跟着小土堆继续学,在上篇的学习中已经掌握了对Pytorch的基本使用 ,这篇构建模型练手
前置知识
container中Sequential的使用:
作用:将按各个模块按顺序搭建起来
CIFAR10网络模型结构
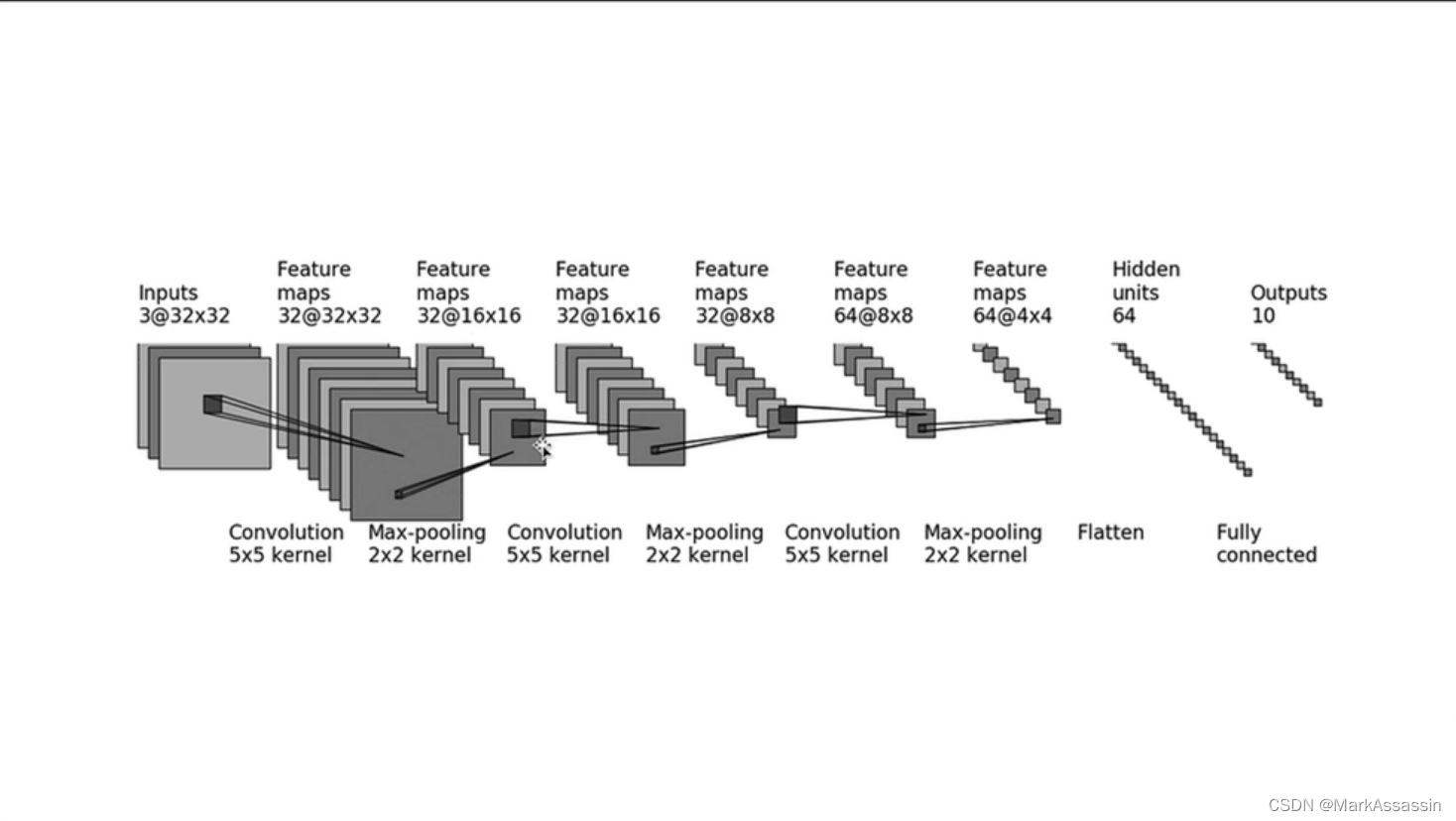
卷积输入输出计算公式
通过卷积的输出公式计算就可以根据输入和输出的图像形状反推出padding等值

模型
模型搭建
python
class CIFAR10_Net(nn.Module):
def __init__(self):
super(CIFAR10_Net, self).__init__()
self.model = nn.Sequential( #Sequential将按各个模块按顺序搭建起来
#卷积输入输出计算:32 = (32 + 2 * padding - 1 * (5-1) - 1) + 1得到padding为2【Hin = 32,stride = 1,dilation = 1,kernel_size = 5,Hout = 32】
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), #第一步是5*5的卷积【将(3*32*32)的图片转为(32*32*32)的数据】
nn.MaxPool2d(kernel_size=2, stride=2), #第二步是2*2最大池化【将(32*32*32)的数据转为(32*16*16)的数据】
#卷积输入输出计算:16 = (16 + 2 * padding - 1 * (5-1) - 1) + 1得到padding为2【Hin = 16,stride = 1,dilation = 1,kernel_size = 5,Hout = 16】
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2), #第三步还是5*5的卷积【将(32*16*16)的数据转为(32*16*16)的数据】
nn.MaxPool2d(kernel_size=2, stride=2), #第四步还是2*2最大池化【将(32*16*16)的数据转为(32*8*8)的数据】
# 卷积输入输出计算:8 = (8 + 2 * padding - 1 * (5-1) - 1) + 1得到padding为2【Hin = 8,stride = 1,dilation = 1,kernel_size = 5,Hout = 8】
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2), #第五步还是5*5的卷积【将(32*8*8)的数据转为(64*8*8)的数据】
nn.MaxPool2d(kernel_size=2, stride=2), #第六步还是2*2最大池化【将(64*8*8)的数据转为(64*4*4)的数据】
nn.Flatten(), #第七步展平数据【将(64*4*4)的数据转为64*4*4的数据】
#全连接层
#上面经过model已经得到数据,接下来要将数据转为输出结构
nn.Linear(64*4*4,64), #第八步线性连接进入隐藏层【将64*4*4的数据输入计算出64个隐藏层结果】
nn.Linear(64,10) #第九步线性连接得出预测【将64的数据输入计算出10个预测结果的分数】
)
def forward(self, x):
x = self.model(x)
x = self.fc1(x)
x = self.fc2(x)
return x测试验证模型
python
#模型实例化
cifar10_net = CIFAR10_Net()
print(cifar10_net)
#测试数据【ones代表全为1,random即随机】
input = torch.ones(64, 3, 32, 32)
output = cifar10_net(input)
print(output.shape)
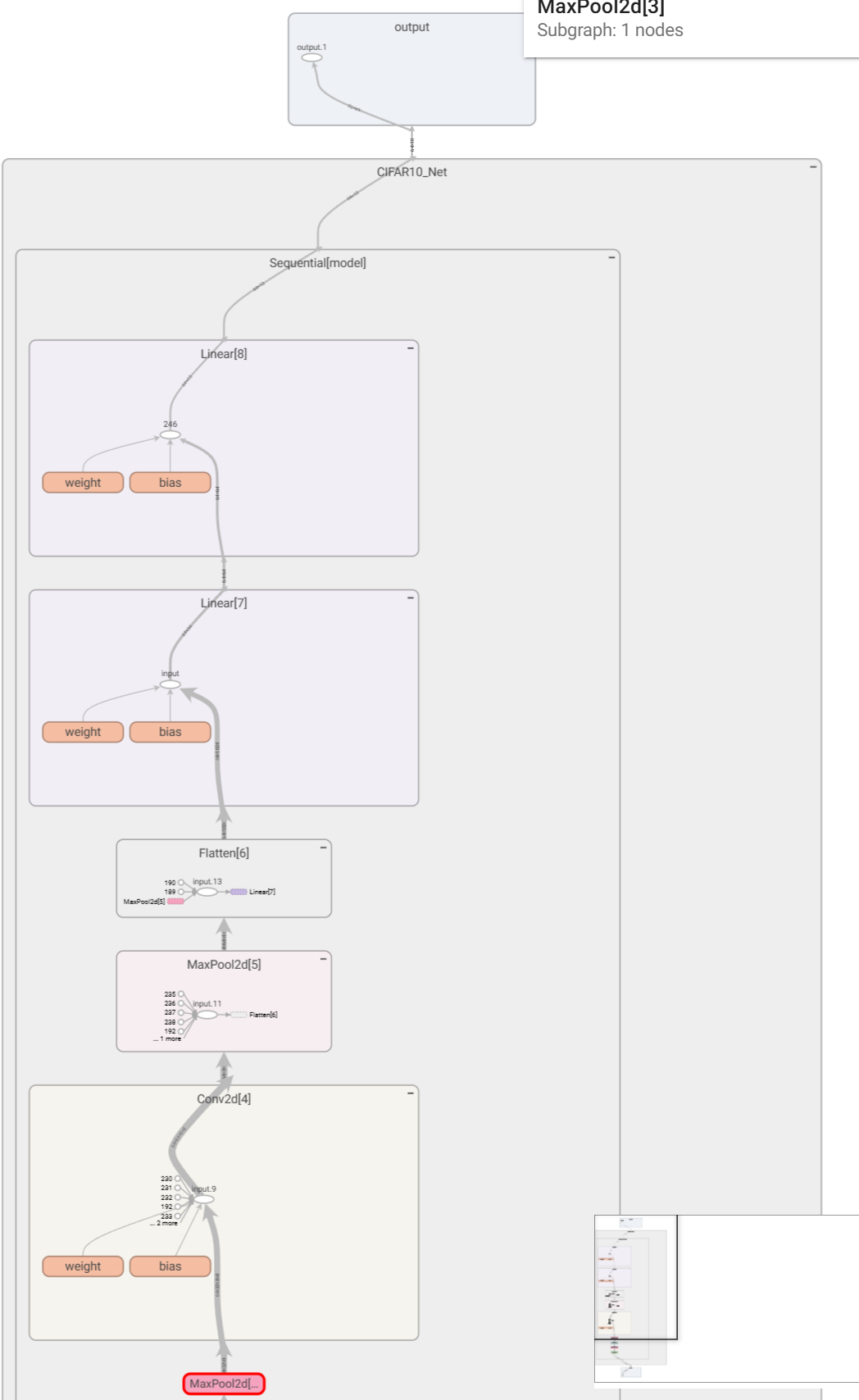
Tensorboard展示
python
writer = SummaryWriter("./logs_model")
writer.add_graph(cifar10_net, input)
writer.close()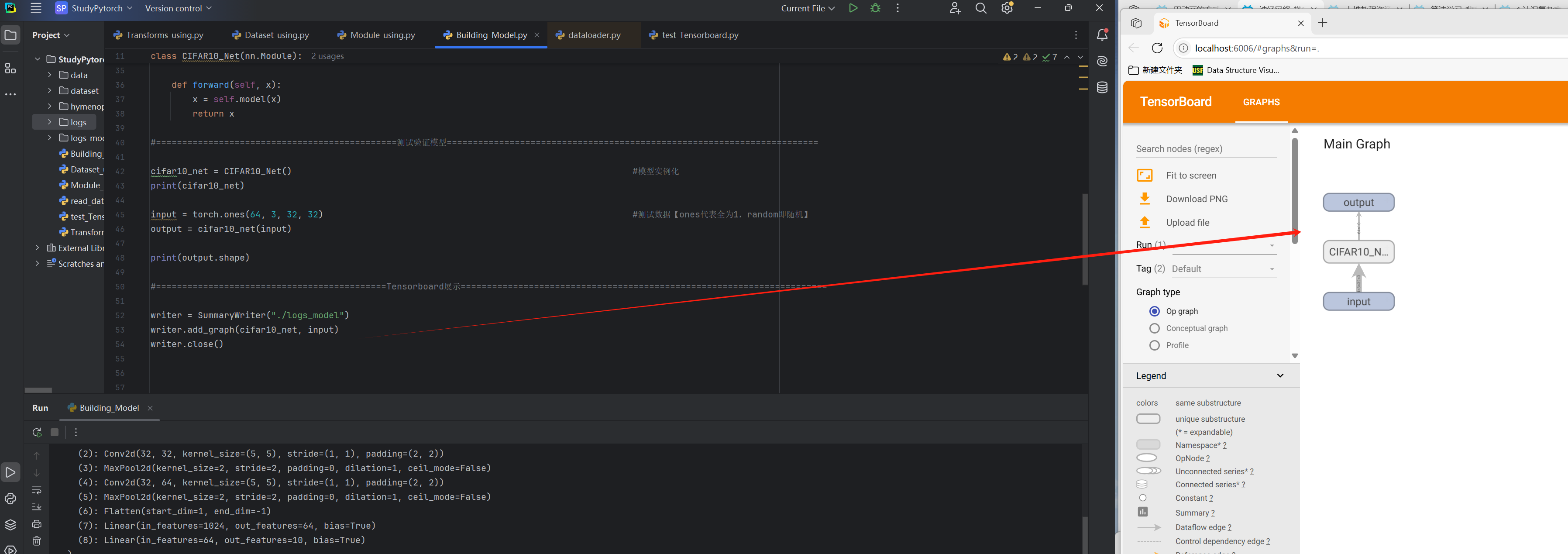
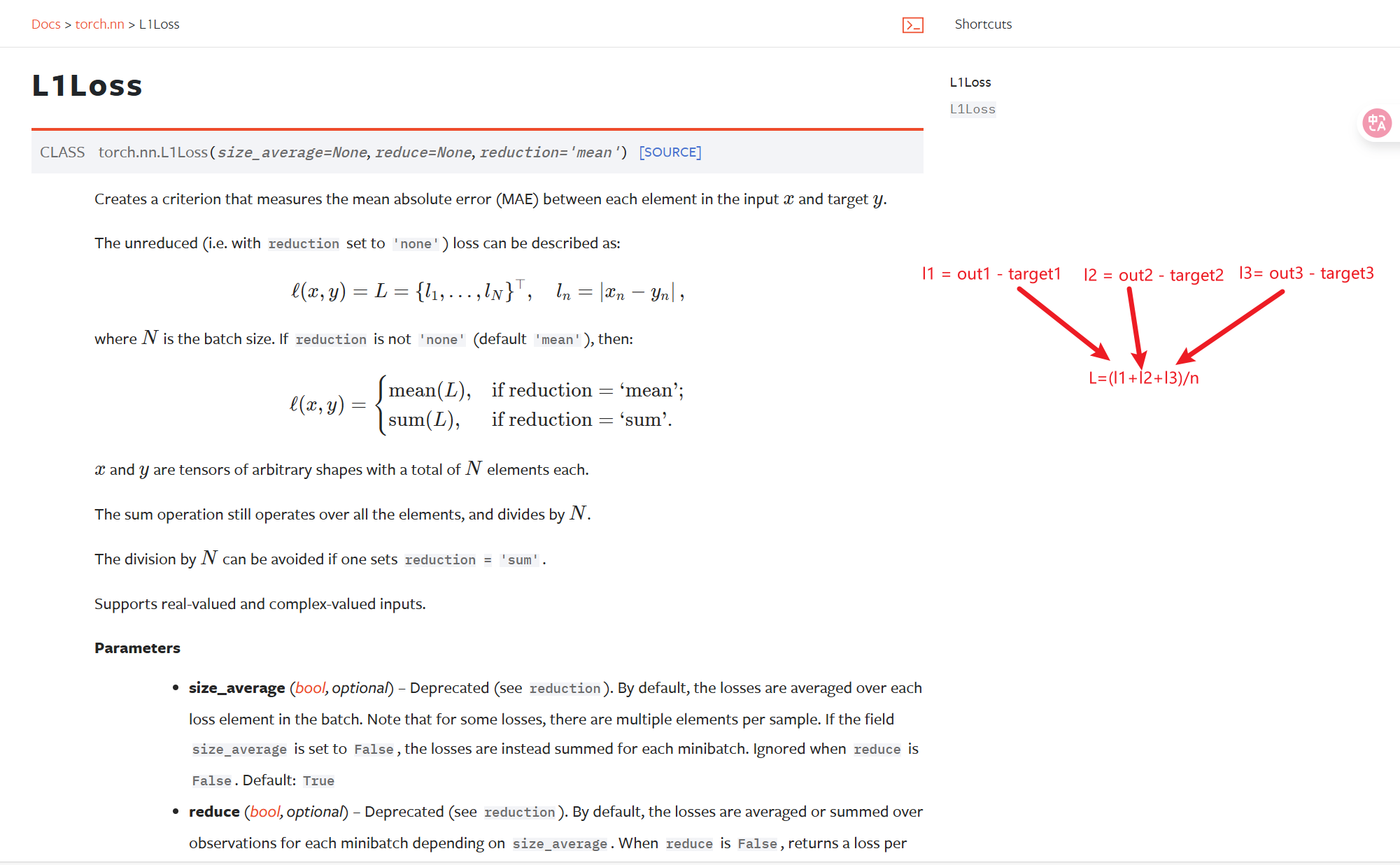
Loss损失函数
求和平均L1Loss
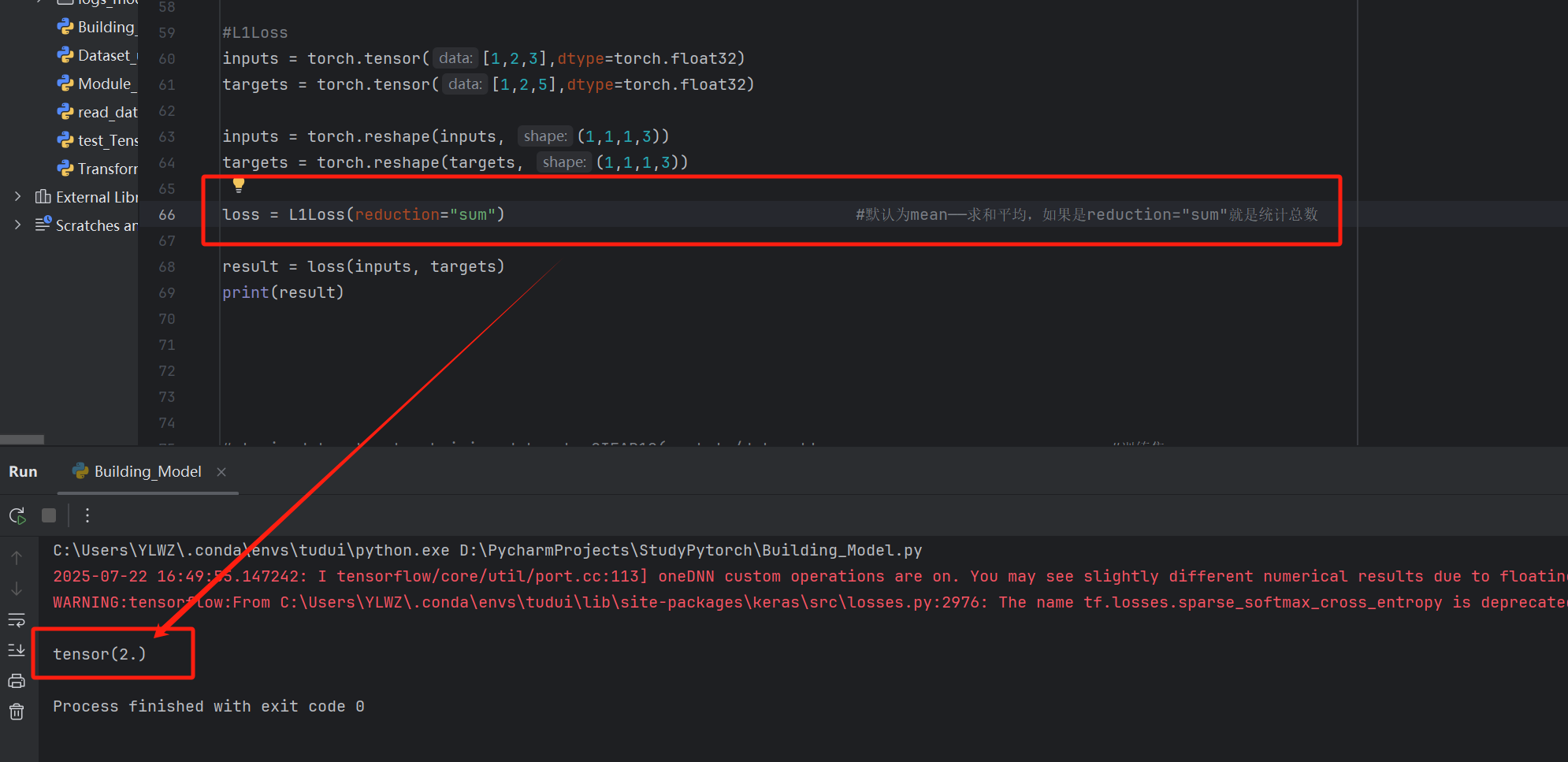
python
#L1Loss
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs, (1,1,1,3))
targets = torch.reshape(targets, (1,1,1,3))
loss = L1Loss() #默认为mean------求和平均,如果是reduction="sum"就是统计总数
result = loss(inputs, targets)
print(result)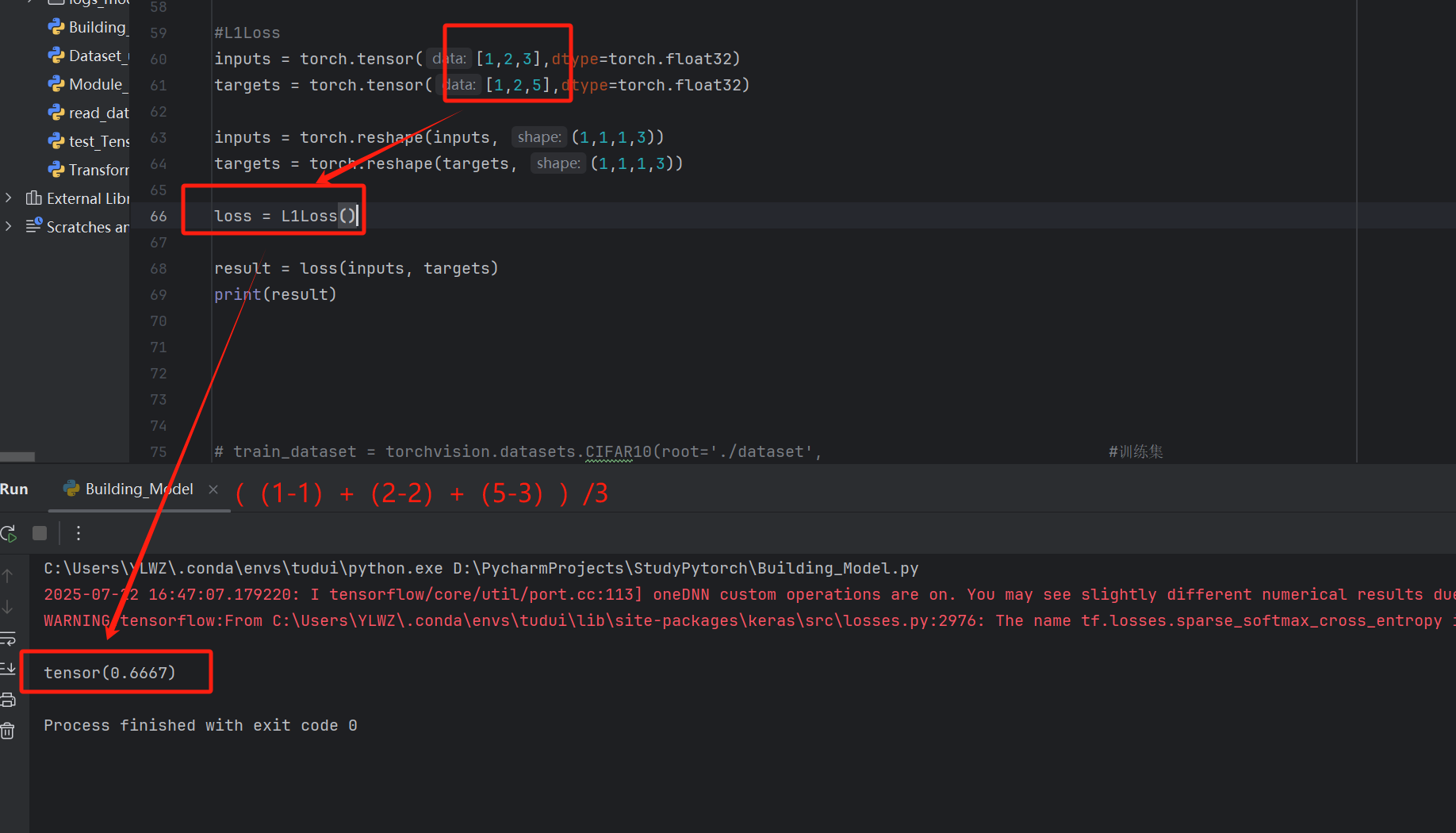
平方差MSELoss

python
#MSELoss
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs, (1,1,1,3))
targets = torch.reshape(targets, (1,1,1,3))
loss = MSELoss() #默认为mean------求和平均,如果是reduction="sum"就是统计总数
result = loss(inputs, targets)
print(result)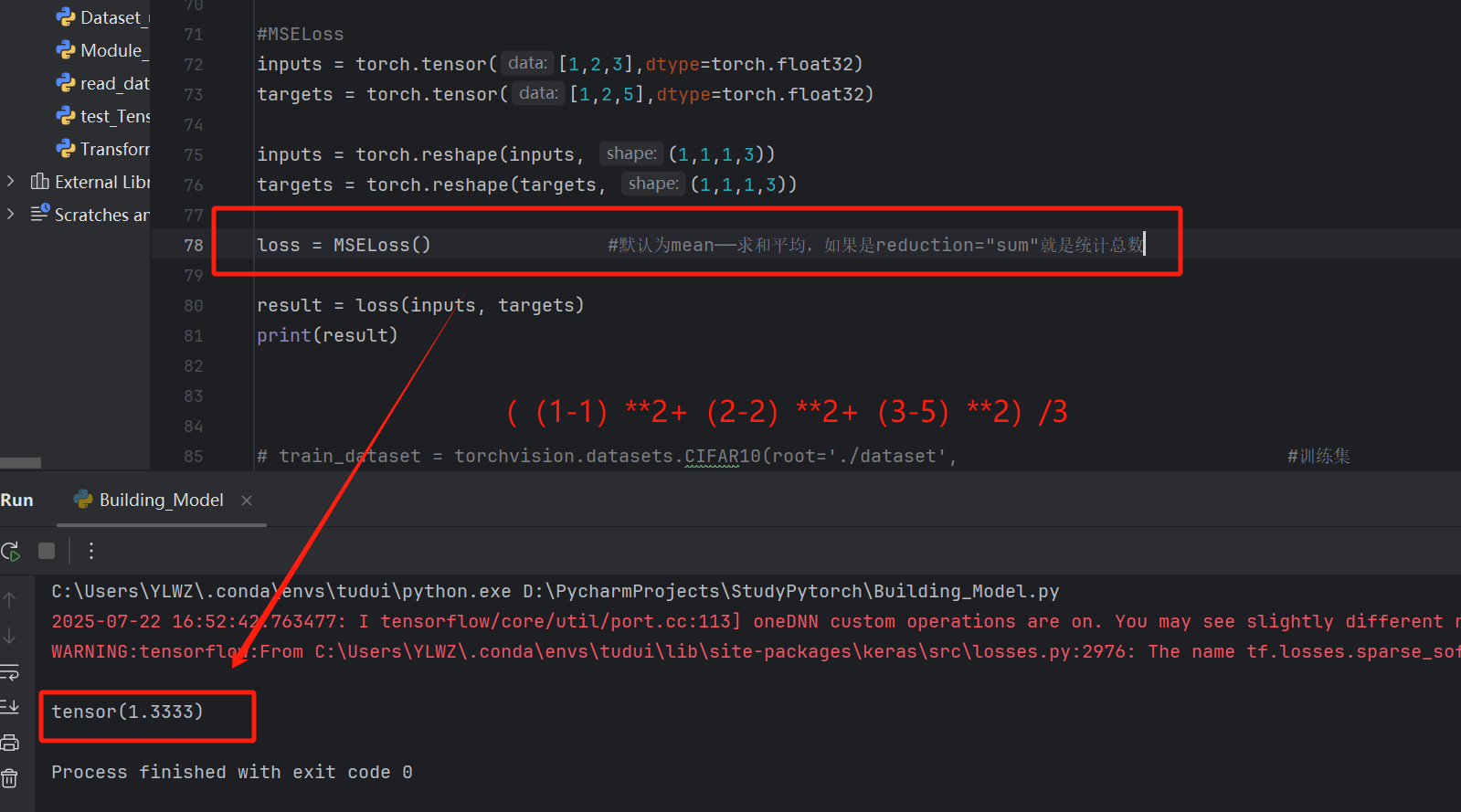
交叉熵CrossEntropyLoss
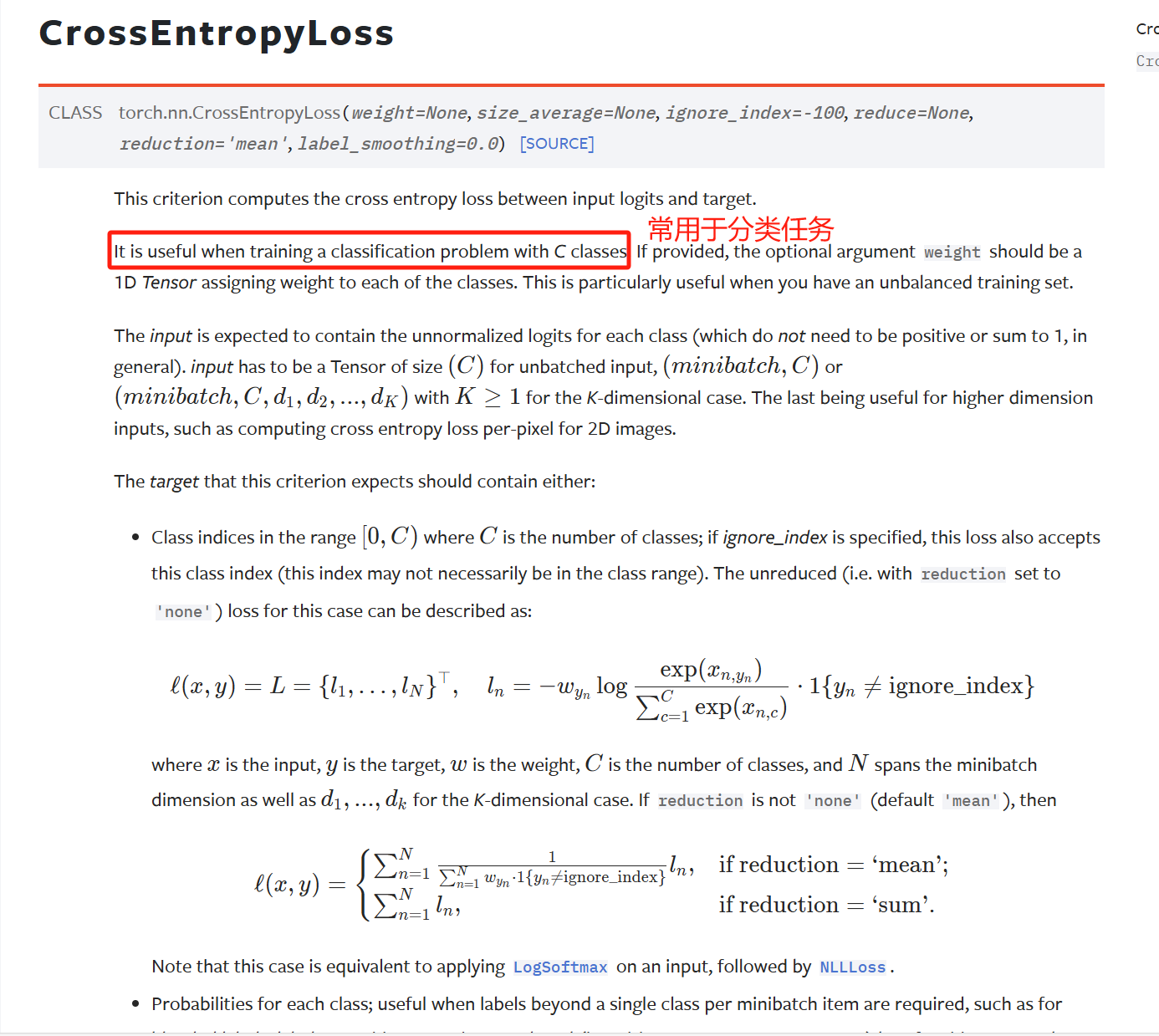

CrossEntropyLoss输入要求

python
#CrossEntropyLoss
inputs = torch.tensor([0.1,0.2,0.3],dtype=torch.float32)
targets = torch.tensor([1]) #标签
inputs = torch.reshape(inputs, (1,3)) #CrossEntropyLoss要求的输入形状是(N,C) =》(batch_size,number of class)
loss = CrossEntropyLoss()
result = loss(inputs, targets)
print(result)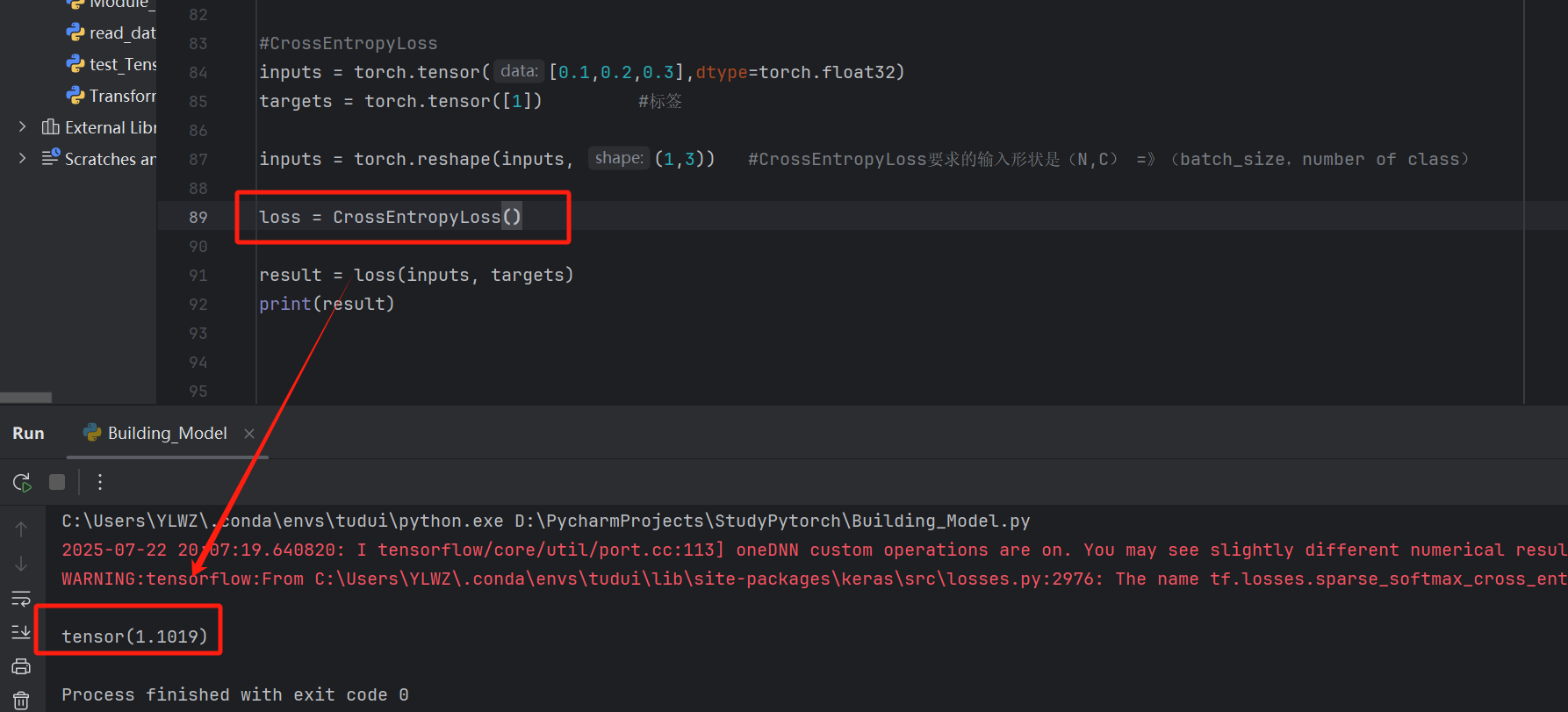
损失的梯度计算
梯度计算即是反向传播,通过利用backward函数进行计算,计算好的结果会存放到model中
给result_loss.backward()这一步打上断点,执行调试【右上角的虫子,在运行旁边】
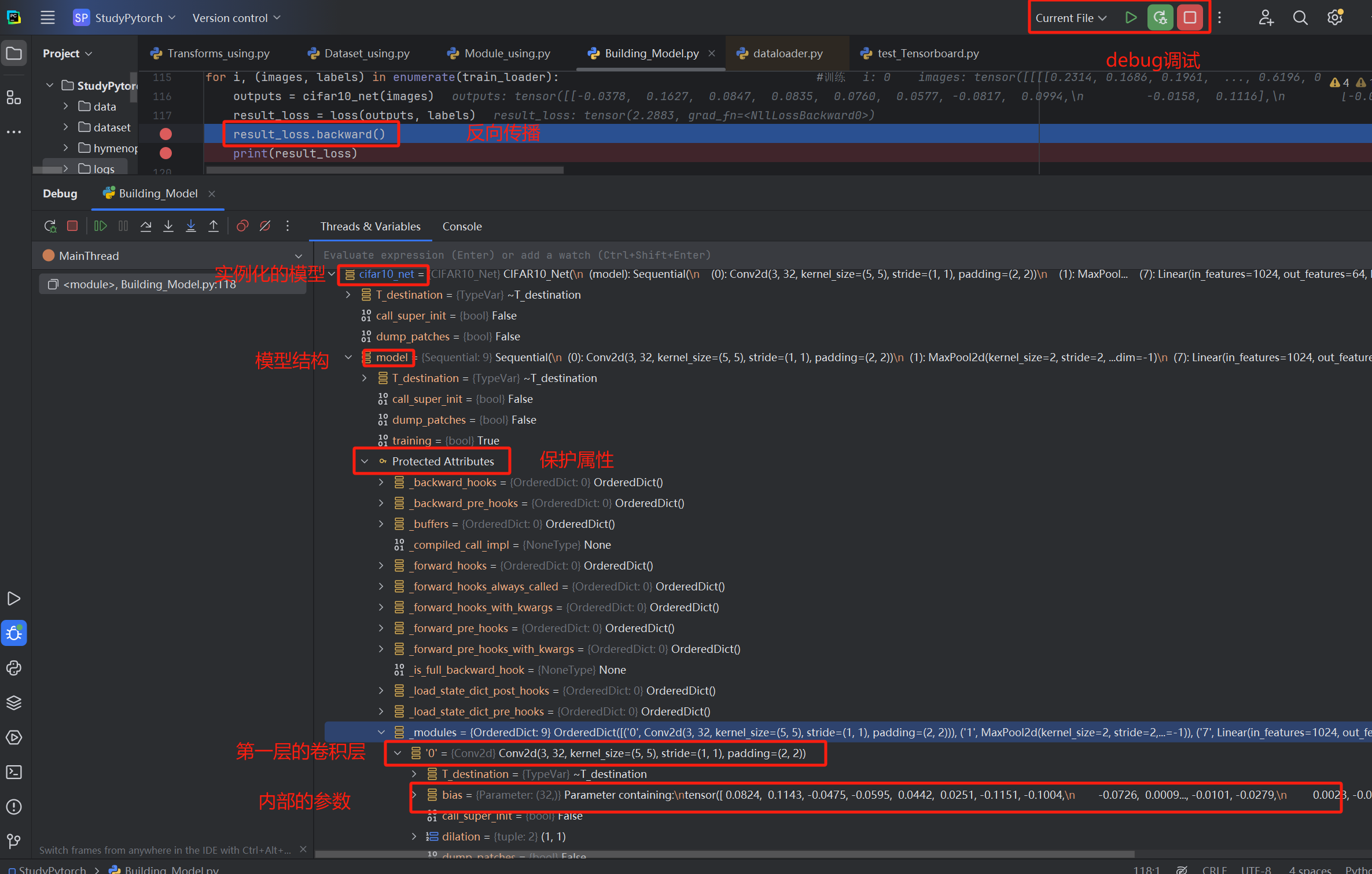
执行result_loss.backward()这一步后,梯度结果就会存放在model中【我们输入的output数据类型是tensor,而tensor中会保存计算的前向路径,因此backward就可以自动追踪路径定位到相应model,往其中存放梯度grad】
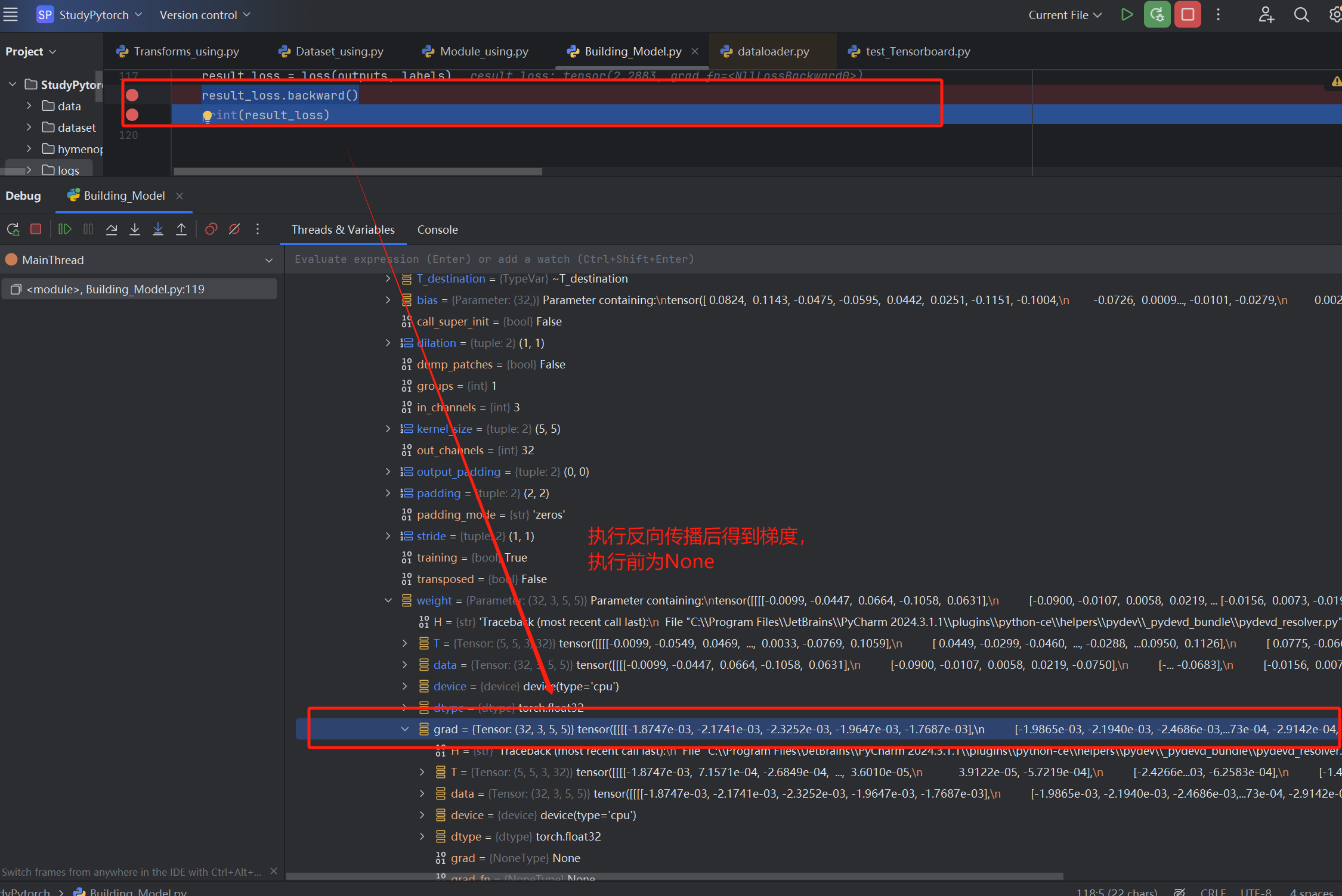
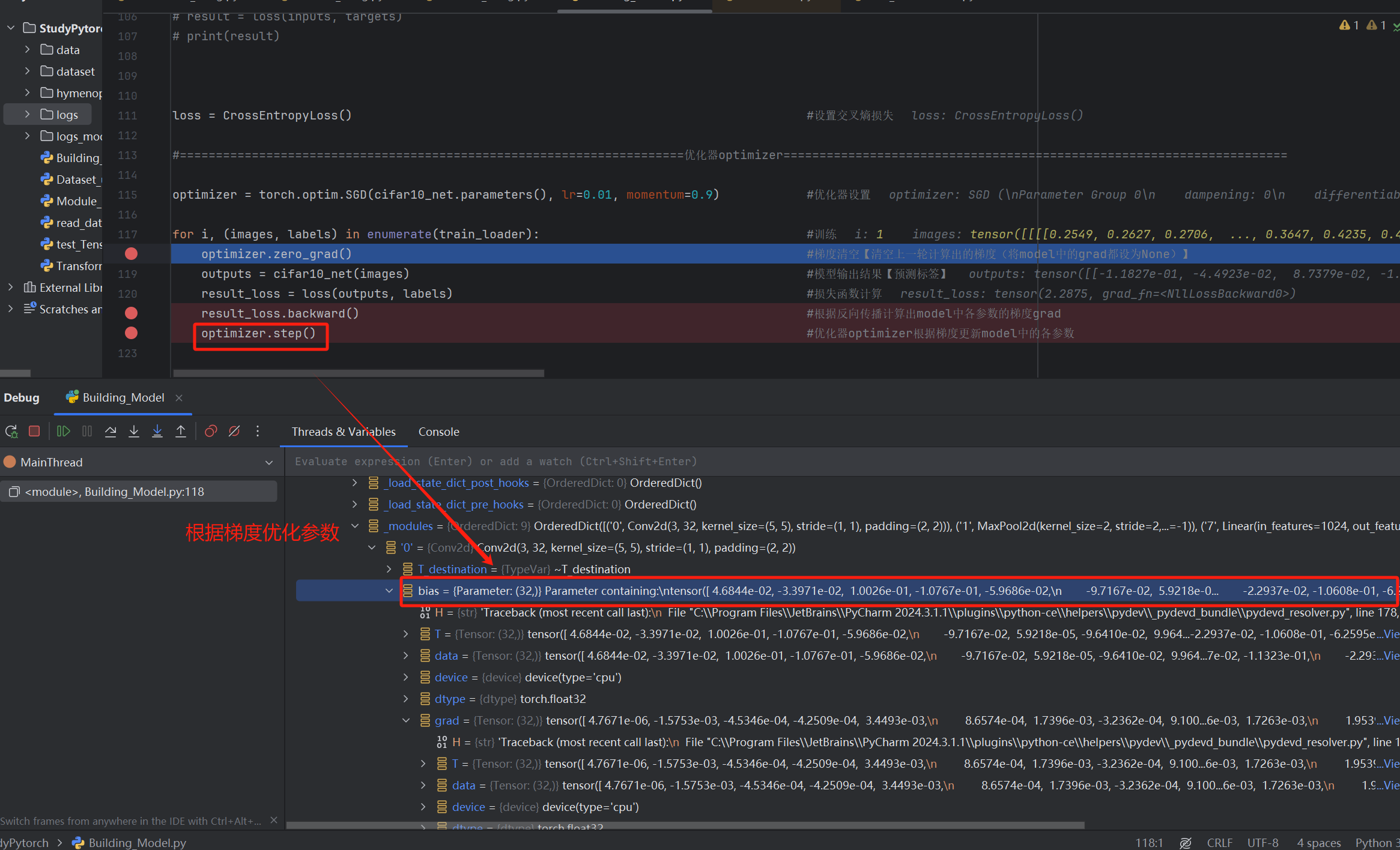
优化器optimizer
通过损失函数我们已经计算出了模型中各参数的梯度grad,优化器optimizer的作用就是根据梯度进行参数更新
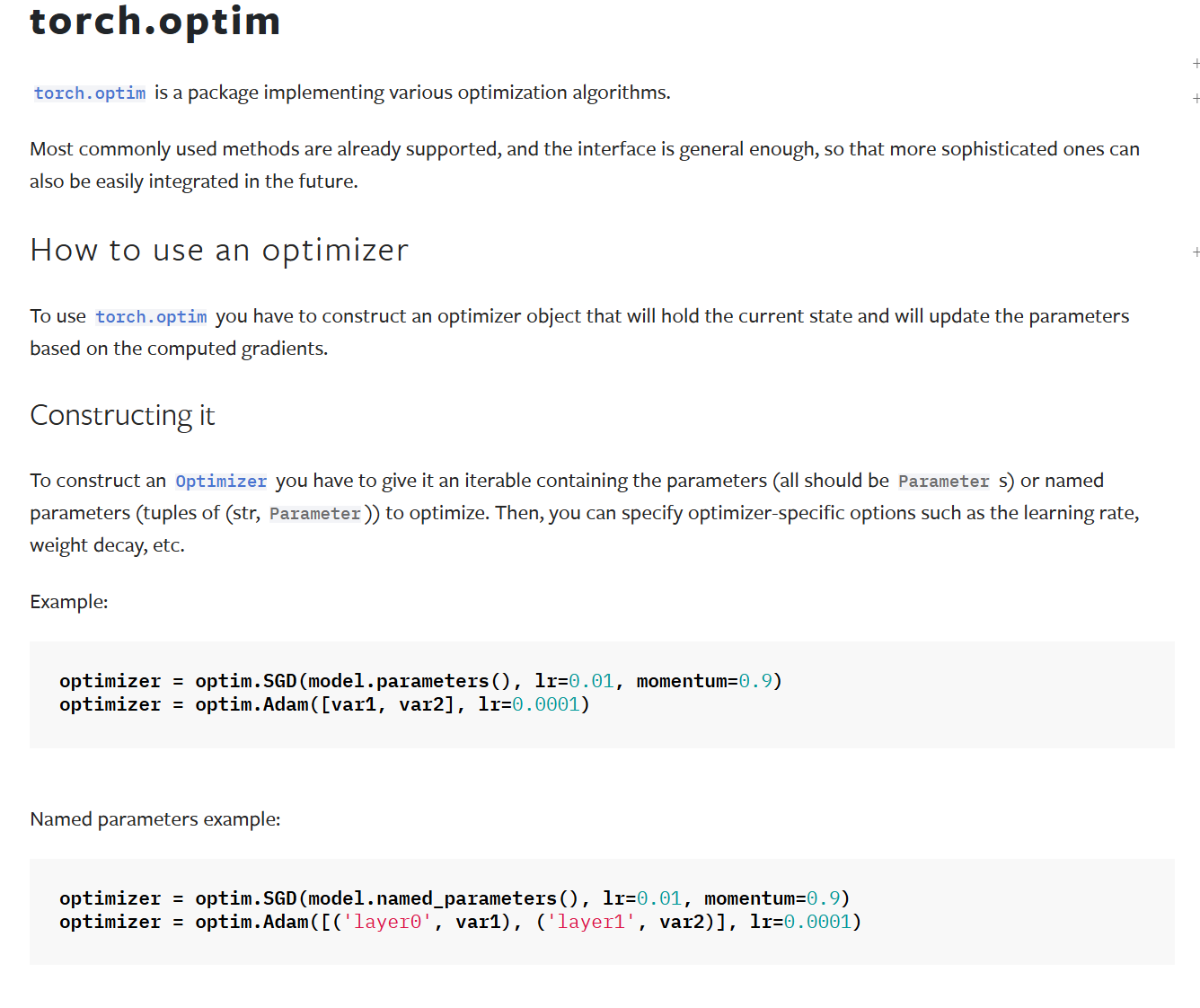
使用示例
【optimizer.step()的作用就是根据梯度gard更新参数,而optimizer.zero_grad()是清空model中的梯度,以防止上次的梯度影响这次优化器优化,接着重新利用loss.back()重新计算梯度,循环往复】
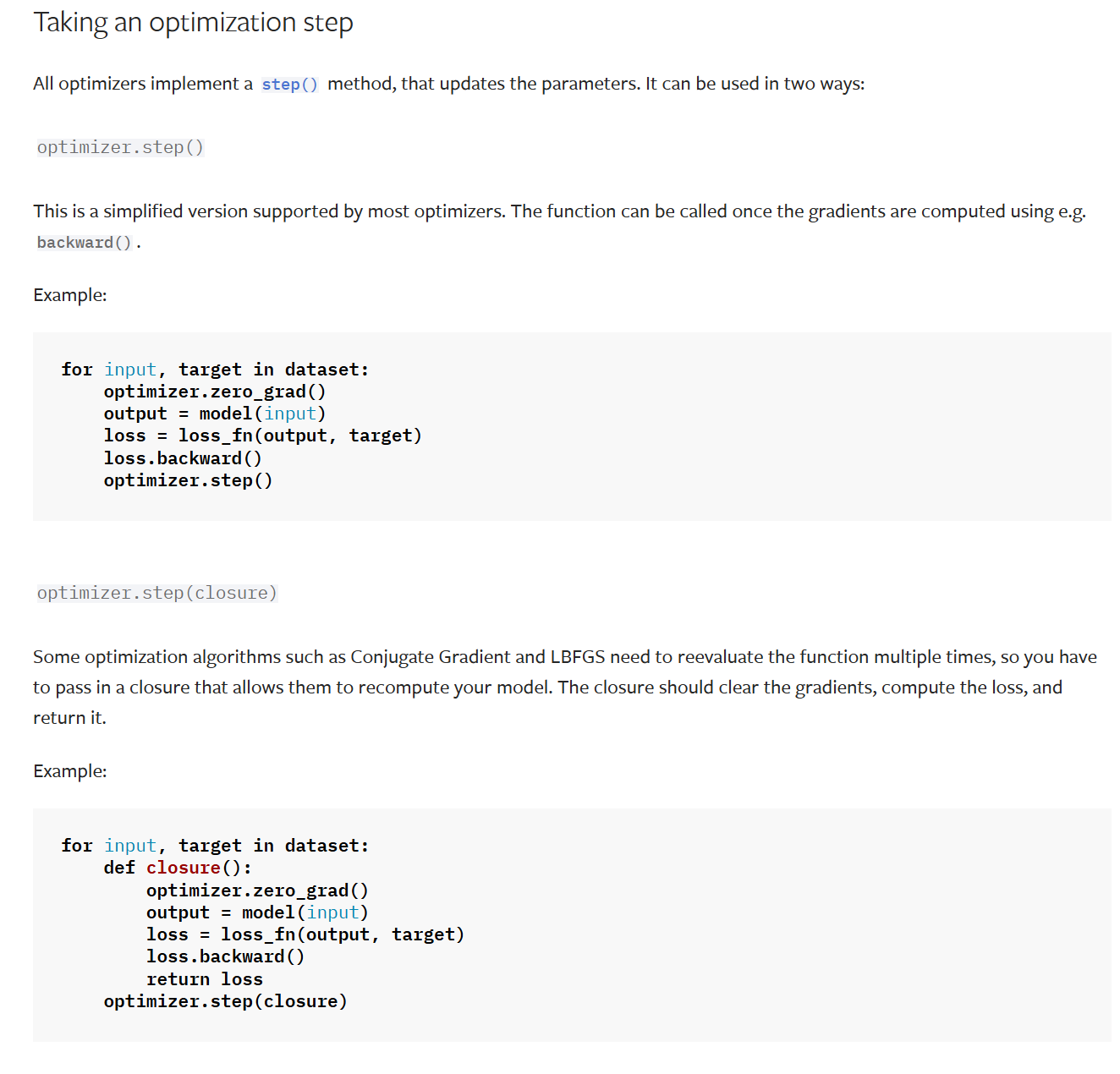
【1】梯度清零
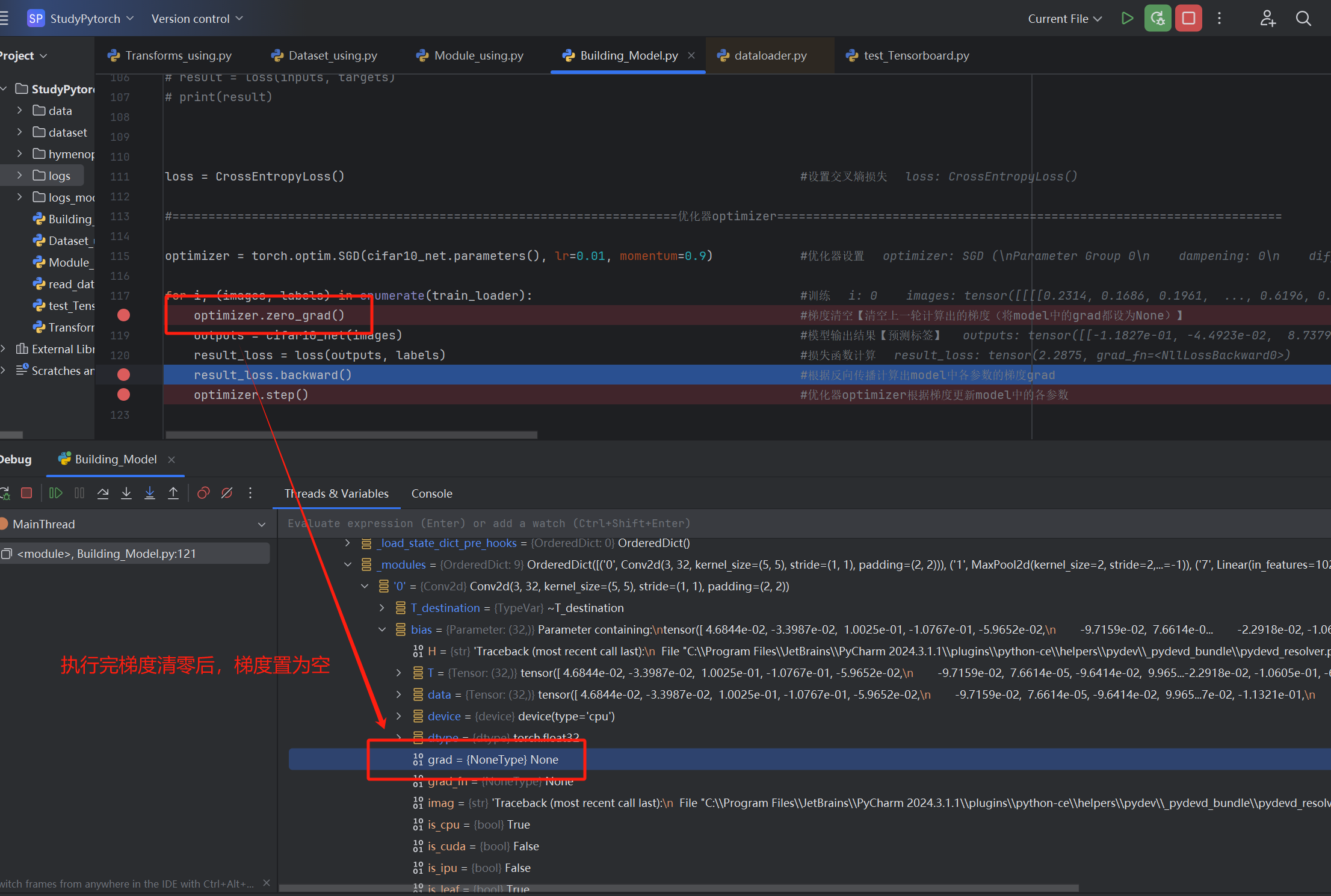
【2】反向传播求梯度
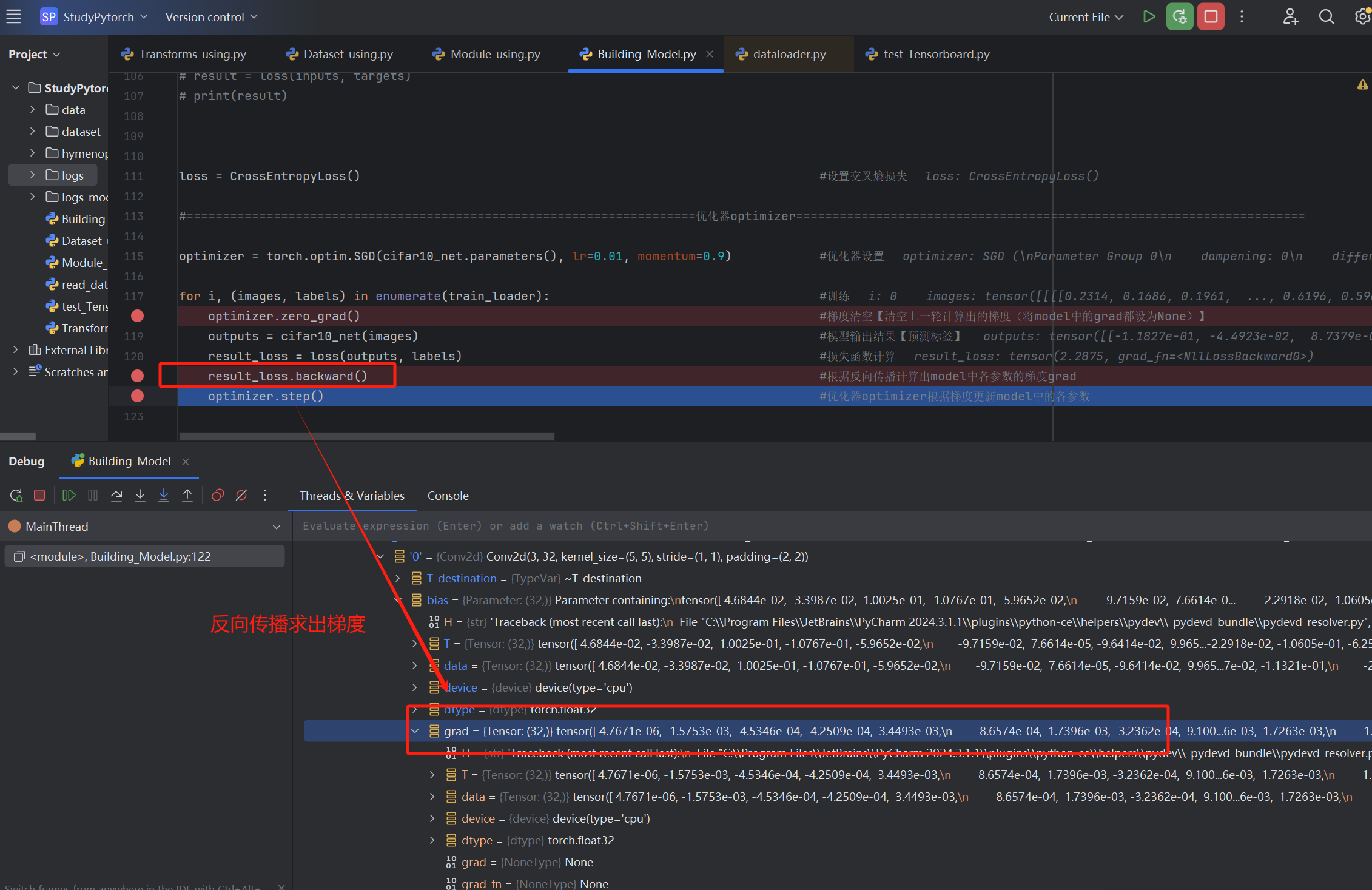
【3】根据梯度,优化器更新参数
更新前

更新后
【4】循环往复(重复前面的步骤)
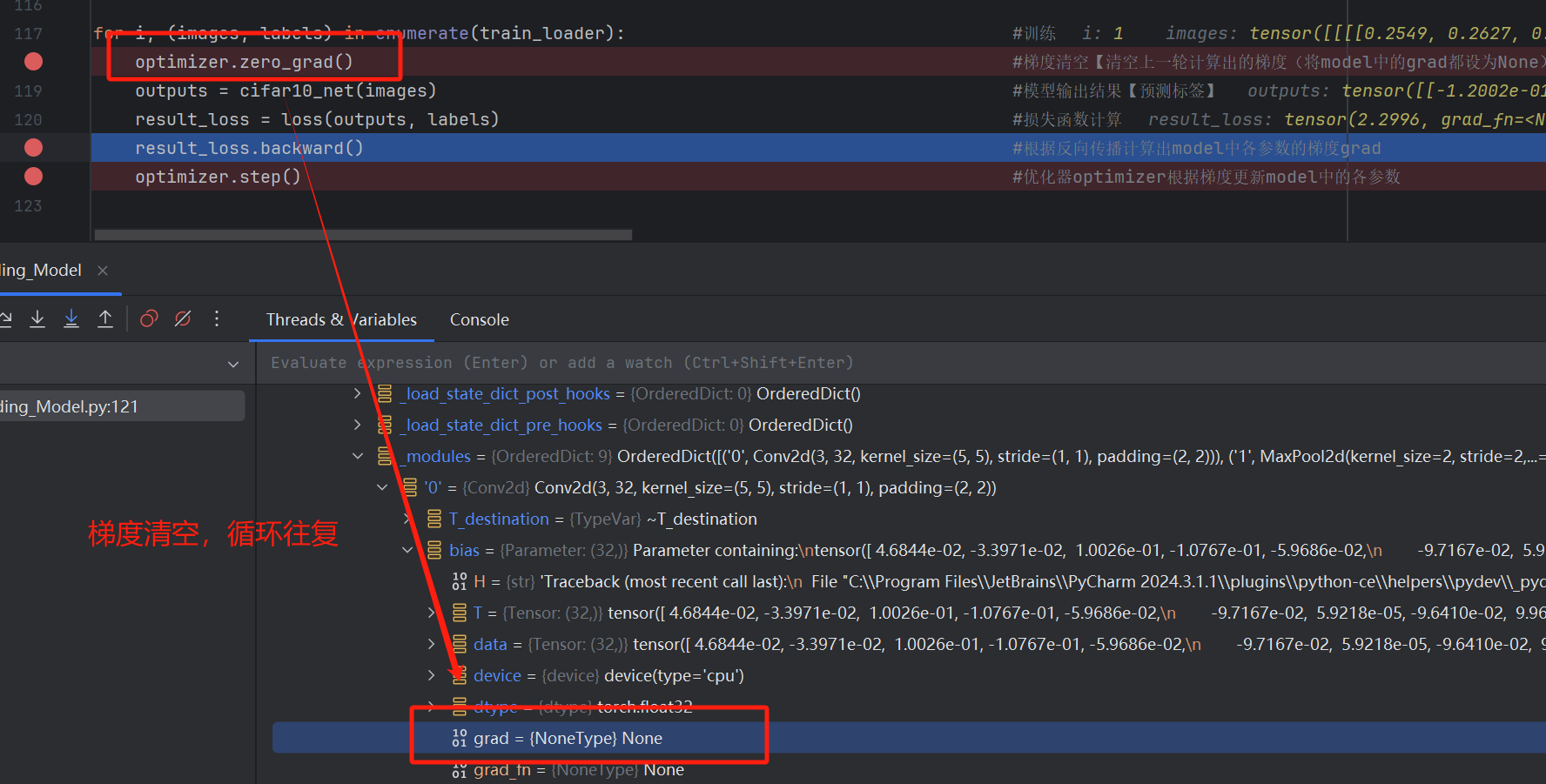
以上遍历完整个数据集(训练集)就相当于一轮学习,我们训练时往往要经过多轮学习,不断优化model参数
python
for epoch in range(20):
running_loss = 0.0 #统计这一轮的总损失
for i, (images, labels) in enumerate(train_loader): #训练
optimizer.zero_grad() #梯度清空【清空上一轮计算出的梯度(将model中的grad都设为None)】
outputs = cifar10_net(images) #模型输出结果【预测标签】
result_loss = loss(outputs, labels) #损失函数计算
result_loss.backward() #根据反向传播计算出model中各参数的梯度grad
optimizer.step() #优化器optimizer根据梯度更新model中的各参数
running_loss += result_loss #统计这一轮的总损失
print('epoch:{}, running_loss:{}'.format(epoch, running_loss)) #输出这一轮的总损失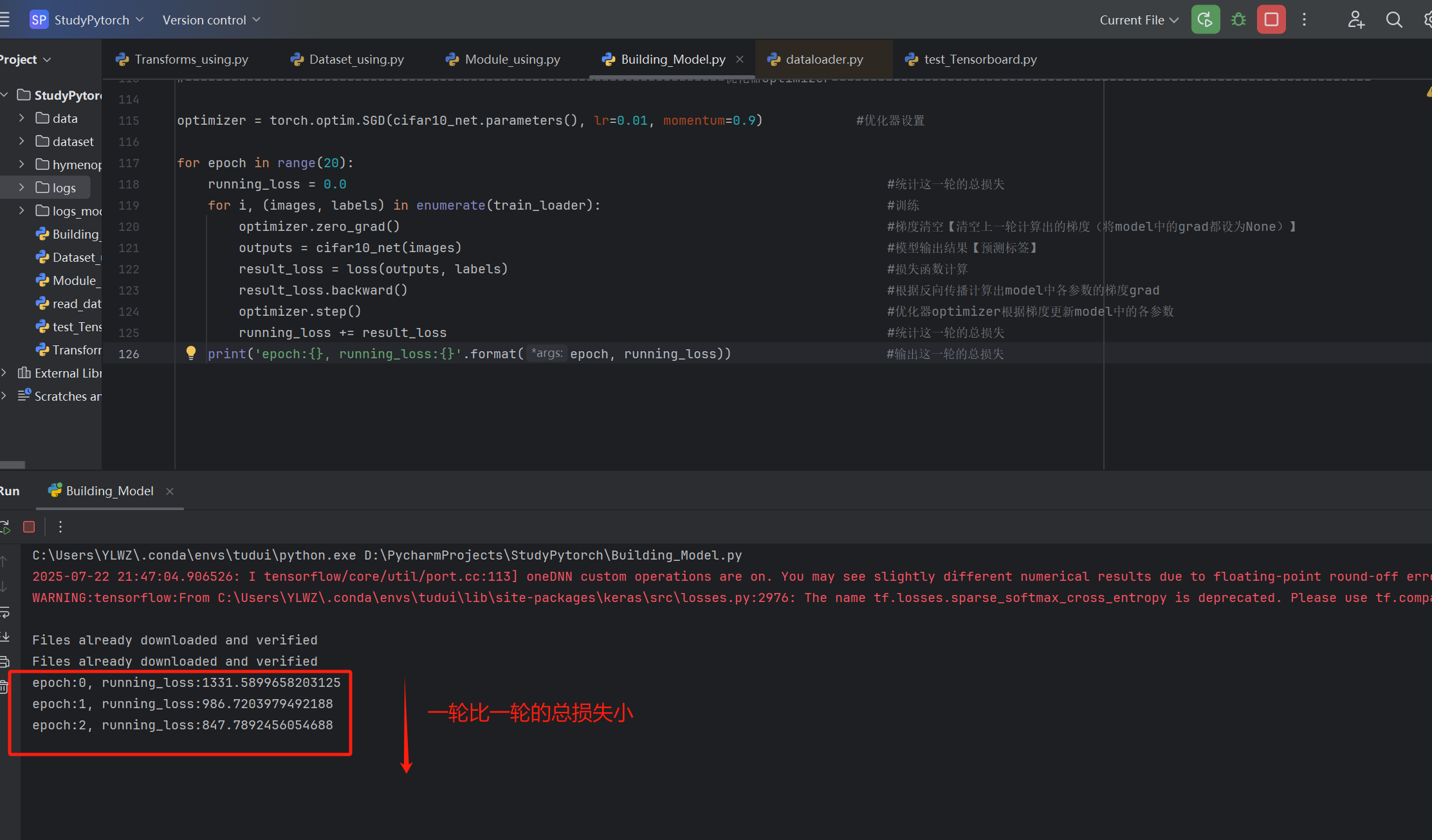
网络模型读取和保存
模型保存
保存方式1:save(model,save_path)【完全保存】
保存网络模型的同时也保存相应的参数,".pth"的后缀其实取什么都可以,但是默认是.pth
【注意:该方式加载预训练模型时要求文件中含有model的类(import导入或直接定义,一边都是import导入)】
python
#保存方式1
#保存模型
torch.save(cifar10_net, "cifar10_net.pth") #保存网络模型的同时也保存相应的参数,".pth"的后缀其实取什么都可以,但是默认是.pth
#加载模型
load_net = torch.load("cifar10_net.pth")
print(load_net)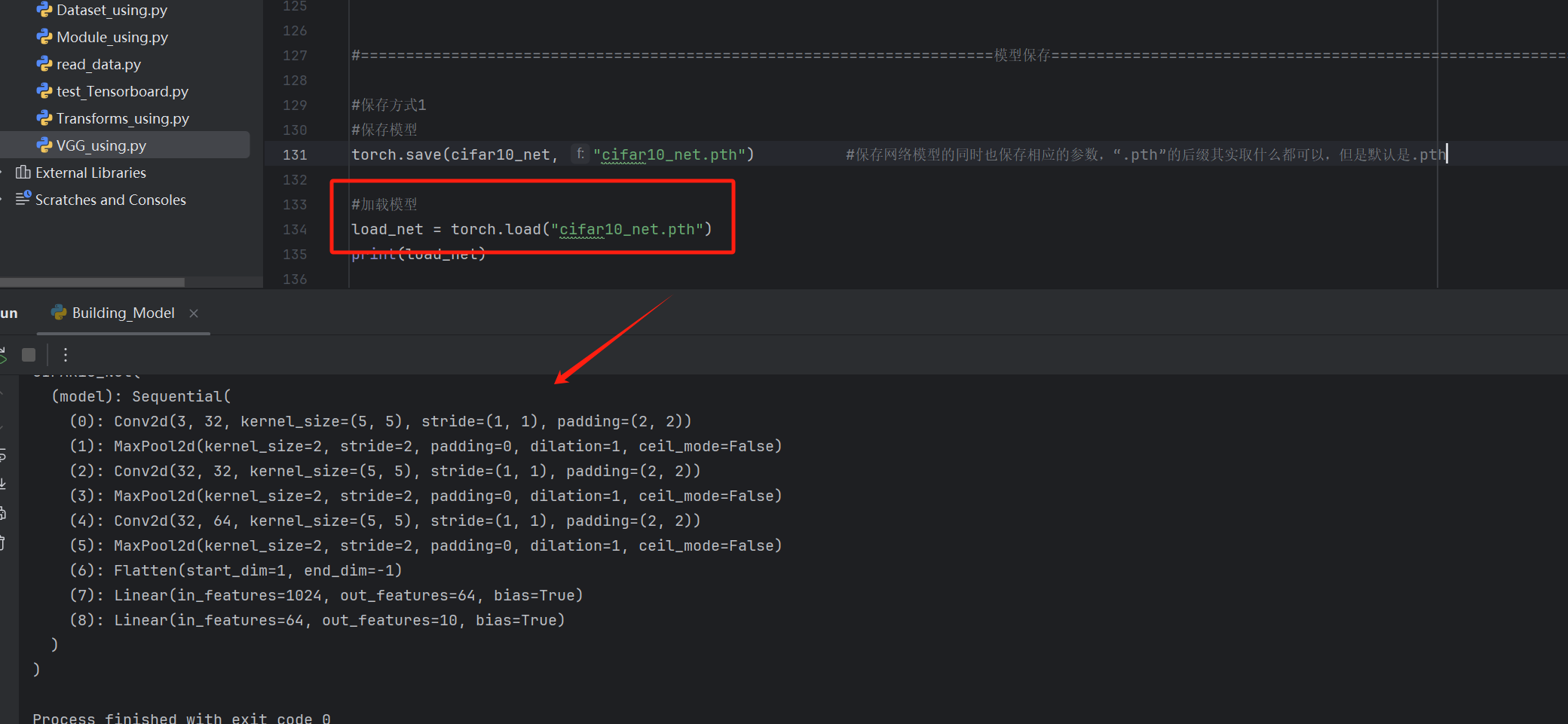
保存方式2:save(model.state_dict,save_path)【只保存参数字典】
只保存模型相应的参数,不保存模型的网络结构(官方推荐,保存下来占用的空间小)
python
#保存方式2(官方推荐,保存下来占用的空间小)
#保存模型
torch.save(cifar10_net.state_dict(), "cifar10_dict.pth") #用字典保存模型相应的参数,不保存模型的网络结构
#加载模型
load_net = CIFAR10_Net() #实例化模型
load_dict = torch.load("cifar10_dict.pth") #加载参数字典
load_net.load_state_dict(load_dict) #将参数字典加载到模型结构汇总
print(load_net)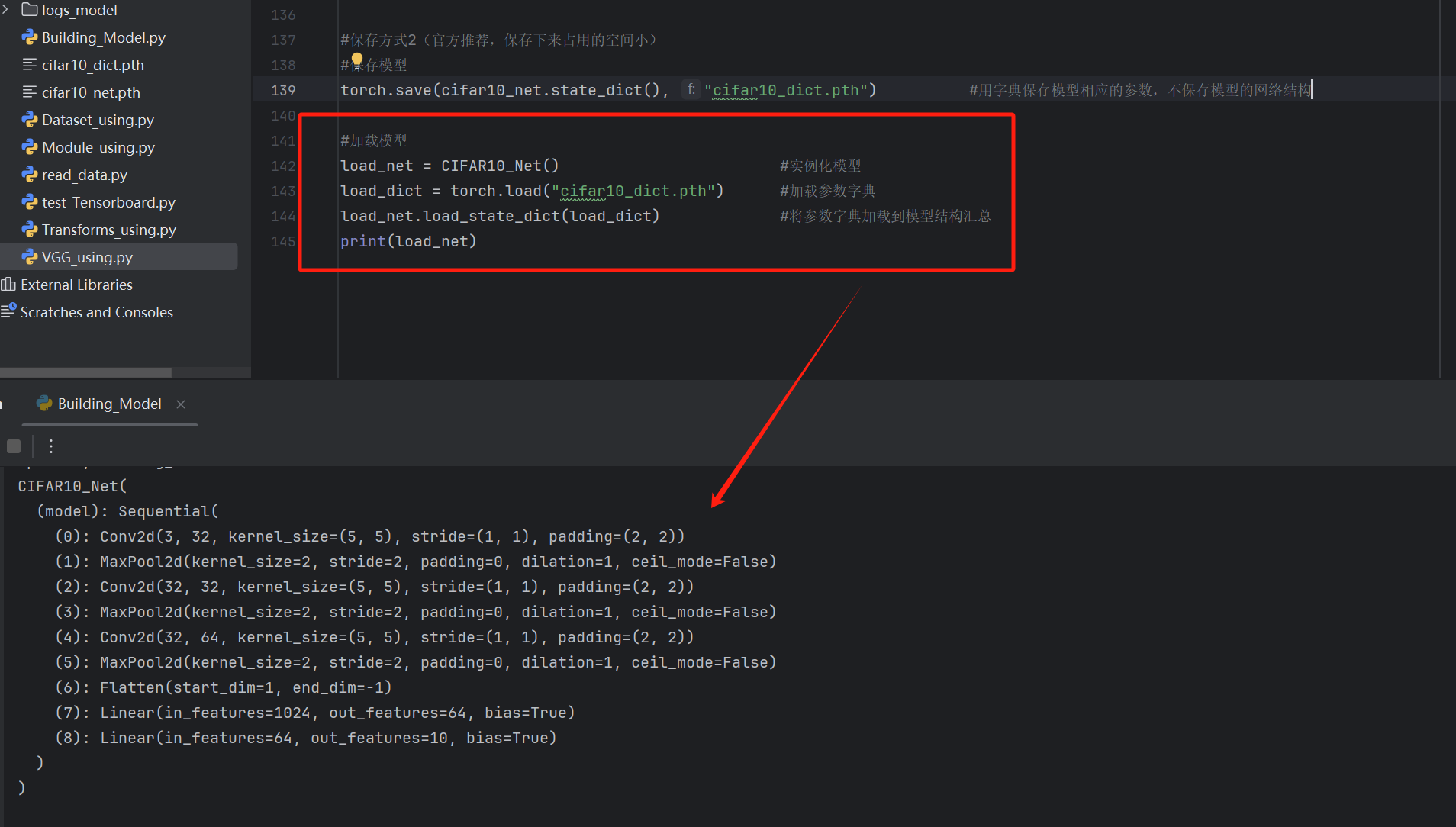
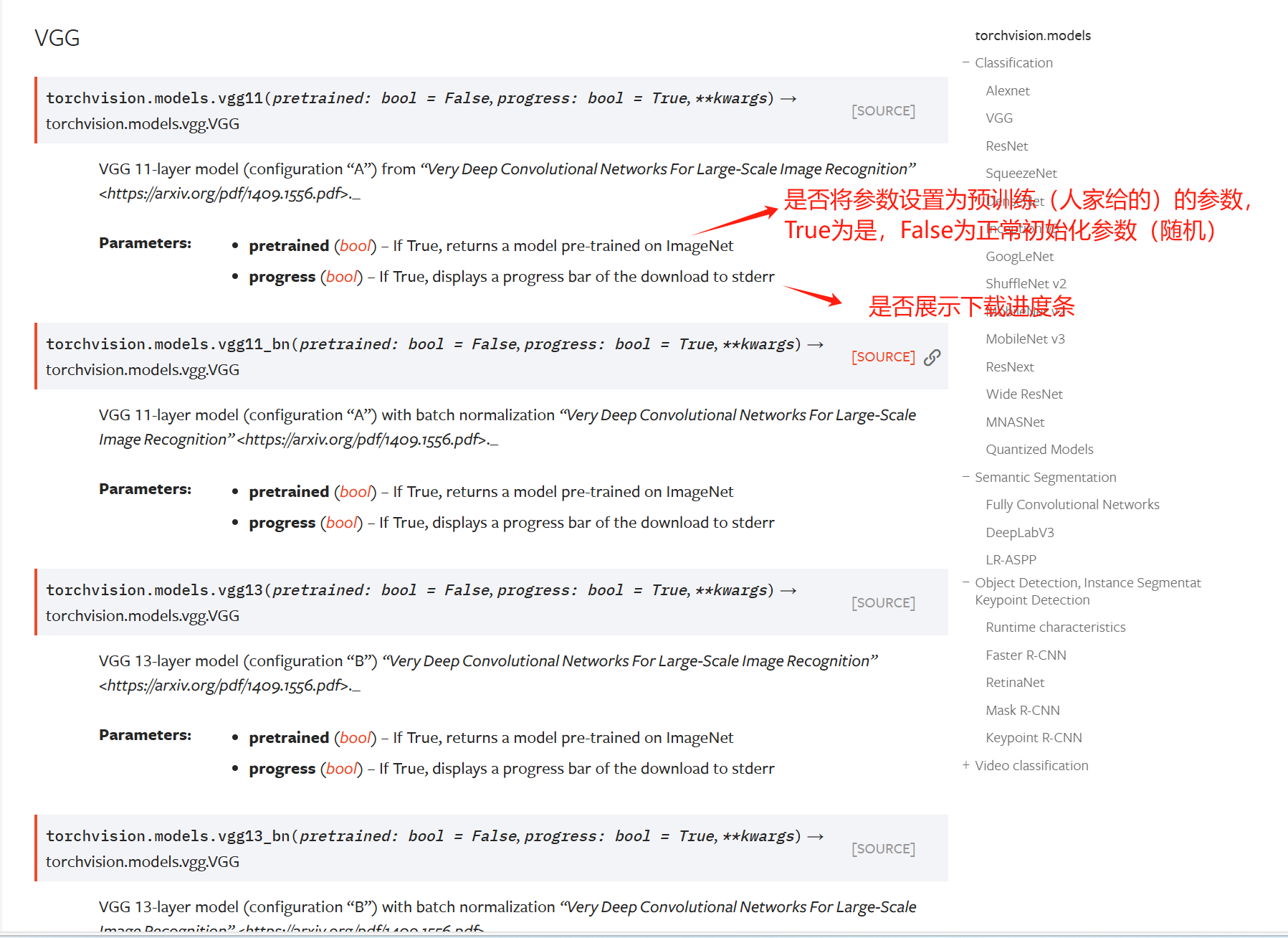
现有网络模型(Pytorch提供)的使用
VGG的使用
VGG对应的数据集ImageNet
数据集下载(需在虚拟环境中提前安装scipy包)
python
Train_Dataset = torchvision.datasets.ImageNet(root='./ImageNet_data',
split='train',
transform=torchvision.transforms.ToTensor())
Test_Dataset = torchvision.datasets.ImageNet(root='./ImageNet_data',
split='val',
transform=torchvision.transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(dataset=Train_Dataset,batch_size=64)
test_loader = torch.utils.data.DataLoader(dataset=Test_Dataset,batch_size=64)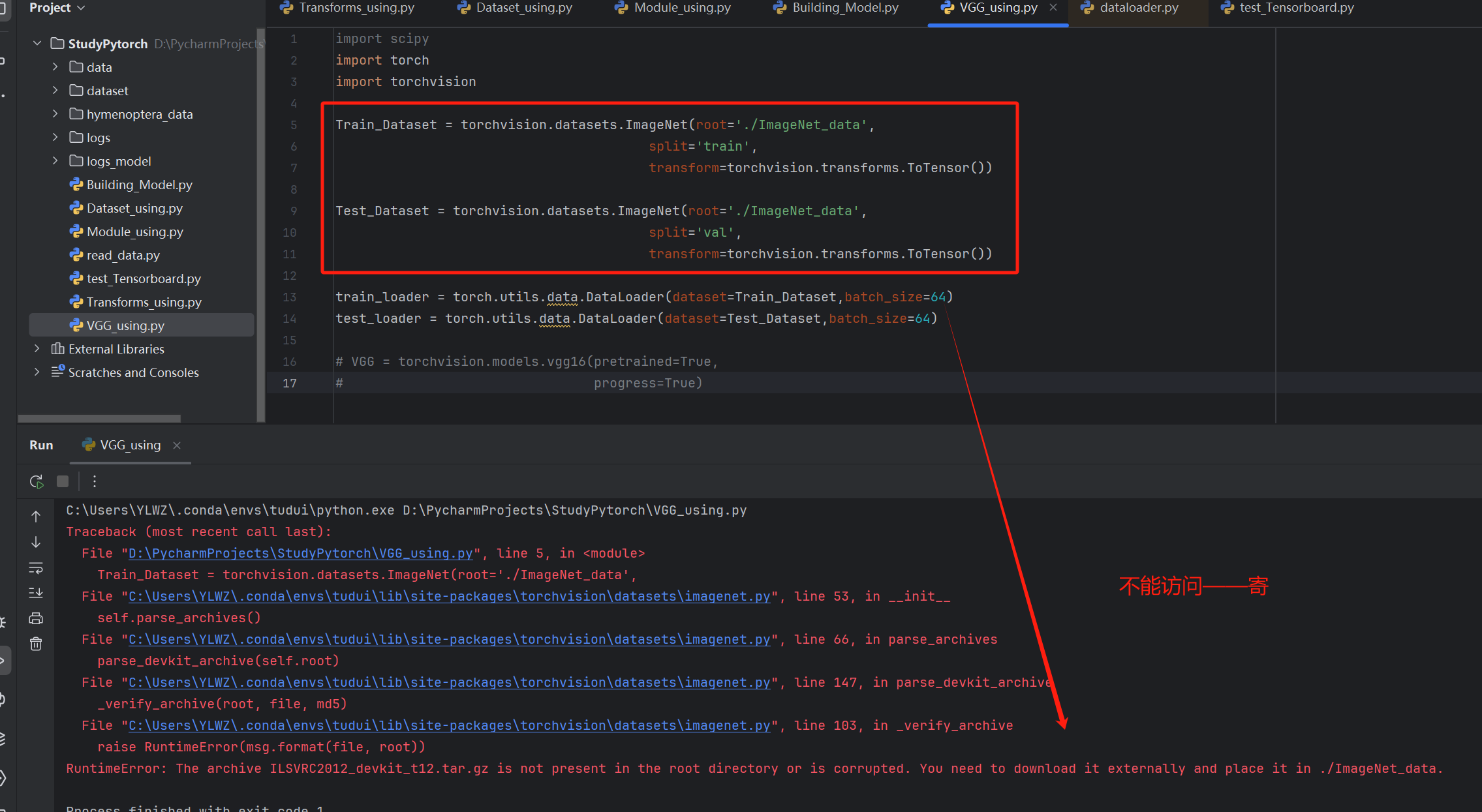
上网下载【不做验证了,数据集太大了,百来个G】
加载预训练模型
python
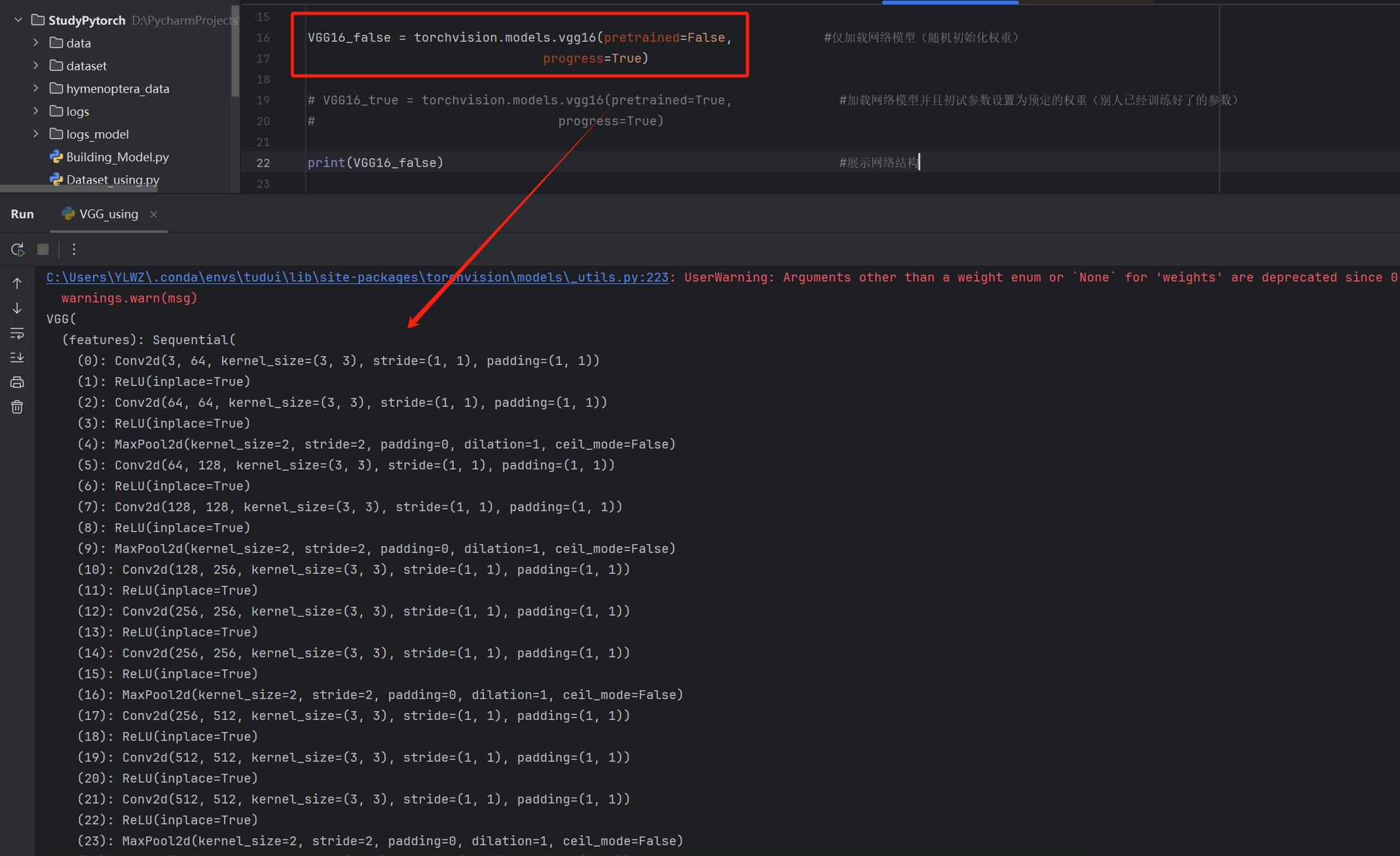
VGG16_false = torchvision.models.vgg16(pretrained=False, #仅加载网络模型(随机初始化权重)
progress=True)
VGG16_true = torchvision.models.vgg16(pretrained=True, #加载网络模型并且初试参数设置为预定的权重(别人已经训练好了的参数)
progress=True)
修改现有网络模型结构
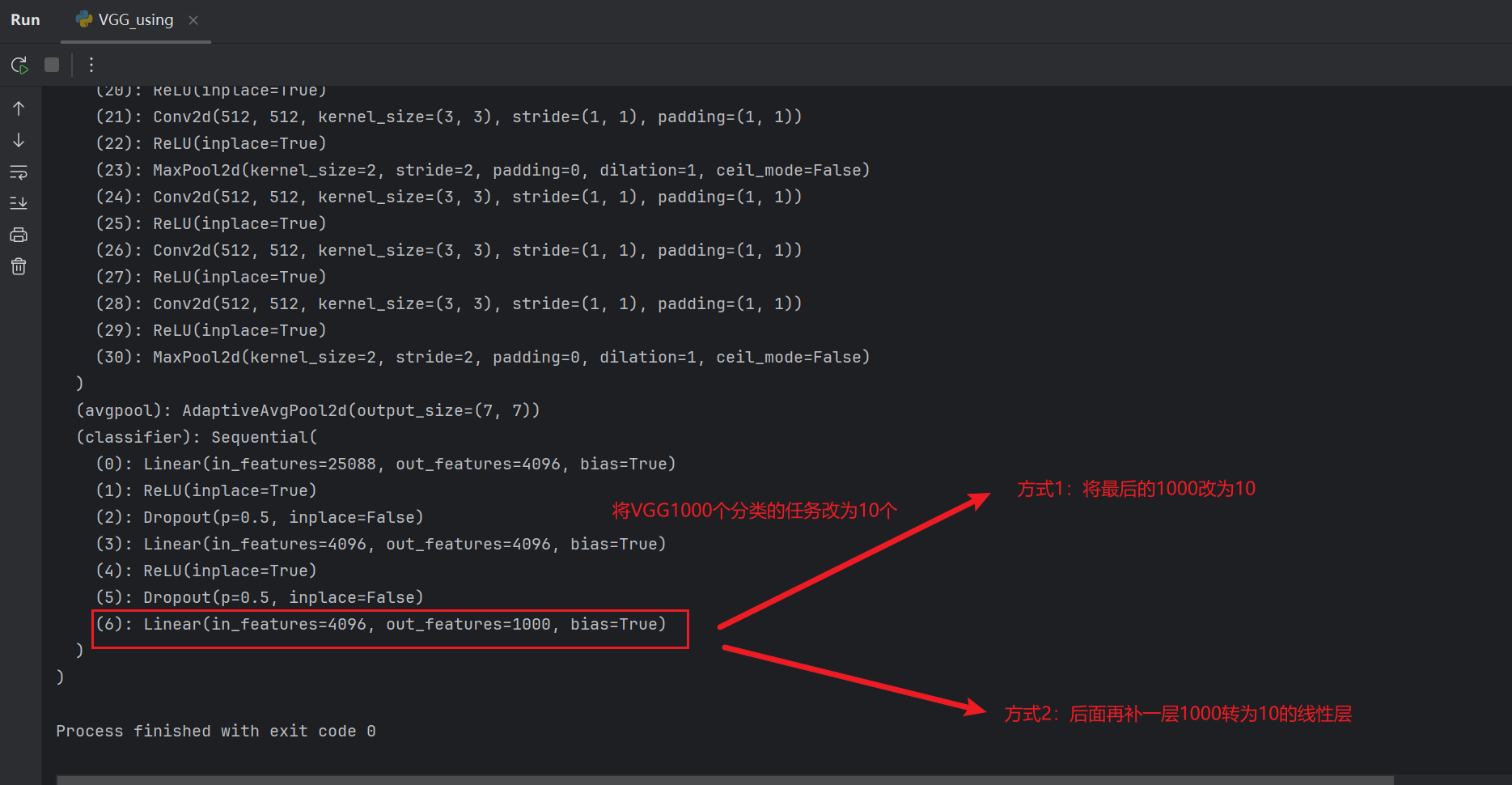
方式1:修改原模型
python
#方式1:修改原模型
VGG16_false.classifier[6] = nn.Linear(4096, 10)
print(VGG16_false)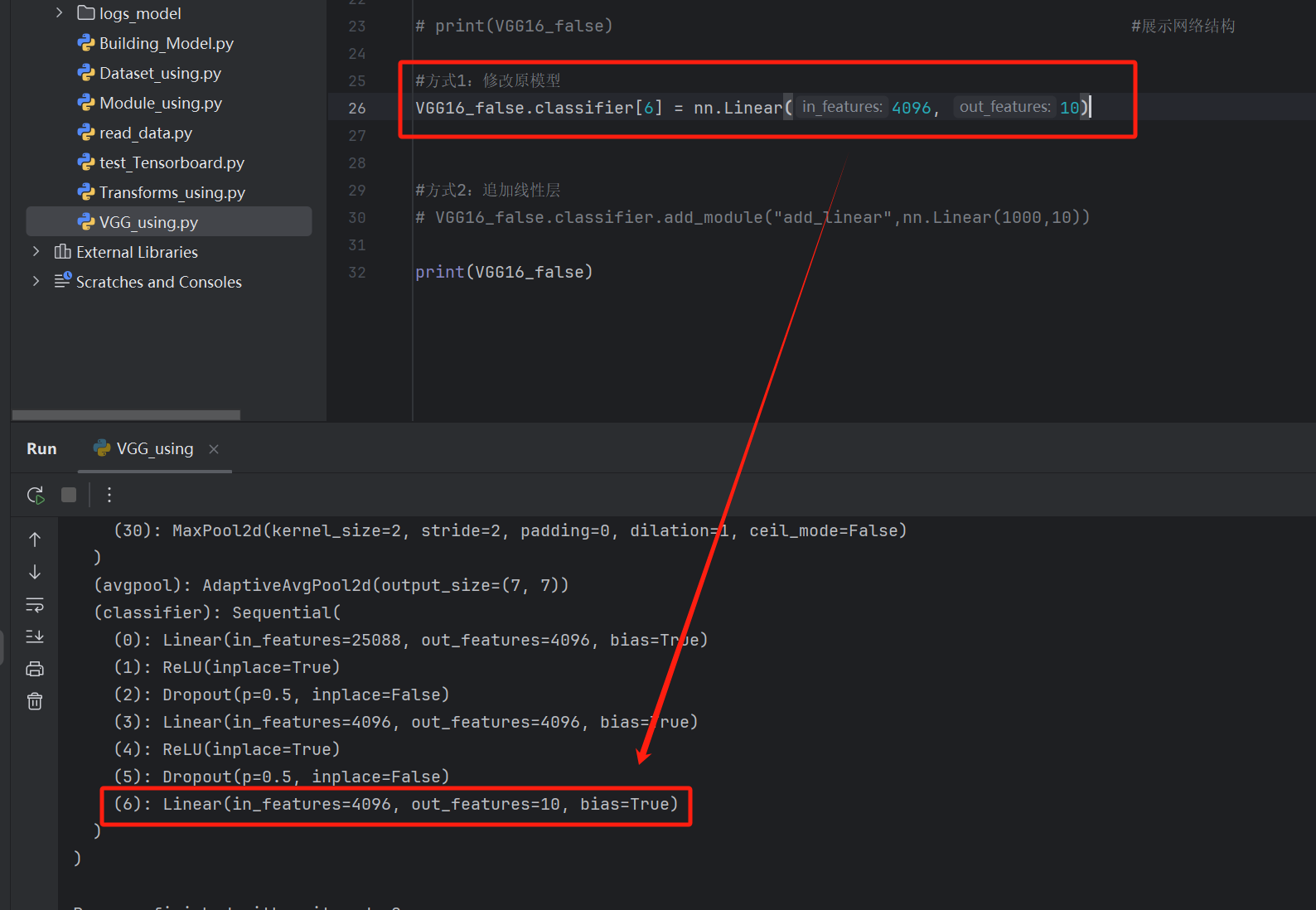
方式2:追加线性层
使用add_module()函数
python
#追加线性层
VGG16_false.add_module("add_linear",nn.Linear(1000,10))
print(VGG16_false)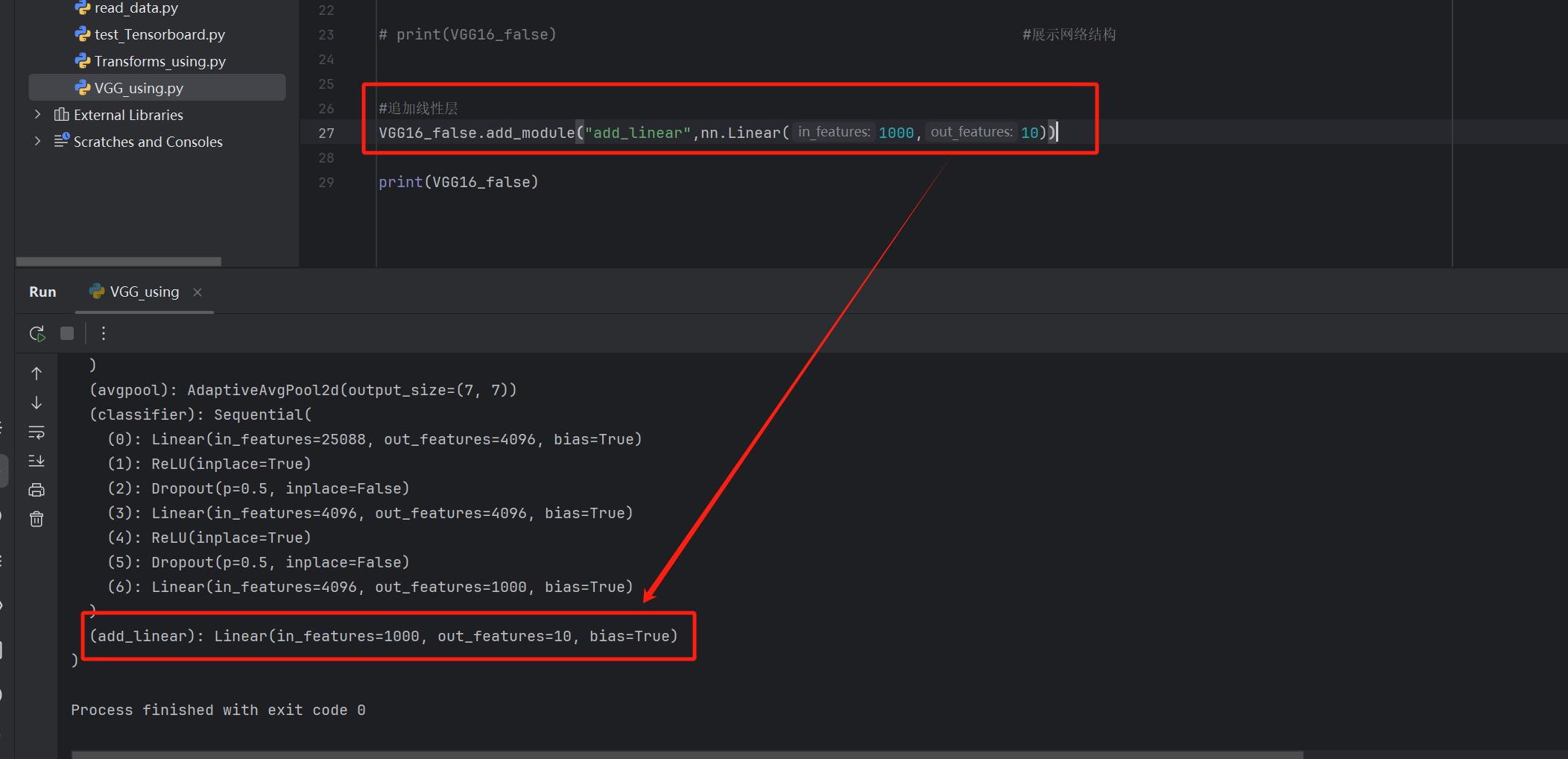
加到classifier(Sequential构造的一连串模块)中
python
VGG16_false.classifier.add_module("add_linear",nn.Linear(1000,10))
print(VGG16_false)
模型训练套路
建立model.py存放模型结构
python
import torch
from torch import nn
#======================================================================模型搭建======================================================================
class CIFAR10_Net(nn.Module):
def __init__(self):
super(CIFAR10_Net, self).__init__()
self.model = nn.Sequential( #Sequential将按各个模块按顺序搭建起来
#卷积输入输出计算:32 = (32 + 2 * padding - 1 * (5-1) - 1) + 1得到padding为2【Hin = 32,stride = 1,dilation = 1,kernel_size = 5,Hout = 32】
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), #第一步是5*5的卷积【将(3*32*32)的图片转为(32*32*32)的数据】
nn.MaxPool2d(kernel_size=2, stride=2), #第二步是2*2最大池化【将(32*32*32)的数据转为(32*16*16)的数据】
#卷积输入输出计算:16 = (16 + 2 * padding - 1 * (5-1) - 1) + 1得到padding为2【Hin = 16,stride = 1,dilation = 1,kernel_size = 5,Hout = 16】
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2), #第三步还是5*5的卷积【将(32*16*16)的数据转为(32*16*16)的数据】
nn.MaxPool2d(kernel_size=2, stride=2), #第四步还是2*2最大池化【将(32*16*16)的数据转为(32*8*8)的数据】
# 卷积输入输出计算:8 = (8 + 2 * padding - 1 * (5-1) - 1) + 1得到padding为2【Hin = 8,stride = 1,dilation = 1,kernel_size = 5,Hout = 8】
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2), #第五步还是5*5的卷积【将(32*8*8)的数据转为(64*8*8)的数据】
nn.MaxPool2d(kernel_size=2, stride=2), #第六步还是2*2最大池化【将(64*8*8)的数据转为(64*4*4)的数据】
nn.Flatten(), #第七步展平数据【将(64*4*4)的数据转为64*4*4的数据】
#全连接层
#上面经过model已经得到数据,接下来要将数据转为输出结构
nn.Linear(64*4*4,64), #第八步线性连接进入隐藏层【将64*4*4的数据输入计算出64个隐藏层结果】
nn.Linear(64,10) #第九步线性连接得出预测【将64的数据输入计算出10个预测结果的分数】
)
def forward(self, x):
x = self.model(x)
return x
#======================================================================测试验证模型======================================================================
if __name__ == '__main__': #main函数==》只在执行本文件时运行,当作为类使用时,这部分不会被引入【目的在于测试该文件,有更好的规范性】
cifar10_net = CIFAR10_Net() #模型实例化
print(cifar10_net)
input = torch.ones(64, 3, 32, 32) #测试数据【ones代表全为1,random即随机】
output = cifar10_net(input)
print(output.shape)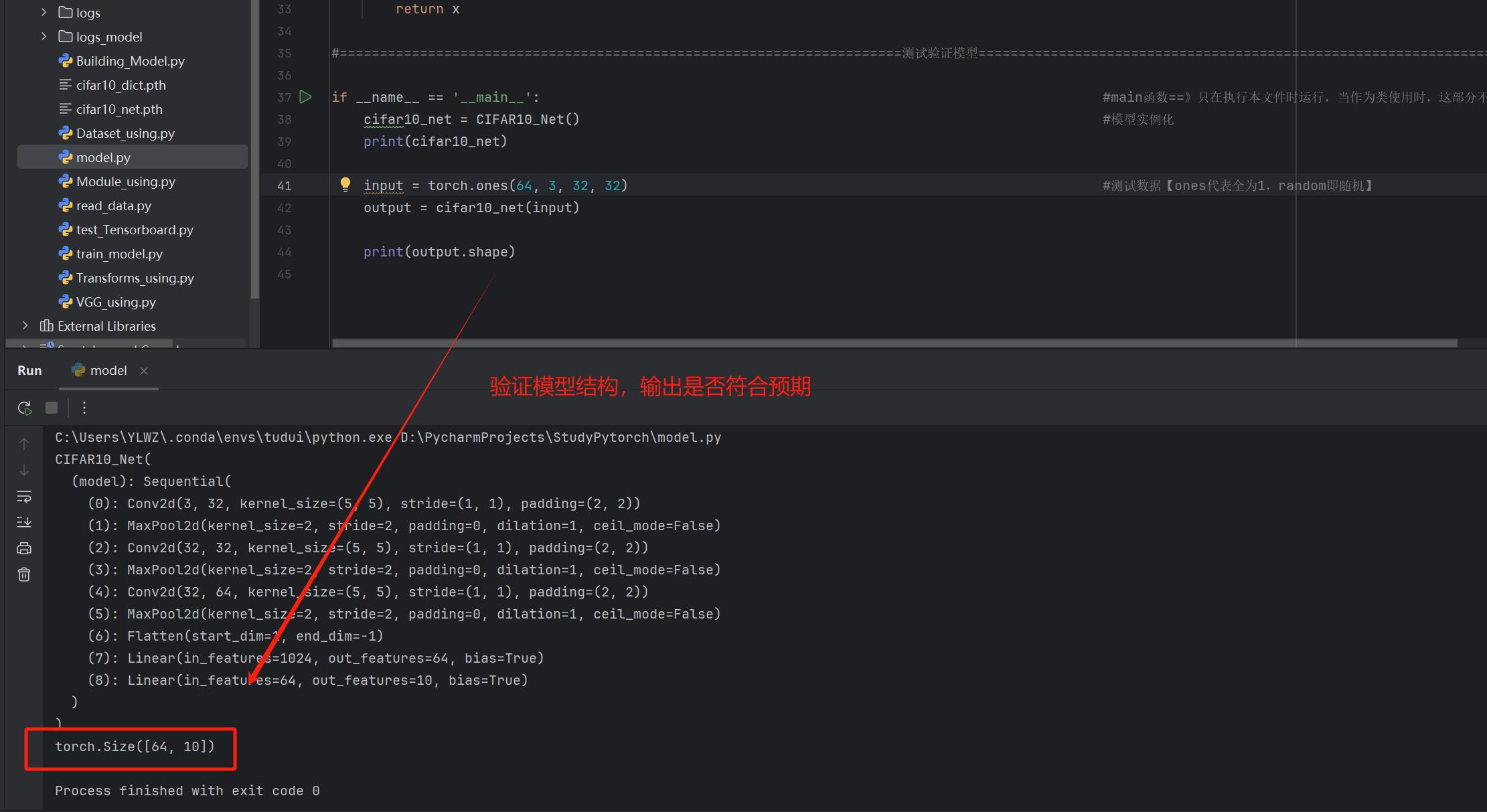
cuda(GPU)加速模型训练
环境配置
检查cuda能否使用
python
print('Pytorch版本:', torch.__version__)
print('显卡是否可用:', '可用' if (torch.cuda.is_available()) else '不可用')以下是有英伟达显卡但是cuda不能使用的情况:
【情况一:Pytorch版本不对(没下载到cuda版本的Pytorch)】
解决:重新安装Pytorch
(1)进入虚拟环境中卸载cpu版本的Pytorch
bash
activate tudui
conda uninstall pytorch(2)去Pytorch官方下载对应cuda版本的Pytorch
查看自己的cuda版本:
win+r输入cmd回车进入命令行,输入:
bash
nvidia-smi
在Pytorch官网中找到对应版本的下载链接Get Started
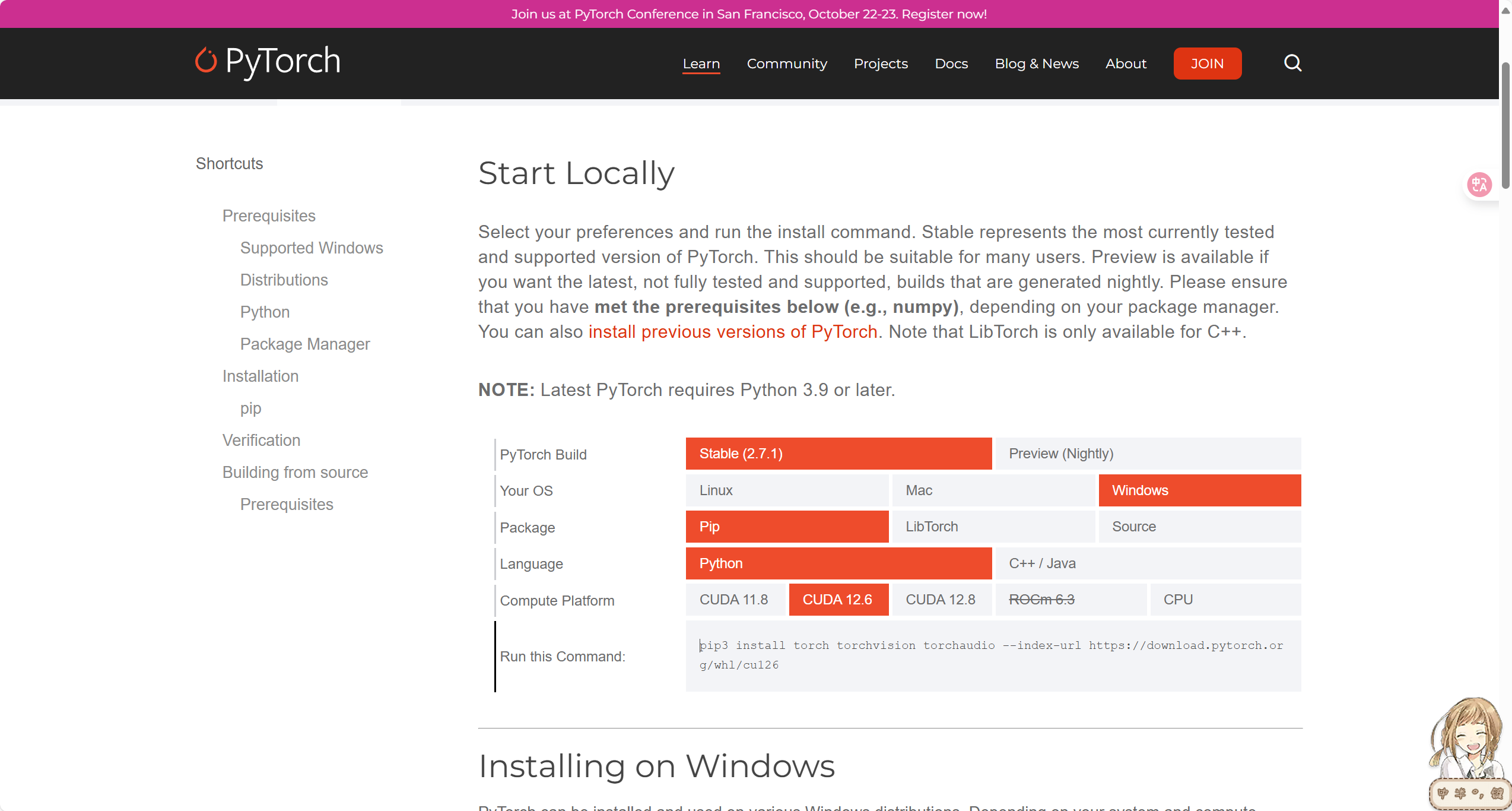
下载
【情况二:Pytorch版本与cuda版本不匹配(某些项目可能会出现版本不匹配的问题)】
在确认自己的cuda版本后,在Pytorch官方找到对应版本的Pytorch下载链接,重复上面的操作
以上成功解决后,我们就可以用cuda把我们训练放到GPU上,加速训练
使用to(device)函数加载
python
#定义训练设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #cuda:0代表第一个GPU(如果你有多个GPU的话),如果没有GPU就用CPU
cifar10_net.to(device) #将模型加载到GPU上训练train函数设计
导入模型以及各种包
python
from typing import OrderedDict
import torch
import torchvision
from torch import nn
from torch.nn import L1Loss, MSELoss, CrossEntropyLoss
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
#引入model
from model import *数据加载
python
#======================================================================数据加载======================================================================
train_dataset = torchvision.datasets.CIFAR10(root='./dataset', #训练集
train=True,
download=True,
transform=transforms.ToTensor())
test_dataset = torchvision.datasets.CIFAR10(root='./dataset', #测试集
train=False,
download=True,
transform=transforms.ToTensor())
#查询数据集长度
train_len = len(train_dataset)
test_len = len(test_dataset)
print('Train dataset length:', train_len)
print('Test dataset length:', test_len)
train_loader = torch.utils.data.DataLoader(train_dataset,64) #数据加载
test_loader = torch.utils.data.DataLoader(test_dataset, 64)实例化模型
python
#======================================================================创建模型实例对象======================================================================
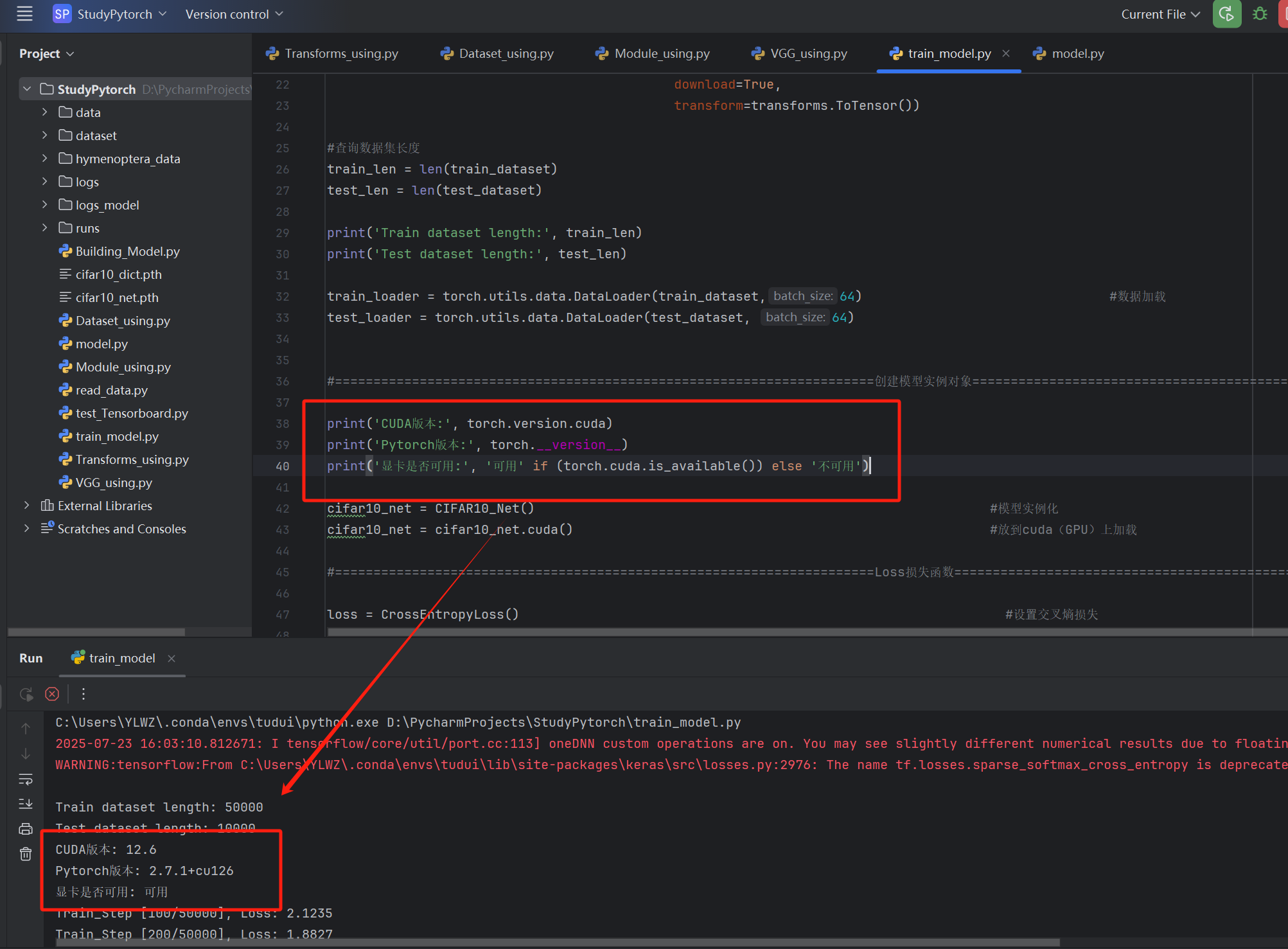
#确认cuda可用
print('CUDA版本:', torch.version.cuda)
print('Pytorch版本:', torch.__version__)
print('显卡是否可用:', '可用' if (torch.cuda.is_available()) else '不可用')
cifar10_net = CIFAR10_Net() #模型实例化
cifar10_net = cifar10_net.cuda() #放到cuda(GPU)上加载实例化损失函数
python
#======================================================================Loss损失函数======================================================================
loss = CrossEntropyLoss() #设置交叉熵损失
loss = loss.cuda() #放到cuda(GPU)上加载实例化优化器
python
#======================================================================优化器optimizer======================================================================
optimizer = torch.optim.SGD(cifar10_net.parameters(), lr=1e-2, momentum=0.9) #优化器设置(SGD是随机梯度下降,1e-2即是1*(10)**2 = 0.01)模型训练以及测试与保存
模型测试中模型效果衡量标准为acc(分类任务中常用指标),即对比模型输出结果和标签查看是否一致,一致则说明我们的预测正确,对比完整个测试集后,acc = 预测正确数/测试总数
得到output后,我们使用argmax(dim = 1)进行分析结果,其中对output来说就相当于一个二维数组(在本案例中),而dim的作用是指定相应的维度,dim = 1即是第二维(第一维是dim = 0),拿其中一个输出i举例:
dim = 1相对应的就是第i个输出outputi\[\]的一行(设第一维为列,第二维为行),argmax的作用就是选出其中最大元素所在的下标(代表最大概率的分类),如果一个output为0.1,0.2,0.4,0.3 ---> argmax返回的就是下标3,此时查看target的标记是多少,如果target为3,即两者相等,预测正确,反之错误
python
#======================================================================训练过程======================================================================
#记录训练的步数
train_step = 0
#记录测试的步数
test_step = 0
#训练轮数
epochs = 10
#加载到Tensorboard中
writer = SummaryWriter("./logs_model_loss")
for epoch in range(epochs):
for i, (images, labels) in enumerate(train_loader): #训练
images = images.to('cuda') #放到cuda(GPU)上加载
labels = labels.to('cuda') #放到cuda(GPU)上加载
optimizer.zero_grad() #梯度清空【清空上一轮计算出的梯度(将model中的grad都设为None)】
outputs = cifar10_net(images) #模型输出结果【预测标签】
result_loss = loss(outputs, labels) #损失函数计算
result_loss.backward() #根据反向传播计算出model中各参数的梯度grad
optimizer.step() #优化器optimizer根据梯度更新model中的各参数 #统计这一轮的总损失
train_step += 1
if train_step % 100 == 0: #每训练一百次打印一次结果
print("Train_Step [{}/{}], Loss: {:.4f}".format(train_step, train_len,result_loss))
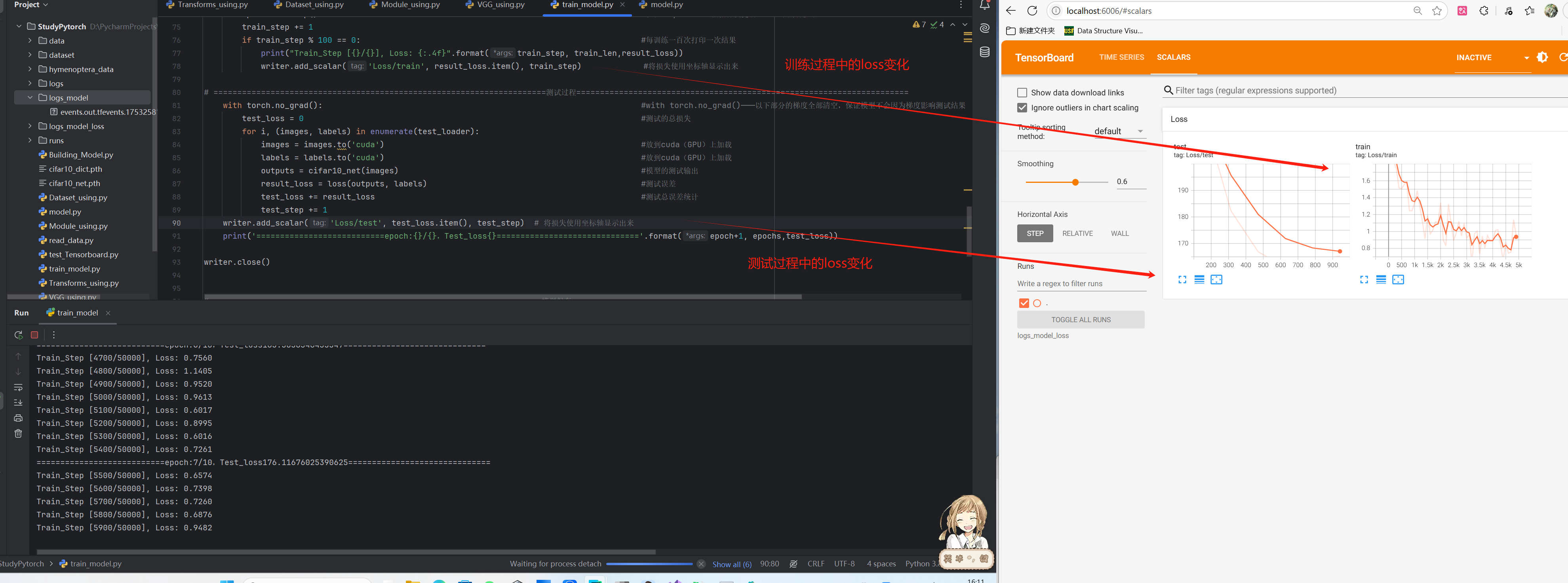
writer.add_scalar('Loss/train', result_loss.item(), train_step) #将损失使用坐标轴显示出来
#======================================================================测试过程======================================================================
#每一轮epoch训练完后都经过测试
with torch.no_grad(): #with torch.no_grad()---------以下部分的梯度全部清空,保证模型不会因为梯度影响测试结果
test_loss = 0 #测试的总损失
test_accuracy = 0 #衡量指标:预测准确度acc
for i, (images, labels) in enumerate(test_loader):
images = images.to('cuda') #放到cuda(GPU)上加载
labels = labels.to('cuda') #放到cuda(GPU)上加载
outputs = cifar10_net(images) #模型的测试输出
result_loss = loss(outputs, labels) #测试误差
test_loss += result_loss #测试总误差统计
test_step += 1
test_accuracy += (outputs.argmax(dim=1) == labels).sum() #统计预测正确的个数
writer.add_scalar('Loss/test', test_loss.item(), test_step) # 将损失使用坐标轴显示出来
writer.add_scalar('Accuracy/test', test_accuracy/test_len, test_step)
print('===========================epoch:{},acc = {},Test_loss = {}=============================='.format(epoch+1, test_accuracy/test_len, epochs,test_loss))
#======================================================================模型保存======================================================================
#每一轮epoch结束,保存一次模型
# 保存方式2(官方推荐,保存下来占用的空间小)
torch.save(cifar10_net.state_dict(), "cifar10_dict_epcoh{}.pth".format(epoch)) # 用字典保存模型相应的参数,不保存模型的网络结构
print("model saved")
writer.close()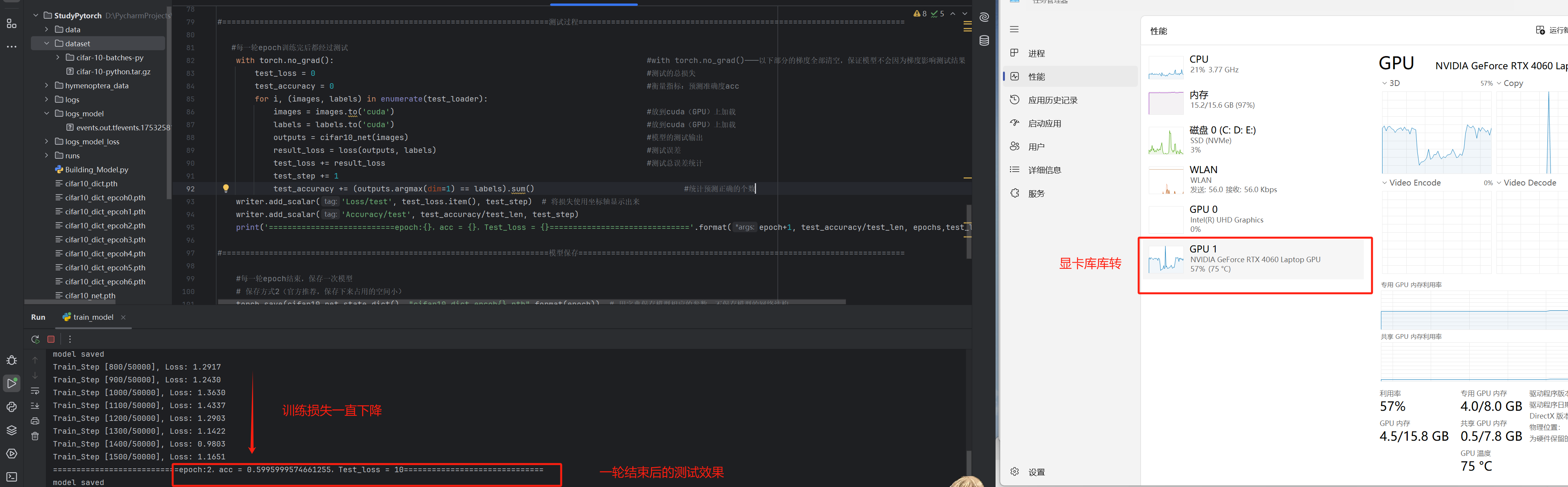
将我们的输出结果放到Tensorboard中
测试test函数设计
数据加载
python
#======================================================================数据加载======================================================================
test_dataset = torchvision.datasets.CIFAR10(root='./dataset', #测试集
train=False,
download=True,
transform=transforms.ToTensor())
#查询数据集长度
test_len = len(test_dataset)
print('Test dataset length:', test_len)
test_loader = torch.utils.data.DataLoader(test_dataset, 64) #数据加载实例化模型并加载预训练参数
python
#======================================================================创建模型实例对象======================================================================
#确认cuda可用
print('CUDA版本:', torch.version.cuda)
print('Pytorch版本:', torch.__version__)
print('显卡是否可用:', '可用' if (torch.cuda.is_available()) else '不可用')
cifar10_net = CIFAR10_Net() #模型实例化
cifar10_net = cifar10_net.cuda() #放到cuda(GPU)上加载
#加载模型
load_dict = torch.load("cifar10_dict_epcoh9.pth") #加载参数字典
cifar10_net.load_state_dict(load_dict) #将参数字典加载到模型结构汇总
print(cifar10_net) #打印网络结构实例化损失函数
python
#======================================================================Loss损失函数======================================================================
loss = CrossEntropyLoss() #设置交叉熵损失测试过程
python
#======================================================================测试过程======================================================================
test_loss = 0 #测试的总损失
test_accuracy = 0 #衡量指标:预测准确度acc
for i, (images, labels) in enumerate(test_loader):
images = images.to('cuda') #放到cuda(GPU)上加载
labels = labels.to('cuda') #放到cuda(GPU)上加载
outputs = cifar10_net(images) #模型的测试输出
result_loss = loss(outputs, labels) #测试误差
test_loss += result_loss #测试总误差统计
test_accuracy += (outputs.argmax(dim=1) == labels).sum() #统计预测正确的个数
print('===========================acc = {},Test_loss = {}=============================='.format(test_accuracy/test_len, test_loss))
补充
下面两个函数其实要不要都不影响训练,但是针对特定层的处理往往要用到
train()函数
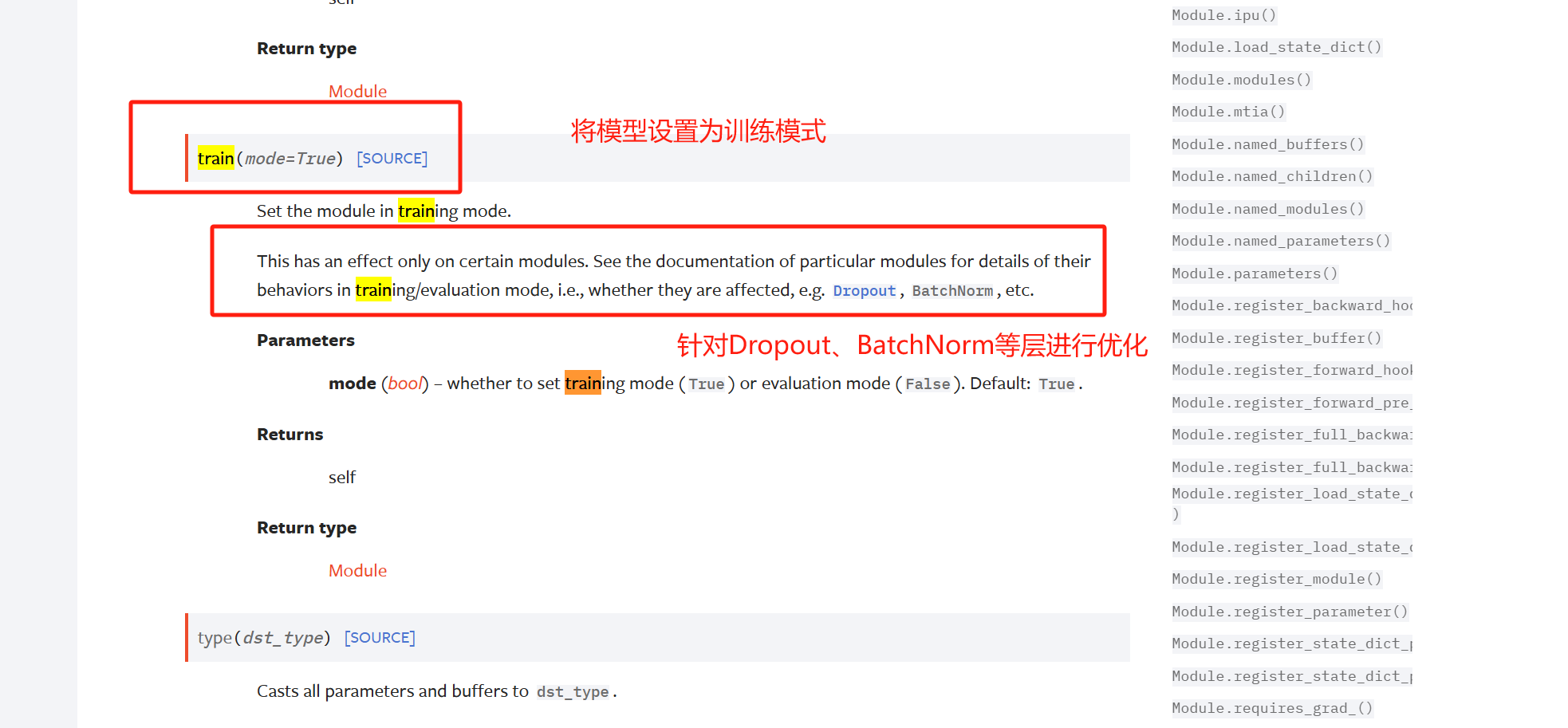
eval()函数
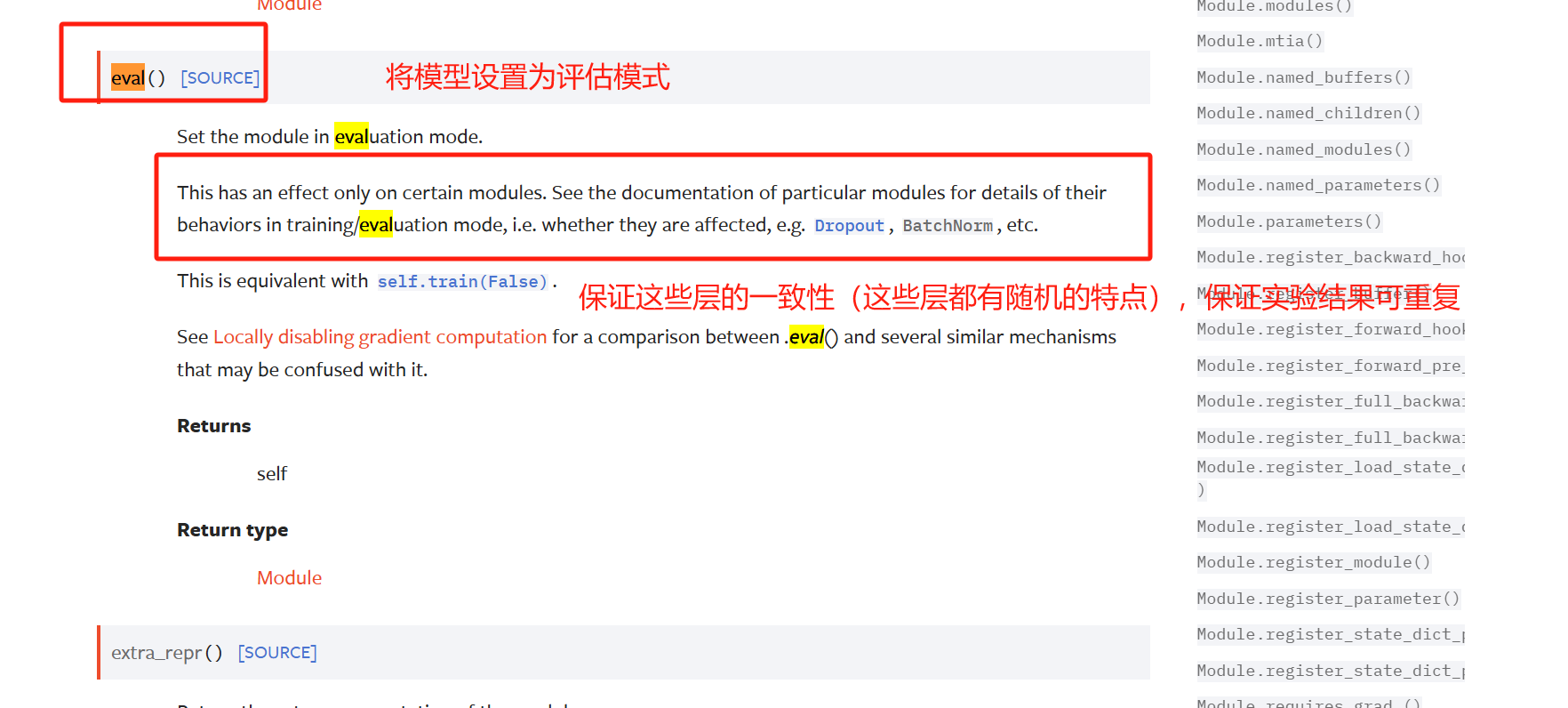
具体影响的层
Dropout 层
- 训练时:随机丢弃部分神经元(如 50%),防止过拟合。
- 评估时:关闭丢弃机制,保留所有神经元进行计算。
Batch Normalization (BN)
- 训练时:使用当前批次数据的均值和方差进行归一化,并更新全局统计量(running_mean/running_var)。
- 评估时:使用训练阶段积累的全局统计量,而非当前批次数据,确保结果稳定。
代码文件
python
import torch
from torch import nn
#======================================================================模型搭建======================================================================
class CIFAR10_Net(nn.Module):
def __init__(self):
super(CIFAR10_Net, self).__init__()
self.model = nn.Sequential( #Sequential将按各个模块按顺序搭建起来
#卷积输入输出计算:32 = (32 + 2 * padding - 1 * (5-1) - 1) + 1得到padding为2【Hin = 32,stride = 1,dilation = 1,kernel_size = 5,Hout = 32】
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), #第一步是5*5的卷积【将(3*32*32)的图片转为(32*32*32)的数据】
nn.MaxPool2d(kernel_size=2, stride=2), #第二步是2*2最大池化【将(32*32*32)的数据转为(32*16*16)的数据】
#卷积输入输出计算:16 = (16 + 2 * padding - 1 * (5-1) - 1) + 1得到padding为2【Hin = 16,stride = 1,dilation = 1,kernel_size = 5,Hout = 16】
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2), #第三步还是5*5的卷积【将(32*16*16)的数据转为(32*16*16)的数据】
nn.MaxPool2d(kernel_size=2, stride=2), #第四步还是2*2最大池化【将(32*16*16)的数据转为(32*8*8)的数据】
# 卷积输入输出计算:8 = (8 + 2 * padding - 1 * (5-1) - 1) + 1得到padding为2【Hin = 8,stride = 1,dilation = 1,kernel_size = 5,Hout = 8】
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2), #第五步还是5*5的卷积【将(32*8*8)的数据转为(64*8*8)的数据】
nn.MaxPool2d(kernel_size=2, stride=2), #第六步还是2*2最大池化【将(64*8*8)的数据转为(64*4*4)的数据】
nn.Flatten(), #第七步展平数据【将(64*4*4)的数据转为64*4*4的数据】
#全连接层
#上面经过model已经得到数据,接下来要将数据转为输出结构
nn.Linear(64*4*4,64), #第八步线性连接进入隐藏层【将64*4*4的数据输入计算出64个隐藏层结果】
nn.Linear(64,10) #第九步线性连接得出预测【将64的数据输入计算出10个预测结果的分数】
)
def forward(self, x):
x = self.model(x)
return x
#======================================================================测试验证模型======================================================================
if __name__ == '__main__': #main函数==》只在执行本文件时运行,当作为类使用时,这部分不会被引入【目的在于测试该文件,有更好的规范性】
cifar10_net = CIFAR10_Net() #模型实例化
print(cifar10_net)
input = torch.ones(64, 3, 32, 32) #测试数据【ones代表全为1,random即随机】
output = cifar10_net(input)
print(output.shape)train_model.py
python
from typing import OrderedDict
import torch
import torchvision
from torch import nn
from torch.nn import L1Loss, MSELoss, CrossEntropyLoss
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
#引入model
from model import *
#======================================================================数据加载======================================================================
train_dataset = torchvision.datasets.CIFAR10(root='./dataset', #训练集
train=True,
download=True,
transform=transforms.ToTensor())
test_dataset = torchvision.datasets.CIFAR10(root='./dataset', #测试集
train=False,
download=True,
transform=transforms.ToTensor())
#查询数据集长度
train_len = len(train_dataset)
test_len = len(test_dataset)
print('Train dataset length:', train_len)
print('Test dataset length:', test_len)
train_loader = torch.utils.data.DataLoader(train_dataset,64) #数据加载
test_loader = torch.utils.data.DataLoader(test_dataset, 64)
#======================================================================创建模型实例对象======================================================================
#确认cuda可用
print('CUDA版本:', torch.version.cuda)
print('Pytorch版本:', torch.__version__)
print('显卡是否可用:', '可用' if (torch.cuda.is_available()) else '不可用')
cifar10_net = CIFAR10_Net() #模型实例化
cifar10_net = cifar10_net.cuda() #放到cuda(GPU)上加载
#======================================================================Loss损失函数======================================================================
loss = CrossEntropyLoss() #设置交叉熵损失
#======================================================================优化器optimizer======================================================================
optimizer = torch.optim.SGD(cifar10_net.parameters(), lr=1e-2, momentum=0.9) #优化器设置(SGD是随机梯度下降,1e-2即是1*(10)**2 = 0.01)
#======================================================================训练过程======================================================================
#记录训练的步数
train_step = 0
#记录测试的步数
test_step = 0
#训练轮数
epochs = 10
#加载到Tensorboard中
writer = SummaryWriter("./logs_model_loss")
for epoch in range(epochs):
for i, (images, labels) in enumerate(train_loader): #训练
images = images.to('cuda') #放到cuda(GPU)上加载
labels = labels.to('cuda') #放到cuda(GPU)上加载
optimizer.zero_grad() #梯度清空【清空上一轮计算出的梯度(将model中的grad都设为None)】
outputs = cifar10_net(images) #模型输出结果【预测标签】
result_loss = loss(outputs, labels) #损失函数计算
result_loss.backward() #根据反向传播计算出model中各参数的梯度grad
optimizer.step() #优化器optimizer根据梯度更新model中的各参数 #统计这一轮的总损失
train_step += 1
if train_step % 100 == 0: #每训练一百次打印一次结果
print("Train_Step [{}/{}], Loss: {:.4f}".format(train_step, train_len,result_loss))
writer.add_scalar('Loss/train', result_loss.item(), train_step) #将损失使用坐标轴显示出来
#======================================================================测试过程======================================================================
#每一轮epoch训练完后都经过测试
with torch.no_grad(): #with torch.no_grad()---------以下部分的梯度全部清空,保证模型不会因为梯度影响测试结果
test_loss = 0 #测试的总损失
test_accuracy = 0 #衡量指标:预测准确度acc
for i, (images, labels) in enumerate(test_loader):
images = images.to('cuda') #放到cuda(GPU)上加载
labels = labels.to('cuda') #放到cuda(GPU)上加载
outputs = cifar10_net(images) #模型的测试输出
result_loss = loss(outputs, labels) #测试误差
test_loss += result_loss #测试总误差统计
test_step += 1
test_accuracy += (outputs.argmax(dim=1) == labels).sum() #统计预测正确的个数
writer.add_scalar('Loss/test', test_loss.item(), test_step) # 将损失使用坐标轴显示出来
writer.add_scalar('Accuracy/test', test_accuracy/test_len, test_step)
print('===========================epoch:{},acc = {},Test_loss = {}=============================='.format(epoch+1, test_accuracy/test_len, epochs,test_loss))
#======================================================================模型保存======================================================================
#每一轮epoch结束,保存一次模型
# 保存方式2(官方推荐,保存下来占用的空间小)
torch.save(cifar10_net.state_dict(), "cifar10_dict_epcoh{}.pth".format(epoch)) #用字典保存模型相应的参数,不保存模型的网络结构
print("model saved")
writer.close()test_model.py
python
from typing import OrderedDict
import torch
import torchvision
from torch import nn
from torch.nn import L1Loss, MSELoss, CrossEntropyLoss
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
#引入model
from model import *
#======================================================================数据加载======================================================================
test_dataset = torchvision.datasets.CIFAR10(root='./dataset', #测试集
train=False,
download=True,
transform=transforms.ToTensor())
#查询数据集长度
test_len = len(test_dataset)
print('Test dataset length:', test_len)
test_loader = torch.utils.data.DataLoader(test_dataset, 64) #数据加载
#======================================================================创建模型实例对象======================================================================
#确认cuda可用
print('CUDA版本:', torch.version.cuda)
print('Pytorch版本:', torch.__version__)
print('显卡是否可用:', '可用' if (torch.cuda.is_available()) else '不可用')
cifar10_net = CIFAR10_Net() #模型实例化
#加载模型
load_dict = torch.load("cifar10_dict_epcoh9.pth") #加载参数字典
cifar10_net.load_state_dict(load_dict) #将参数字典加载到模型结构汇总
print(cifar10_net) #打印网络结构
#定义训练设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #cuda:0代表第一个GPU(如果你有多个GPU的话),如果没有GPU就用CPU
cifar10_net.to(device) #将模型加载到GPU上
#======================================================================Loss损失函数======================================================================
loss = CrossEntropyLoss() #设置交叉熵损失
loss.to(device) #放到cuda(GPU)上加载
#======================================================================测试过程======================================================================
test_loss = 0 #测试的总损失
test_accuracy = 0 #衡量指标:预测准确度acc
for i, (images, labels) in enumerate(test_loader):
images = images.to(device) #放到cuda(GPU)上加载
labels = labels.to(device) #放到cuda(GPU)上加载
outputs = cifar10_net(images) #模型的测试输出
result_loss = loss(outputs, labels) #测试误差
test_loss += result_loss #测试总误差统计
test_accuracy += (outputs.argmax(dim=1) == labels).sum() #统计预测正确的个数
print('===========================acc = {},Test_loss = {}=============================='.format(test_accuracy/test_len, test_loss))