Apriori算法
Apriori算法基于频繁项集性质的先验知识,使用由下至上逐层搜索的迭代方法,即从频繁1项集开始,采用频繁k项集搜索频繁k+1项集,直到不能找到包含更多项的频繁项集为止。
Apriori算法由以下步骤组成,其中的核心步骤是连接步和剪枝步:
-
连接步
-
剪枝步
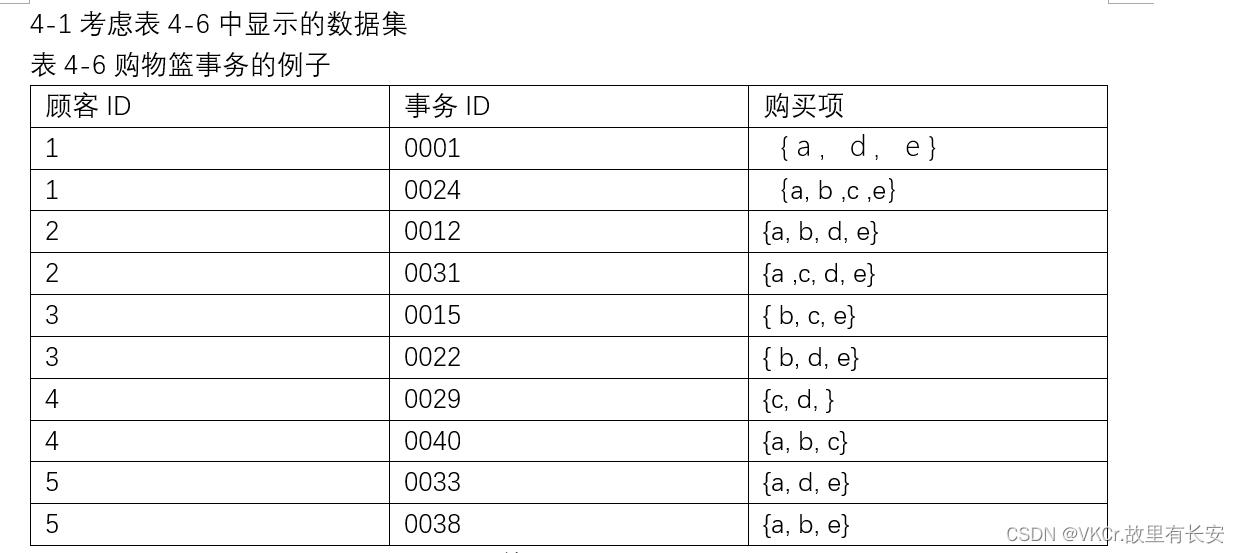
eg1:


eg2:
|-----|-------------|
| TID | ItemSet |
| 1 | 啤酒,尿布,牙膏 |
| 2 | 尿布,牙膏,面包,牛奶 |
| 3 | 啤酒,牙膏,牛奶 |
| 4 | 尿布,牙膏,面包 |
| 5 | 尿布,牙膏,面包,牛奶 |
(1)写出Apriori算法生成频繁项目集的结果(MinSupport=60%)

Apriori算法------不足
①对数据库的扫描次数过多
②Apriori算法会产生大量的中间项集
③采用唯一支持度,没有将各个属性的重要程度的不同都考虑进去
④算法的适应面窄
Apriori算法------改进
①通过减少扫描数据库的次数改进I/O的性能;
②改进产生频繁项集的计算性能;
③寻找有效的并行关联规则算法;
④引入抽样技术改进生成频繁项集的I/O和计算性能;
⑤扩展应用领域。比如展开定量关联规则、泛化关联规则及周期性的关联规则的研究。
FP-Growth算法
频繁模式树增长算法(Frequent Pattern Tree Growth)采用分而治之的基本思想,将数据库中的频繁项集压缩到一棵频繁模式树中,同时保持项集之间的关联关系。然后将这棵压缩后的频繁模式树分成一些条件子树,每个条件子树对应一个频繁项,从而获得频繁项集,最后进行关联规则挖掘。
FpGrowth算法的平均效率远高于Apriori算法,但它并不能保证高效率,它的效率依赖于数据集。Fptree还需要其他的开销,需要存储空间更大,使用FpGrowth算法前,首先需要对数据分析,在决策是否采用FpGrowth算法。