- 深度优先爬虫:深度优先爬虫是一种以深度为优先的爬虫算法。它从一个起始点开始,先访问一个链接,然后再访问该链接下的链接,一直深入地访问直到无法再继续深入为止。然后回溯到上一个链接,再继续深入访问下一个未被访问的链接。这种算法的优点是可以快速深入到网站的深层页面,但可能会陷入无限循环或者遗漏一些链接。
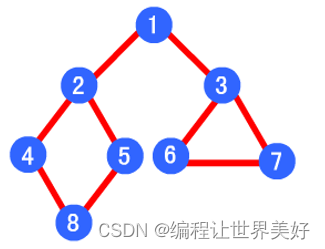
- 广度优先爬虫:广度优先爬虫是一种以广度为优先的爬虫算法。它从一个起始点开始,首先访问该链接下的所有链接,然后再逐个访问这些链接下的链接。这种算法的优点是可以较好地保证网站的全面爬取,并避免陷入无限循环。但缺点是可能会花费较长的时间,因为需要逐层遍历所有链接。
这两种爬虫算法适用于不同的应用场景,深度优先爬虫适用于需要尽快深入到网站的深层页面进行数据抓取的场景,而广度优先爬虫适用于需要全面爬取整个网站的场景。
对应地,我们可以联系数据结构的树来进行理解。
树是一种数据结构,它是由节点和边组成的集合。树的节点之间有一对一的关系,其中一个节点是根节点,其他节点可以分为多个子节点,每个子节点可以再分为更多的子节点,以此类推。树的模型在计算机科学中被广泛应用,包括文件系统、数据库索引、图形界面等。
树的根节点是最顶层的节点,没有父节点。每个节点可以有零个或多个子节点。节点之间的边表示节点之间的关系,其中每个边连接一个父节点和一个子节点。
树的一些常见的特殊情况包括二叉树、二叉搜索树、平衡二叉树等。二叉树是一种特殊的树,其中每个节点最多有两个子节点。二叉搜索树是一种有序的二叉树,其中对于每个节点,其左子树的所有节点的值都小于它的值,右子树的所有节点的值都大于它的值。平衡二叉树是一种特殊的二叉搜索树,其中任意节点的左子树和右子树的高度差不大于1。
树的模型可以用来表示层次化的数据,如组织结构、目录结构等。在编程中,可以使用树来实现递归算法、搜索算法、排序算法等。树的模型也可以用图形方式表示,通过节点和边的可视化,更直观地展示树结构。
from bs4 import BeautifulSoup
import requests
import re
#自定义队列类
class linkQuence:
def __init__(self):
# 已访问的url集合
self.visted = []
# 待访问的url集合
self.unVisited = []
# 获取访问过的url队列
def getVisitedUrl(self):
return self.visted
# 获取未访问的url队列
def getUnvisitedUrl(self):
return self.unVisited
# 添加到访问过得url队列中
def addVisitedUrl(self, url):
self.visted.append(url)
# 移除访问过得url
def removeVisitedUrl(self, url):
self.visted.remove(url)
# 未访问过得url出队列
def unVisitedUrlDeQuence(self):
try:
return self.unVisited.pop()
except:
return None
# 保证每个url只被访问一次
def addUnvisitedUrl(self, url):
if url != "" and url not in self.visted and url not in self.unVisited:
self.unVisited.insert(0, url)
# 获得已访问的url数目
def getVisitedUrlCount(self):
return len(self.visted)
# 获得未访问的url数目
def getUnvistedUrlCount(self):
return len(self.unVisited)
# 判断未访问的url队列是否为空
def unVisitedUrlsEnmpy(self):
return len(self.unVisited) == 0
class MyCrawler:
def __init__(self, seeds):
# 初始化当前抓取的深度
self.current_deepth = 1
# 使用种子初始化url队列
self.linkQuence = linkQuence()
if isinstance(seeds, str):
self.linkQuence.addUnvisitedUrl(seeds)
if isinstance(seeds, list):
for i in seeds:
self.linkQuence.addUnvisitedUrl(i)
print("Add the seeds url %s to the unvisited url list" % str(self.linkQuence.unVisited))
# 抓取过程主函数
def crawling(self, seeds, crawl_deepth):
# ********** Begin **********#
# 循环条件:抓取深度不超过crawl_deepth
while self.current_deepth <= crawl_deepth:
# 循环条件:待抓取的链接不空
while not self.linkQuence.unVisitedUrlsEnmpy():
# 队头url出队列
visitUrl = self.linkQuence.unVisitedUrlDeQuence()
print("Pop out one url \"%s\" from unvisited url list" % visitUrl)
if visitUrl is None or visitUrl == "":
continue
# 获取超链接
links = self.getHyperLinks(visitUrl)
print("Get %d new links" % len(links))
# 将url放入已访问的url中
self.linkQuence.addVisitedUrl(visitUrl)
print("Visited url count: " + str(self.linkQuence.getVisitedUrlCount()))
print("Visited deepth: " + str(self.current_deepth))
# 未访问的url入列
for link in links:
self.linkQuence.addUnvisitedUrl(link)
print("%d unvisited links:" % len(self.linkQuence.getUnvisitedUrl()))
self.current_deepth += 1
# ********** End **********#
# 获取源码中得超链接
def getHyperLinks(self, url):
# ********** Begin **********#
links = []
data = self.getPageSource(url)
soup = BeautifulSoup(data,'html.parser')
a = soup.findAll("a", {"href": re.compile('^http|^/')})
for i in a:
if i["href"].find("http://") != -1:
links.append(i["href"])
return links
# ********** End **********#
# 获取网页源码
def getPageSource(self, url):
# ********** Begin **********#
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ''
# ********** End **********#
def main(seeds, crawl_deepth):
craw = MyCrawler(seeds)
craw.crawling(seeds, crawl_deepth)
if __name__ == '__main__':
main("http://www.baidu.com", 3)