文章目录
版本选择
在ElasticSearch分析京东商城商品搜索实现|聚合|全文查找|搜索引擎|ES Java High Level Rest Client|ES Java API Client这篇文章里进行了说明,使用的7.17.3版本,不再赘述。
- Elasticsearch 7.17.3下载地址
- Kibana 7.17.3下载地址
- 环境CentOS 7.6.1
单机ES安装与配置
创建非root用户
ES不允许root用户运行,使用root 用户为其创建一个用户es ,为用户es 配置密码,并切换到es用户。
shell
adduser es
passwd es
su es导入安装包
将下载好的Elasticsearch,Kibana 导入到es 用户home目录
powershell
[es@polaris ~]$ cd ~
[es@polaris ~]$ pwd
/home/es
[es@polaris ~]$ ls
kibana-7.17.3-linux-x86_64.tar.gz
elasticsearch-7.17.3-linux-x86_64.tar.gz 安装包解压
shell
tar -zxvf elasticsearch-7.17.3-linux-x86_64.tar.gz
tar -zxvf kibana-7.17.3-linux-x86_64.tar.gz配置JDK环境变量
当前还在用户home目录下,
添加两行(ES7.x及以后版本内置了jdk)
shell
export ES_JAVA_HOME=/home/es/elasticsearch-7.17.3/jdk
export ES_HOME=/home/es/elasticsearch-7.17.3
shell
[es@polaris ~]$ vim .bash_profile
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
export ES_JAVA_HOME=/home/es/elasticsearch-7.17.3/jdk
export ES_HOME=/home/es/elasticsearch-7.17.3
PATH=$PATH:$HOME/.local/bin:$HOME/bin
export PATH执行以下命令,使之生效。(之后使用es 用户开启一个终端会话(参考:ES环境变量设置的问题,分析用户级环境变量设置与读取,报错分析与解决⚠️ usage of JAVA_HOME is deprecated, use ES_JAVA_HOME),该环境变量配置就会是生效的)
shell
source .bash_profile配置single-node
切换到es目录
shell
cd elasticsearch-7.17.3/
shell
# 0. 备份一下原配置文件
cp config/elasticsearch.yml config/elasticsearch.yml.origin
# 修改配置
vim config/elasticsearch.yml
# 1. 开启远程访问,监听所有网卡,可以在虚拟机外部如win主机上访问
network.host: 0.0.0.0
# 2. 单节点模式
discovery.type: single-node配置JVM参数
官方建议:将 Xms 和 Xmx 设置为不超过总内存的 50%。 Elasticsearch 需要内存用于 JVM堆以外的用途。例如,Elasticsearch 使用堆外缓冲区来实现高效的网络通信,并依赖操作系统的文件系统缓存来高效地访问文件。 JVM本身也需要一些内存。Elasticsearch 使用的内存多于 Xmx 设置配置的限制是正常的。
机器情况:CPU 4核8线程,内存16GB,打算搭三节点集群演示,主机上还会运行一些东西,因此为每个虚拟机分配了2GB的内存,处理器数量2个,单个处理器内核数量设置为了2个,处理器内核总数为4
虚拟机内存2GB,堆内存设置不超过50%,这里设置1GB
shell
# 0. 备份一下原配置文件
cp config/jvm.options config/jvm.options.origin
# 修改堆内存
vim config/jvm.option
-Xms1g
-Xmx1g后台启动|启动日志查看
后台启动可以保证启动成功后,当前会话断开,es还是在运行,不会随着终端会话关闭而终止。
shell
bin/elasticsearch -d如果启动有问题可以查看es启动日志
shell
tail -f logs/elasticsearch.log启动成功,访问
终端访问
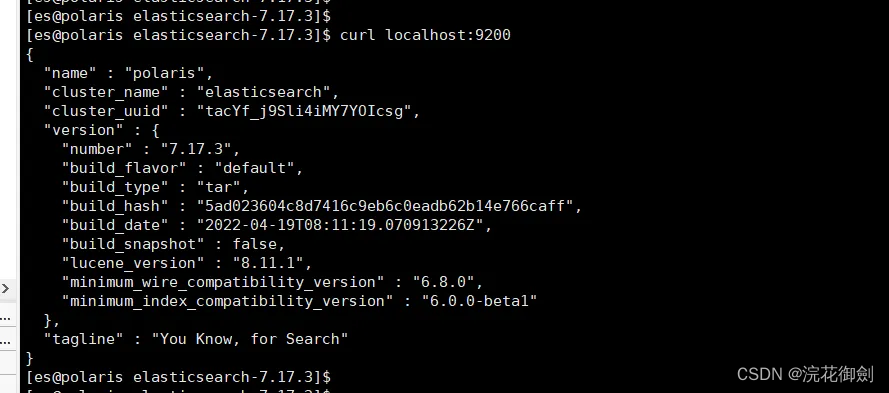
浏览器访问
如果浏览器访问不通,那么可以关闭防火墙简化操作,
云服务器的话可以通过配置安全组规则,进行端口映射,开放端口(参考:添加安全组规则)
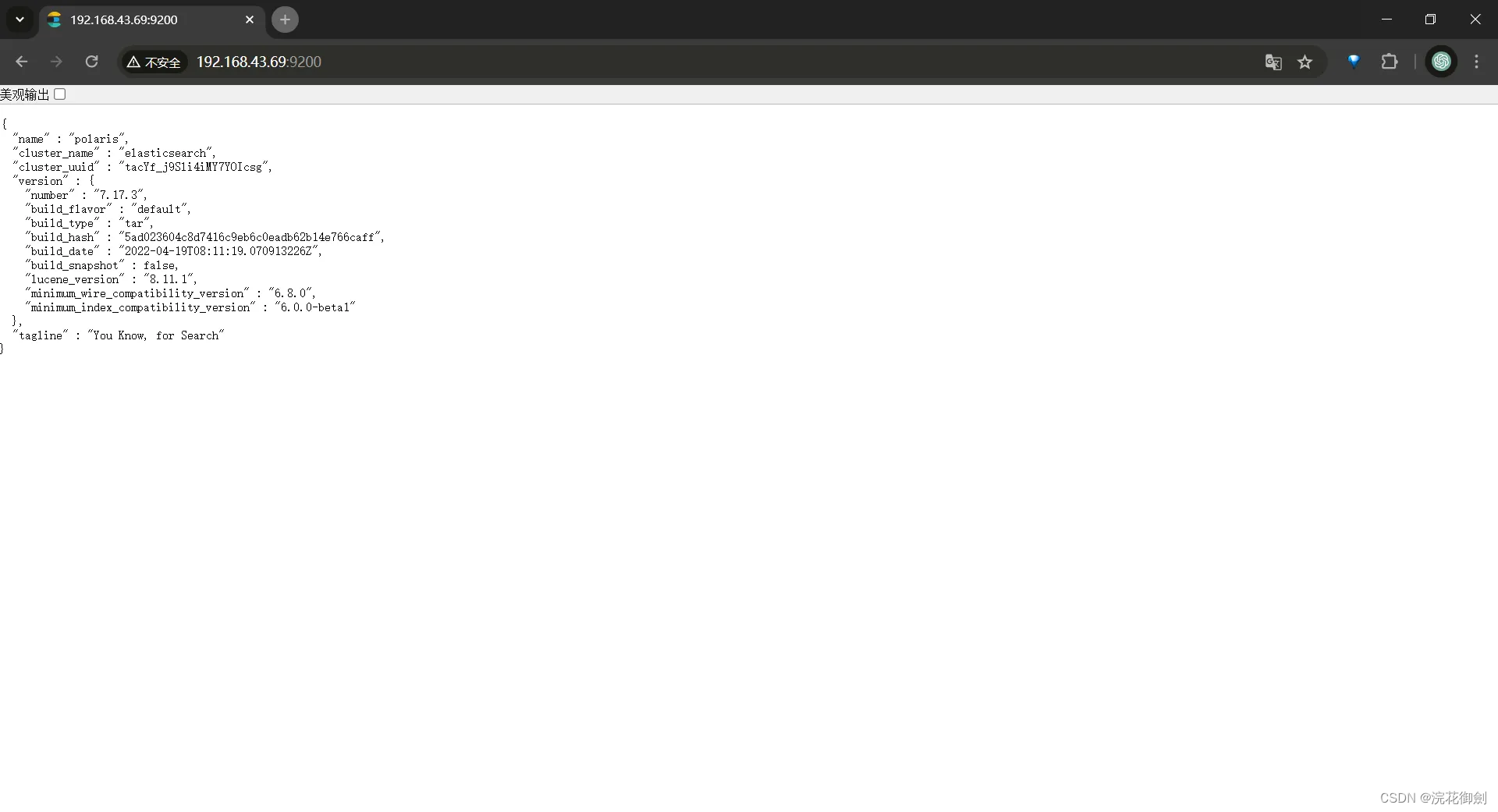
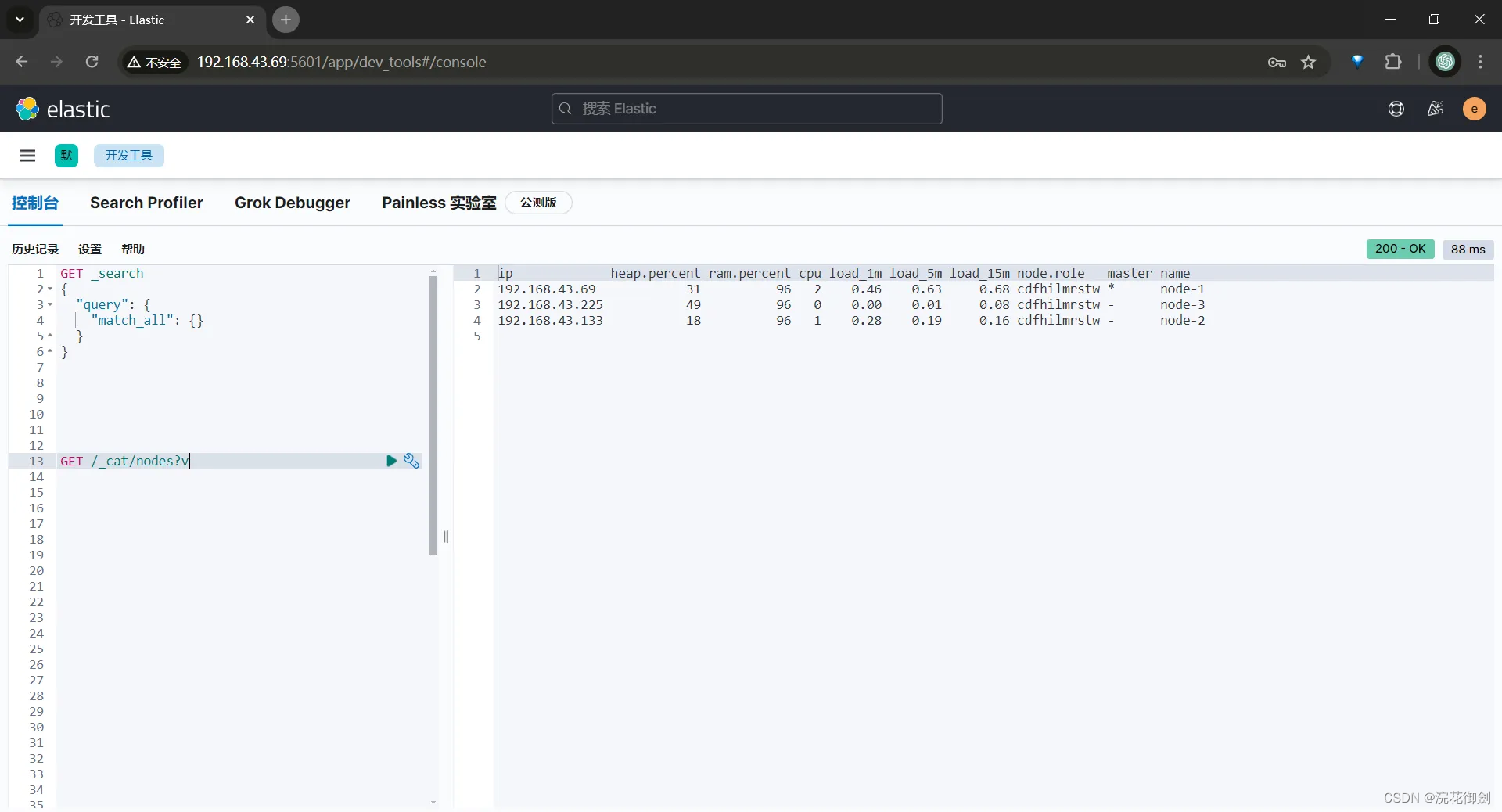
这样单节点的es就可以正常工作,之后通过修改配置把他加入到集群。
Kibana安装
Kibana 是官方提供的ES一个客户端连接工具。
只在一台虚拟机上安装即可(或者win主机上安装一个都行),注意修改配置,使之能够访问到es(单机或集群),以及可以对外提供服务(Kibana 对外能够被访问)。
这里是在虚拟机上安装。
修改配置
shell
cd ~/kibana-7.17.3-linux-x86_64/
#备份一个源文件
cp config/kibana.yml config/kibana.yml.origin
#修改配置
vim config/kibana.yml
#指定Kibana服务器监听的端口号
server.port: 5601
#开启远程访问,监听所有网卡,可以在虚拟机外部如win主机上访问
server.host: "0.0.0.0"
#指定Kibana连接到的ES实例的访问地址,
#如果访问本地的ES(Kibana与ES安装在同一台服务器上)就是localhost,访问其他的换成ip
#集群的话就配上所有的节点elasticsearch.hosts: ["http://192.168.43.69:9200", "http://192.168.43.133:9200", "http://192.168.43.225:9200"]
elasticsearch.hosts: ["http://localhost:9200"]
#将 Kibana 的界面语言设置为简体中文。默认en
i18n.locale: "zh-CN" 后台启动|启动日志查看
后台启动可以保证启动成功后,当前会话断开,kibana还是在运行,不会随着终端会话关闭而终止。
shell
nohup bin/kibana &如果启动有问题可以查看Kibana启动日志
shell
tail -f nohup.out浏览器访问
win主机浏览器访问机器ip+":"+port(5601),
shell
http://192.168.43.69:5601/到此,Elasticsearch 环境及客户端Kibana就安装配置完成。
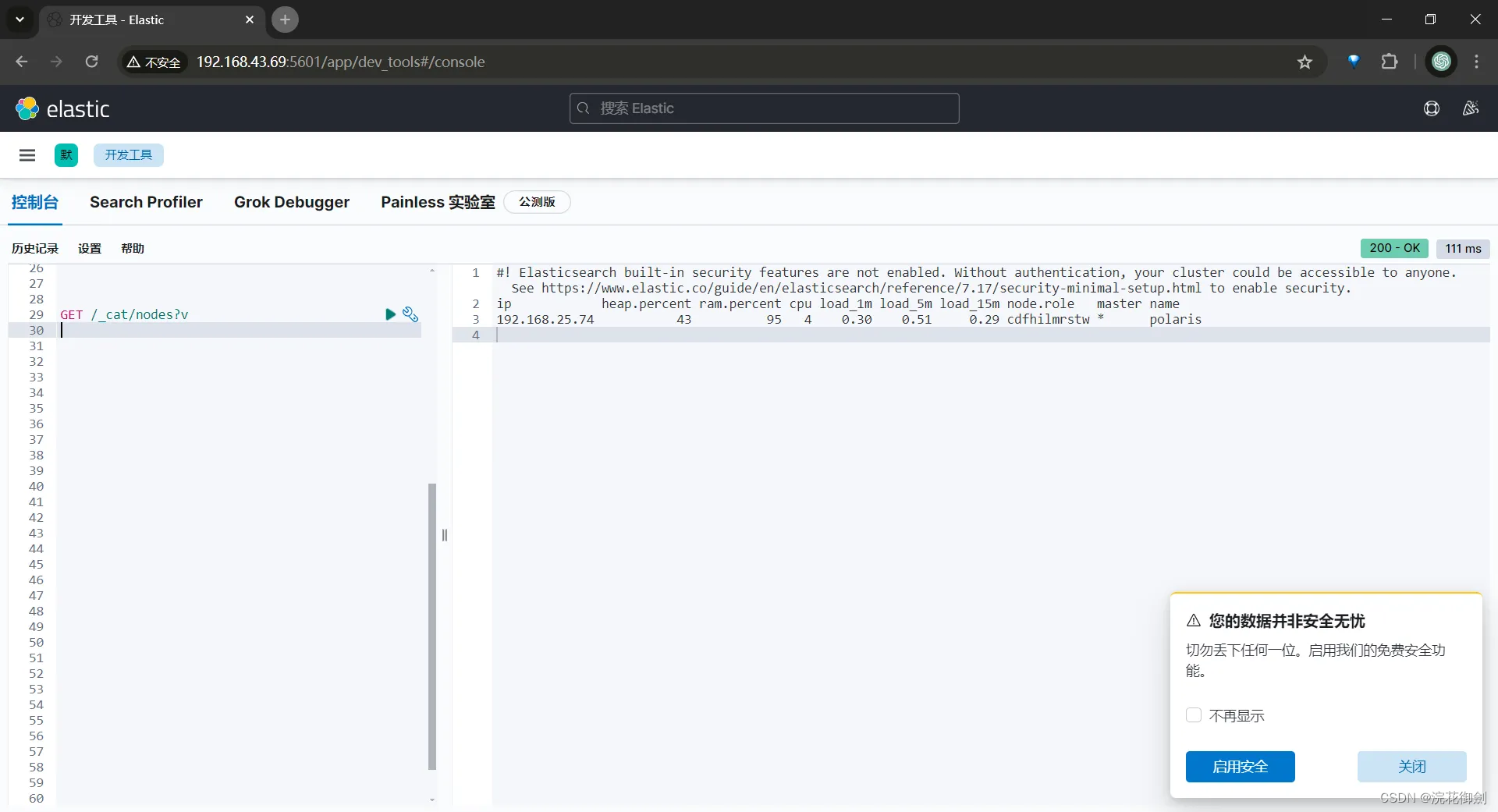
这里查看到的节点ip是192.168.25.74 而不是我们访问的机器ip 192.168.43.69 ,是有问题的(正常情况是不会有这个问题的)。这个问题的原因参考:ES ElasticSearch节点加入集群失败经历分析主节点选举、ES网络配置 publish_address不是当前机器ip
下面说明ES集群搭建方法。
ES三节点集群搭建
可以把刚才的虚拟机克隆出额外的两个,也可以在额外的两个虚拟机上重复上面es的安装过程(Kibana不需要再装了,它只是个es连接工具,装一个就行了)
停止es服务
shell
#查看es进程
ps -ef|grep elasticsearch
#停止es运行
kill pid #pid是上面命令查出来的进程号域名配置
三台机器都切换root用户,配置机器ip与域名对应关系,用于在服务发现时,集群内的各节点通过这个域名彼此可以找到彼此。
shell
su
vim /etc/hosts
192.168.43.69 es-node1
192.168.43.133 es-node2
192.168.43.225 es-node3之后再切换回es用户
shell
su es配置修改
注释掉单节点
shell
#注释掉单节点
#discovery.type: single-node集群配置
注意:数据目录日志目录单独指定,要和之前单机启动区别开
配置说明
- cluster.name:集群名称,指定一个(避免因未指定,启动一个es就会加入到集群中),配置好其他属性,然后集群同名才可加入到这个集群中。
- node.name:节点名字,集群内唯一
- node.master:是否有资格为master节点,默认为true,表示这个节点有资格成为主节点(master node)。主节点主要负责集群级别的操作,如创建或删除索引、跟踪集群中哪些节点是活动的等。
- node.data:是否为data数据节点,默认为true,表示这个节点也是一个数据节点(data node),它会存储索引数据并处理搜索请求。
- http.cors.enabled: true:允许跨源资源共享(CORS)。当你想从另一个域的网页或应用访问这个Elasticsearch节点时,CORS允许这样的请求
- http.cors.allow-origin: "*" : 允许来自任何域的CORS请求。但出于安全考虑,通常不建议在生产环境中使用*,而是指定特定的域名。
- path.data:定义了Elasticsearch用于存储索引数据的路径。
- path.logs:定义了Elasticsearch存储其日志文件的路径。
- network.host: 0.0.0.0:告诉Elasticsearch监听所有可用的网络接口。但在生产环境中,为了安全起见,通常会指定特定的IP地址或范围。
- discovery.seed_hosts:定义了Elasticsearch在启动时用于发现其他集群成员的初始主机列表。可以通过es-node1、es-node2和es-node3这些主机域名或IP地址来访问其他节点。(上面配置了域名与机器ip的映射关系,因此可以使用机器域名)
- cluster.initial_master_nodes:在Elasticsearch第一次启动时,需要指定哪些节点应该成为主节点(指定node.name指定的节点名字列表)。
配置节点1
shell
vim config/elasticsearch.yml
# node-1
cluster.name: es-cluster
node.name: node-1
node.master: true
node.data: true
http.cors.enabled: true
http.cors.allow-origin: "*"
path.data: /home/es/elasticsearch-7.17.3/data-cluster
path.logs: /home/es/elasticsearch-7.17.3/logs-cluster
network.host: 0.0.0.0
discovery.seed_hosts: ["es-node1","es-node2","es-node3"]
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]配置节点2
shell
vim config/elasticsearch.yml
# node-2
cluster.name: es-cluster
node.name: node-2
node.master: true
node.data: true
http.cors.enabled: true
http.cors.allow-origin: "*"
path.data: /home/es/elasticsearch-7.17.3/data-cluster
path.logs: /home/es/elasticsearch-7.17.3/logs-cluster
network.host: 0.0.0.0
discovery.seed_hosts: ["es-node1","es-node2","es-node3"]
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]配置节点3
shell
vim config/elasticsearch.yml
# node-3
cluster.name: es-cluster
node.name: node-3
node.master: true
node.data: true
http.cors.enabled: true
http.cors.allow-origin: "*"
path.data: /home/es/elasticsearch-7.17.3/data-cluster
path.logs: /home/es/elasticsearch-7.17.3/logs-cluster
network.host: 0.0.0.0
discovery.seed_hosts: ["es-node1","es-node2","es-node3"]
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]分别启动
shell
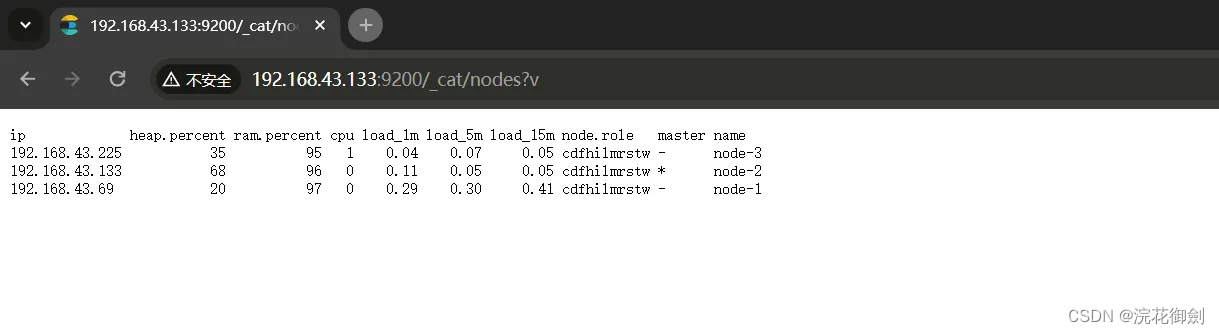
bin/elasticsearch -d验证集群搭建成功
Kibana配置修改
集群搭建成功,更改kibana的配置中的ES instances地址
shell
elasticsearch.hosts: ["http://192.168.43.6:9200", "http://192.168.43.133:9200", "http://192.168.43.225:9200"]重启Kibana
查看进程
shell
netstat -tunlp|grep 5601
shell
[es@polaris kibana-7.17.3-linux-x86_64]$ netstat -tunlp|grep 5601
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 7379/bin/../node/bi 停止Kibana服务
shell
kill 7379启动Kibana
shell
nohup bin/kibana &验证