1 项目介绍
1.1 摘要
随着工业化和城市化的迅猛推进,工作场所的安全管理愈发受到重视。安全帽作为保护工人头部安全的关键装备,其实时监测和检测的重要性不言而喻。本文提出并深入研究了基于YOLOv7算法的安全帽佩戴检测技术,该技术旨在实现工作场所中工人安全帽佩戴情况的自动、精确且高效的检测。
本研究充分利用了YOLOv7目标检测算法的卓越性能,结合Python编程语言、OpenCV计算机视觉库以及PyTorch深度学习框架,构建了一套高效且精准的安全帽佩戴检测系统。YOLOv7算法因其出色的检测速度和准确性,在目标检测领域得到了广泛应用,尤其适合对实时性和准确性有严格要求的场景。
在研究中,首先利用大量经过精细标注的安全帽佩戴图像数据对YOLOv7模型进行了训练,以确保其能够精确识别图像中的安全帽并准确判断佩戴情况。随后,借助OpenCV库,实现了图像的实时采集和预处理,并将处理后的图像输入到已训练好的YOLOv7模型中进行安全帽佩戴检测。最后,利用PyTorch框架的灵活性和高效性,对检测结果进行了精细化的后处理和直观的可视化展示。
实验结果显示,基于YOLOv7的安全帽佩戴检测系统能够在工作场所中实现对工人安全帽佩戴情况的快速且准确的检测。与传统的人工检测方式相比,本系统不仅检测效率和准确性显著提升,而且能够自动记录和报告检测结果,为工作场所的安全管理提供了强有力的技术支撑。
本文的研究成果不仅为安全帽佩戴检测领域带来了新的技术突破,也为其他类似场景下的目标检测问题提供了有价值的参考和启示。展望未来,将继续深入探索和优化算法模型,提升系统的鲁棒性和泛化能力,以更好地应对更加复杂多变的应用场景。
1.2 系统技术栈
Python
YOLOV7
OpenCV
PyQt5
1.3 系统角色
管理员
用户
1.4 算法描述
YOLOv7,作为YOLO系列算法的最新版本,继承了该系列一贯的实时目标检测核心思想,并通过一系列创新和改进,进一步提升了检测速度和准确性。其工作原理主要围绕三个核心部分展开:Backbone(主干网)、Neck(颈部)和Head(头部)。
首先,YOLOv7接收输入图像,并通过预处理操作将其调整为模型所需的大小和格式。随后,图像进入Backbone部分,这一部分由多个卷积层、池化层等构成,用于逐步提取图像中的深层特征。这些特征不仅包含了图像的纹理、形状等基本信息,还蕴含了目标物体的关键信息。
接下来,提取到的特征经过Neck模块进行融合处理。Neck模块是YOLOv7的一个重要创新点,它采用了多种特征融合技术,如FPN(Feature Pyramid Networks)和PANet(Path Aggregation Network)等,将不同尺度的特征图进行融合,从而增强模型对不同大小目标的检测能力。这一步骤对于提高模型的泛化能力和鲁棒性至关重要。
最后,融合后的特征被送入Head部分进行目标检测。Head部分通过一系列卷积层和全连接层,对特征图进行解析和预测,输出每个目标的位置坐标(边界框)、类别概率和置信度等信息。为了进一步提高检测结果的准确性,YOLOv7还采用了非极大值抑制(NMS)等后处理技术,对检测到的目标进行筛选和去重。
在优化与改进方面,YOLOv7引入了新的网络结构和激活函数,这些创新不仅提高了模型的表达能力和收敛速度,还使得模型在保持实时性的同时,实现了更高的检测精度。此外,YOLOv7还采用了更高效的训练策略和数据增强技术,进一步提升了模型的泛化能力和鲁棒性。这些改进使得YOLOv7在实时目标检测领域取得了显著的优势,并广泛应用于各种实际场景中。
1.5 系统功能框架图
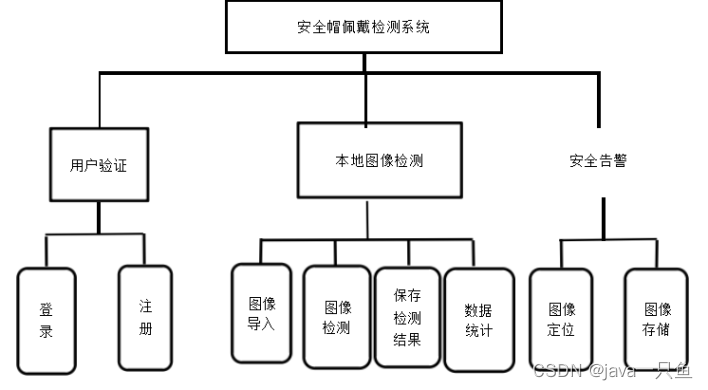
1.6 设计思路
在算法选择上,选用了YOLOv7作为目标检测的基础框架。YOLOv7以其高效的检测速度和较高的准确度,在实时性要求较高的场景中表现出色,因此非常适用于安全帽检测这一应用场景。
接下来,利用准备好的数据集对YOLOv7模型进行训练。通过调整学习率、批处理大小等超参数,不断优化模型的性能,以使其能够更好地适应的检测任务。同时,为了增加模型的泛化能力,在训练过程中采用了数据增强技术,如随机裁剪、旋转、翻转等,以模拟更多样化的实际场景。
在图像预处理阶段,利用OpenCV库对输入的图像进行了一系列操作,包括灰度化、滤波去噪和图像缩放等。这些预处理步骤能够去除图像中的冗余信息,提高模型的检测准确性。
完成预处理后,将图像输入到训练好的YOLOv7模型中进行安全帽检测。模型会输出一系列边界框和对应的类别置信度,根据这些输出信息判断图像中是否存在安全帽。
为了进一步提高检测结果的准确性,对模型的输出进行了后处理。采用了非极大值抑制(NMS)等算法,去除了冗余的边界框,保留了最准确的检测结果。
最后,将检测结果整合到系统中,并通过PyQt5等GUI框架设计了用户友好的界面。这个界面不仅展示了视频流和实时检测结果,还包含了控制面板和状态指示器等元素,使用户能够方便地与系统交互,如启动或停止检测过程、查看历史记录和统计数据等。
2 系统功能实现截图
2.1 功能模块实现
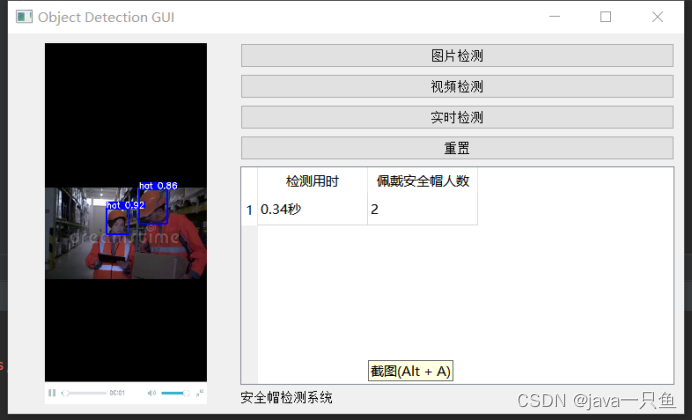
2.1.1 图片检测
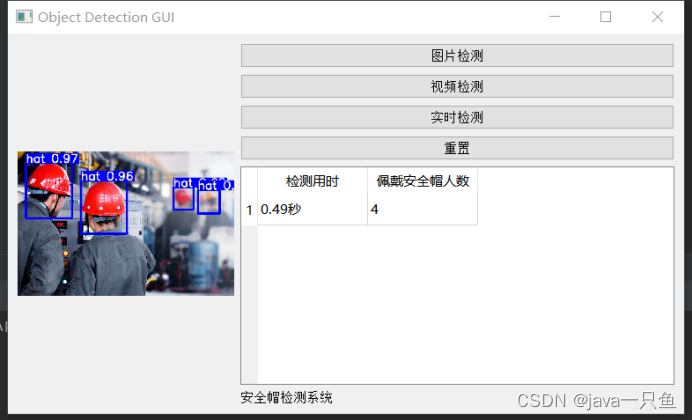
2.1.2 视频检测
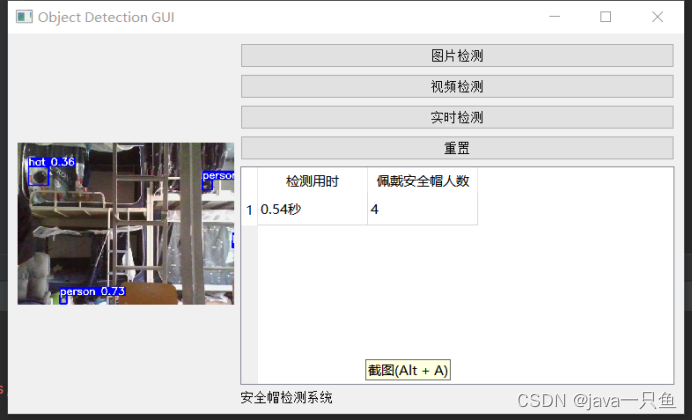
2.1.3 实时检测