目录
[一、对于 sogou_500w_utf 数据,使用 MapReduce 编程模型完成对以下数据的分析任务。](#一、对于 sogou_500w_utf 数据,使用 MapReduce 编程模型完成对以下数据的分析任务。)
[1. 统计搜索的关键字查询频度,找出搜索次数超过 20 次的关键字的个数。](#1. 统计搜索的关键字查询频度,找出搜索次数超过 20 次的关键字的个数。)
[① 运行截图](#① 运行截图)
[② 源代码](#② 源代码)
[二、改造 WordCount 程序,使得结果的排序规则为按照单词词频从大到小排序。](#二、改造 WordCount 程序,使得结果的排序规则为按照单词词频从大到小排序。)
[1. 输入](#1. 输入)
[2. 输出](#2. 输出)
[3. 源代码](#3. 源代码)
一、对于 sogou_500w_utf 数据,使用 MapReduce 编程模型完成对以下数据的分析任务。
1. 统计搜索的关键字查询频度,找出搜索次数超过 20 次的关键字的个数。
① 运行截图
bash
hadoop jar /home/2130502441ryx/SogouKeyWord.jar org/ryx/KeyWordDriver /sogou.500.utf8 /output8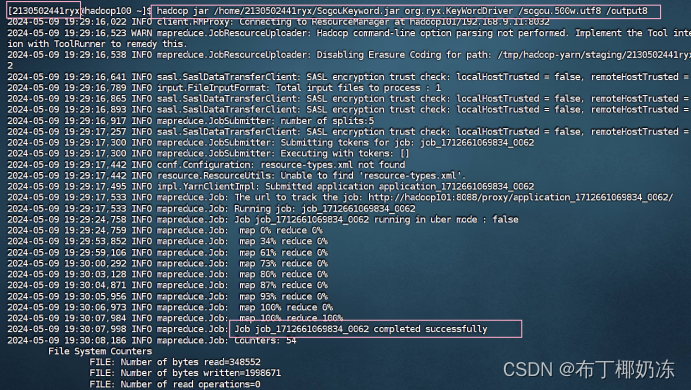
查看输出文件
bash
hdfs dfs -ls /output8
查看运行结果:(前四十条)
bash
hdfs dfs -cat /output8/part-r-00000 | head -n 40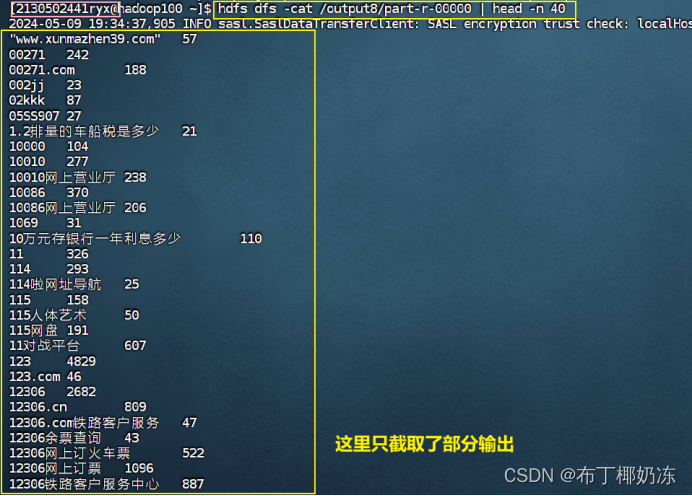
② 源代码
KeyWordMapper.java
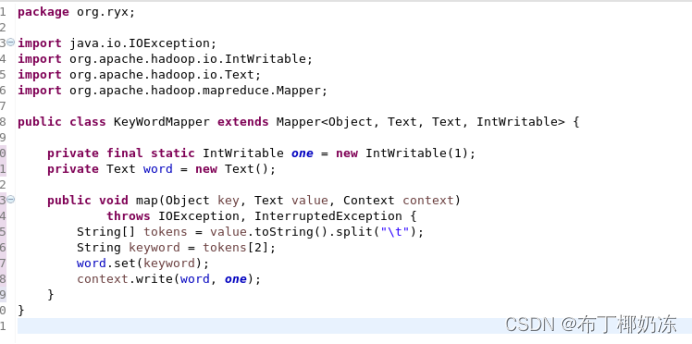
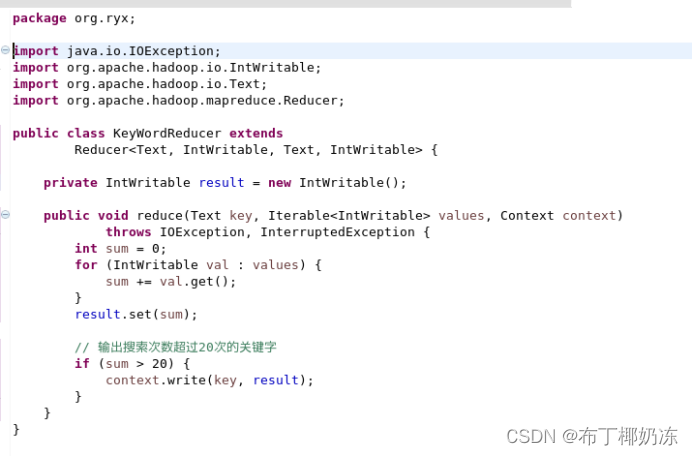
KeyWordReducer.java
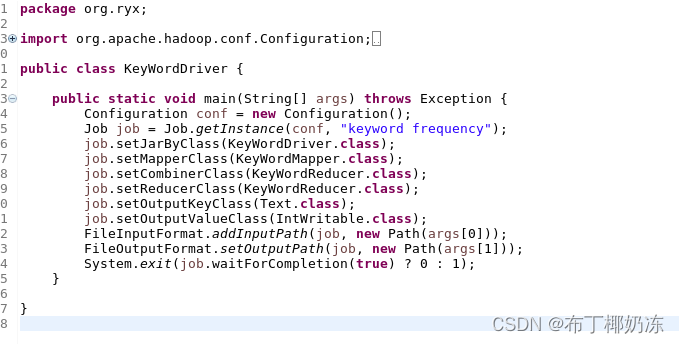
KeyWordDriver.java
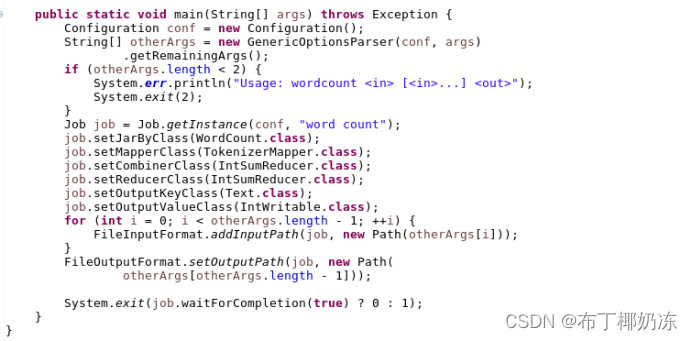
二、改造 WordCount 程序,使得结果的排序规则为按照单词词频从大到小排序。
1. 输入
bash
hdfs dfs -cat /input2
2. 输出
bash
hadoop jar /home/2130502441ryx/MapReduceTest.jar org/ryx/WordCount /input2 /output9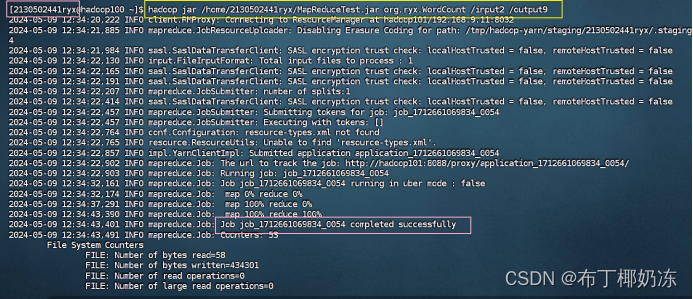
bash
hdfs dfs -ls /output9
hdfs dfs -cat /output9/part-r-00000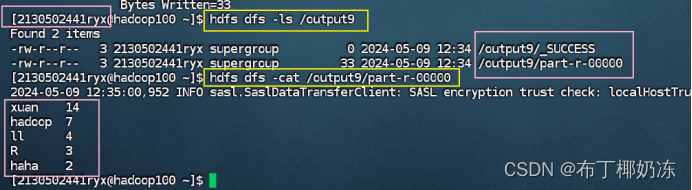
3. 源代码