深度学习基准模型Transformer
深度学习基准模型Transformer,最初由Vaswani等人在2017年的论文《Attention is All You Need》中提出,是自然语言处理(NLP)领域的一个里程碑式模型。它在许多序列到序列(seq2seq)任务中,尤其是机器翻译,展现了卓越的性能,并逐渐成为处理序列数据的标准架构之一。以下是Transformer模型的关键特点和组件:
- Self-Attention机制:这是Transformer模型的核心创新。与传统的循环神经网络(RNNs)不同,Self-Attention允许模型并行处理序列中的所有位置,通过计算输入序列中所有元素对的相互关系来捕捉依赖关系,极大地提升了模型处理长距离依赖的能力和训练速度。
- Positional Encoding:由于Self-Attention机制本身不具备顺序信息,Transformer通过加入位置编码来为输入序列的每个位置附加一个固定的向量,这样模型就能区分不同位置的输入信息,确保模型理解序列中元素的顺序。
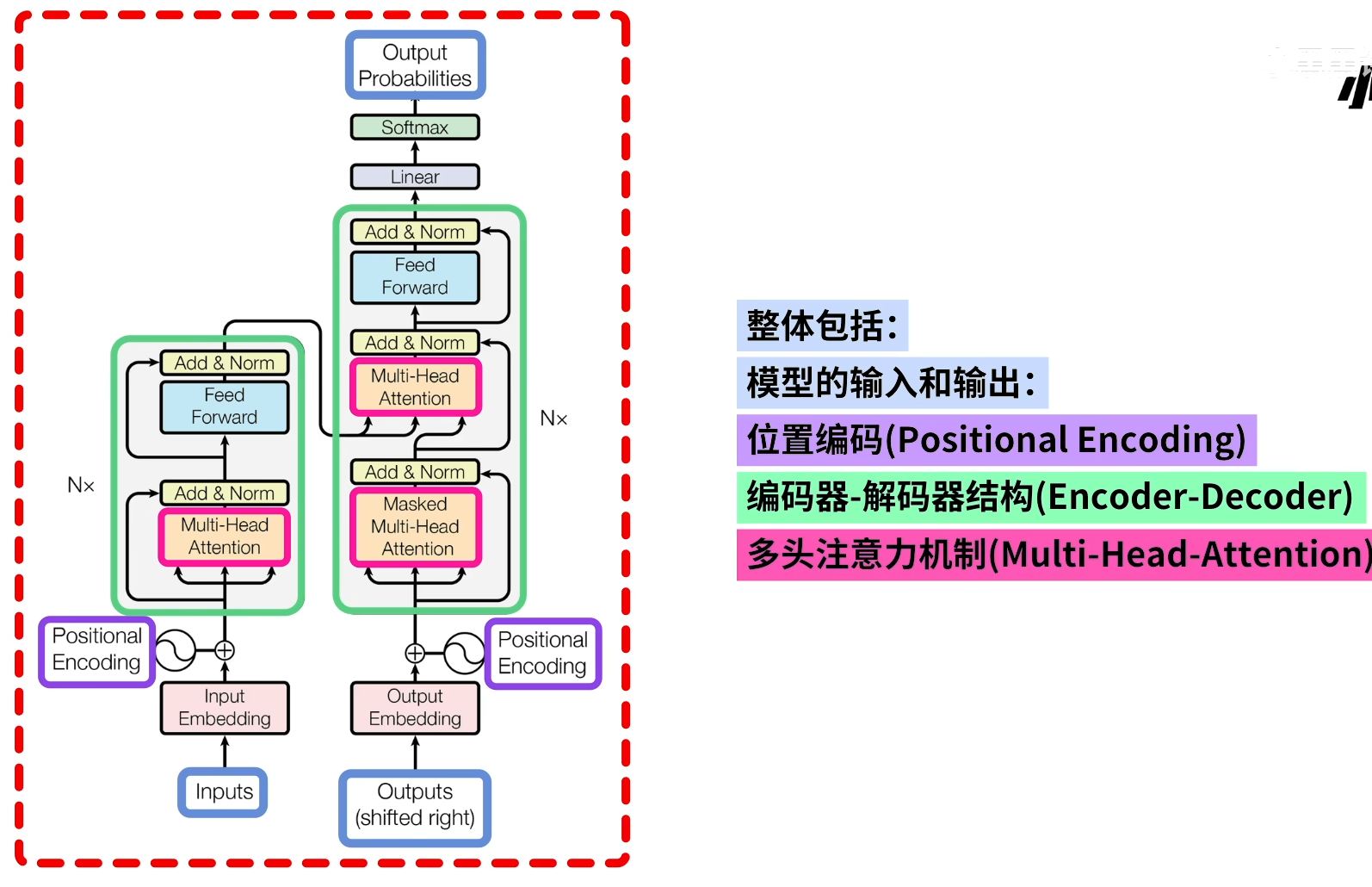
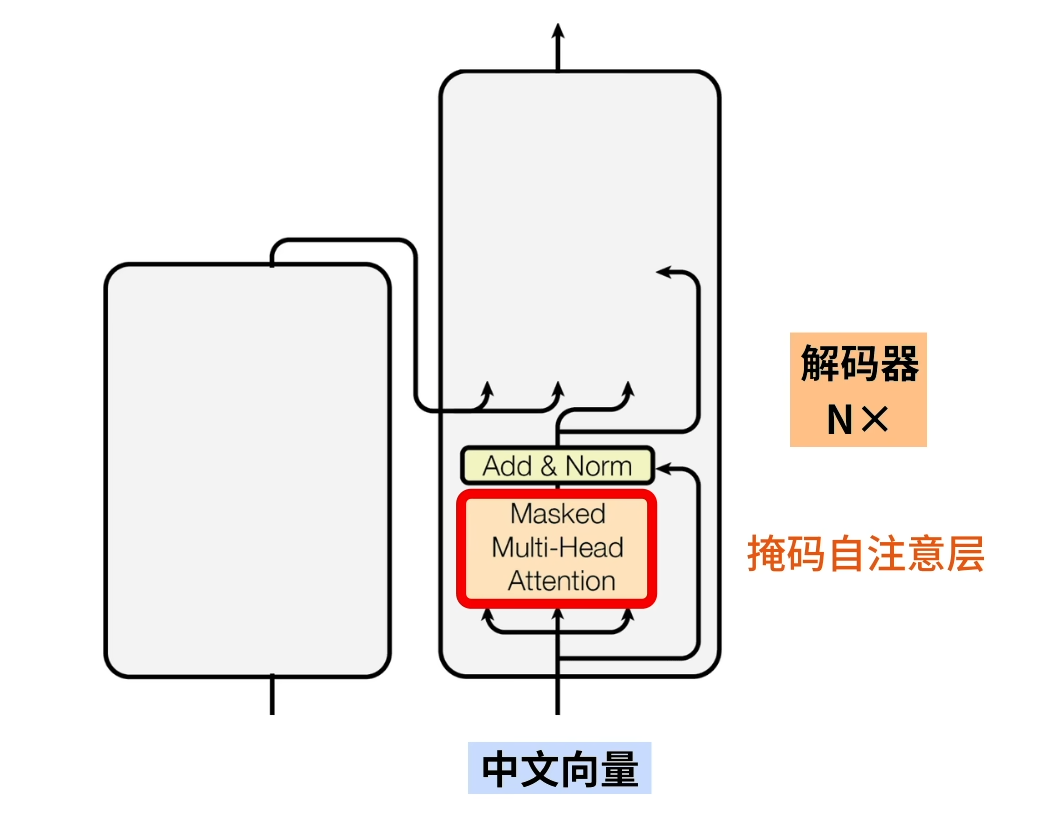
- Encoder-Decoder架构:Transformer模型通常包含一个编码器(Encoder)和一个解码器(Decoder)。编码器负责将输入序列编码为一个高维向量表示,解码器则利用这些向量信息生成输出序列。解码器中还包含了Masked Self-Attention,以防止未来信息泄露。
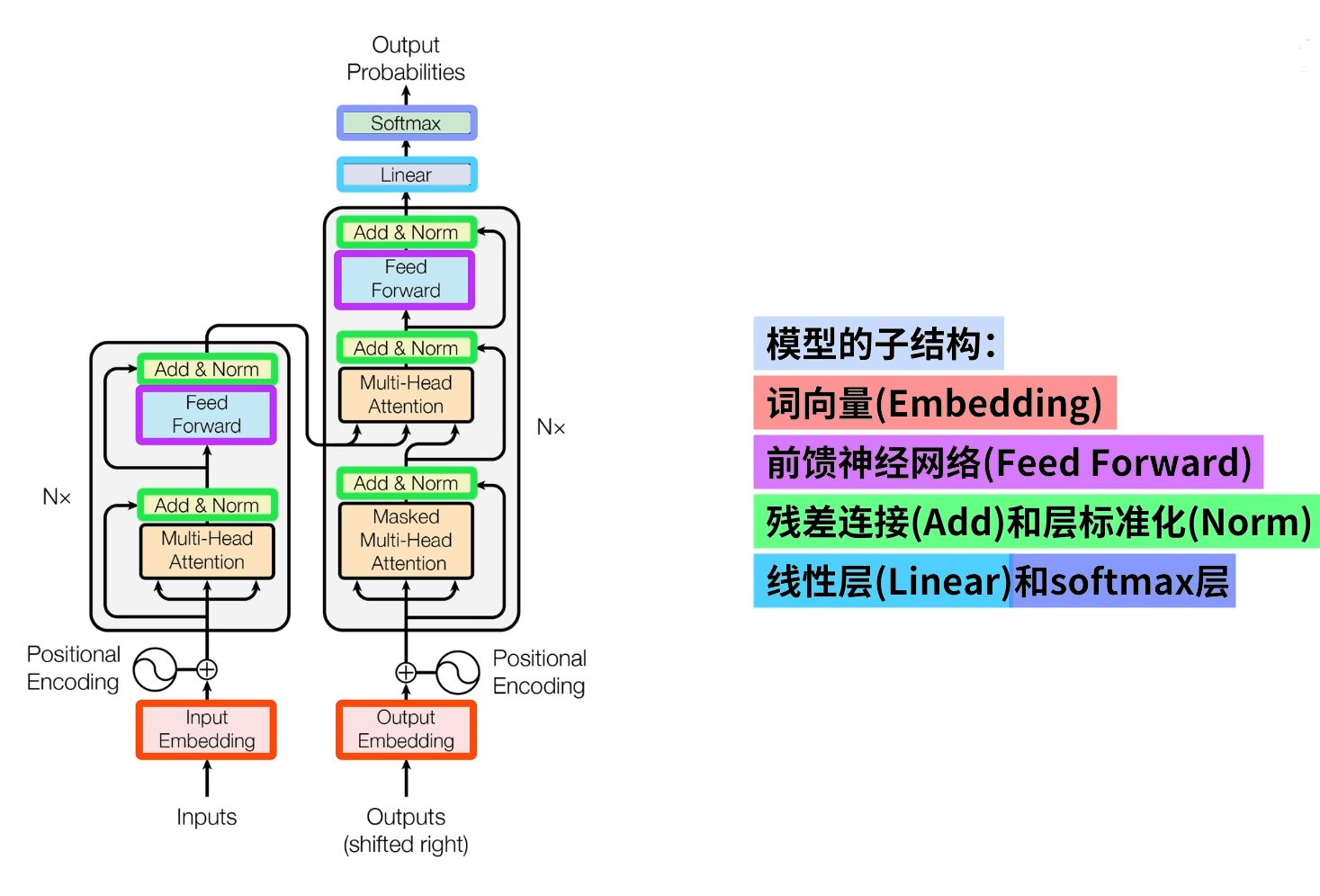
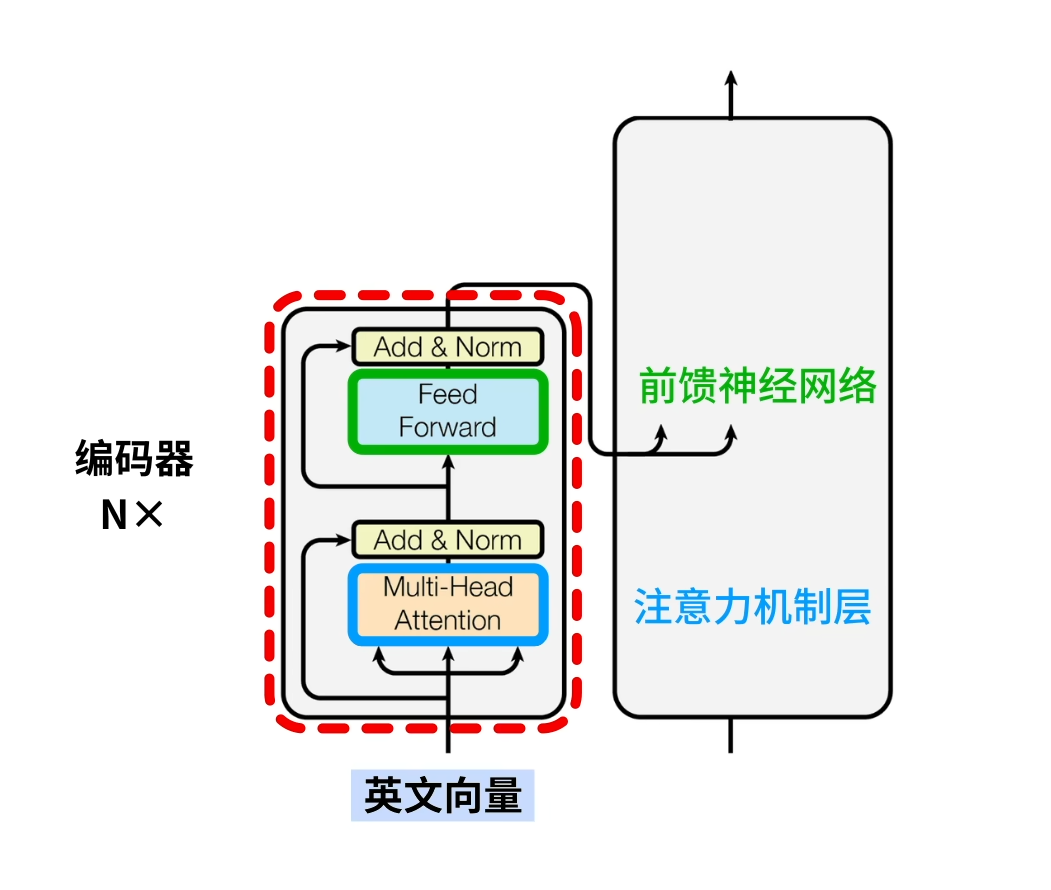
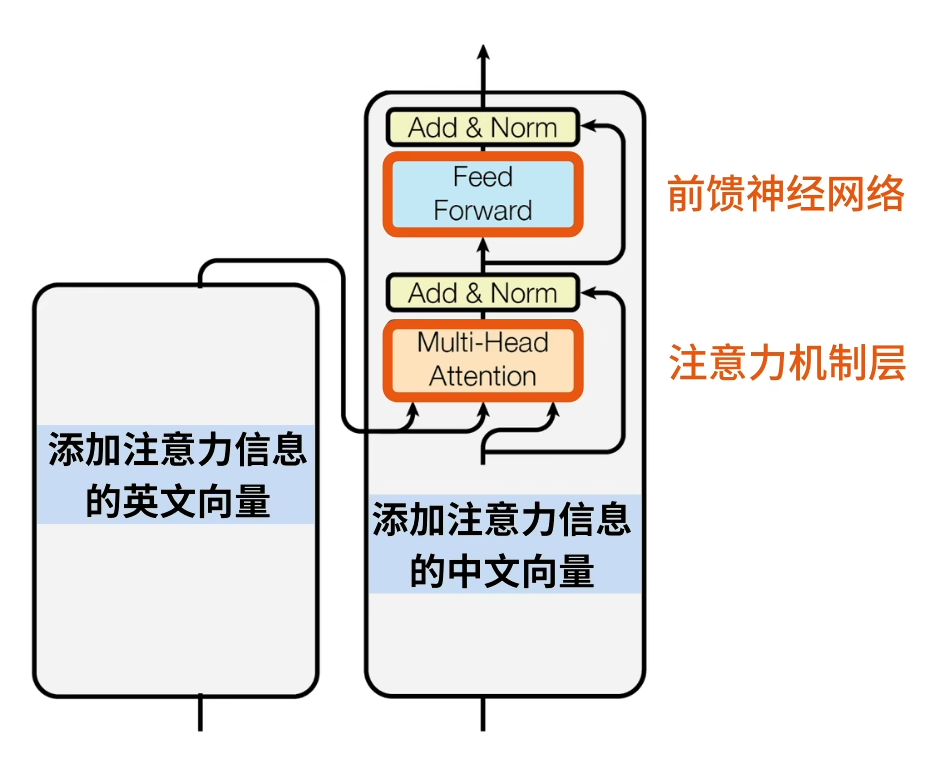
- 多层堆叠:Transformer的编码器和解码器都由多个相同的层堆叠而成,每层包含多头自注意力(Multi-Head Attention)子层和前馈神经网络(Feed Forward Networks, FFNs)子层,之间通过残差连接和Layer Normalization增强模型的表达能力和稳定性。
- 并行化和效率:由于Self-Attention的并行特性,Transformer模型在现代硬件上能非常高效地训练,相较于RNNs,它降低了训练时间并可以处理更大量的数据。
- 广泛的应用:Transformer模型的成功不仅限于机器翻译,它还是诸如BERT、GPT系列等许多先进预训练模型的基础。这些模型在语言理解、生成、问答、文本分类等众多NLP任务上刷新了记录,展示了Transformer架构的通用性和强大功能。
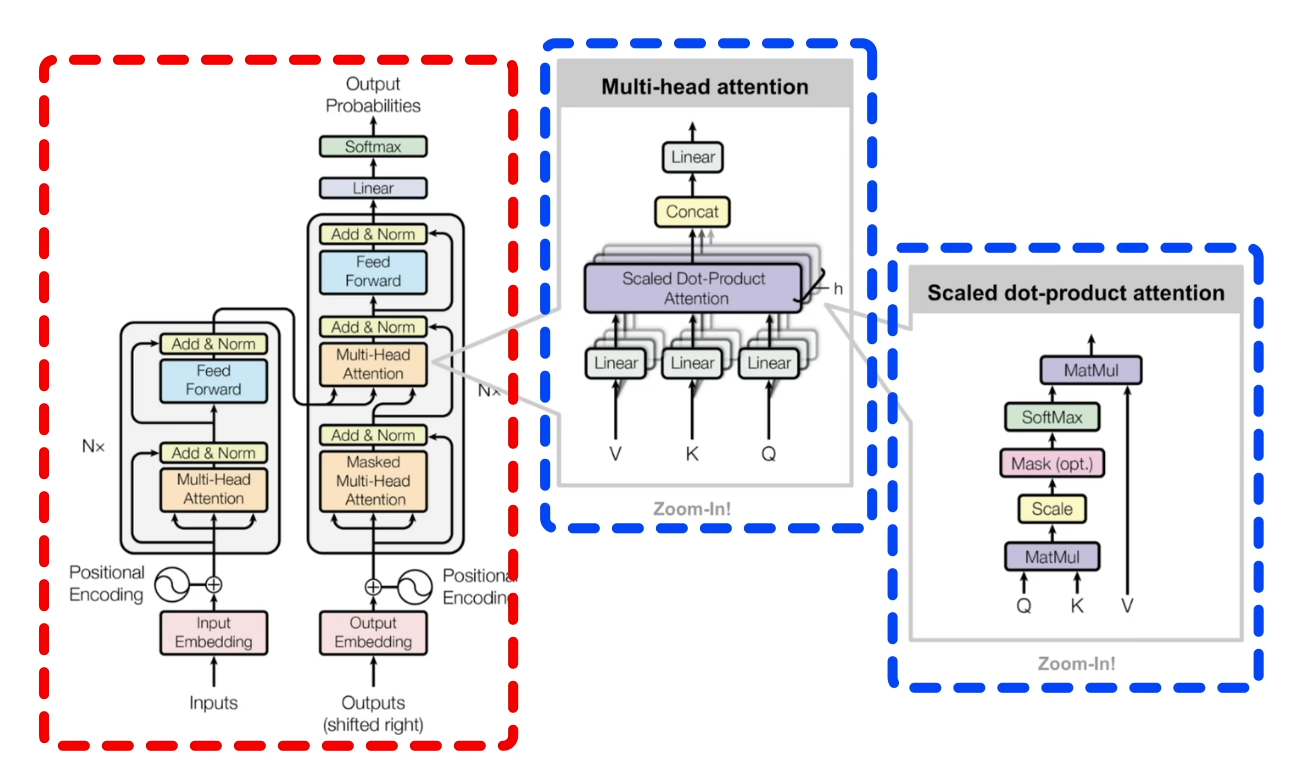
整体架构
Encoder与Decoder就是先归纳后推理
子结构
英文输入
中文输入
Transformer模型的出现不仅推动了NLP领域的发展,还影响了计算机视觉、语音识别等其他领域的研究,成为了深度学习领域的一个重要基石。
语音识别等其他领域的研究,成为了深度学习领域的一个重要基石。
了解更多知识请戳下: