TL;DR
- 场景:三台 Linux 机器部署 Elasticsearch 7.3.0,多节点联机与系统参数校正。
- 结论:按目录权限→系统内核/limits→ES 配置→分发→启动顺序执行,能稳定形成集群。
- 产出:可复用的命令清单、最小化配置模板、常见错误定位与修复清单。

版本矩阵
| 项目 | 已验证 | 说明 |
|---|---|---|
| Elasticsearch 7.3.0 (linux-x86_64 tar.gz) | ✅ | 按文中下载与解压路径部署到 /opt/servers/elasticsearch-7.3.0。 |
| 节点数量:3(h121/h122/h123) | ✅ | 每节点 node.name 唯一;通过 rsync 分发配置后做节点名/host 差异化。 |
| 目录与权限 | ✅ | /opt/servers/es/{data,logs} 属主 es_server;ES 目录 chown -R es_server。 |
| 运行用户 | ✅ | 使用 es_server 启动,禁止 root。 |
| 系统参数(内核/limits) | ✅ | vm.max_map_count=655360;nofile 65536、nproc 4096。需 sysctl -p 生效。 |
| JVM 堆 | ✅ | -Xms2g / -Xmx2g(示例值,建议按物理内存≈50%评估)。 |
文件夹设置
三台机器都要执行,建立文件夹,这里是 日志、数据等内容。
shell
mkdir -p /opt/servers/es
mkdir -p /opt/servers/es/data
mkdir -p /opt/servers/es/logs
chown -R es_server /opt/servers/es
chown -R es_server /opt/servers/es/data
chown -R es_server /opt/servers/es/logs
复制项目
我们目前有三台机器,上节我们完成了一台机器的配置。现在我们把三台机器都安装上ES的环境,你可以每台都下载,或者使用同步工具来同步。
shell
rsync-script /opt/software/elasticsearch-7.3.0-linux-x86_64.tar.gzh121主机
h121是主机,这里是之前下载的。
shell
cd /opt/software
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.3.0-linux-x86_64.tar.gz
shell
tar -zxvf elasticsearch-7.3.0-linux-x86_64.tar.gz
mv elasticsearch-7.3.0 ../servers/处理完的结果如下图所示: 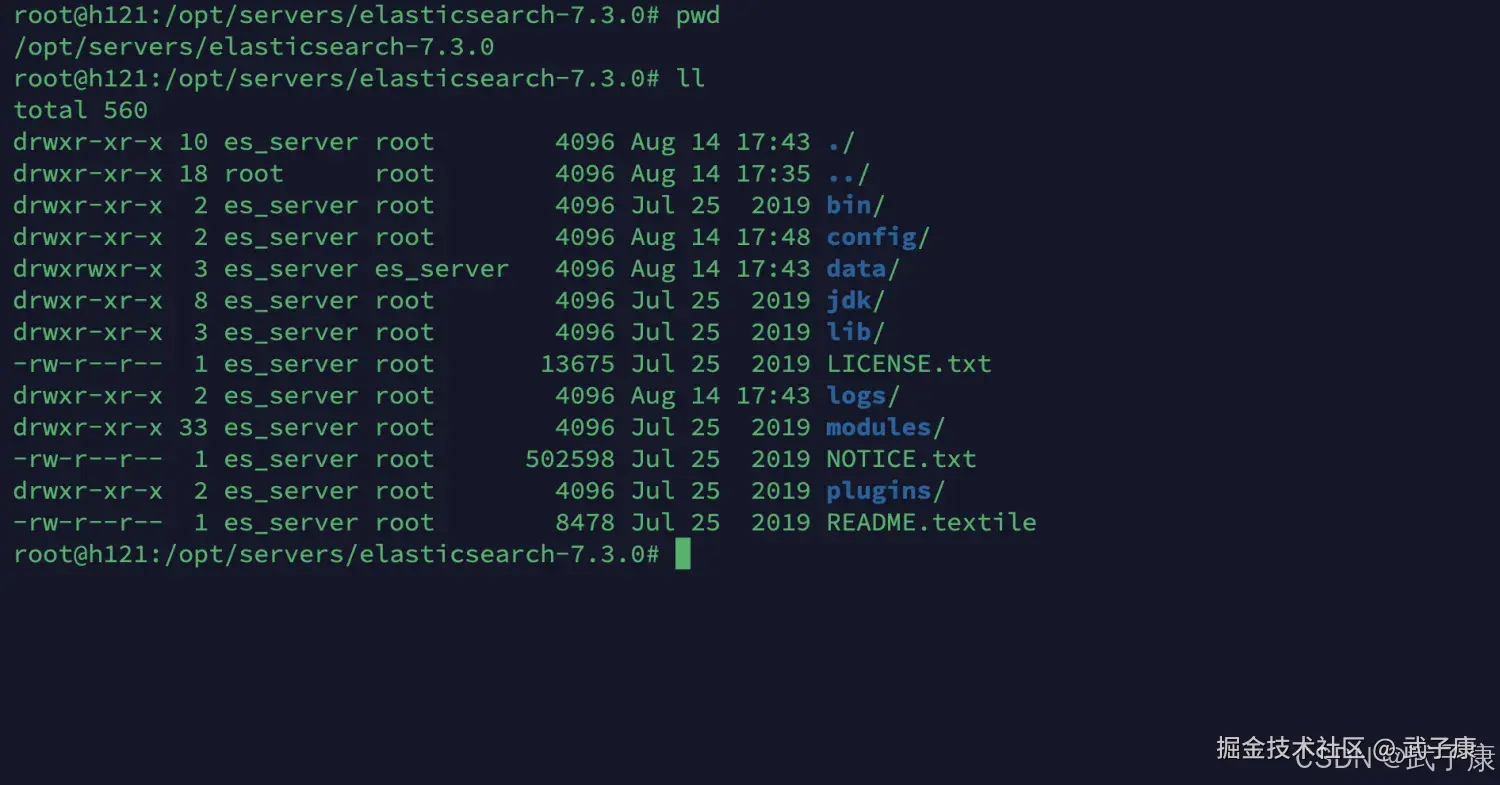
创建用户
三台机器都要设置对了,我的账号和密码是一样的,都是 es_server。
shell
useradd es_server
passwd es_server文件夹设置
三台机器都要执行,建立文件夹,这里是 日志、数据等内容。
shell
mkdir -p /opt/servers/es
mkdir -p /opt/servers/es/data
mkdir -p /opt/servers/es/logs
chown -R es_server /opt/servers/es
chown -R es_server /opt/servers/es/data
chown -R es_server /opt/servers/es/logs目录权限
shell
chown -R es_server /opt/servers/elasticsearch-7.3.0配置完的路径如下图所示: 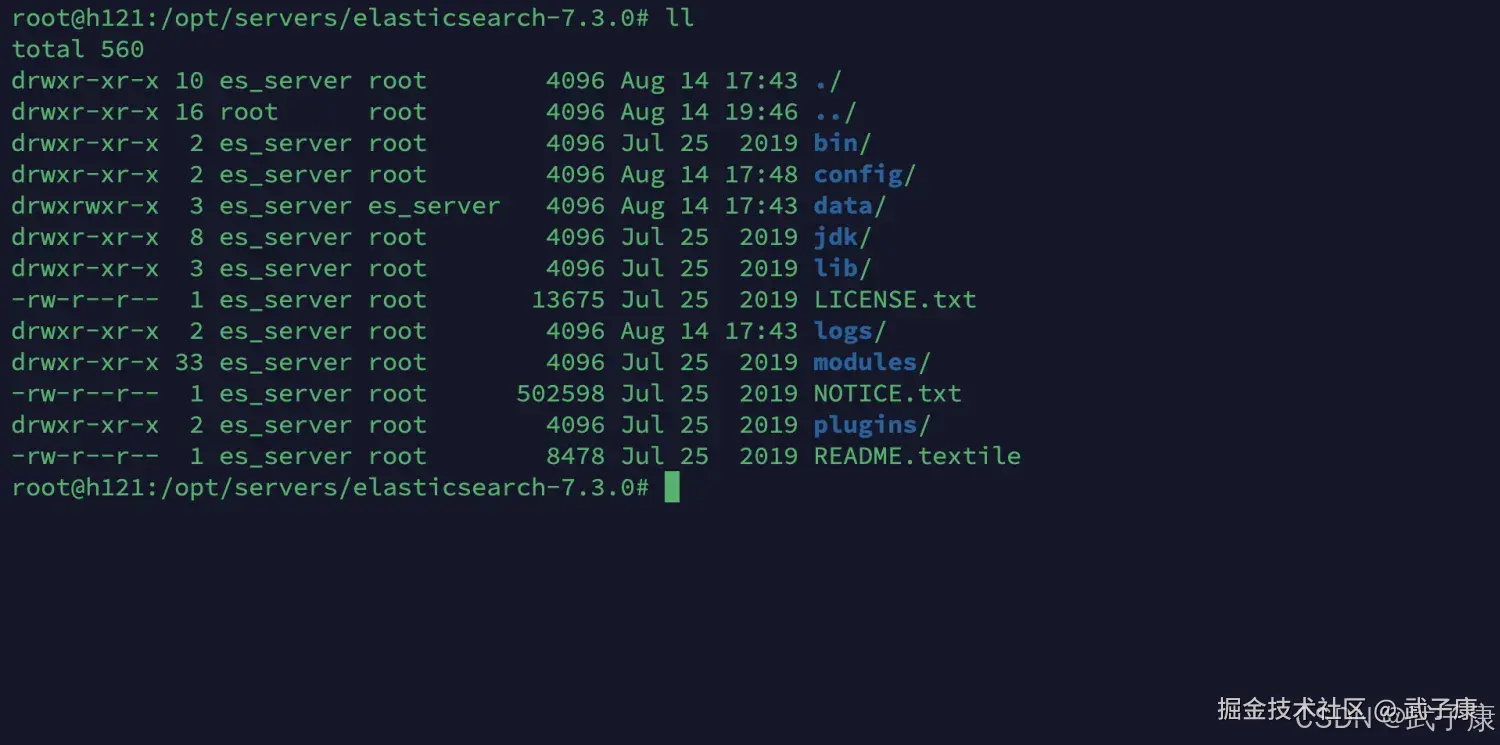
sudo权限
三台机器使用root用户执行sudo然后为es用户添加权限:
shell
vim /etc/sudoers添加以下的内容:
shell
es ALL=(ALL) ALL添加的截图如下图所示: 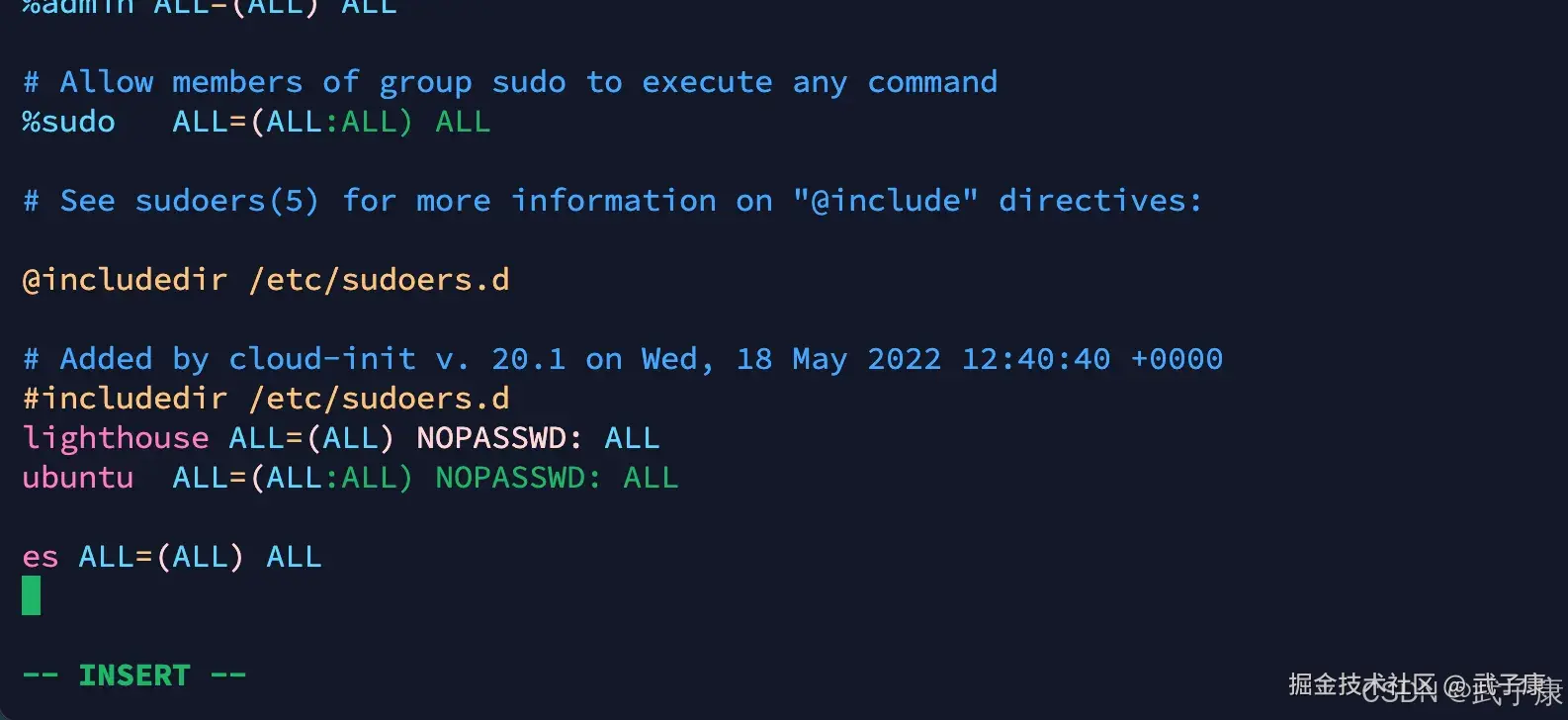
配置说明
elasticsearch.yml 配置文件说明如下: 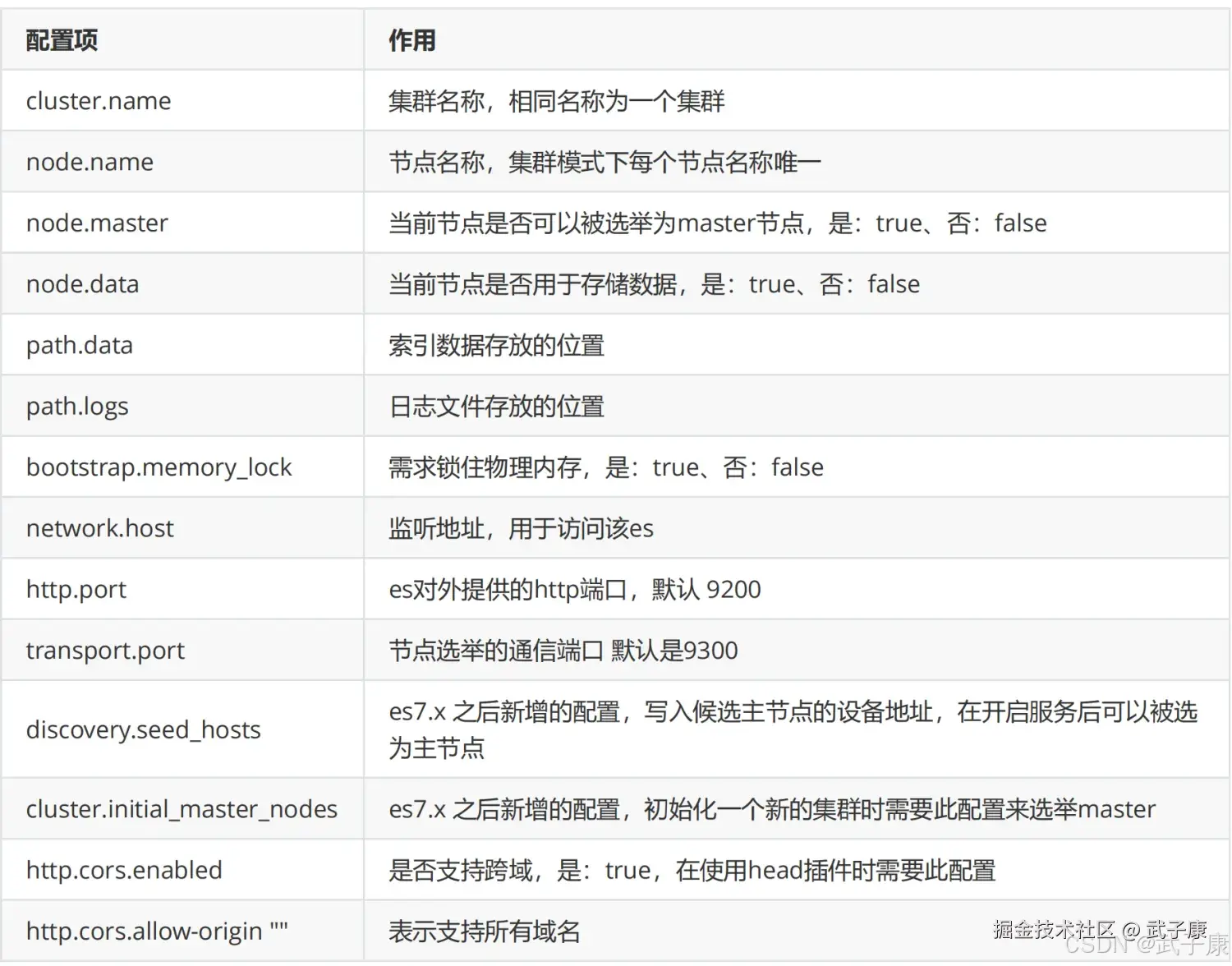
修改配置
三台机器都要执行,我们需要修改配置文件信息:
shell
cd /opt/servers/elasticsearch-7.3.0/config
vim elasticsearch.yml修改配置的内容有如下这些:
shell
# 集群名字
cluster.name: wzkicu-es
# 集群中当前的节点
node.name: h121.wzk.icu
# 数据目录
path.data: /opt/servers/es/data
# 日志目录
path.logs: /opt/servers/es/logs
# 当前主机的ip地址
network.host: h121.wzk.icu
network.bind_host: h121.wzk.icu
# 这里如果网卡绑定的不对 可以写死你的公网IP
network.publish_host: 114.115.221.144
http.port: 9200
# 初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["h121.wzk.icu","h122.wzk.icu","h123.wzk.icu"]
# 写入候选主节点的设备地址
discovery.seed_hosts: ["h121.wzk.icu", "h122.wzk.icu","h123.wzk.icu"]分发配置
为了保证三个文件的配置内容一致(手动修改name等除外),我们直接分发配置的整个文件夹过去:
shell
rsync-script /opt/servers/elasticsearch-7.3.0/config这样可以防止认证等信息错误导致的不必要的错误,对应的配置内容如下,注意在 h122 和 h123 节点上,node.name 等内容要根据实际情况修改: 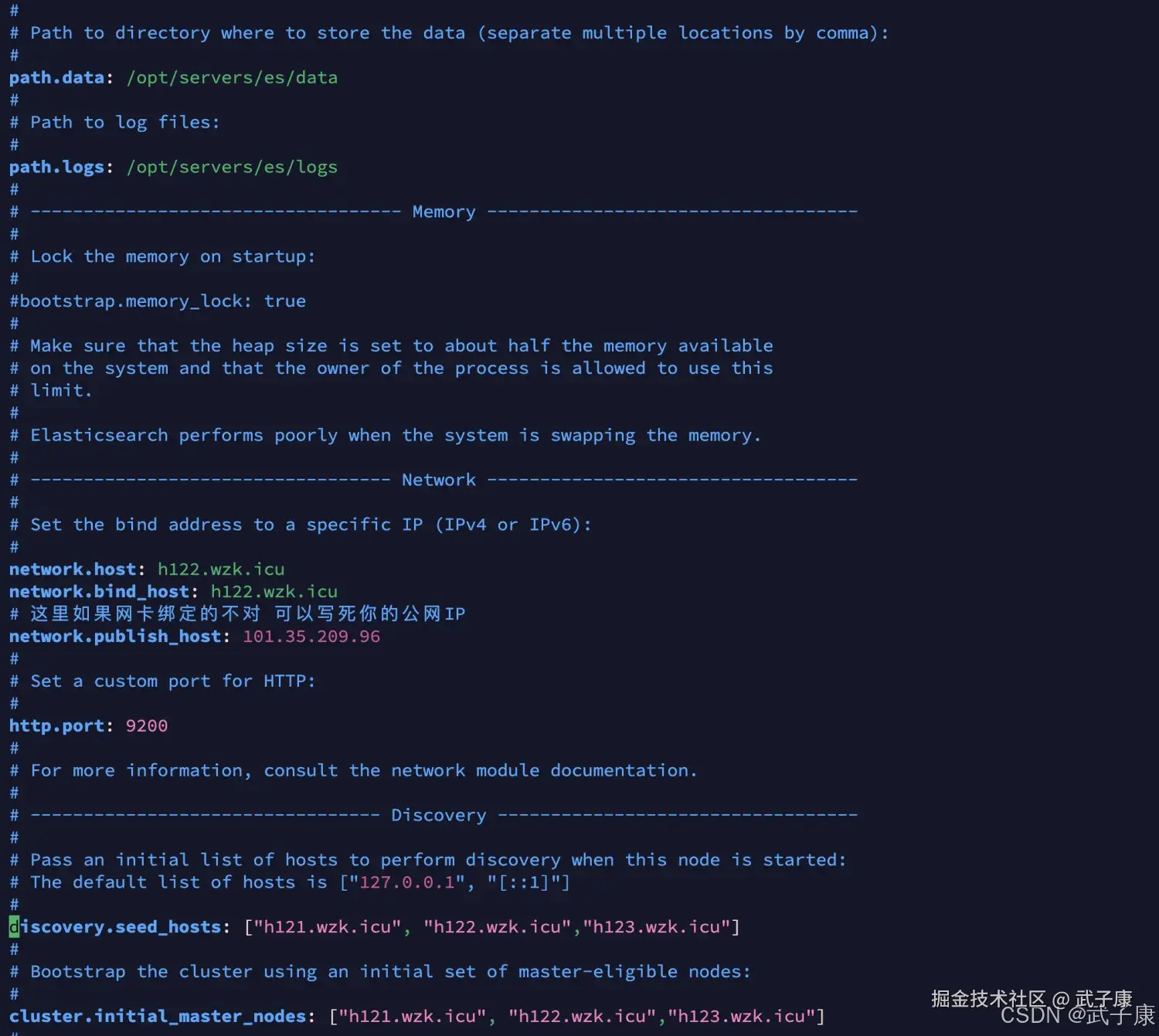
(注意:network部分是比较容易出问题的,如果你出了问题,必须绑定的网卡不对,导致IP的问题等,那你需要向我这样配置,来指明绑定的地址等内容) (注意:如果你一切正常,那按之前的来就行,没有必要增加不必要的复杂度) 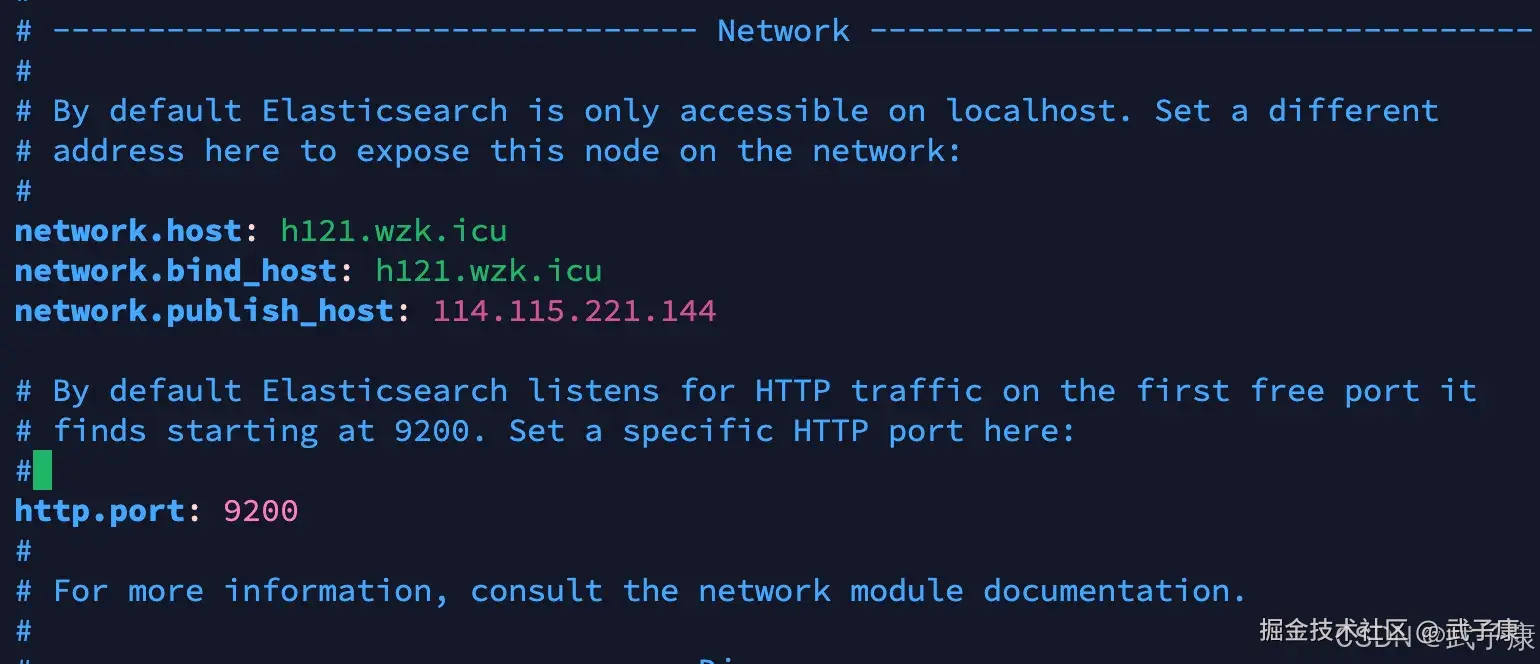
系统参数
记得和上节一样,修改 JVM 内存大小:
shell
cd /opt/lagou/servers/es/elasticsearch/config
vim jvm.options修改内存的参数:
shell
-Xms2g
-Xmx2g此外和上节一样,如果你没修改操作系统的限制,如果你启动报错的话,请回到上节,修改 limits 等参数配置。具体的内容如下: 修改 sysctl.conf:
shell
vim /etc/sysctl.conf末尾我们添加:
shell
vm.max_map_count=655360修改的结果如下图所示: 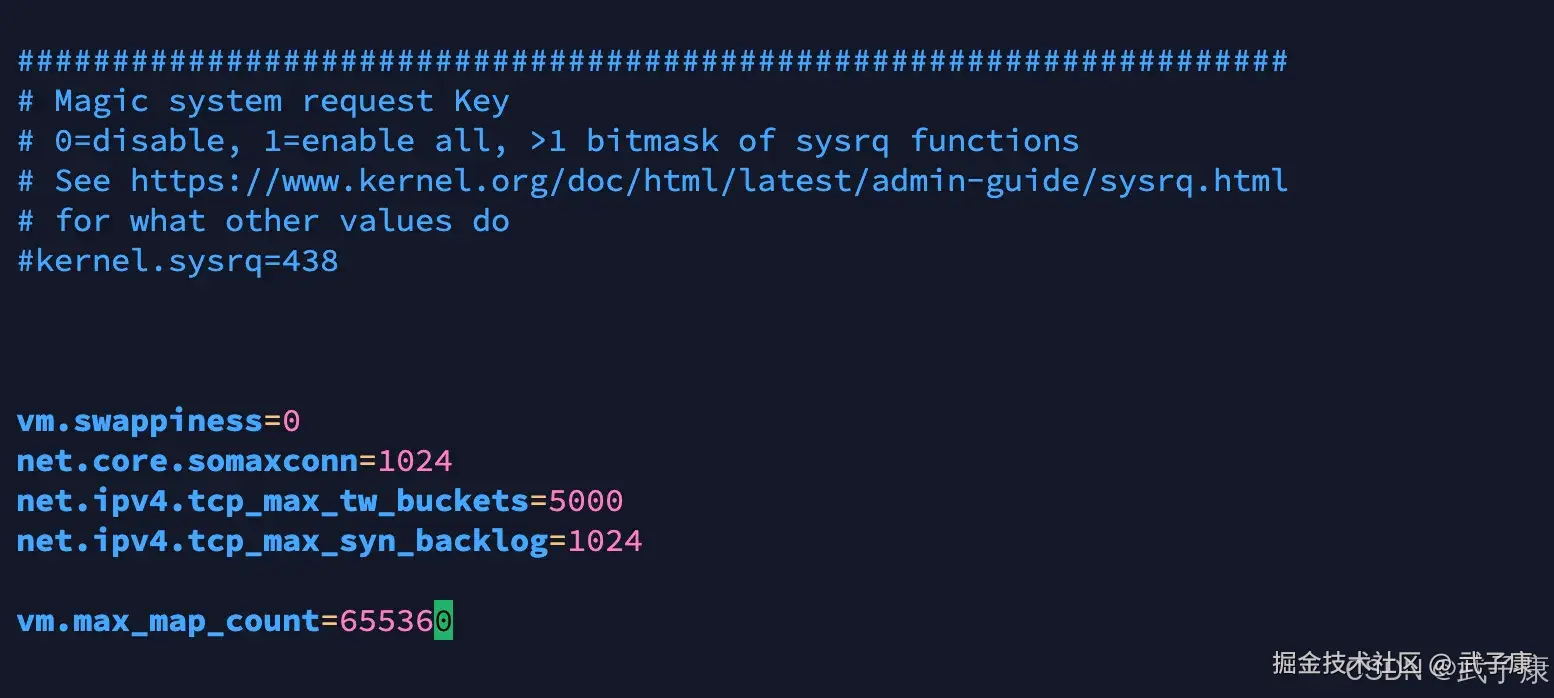 执行 sysctl -p,让配置生效:
执行 sysctl -p,让配置生效:
shell
sysctl -p运行结果如下图所示:  继续修改:limits.conf,目的是修改Linux系统对文件描述符的限制级别:
继续修改:limits.conf,目的是修改Linux系统对文件描述符的限制级别:
shell
vim /etc/security/limits.conf我们需要在末尾添加如下的内容:
shell
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096截图如下所示: 
启动服务
这里是启动,要发现错误的话,可以到 logs 目录下查看,我们在三台机器上都执行:
shell
su es_server
/opt/servers/elasticsearch-7.3.0/bin/elasticsearch -dh121
h121 启动 ES服务,启动结果如下: 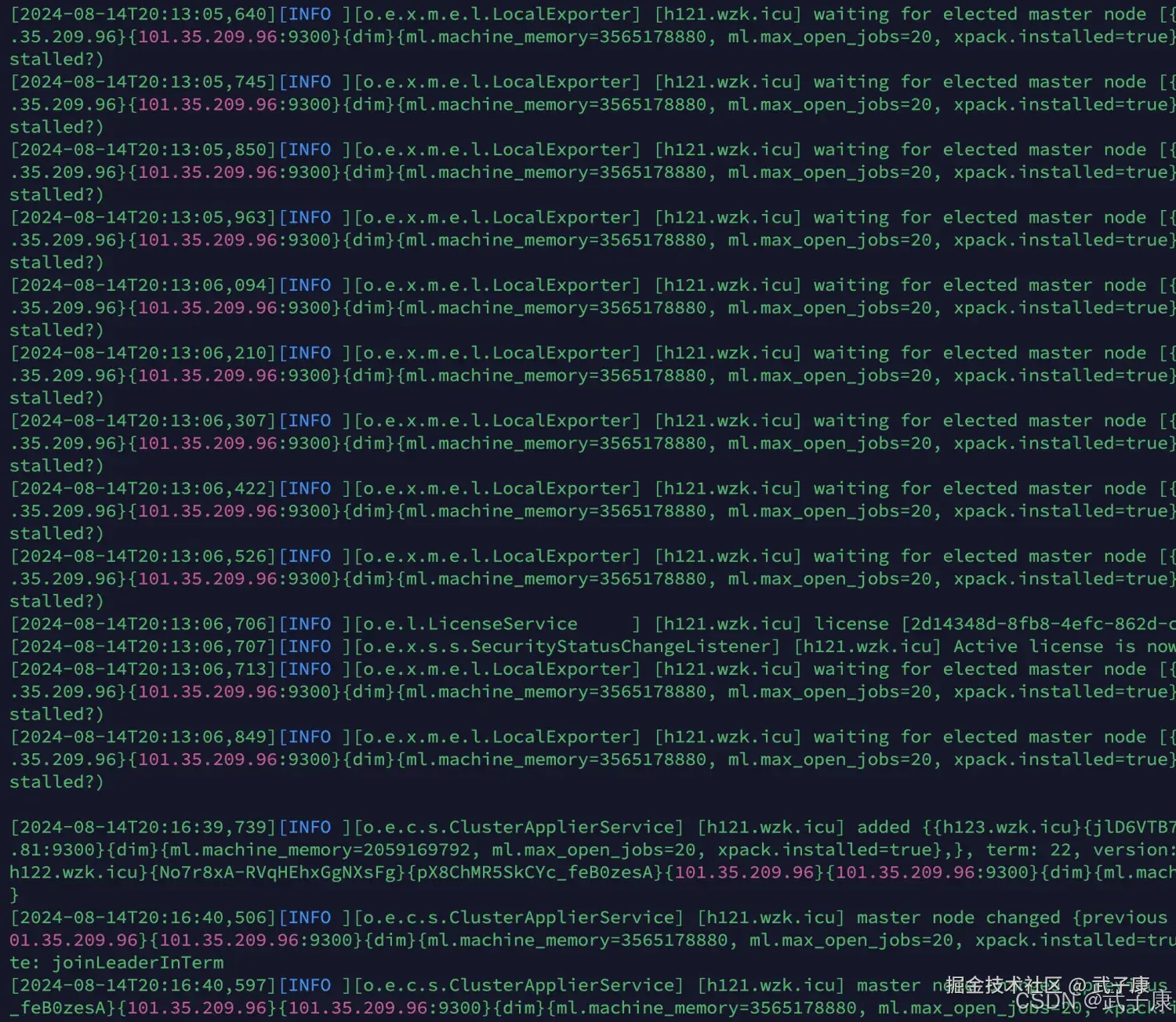 对应的网页内容:
对应的网页内容: 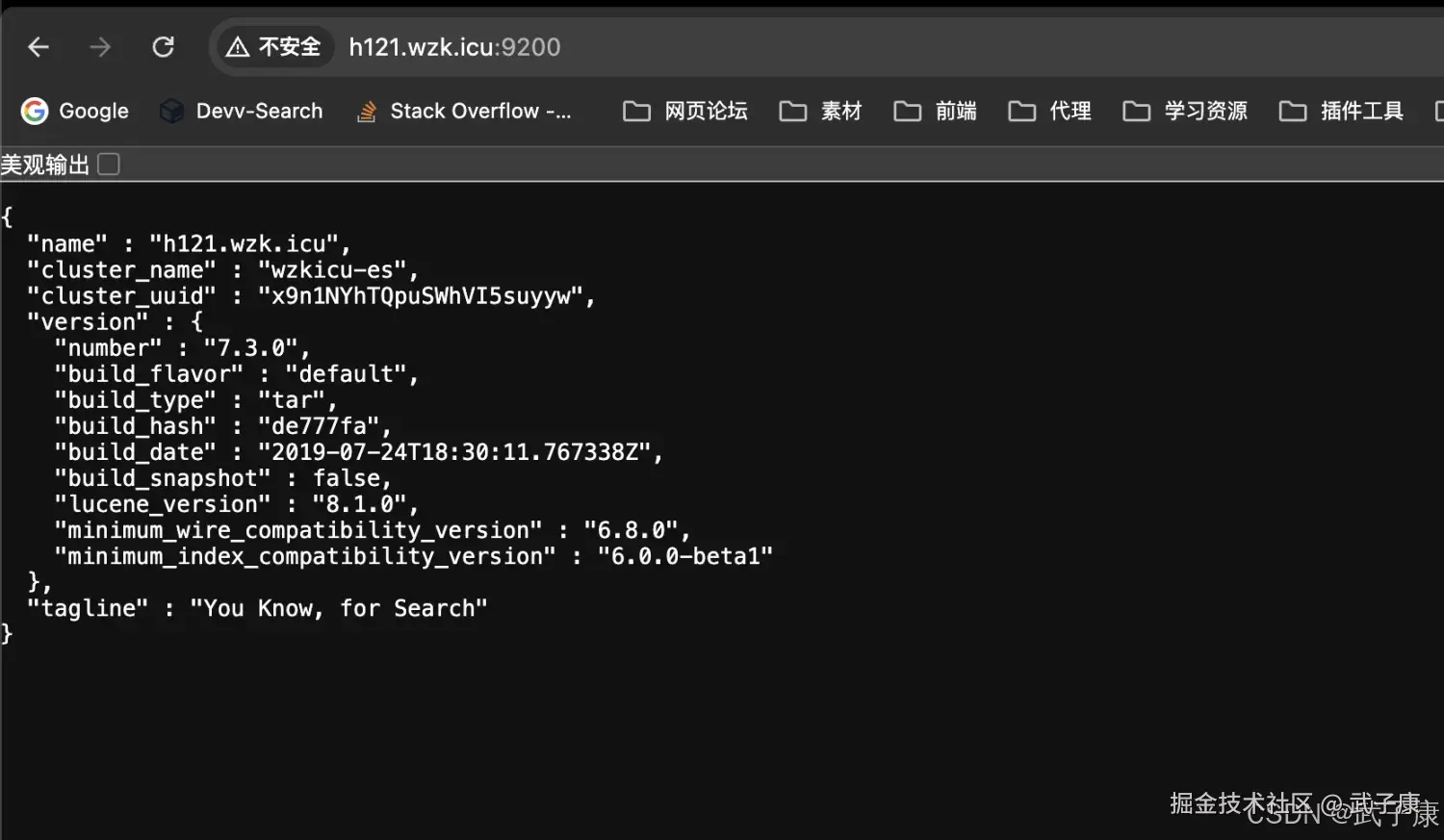
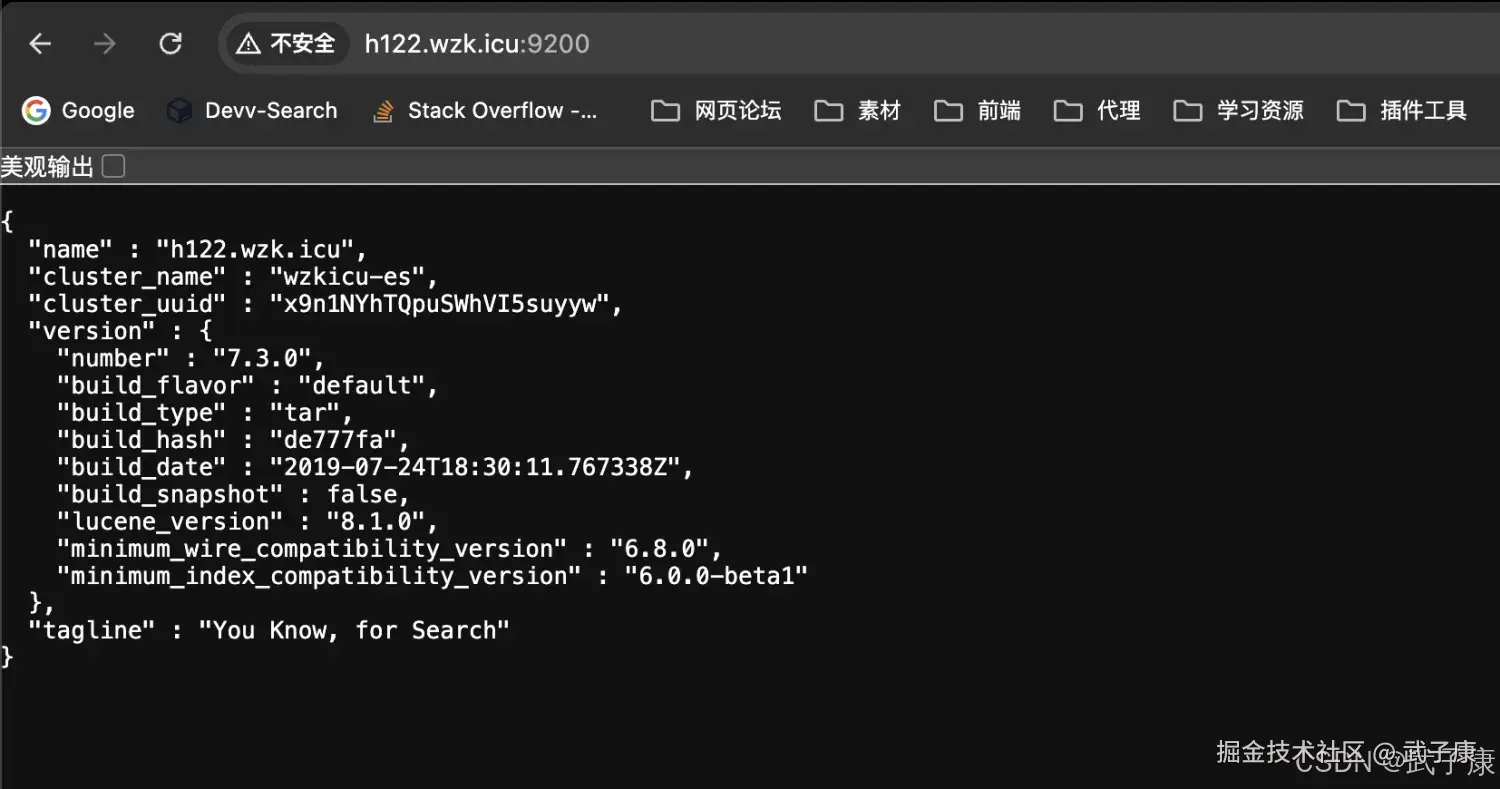
h122
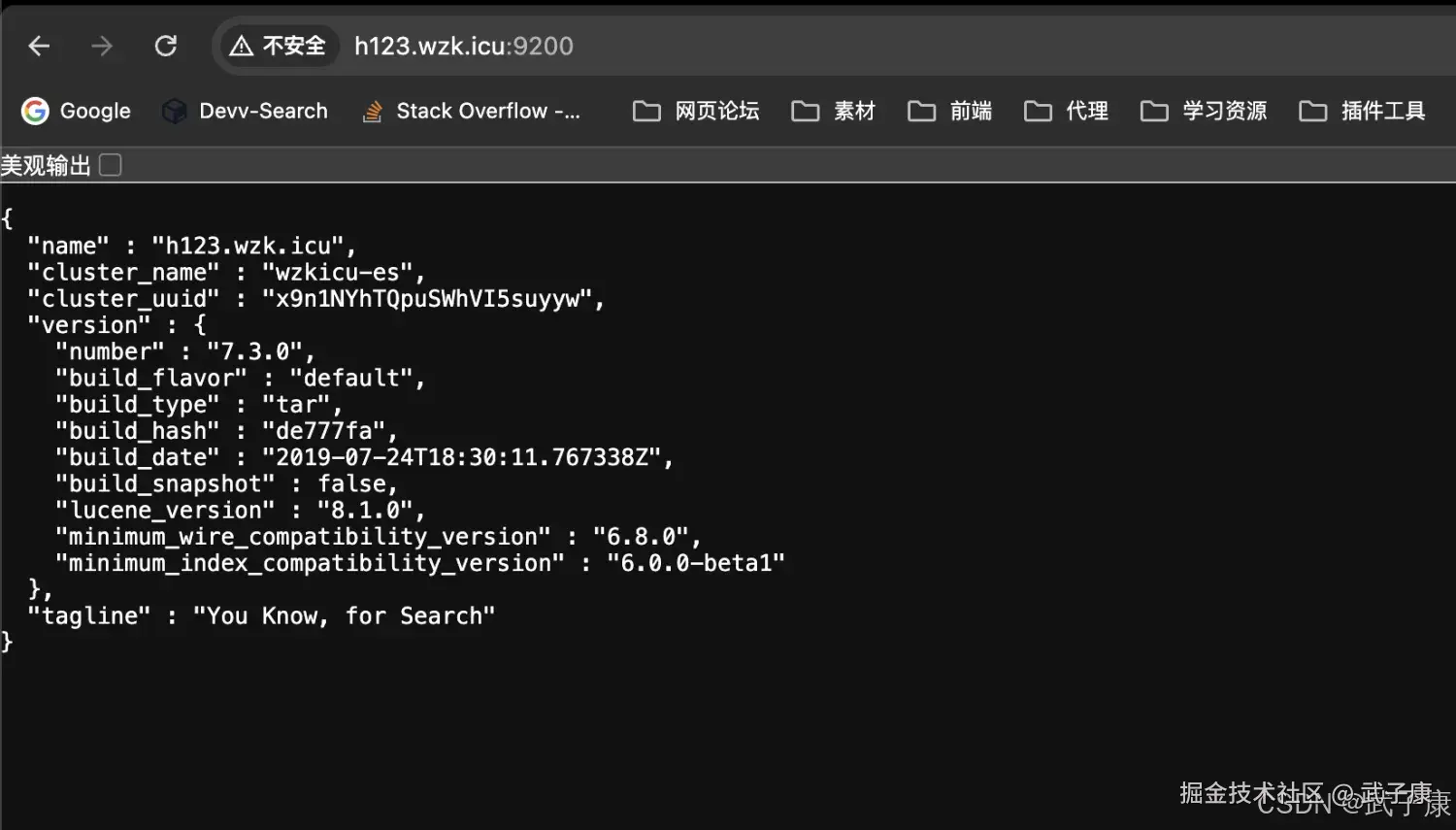
h123
访问集群
如果我们使用Elasticsearch Head工具查看,可以看到是集群的状态,对应的截图为: 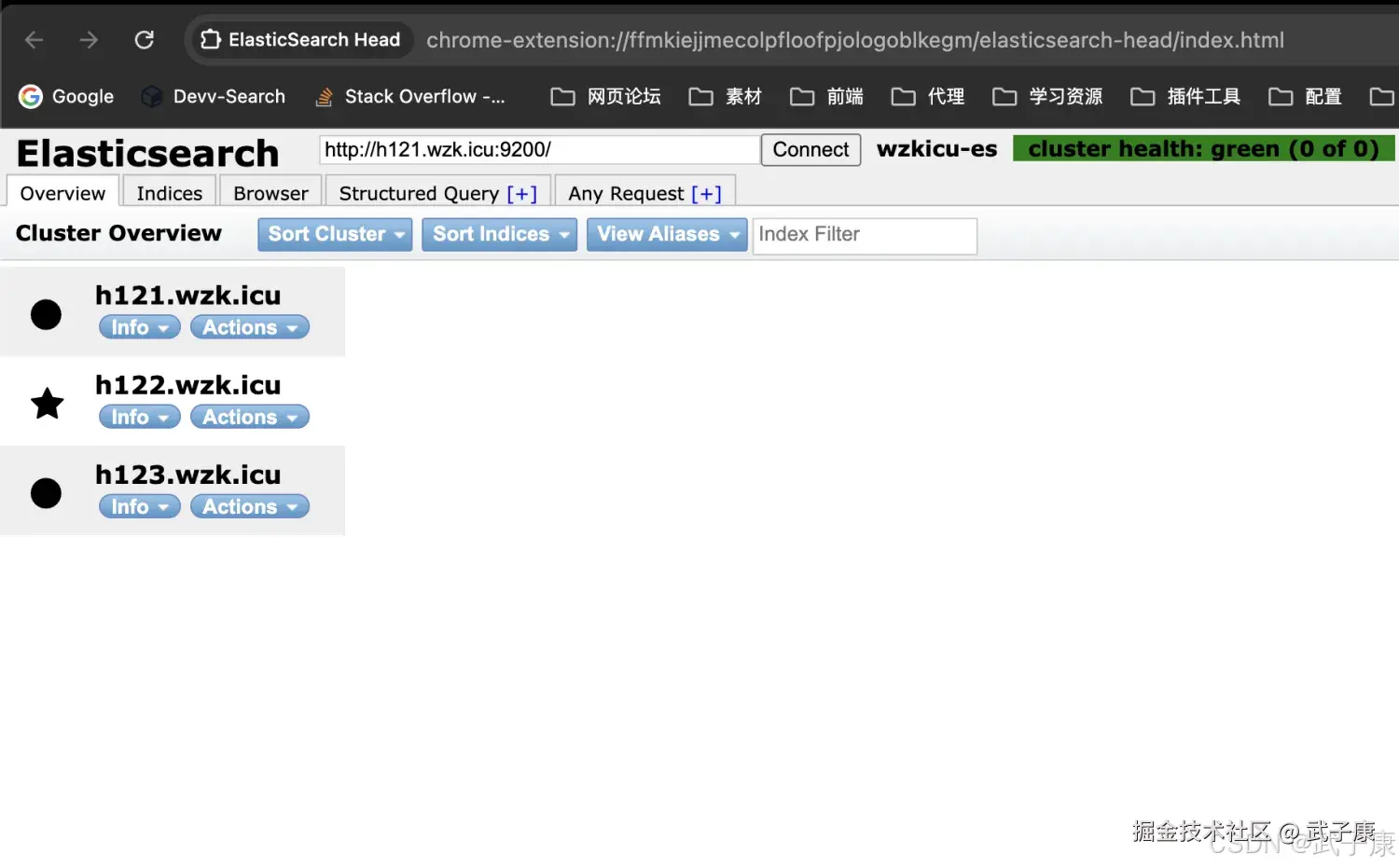
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 启动即报"max virtual memory areas vm.max_map_count too low" | 未设置内核参数 | dmesg/日志首屏 | /etc/sysctl.conf 加 vm.max_map_count=655360,sysctl -p |
| "max file descriptors 4096 for elasticsearch process is too low" | limits 未生效 | ulimit -n |
limits.conf 设置 nofile 65536、nproc 4096,重新登录生效 |
| ES 拒绝以 root 运行 | 以 root 启动 | 启动日志警告 | 切换为 su es_server;确保 ES 目录属主为 es_server |
| 节点启动但不入集群 | 9300 未通/主机名解析失败/discovery.seed_hosts 不可达 |
netstat/telnet 9300/nslookup |
放通内网 9300;修正 discovery.seed_hosts 为可解析可达地址;统一 /etc/hosts/DNS |
publish_host 误指向外网或错误网卡 |
网络绑定错误 | 启动日志中的绑定地址 | 将 network.host/publish_host 指向实际内网地址或正确网卡;必要时用具体 IP |
| 集群黄/红,分片未分配 | 节点角色/磁盘水位/路径权限问题 | _cluster/health 与日志 |
检查磁盘阈值与 path.data 权限;确保 3 节点同时在线且可分片 |
| "node name already in use" | 多节点 node.name 重复 |
日志报错 | 为 h121/h122/h123 分配唯一 node.name |
| 启动后 9200 可访但跨节点搜索失败 | 9300 互通性问题 | 跨节点查询异常日志 | 核查防火墙与安全组;确认 transport 层正常互通 |
rsync 后配置全同导致冲突 |
未按节点改 node.name/network.* |
节点日志冲突提示 | 分发后逐节点校正差异项并重启 |
| 暴露在公网被扫/高风险 | 对外开放 9200/9300 且未鉴权 | 访问日志异常 IP | 仅内网暴露;或启用 xpack.security、TLS、源 IP 访问控制 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-127 Qwen2.5-Omni 深解:Thinker-Talker 双核、TMRoPE 与流式语音
💻 Java篇持续更新中(长期更新)
Java-174 FastFDS 从单机到分布式文件存储:实战与架构取舍 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 正在更新,深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解