目录
[1. 简介](#1. 简介)
[2. DPU 原理介绍](#2. DPU 原理介绍)
[2.1 基本原理](#2.1 基本原理)
[2.2 增强型用法](#2.2 增强型用法)
[3. DPU 开发流程](#3. DPU 开发流程)
[3.1 添加 DPU IP](#3.1 添加 DPU IP)
[3.2 在 BD 中调用](#3.2 在 BD 中调用)
[3.3 配置 DPU 参数](#3.3 配置 DPU 参数)
[3.4 DPU 与 Zynq MPSoC互联](#3.4 DPU 与 Zynq MPSoC互联)
[3.5 分配地址](#3.5 分配地址)
[3.6 生成 Bitstream](#3.6 生成 Bitstream)
[3.7 生成 BOOT.BIN](#3.7 生成 BOOT.BIN)
[4. 总结](#4. 总结)
1. 简介
在《Vitis AI 环境搭建 & KV260 PYNQ 安装 & 要点总结_pynq vitis ai-CSDN博客》一文中,我们记录 PYNQ for KV260 配置要点,而 DPU 是使用 KV260 视觉 AI 套件的重要内容,DPU(深度学习处理单元)是KV260视觉AI套件的核心组件,它允许在Xilinx硬件平台上进行AI推理。
DPUCZDX8G
DPUCZDX8G 是专为 Zynq UltraScale+ MPSoC 设计的深度学习处理器单元 (DPU)。它是一个针对卷积神经网络优化的可配置计算引擎。引擎中使用的并行度是一个设计参数,可以根据目标设备和应用进行选择。从高层次来看,DPU 是一种微编码计算引擎,具有高效、优化的指令集,并且可以支持大多数卷积神经网络的推理。
KV260使用的 DPU 型号是:DPUCZDX8G,它支持的主要运算符:
- Supports both Convolution and transposed convolution
- Depthwise convolution and depthwise transposed convolution
- Max pooling
- Average pooling
- ReLU, ReLU6, Leaky ReLU, Hard Sigmoid, and Hard Swish
- Elementwise-sum and Elementwise-multiply
- Dilation
- Reorg
- Correlation 1D and 2D
- Argmax and Max along channel dimension
- Fully connected layer
- Softmax
- Concat, Batch Normalization
2. DPU 原理介绍
2.1 基本原理
DPUCZDX8G 会在启动时从片外存储器中提取指令,用于控制计算引擎的操作。这些指令是由 Vitis AI 编译器生成的。
片上存储器用于缓冲器输入激活、中间特征映射和输出元数据,以达成高吞吐量和高效率的目标。这些数据会尽可能加以复用,以降低外部存储器带宽要求。对于计算引擎,会使用深度流水打拍式设计。处理元件 (PE) 会充分利用各种高精度构建块,例如,乘法器、加法器和累加器。

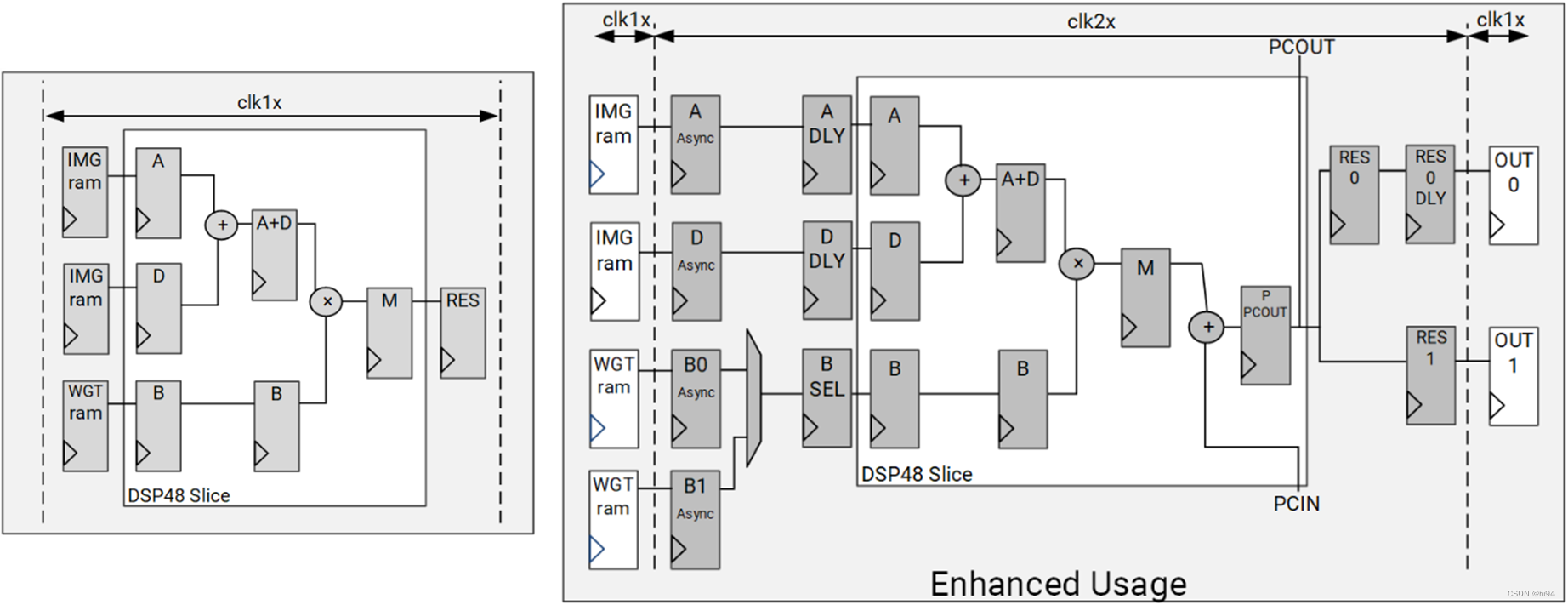
2.2 增强型用法
DSP 双倍数据速率 (DDR) 技巧可用于改善 DPU 可达成的性能。在此配置中,DPUCZDX8G 需采用 2 个输入时钟:1 个 1x 时钟用于通用逻辑,1 个 2x 时钟用于 DSP slice。
3. DPU 开发流程
本文介绍 DPUCZDX8G IP 在 Vivado 的开发流程。
3.1 添加 DPU IP
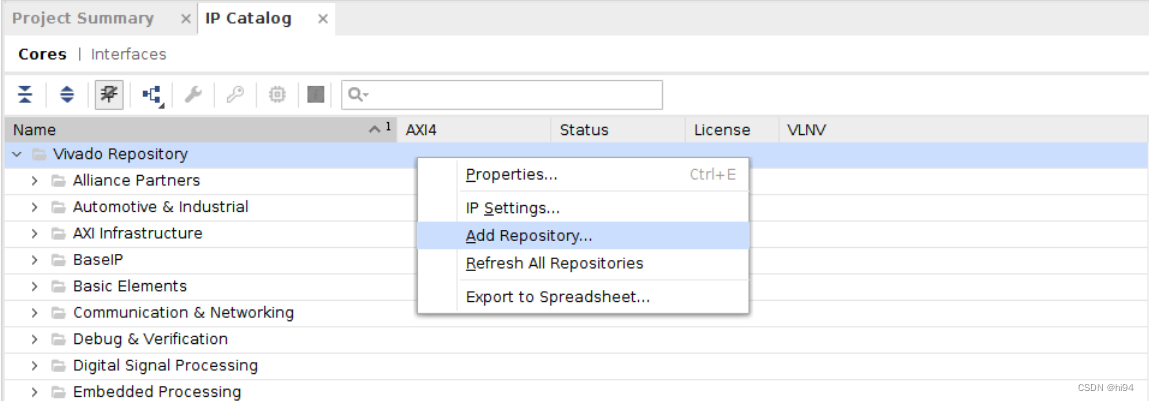
在 Vivado 中,进入 IP Catalog,右键单击并选择添加存储库,然后选择 DPUCZDX8G IP 的位置。
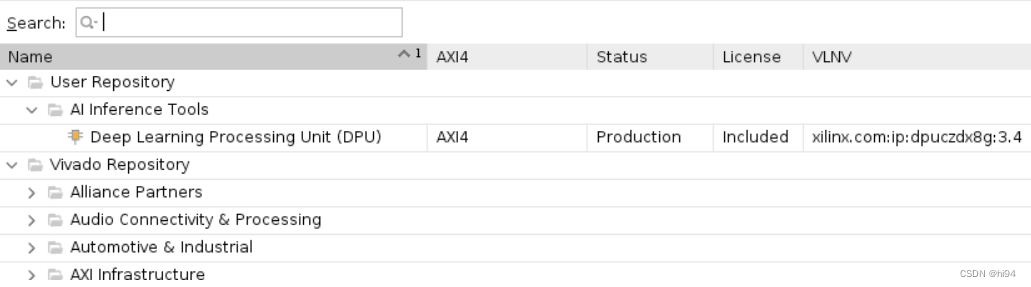
DPUCZDX8G IP 将出现在 IP 目录页面中:
3.2 在 BD 中调用
在Block Design 界面中搜索 DPUCZDX8G,并将 DPUCZDX8G IP 添加到块设计中。
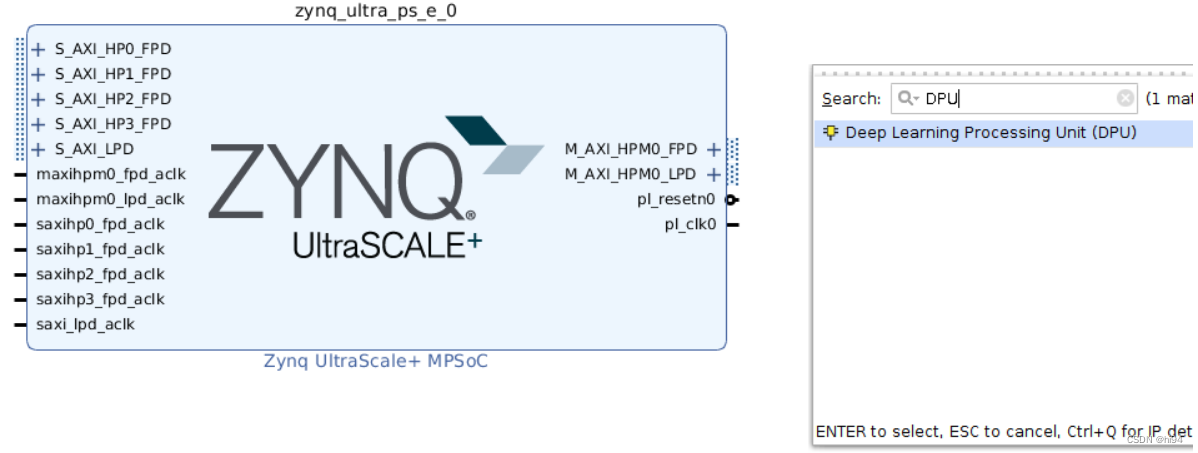
添加后如下:
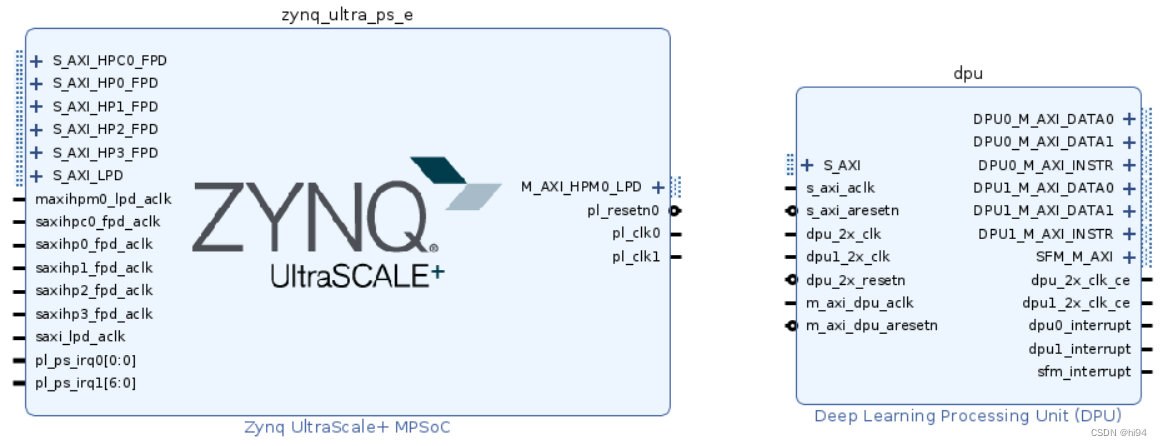
3.3 配置 DPU 参数
DPUCZDX8G 可配置为包含多个预定义的选项,包括 DPUCZDX8G 核的数量、卷积架构、DSP 级联、DSP 用量和 UltraRAM 用量。这些选项支持您设置 DSP slice(切片)、LUT、块 RAM 和 UltraRAM 用量。

3.4 DPU 与 Zynq MPSoC互联
DPUCZDX8G IP核心通过一个从属接口与外部通信。这些核心的数量由DPU_NUM参数决定,该参数可以在配置向导的"DPU核心数量"选项中设置。每个DPUCZDX8G核心配备了三个主要接口:一个用于指令提取,另外两个用于数据访问。
为了确保DPUCZDX8G可以有效地访问DDR存储,它可以通过AXI互连IP与处理器系统(PS)相连。但是,通过互连IP传输数据可能会增加延迟,这会影响DPUCZDX8G的性能。因此,如果PS有足够的AXI从端口,建议将DPUCZDX8G的每个主接口直接连接到PS,而不是通过AXI互连IP。
如果PS的AXI从端口数量不足,那么使用AXI互连进行连接是不可避免的。在这种情况下,两个用于数据访问的AXI主接口应该是高带宽的,而用于指令提取的AXI主接口则应该是低带宽的。通常情况下,所有用于指令提取的主接口都应该通过一个互连连接到PS的S_AXI_LPD端口。而用于数据访问的主接口则应尽可能直接连接到PS。对于DPUCZDX8G核心,建议将优先级较高的核心(例如DPU0)的主接口直接连接到PS中优先级较高的从端口(例如S_AXI_HP0_FPD)。
3.5 分配地址
DPUCZDX8G 所需的最小空间是 16 MB。DPUCZDX8G 从接口可分配至可供主机 CPU 访问的任意起始地址。
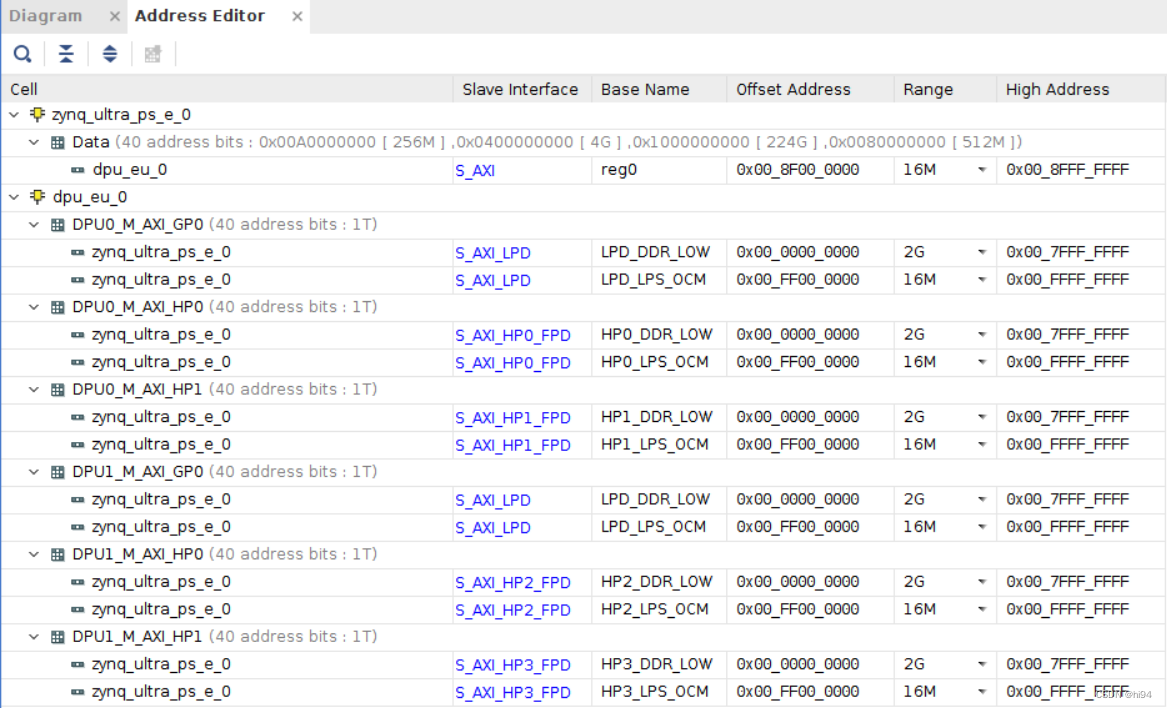
3.6 生成 Bitstream
在 Vivado 中的Generate Bitstream(生成比特流):

3.7 生成 BOOT.BIN
通过 Vivado 或 PetaLinux,可方便生成BOOT.BIN。
4. 总结
本文详细介绍了使用KV260视觉AI套件中的DPUCZDX8G深度学习处理单元(DPU)的环境搭建和开发流程。DPUCZDX8G是专为Zynq UltraScale+ MPSoC设计的,优化了卷积神经网络的计算引擎,支持广泛的运算符,使其成为执行AI推理任务的强大工具。文章从DPU的基本原理出发,解释了其工作机制,包括如何从片外存储器中提取指令以及如何在片上存储器中高效处理数据。
接着,描述了如何在Vivado中添加和配置DPUCZDX8G IP,包括调整DPU参数以满足特定应用需求,并详细说明了DPU与Zynq MPSoC互联的方法。此外,还提到了生成比特流和BOOT.BIN的过程。
