目录
[1.1 最小栈](#1.1 最小栈)
[1.2 栈的弹出和压入序列](#1.2 栈的弹出和压入序列)
[1.3 二叉树的层序遍历](#1.3 二叉树的层序遍历)
[2.1 适配器](#2.1 适配器)
[2.2 deque](#2.2 deque)
[2.2.1 deque的成员变量](#2.2.1 deque的成员变量)
[2.2.2 deque的迭代器](#2.2.2 deque的迭代器)
[2.2.3 deque尾插元素](#2.2.3 deque尾插元素)
[2.2.4 deque头插元素](#2.2.4 deque头插元素)
[2.2.5 下标访问](#2.2.5 下标访问)
[2.2.6 deque的不足](#2.2.6 deque的不足)
1、stack和queue的使用
stack的使用和queue的使用与前面的vector和list类似,并且可以通过看文档来了解,这里主要通过几道题来加深对这两个容器的理解
1.1 最小栈

这道题可以定义两个栈,一个用来存放放入的元素,一个用来储存最小值
注意:最小栈是相对当前位置而言的
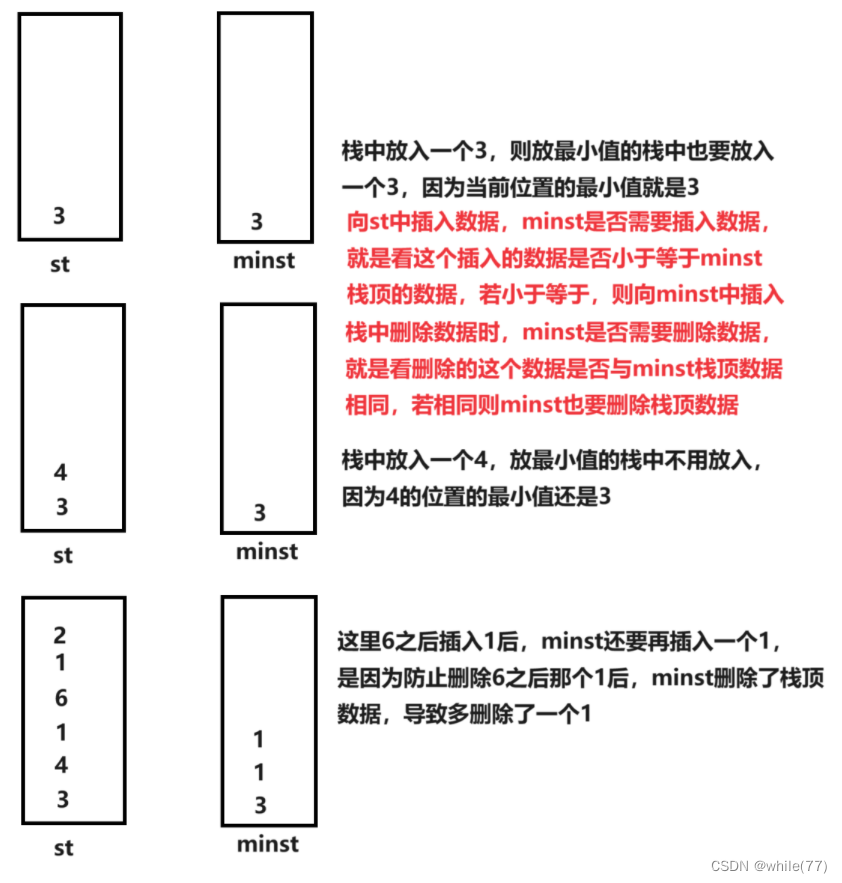
不能用一个min来记录最小值,因为删除元素后min无法更新,且这道题的最小值是相对当前位置
class MinStack {
public:
MinStack() {
//不需要初始化,因为成员变量是自定义类型,会去调用自己的构造函数
}
void push(int val) {
st.push(val);
if(minst.empty() || minst.top() >= val)
minst.push(val);
}
void pop() {
int x = st.top();
st.pop();
if(x == minst.top())
minst.pop();
}
int top() {
return st.top();
}
int getMin() {
return minst.top();
}
stack<int> st;
stack<int> minst;
};1.2 栈的弹出和压入序列
这道题是思路是,创建一个栈,首先将pushV中的第一个数据放入栈中,用popi来记录popV的下标,初始时popi=0,比较栈顶的数据和popVpopi是否相同,若相同,则弹出栈顶数据,并且popi++,然后继续比较现在栈顶的数据是否与popVpopi是否相同,直到不相同再出循环或者栈中已经没有元素了再出循环:若不相同,则继续将pushV中的数据往栈中插入。若已经把pushV中的数据全部放入栈中了,并且循环判断后栈为空,说明是可以的,否则就是不可以的
bool IsPopOrder(vector<int>& pushV, vector<int>& popV) {
size_t popi = 0;
stack<int> st;
for(auto e : pushV)
{
st.push(e);
// 栈顶数据与出栈序列比较
while(!st.empty() && st.top() == popV[popi])
{
popi++;
st.pop();
}
}
return st.empty();
}1.3 二叉树的层序遍历

与之前的层序遍历类似,都是利用队列,父亲结点出队列时就把左右孩子结点带入队列中。这道题的难处是要将每一层的结点放进一个数组中,然后所有层的结点组成一个二维数组,所以要如何区分队列中的结点是那一层的呢?
此时可以借助一个levelSize,levelSize表示每一层数据的个数,入队列还是父亲结点带入左右孩子结点,出队列时,需要用levelSize控制一层一层出,当levelSize==0时,说明当前层出完了,并且此时队列中的就都是下一层的结点,所以levelSize=q.size()
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int>> vv;
if(root == nullptr) return vv;
queue<TreeNode*> q;
q.push(root);
int levelSize = 1;// 记录每层的数据个数
int i = 0;
while(!q.empty())
{
vector<int> v;
while(levelSize)
{
TreeNode* node = q.front();
q.pop();
levelSize--;
v.push_back(node->val);
if(node->left) q.push(node->left);
if(node->right) q.push(node->right);
}
vv.push_back(v);
levelSize = q.size();
}
return vv;
}
};2、stack和queue的模拟实现
vector和list称为容器,而stack和queue称为容器适配器
2.1 适配器
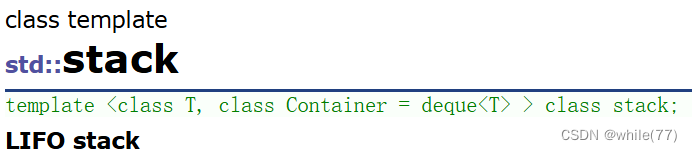
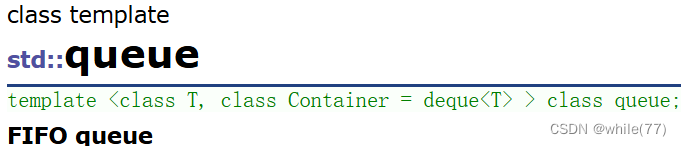


通过观察stack和queue、vector和list会发现,前两者的第二个模板参数和后两者的第二个模板参数不同。前两者的是适配器,后两者的是空间配置器。空间配置器是用来让容器开启空间的,而适配器是这个容器底层是通过什么实现的
适配器 -- 转换 -- 对其他容器封装一下
所以,stack的模拟实现底层可以使用vector或者list
namespace cxf
{
template<class T,class Container = std::vector<T>>
class stack
{
public:
void push(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_back();
}
T& top()
{
return _con.back();
}
const T& top() const
{
return _con.back();
}
size_t size() const
{
return _con.size();
}
bool empty() const
{
return _con.empty();
}
private:
Container _con;
};
}模板参数和函数参数的区别是,模板参数用的是尖括号,函数参数用的是圆括号,模板参数传的是类型,函数参数传的是对象,所以模板参数也是可以给缺省值的
在上面这一个栈的模板中,底层默认是用vector实现的,也可以在创建的时候传入一个其他的容器来让底层变成其他容器,如list
template<class T,class Container = std::list<T>>
class queue
{
public:
void push(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_front();
}
T& top()
{
return _con.front();
}
const T& top() const
{
return _con.front();
}
size_t size() const
{
return _con.size();
}
bool empty() const
{
return _con.empty();
}
private:
Container _con;
};适配器模式是一种设计模式,前面的vector、list是迭代器模式,同样也是一种设计模式
适配器通过一直接口来实现另一种接口,增强了代码的可维护性。当适配器不同时,实际上底层结构已经天差地别,但是使用起来完全是一样的,也具有很强的封装性
适配器选用vector和list各有优势和劣势
vector的优势是下标访问效率低
vector的劣势是扩容、头部插入删除效率低
list的优势是按需申请释放空间任意位置插入删除效率高
list的劣势是下标访问效率低
所以STL中的stack和queue的默认适配器是deque,是vector和list的结合体
2.2 deque

deque叫做双端队列,是一个容器,类似于vector和list的结合体,既可下标访问,又可头插头删
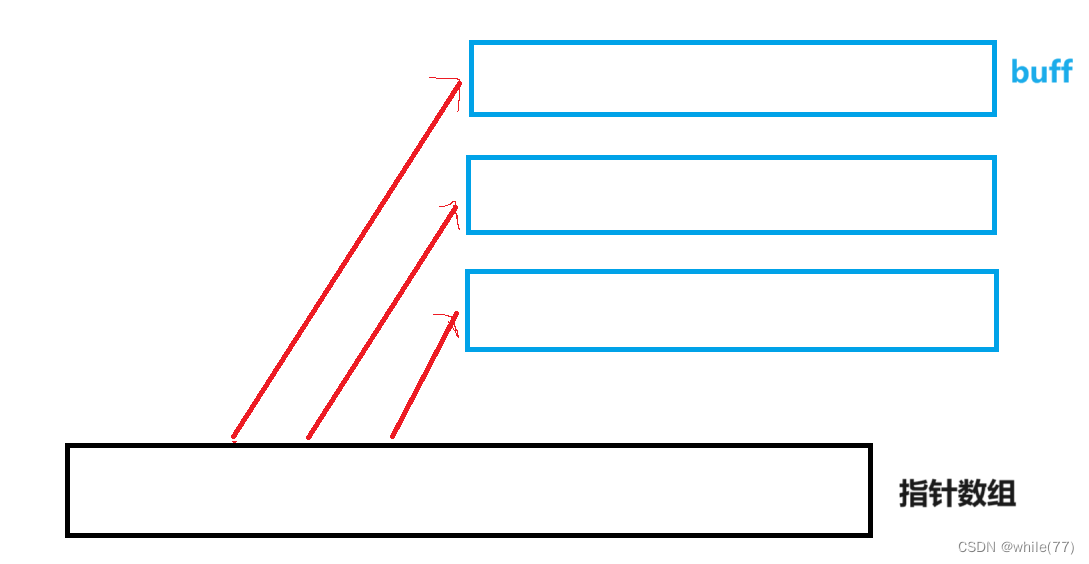
deque底层是通过一个中控数组,也就是一个指针数组来控制一个一个的buff数组
接下来,通过部分的STL源码来大概了解一下deque的底层结构
2.2.1 deque的成员变量

deque的成员函数主要就是由两个迭代器以及一个中控数组组成的
start指向的是deque中第一个buff
finish指向的是deque中最后一个buff
2.2.2 deque的迭代器

deque的迭代器是由4个成员变量组成的
node是指向这个迭代器指向的那个buff,因为buff是数组,node指向数组,所以是二级指针
first是指向这个迭代器的node指向的那个buff数组的第一个位置
last是指向这个迭代器的node指向的那个buff数组的最后一个位置的下一个位置
cur指向当前位置,在deque的成员变量start中就是第一个元素,在deque的成员变量finish中就是最后一个元素
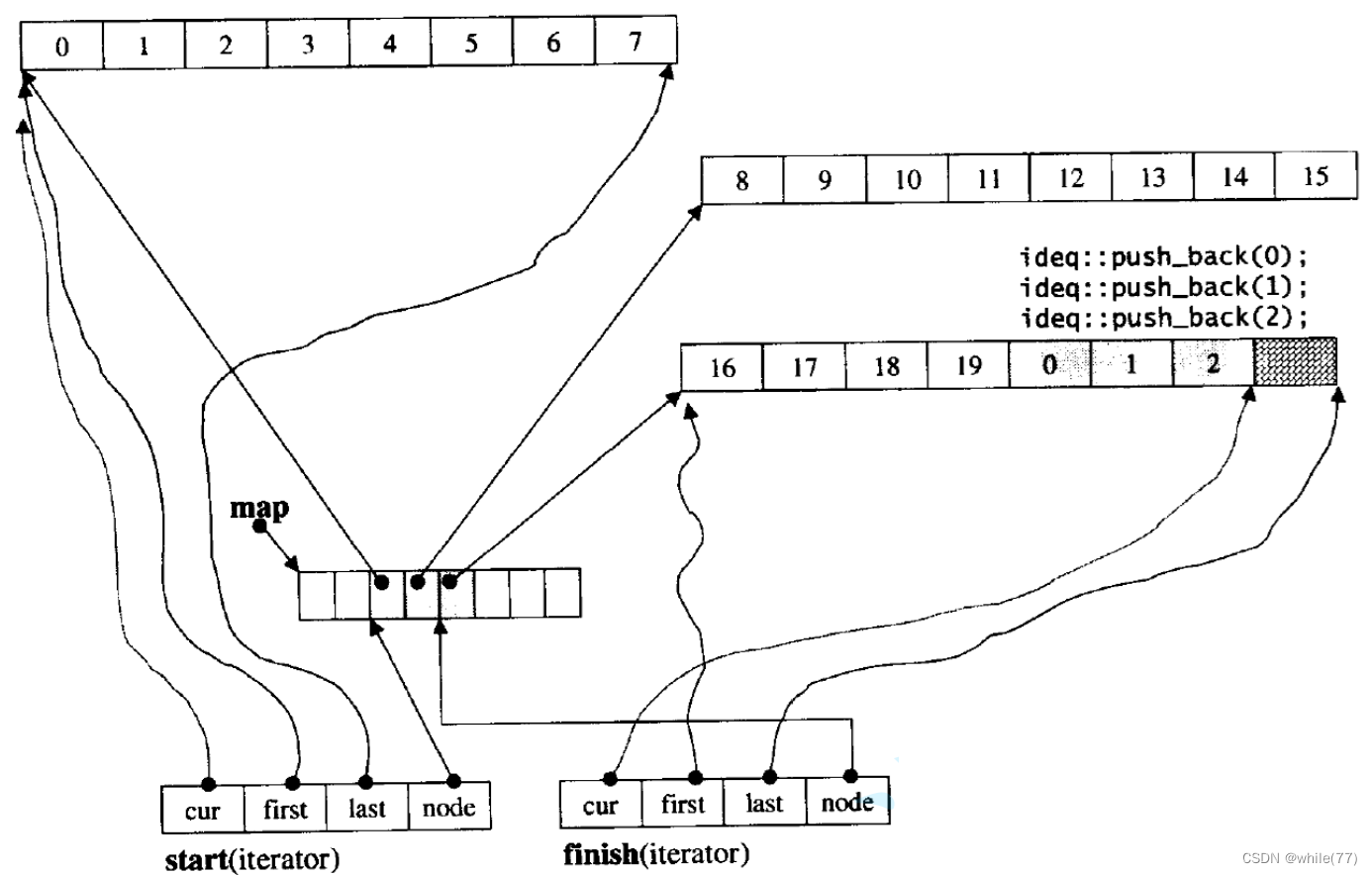
这里面的map是T**

begin返回的是start,end返回的是finish

迭代器++是让迭代器中的cur向后走,如果cur == last,说明当前buff走完了,则让node向后移动一位

it != end 迭代器的比较是用cur来比较的
2.2.3 deque尾插元素
若最后一个buff数组没满,则在其后面插入数据,并让finish的cur向后移动
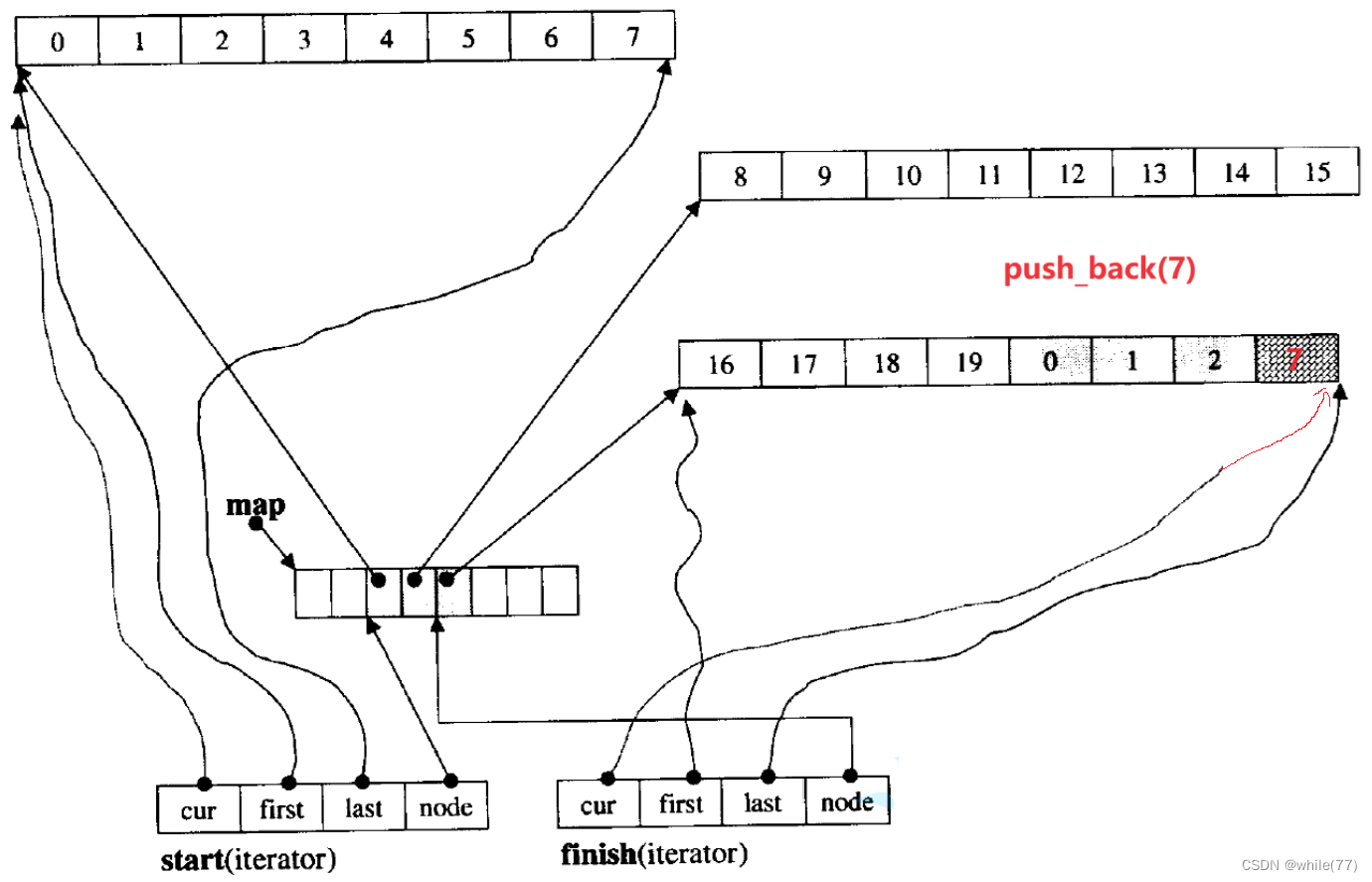
若最后一个buff数组满了,则再开一个buff数组,并且finish后移
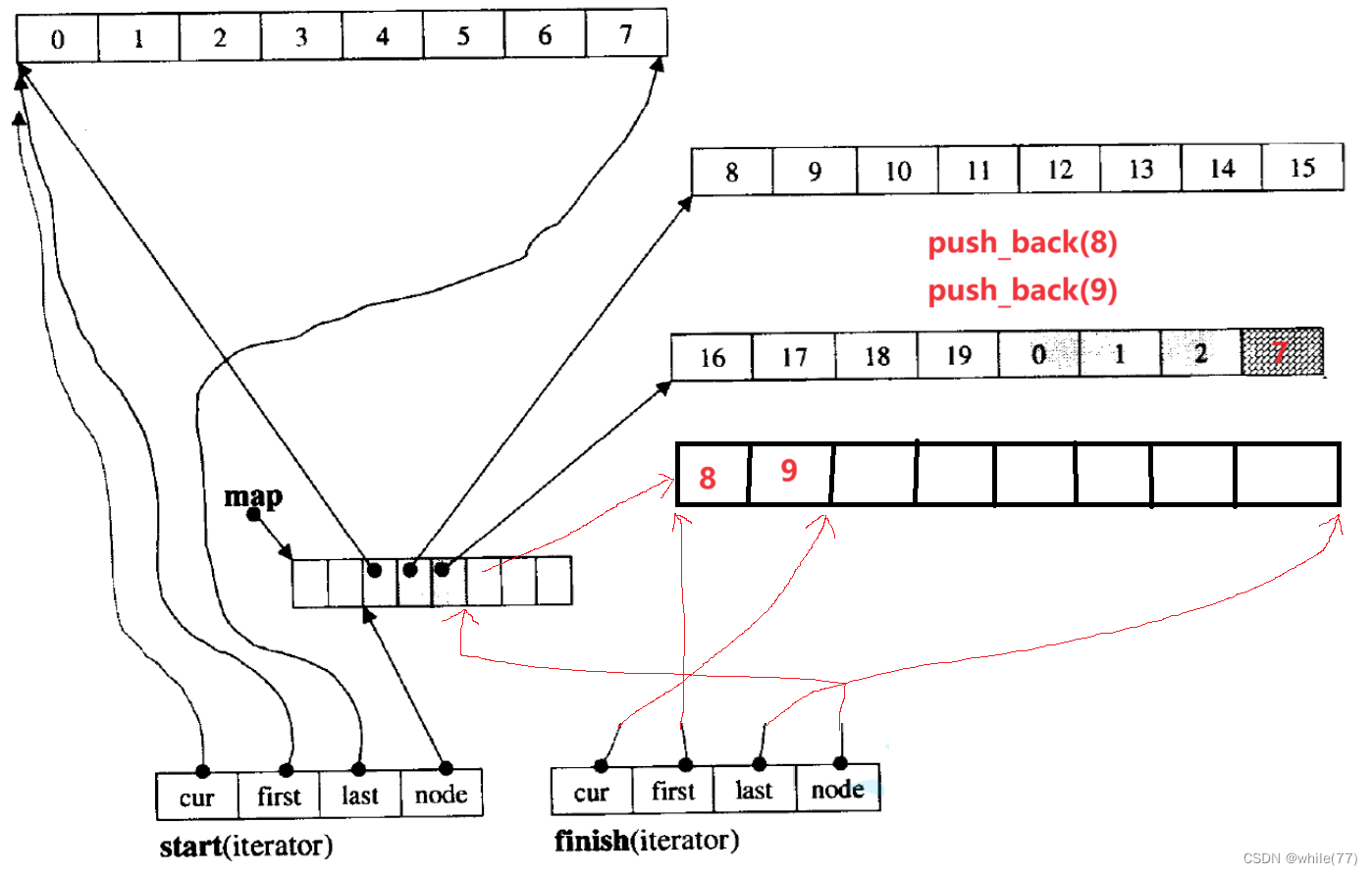
2.2.4 deque头插元素
若第一个buff数组是满的,则头插元素会在第一个buff前面再开一个buff数组,并且start前移一位,并且这个buff数组是从后向前添加元素的
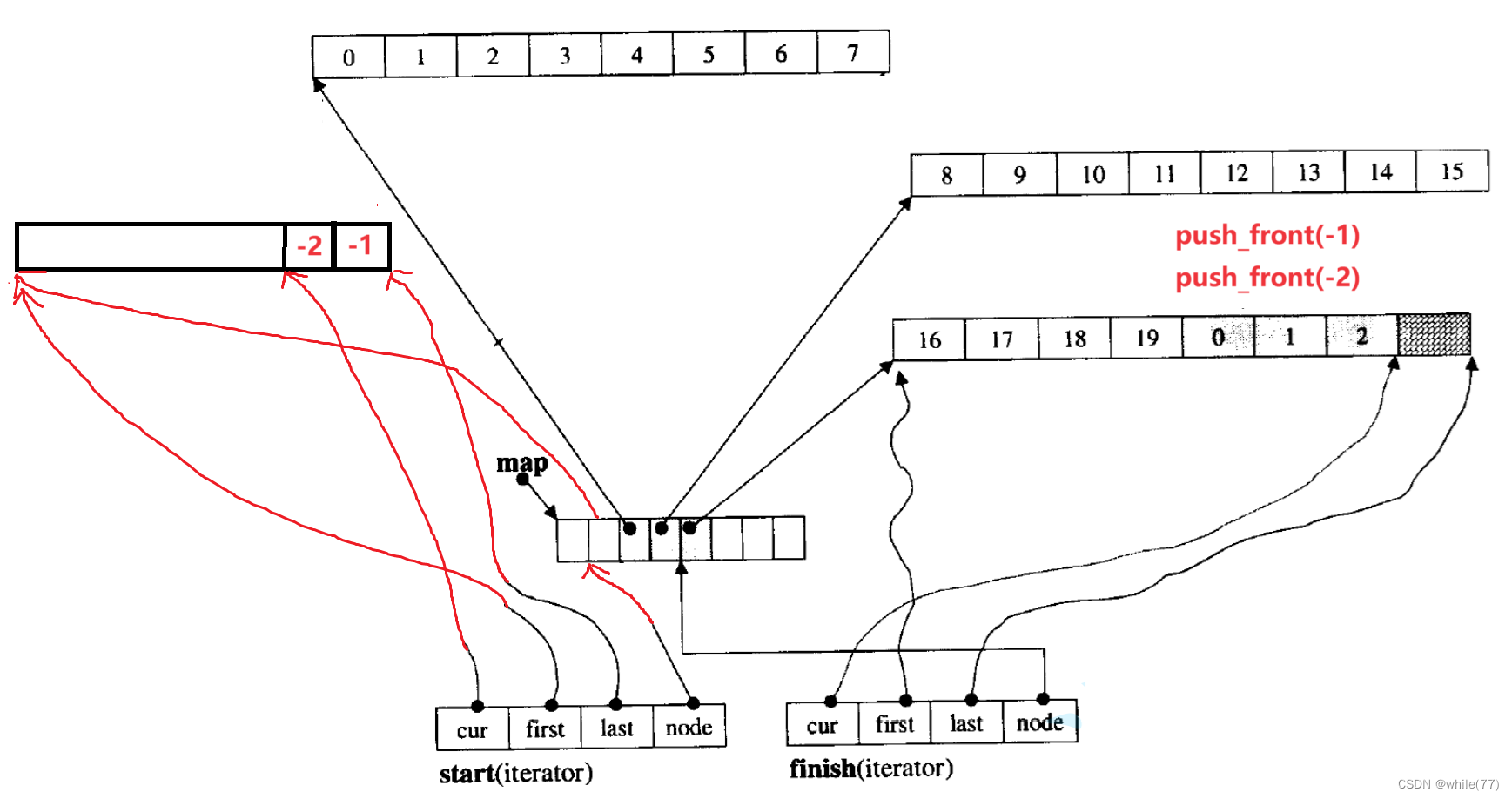
2.2.5 下标访问
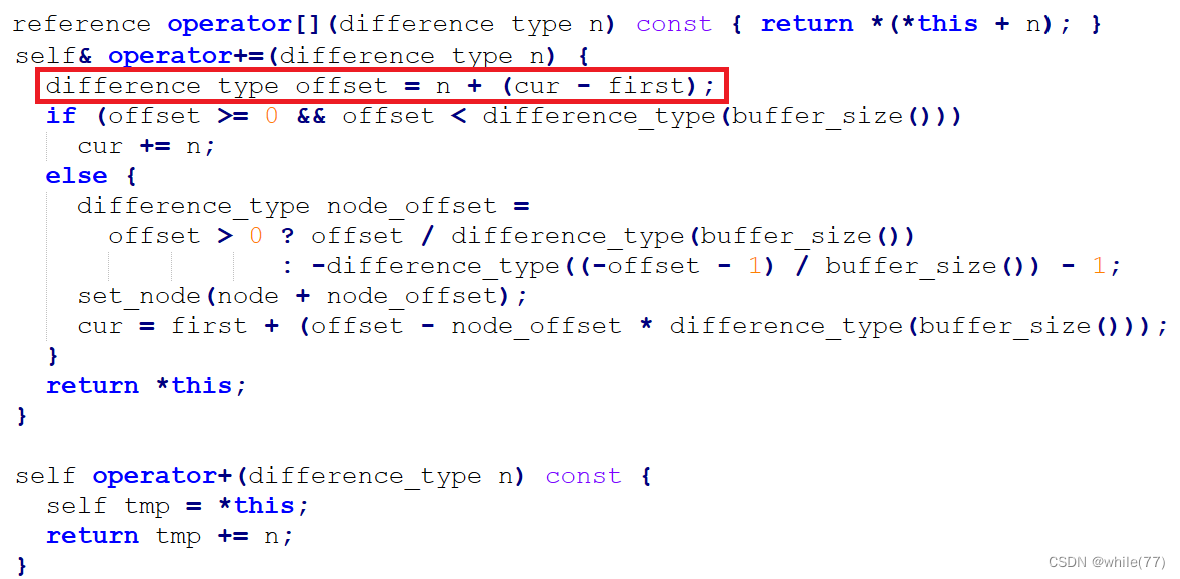
以头插元素中的图为例,假设要访问下标为4的元素,易知一个buff数组能存放8个元素,第一个buff数组中有效元素个数是2,所以用8-2=6,再用6+4=10,实际需要从第一个buff数组的第一个元素开始算,直到下标为10的元素,即2
2.2.6 deque的不足
1、deque的下标访问效率不如vector
2、deque在中间插入效率不如list