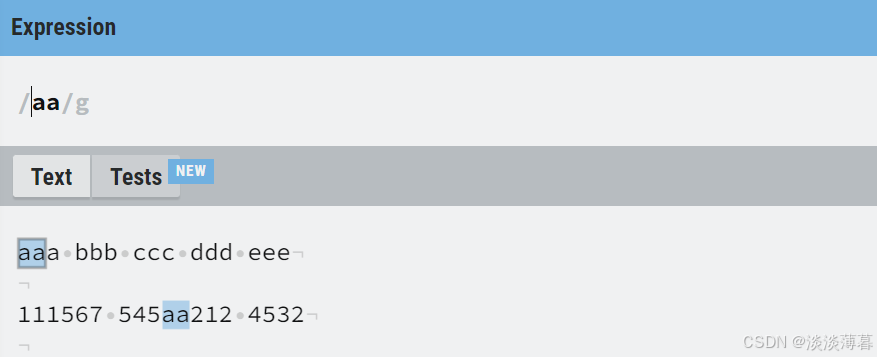
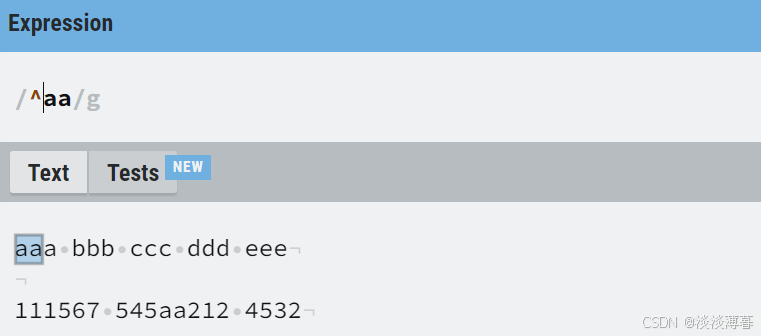
加上 ' ^ ' 后,就只有每段开头的 'aa' 被匹配到了
3)" $ ":
匹配输入字符串的结束位置
示例如下:
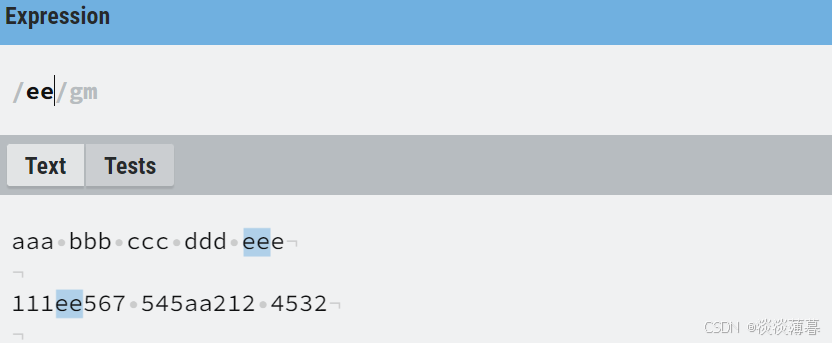
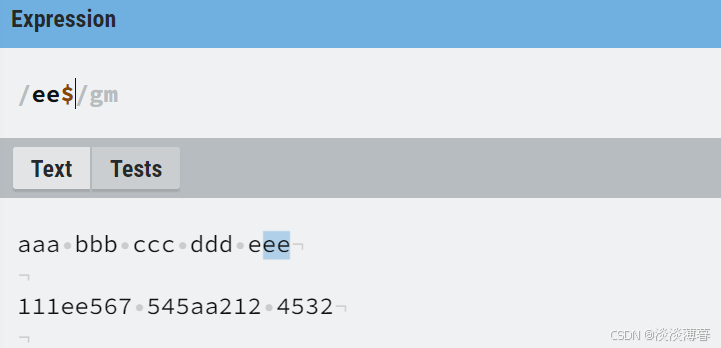
加上 ' $ ' 后,就只有每段结尾的 'ee' 被匹配到了
3. 字符类
1)[abc]
匹配任何一个列在括号中的字符(如
a、b、或c)
示例如下:

匹配到了 'at' 'bt' 'ct' , 里没有d ,所以没有匹配到 'dt'
2)a-z
匹配任何一个从
a到z的小写字母
示例如下:
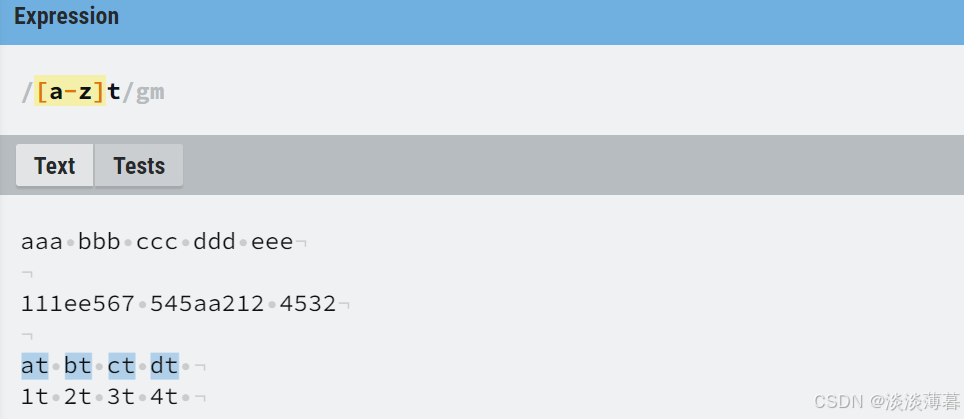
a-z->a到z的任意一个字符都可以匹配,
(可以写成任意两个字符之间的范围:a-f,c-v等等)

0-9->0到9的任意一个字符都可以匹配,

(可以将两个及以上的范围写到一起)a-z0-9 : 0到9或a-z的任意一个字符都可以匹配
3) [^]
匹配任何不在括号中的字符 ( 当' ^ '在 当中时 )
示例如下:

除了小写英文字母的所有字符都可以匹配
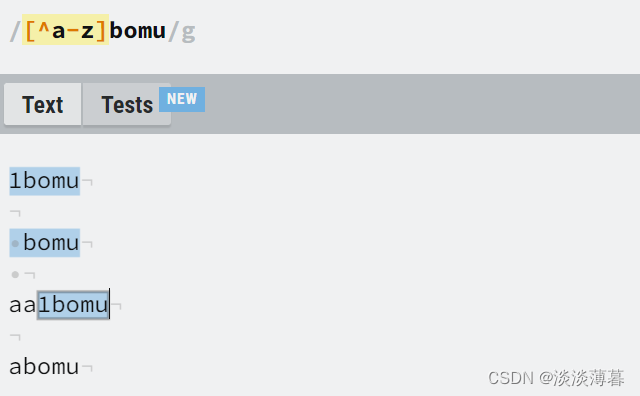
任意一个非小写字母+bomu都可以匹配
4.量词
1) " * "
匹配前面的子表达式零次或多次
示例如下:

w后面接零个或多个o都可以匹配

' . '表示匹配任意一个字符,' .* '就表示匹配任意长度的字符串
2)" + "
匹配前面的子表达式一次或多次
示例如下:

字符o至少要出现一次的情况
3)" ? "
匹配前面的子表达式零次或一次
示例如下:

字符w出现一次或零次的情况
4) {n}
精确匹配 n 次
示例如下:

字符o出现了一次的情况
5) {n,}
匹配 n 次或更多次
示例如下:

字符o出现一次及以上的情况
6) {n,m}
匹配 n 到 m 次
示例如下:

字符o出现2到3次的情况
5.分组和引用
1)(exp)
匹配
exp并捕获文本到自动命名的组里,它可以通过\1、\2等引用
示例如下:

@后面(abc)可出现零次或多次的情况
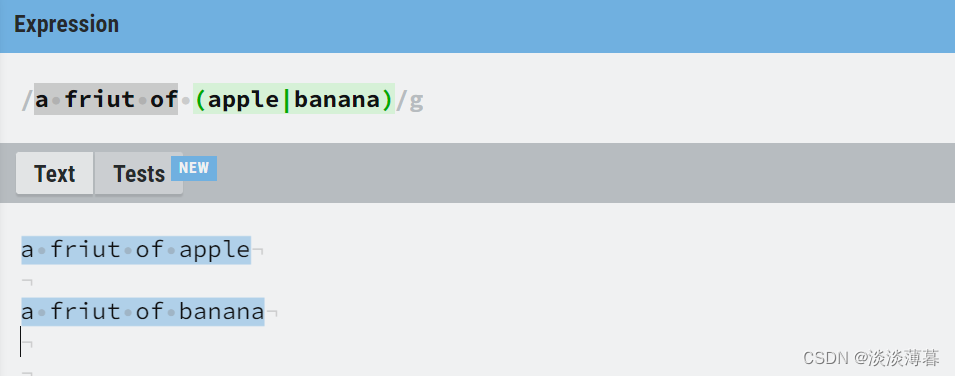
a friut of 后面匹配apple或banana的情况
2)引用
对于每次数据进行匹配时(一行的数据或其他情况),对于所有匹配成功的组都会按顺序编号存储起来(/1 ,/2 ,/3....等等,不同版本的编号的命名方式可能不一样)方便我们再次使用它们
例如:
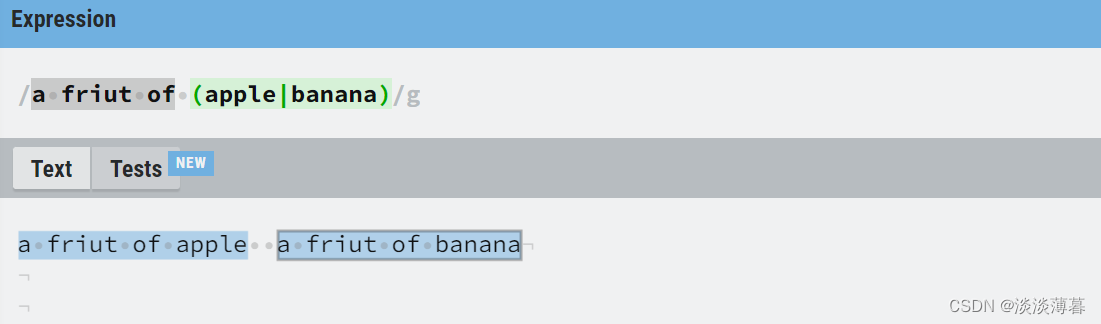
此时匹配成功的有两组,它们的编号分别是/1和/2
当我们使用/1时,系统就会对应上 a friut of apple,使用/2时,系统就会对应上 a friut of banana
3)(?:exp)
匹配
exp但是不捕获匹配的文本,不给此括号组分配组号
正常匹配符号分组的字符串,但是系统将不会编号
6. 标志
当我们使用正则表达式的时候,可以设置一些标志来改变处理方式
1)" i "
使匹配不区分大小写
2)" m "
多行模式,
^和$可以匹配行首行尾
3)" s "
使
.匹配包括换行符在内的所有字符
到这里关于正则表达式的讲解就结束了~