1.谷歌borg云计算管理平台
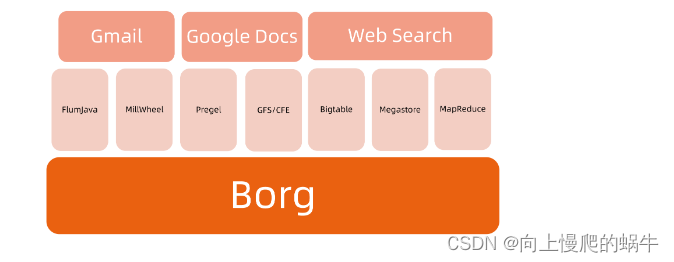
一类:infrastucture platform software
另一类:borg为主的非虚拟化技术,调度进程
核心是轻量级作业调度,不是做虚拟化/云平台的
borg本身用了一些容器技术
生产业务product workload要求高可用,可能资源开销不大,波峰波谷
离线业务none-product批处理,资源要求高,可用性要求低
混合部署
特性
·物理资源利用率高。
·服务器共享,在进程级别做隔离。
·应用高可用,自愈能力强,故障恢复时间短。
·调度策略灵活。
·应用接入和使用方便,提供了完备的Job描述语言,服务发现,实时状态监控和诊断工具。
优势
·对外隐藏底层资源管理和调度、故障处理等。
·实现应用的高可靠和高可用。
·足够弹性,支持应用跑在成千上万的机器上。
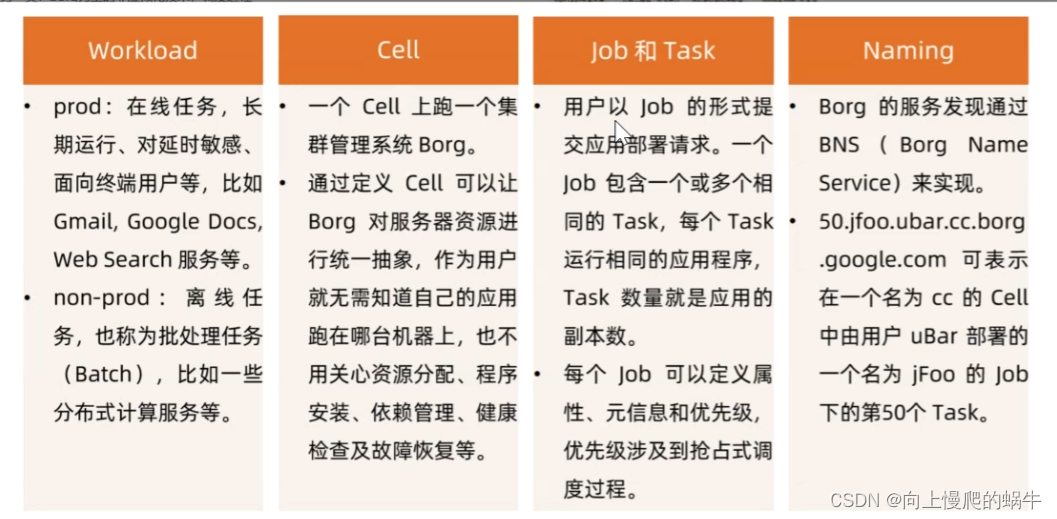
集群管理,作业调度+服务发现
"Workload"(工作负载)
cell,故障域切分
job是一个tasks的组合,job是作业/调度单元,task是进程,
naming域名服务
2.borg架构
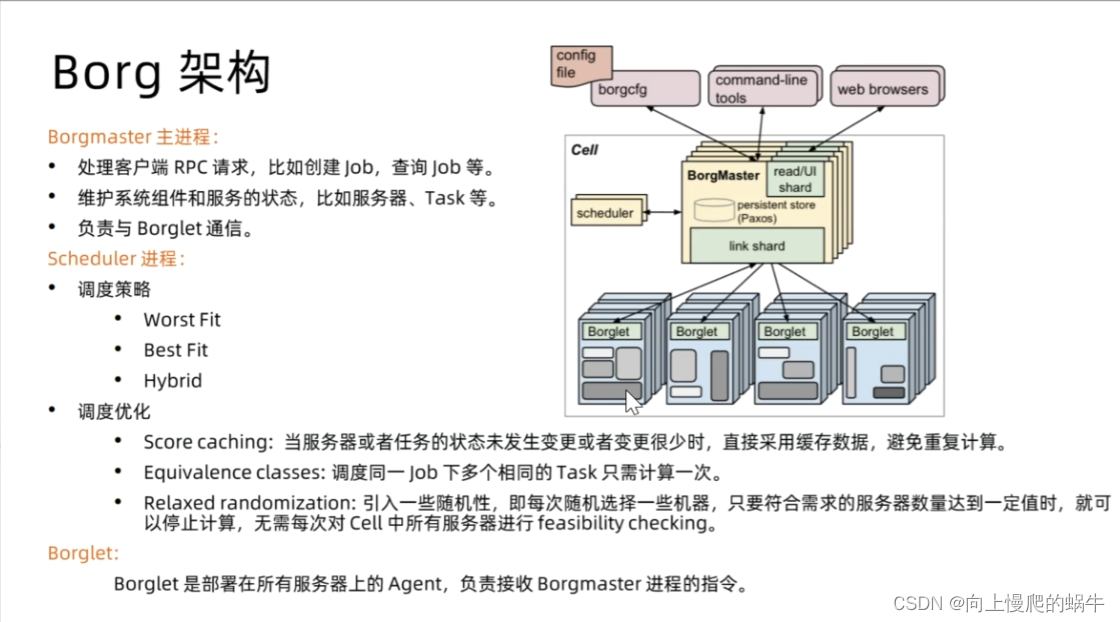
图解:
首先,每个Borg的cell由一系列机器组成,这些机器共同协作以完成集群管理的任务。在每个cell中,运行着一个逻辑的中央控制器,称为Borgmaster。Borgmaster是集群管理的核心,负责处理各种客户端的RPC请求,这些请求可能包括状态变更(如创建任务)或对数据的只读访问(如查询任务状态)。此外,Borgmaster还管理系统中各个对象(如机器、任务、资源分配等)的状态机,并与Borglets(代理进程)进行交互。
在cell中的每台机器上,运行着一个叫Borglet的代理进程。Borglet负责执行从Borgmaster接收到的指令,监控和管理本地机器的状态和资源使用情况,并向Borgmaster报告相关信息。
Borg架构的设计使得它能够在尽量不影响软件运作效率的情况下,最大限度地帮助公司节省成本。通过智能地管理和调度集群资源,Borg能够优化资源利用率,减少资源浪费,从而降低公司的运营成本。
上面是master节点,下面是node节点,一堆master和一堆node节点组合成一个集群,这样集群的概念就是cell。然后再master节点中,如果用户想发起一个调用,通过web ui,命令行或者其他,发送请求,会进行一个统一模板化处理,各个节点会从link shard中监听你的变化,来确定是否是哪个节点要启服务,这样的话用户就只需要发出类似于文件的声明,不管其中的调度流程,就自由的从其中最合适的节点部署起来。
调度策略:
worth fit:集群里面资源利用率最低的优先调度(空余,平均的节点)
best fit:集群里面资源恰好满足需求的节点,没有就选资源空闲最少的
Hybrid:混合模式
borglet:是部署在所有服务器上的 Agent,在某个节点执行服务的部署和任务,进行健康监测
调度优化:
使用缓存调度减少计算次数 短时间pode进行创建使用同一节点创建;一部分减少CPU损耗
用一个job下的多个task只用调度一次随便选几个机器看看他们能不能满足,减少算法复杂度
Relaxedrandomization:引入一些随机性(1000台机器先随机100台;分组,按组去计算是否有符号条件的节点),即每次随机选择一些机器,只要符合需求的服务器数量达到一定值时,就可以停止计算,无需每次对Cell中所有服务器进行feasibilitychecking。
3.应用高可用

优先级在线任务(prod)高于离线任务non-prod,进行跨域部署(能不再同一节点,就不再同一节点/shell,这样是为了保证一点节点出故障导致其他节点出故障)
发生资源抢占的时候,在线业务会抢占离线业务,离线业务放入消息队列等待重新执行
跨故障域
同一个命令敲很多次要保持幂等(如i=i+2这种同意指令多次传入不会产生自增)
4.brog本身高可用
Borgmaster组件多副本设计。
采用一些简单的和底层(low-level)的工具来部署Borg系统实例,避免引入过多的外部依赖。
每个Cell的Borg均独立部署,避免不同Borg系统相互影响。
5.资源利用率
·通过将在线任务(prod)和离线任务(non-prod,Batch)混合部署,空闲时,离线任务可以充分利用计算资源;繁忙时,在线任务通过抢占的方式保证优先得到执行,合理地利用资源。
·98%的服务器实现了混部。
·90%的服务器中跑了超过25个Task和4500个线程。
·在一个中等规模的Cell里,在线任务和离线任务独立部署比混合部署所需的服务器数量多出约20%-30%。可以简单算一笔账,Google的服务器数量在千万级别,按20%算也是百万级别,大概能省下的服务器采购费用就是百亿级别了,这还不包括省下的机房等基础设施和电费等费用。
6.brog调度原理
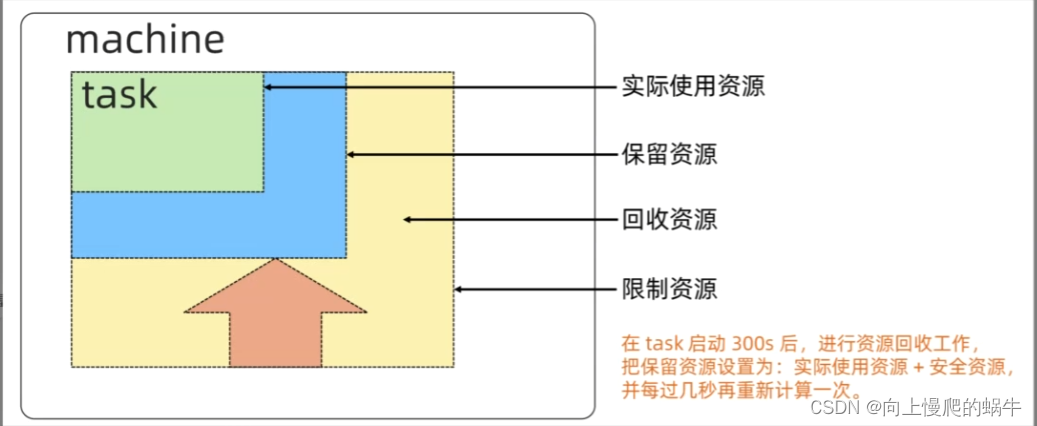
brog会检测资源利用率,如果说task稳定实际占用很小的话,brog会保留就task实际使用乘一个系数的资源值,剩下的则回收
允许多申报资源,在运行一段时间进行资源检测平均值(cpu 内存),进行资源回收
我们未我们的的代码申请的资源大多数情况下是比运行后平均占用的资源要多出一部分的,而在brog中允许多申报资源,在运行一段时间进行资源的平均值检测(cpu 内存),在实际使用资源的基础上保留一部分资源,将多余的资源进行资源回收,再每隔几秒之后还会重新计算一次
7.隔离性
安全性隔离:
·早期采用Chroot jail,后期版本基于Namespace。
性能隔离:
·采用基于Cgroup的容器技术实现。
·在线任务(prod)是延时敏感(latency-sensitive)型的,优先级高,而离线任务(non-prod,Batch)优先级低。
·Borg通过不同优先级之间的抢占式调度来优先保障在线任务的性能,牺牲离线任务。
·Borg将资源类型分成两类:
·可压榨的(compressible),CPU是可压榨资源,资源耗尽不会终止进程;
·不可压榨的(non-compressible),内存是不可压榨资源,资源耗尽进程会被终止。
早期因为还没有namespace技术
可压榨资源和不可压榨资源
chroot jail(也称为chroot监狱)是一种在Unix和类Unix操作系统中使用的操作系统级安全机制。它通过更改程序根目录的方式来限制程序可以看到或访问的文件系统范围。
chroot /path/to/new_root /bin/bash
8.简单理解认识一下k8s
kuberntetes式谷歌开源的集群管理系统,主要是借助容器的热度开源抢占市场,构建生态
kubernetes借助容器的热度开源

系统的类别有声明式系统和命令式系统


kuberntes属于声明式系统(联系brog系统架构理解)
node:集群管理 pod:作业调度 svc:服务发现
一个let所在的节点为node,而这个节点的服务叫pod,namespace就是做资源隔离的
Kubernetes:声明式系统
Kubernetes的所有管理能力构建在对象抽象的基础上,核心对象包括:
· Node:计算节点的抽象,用来描述计算节点的资源抽象、健康状态等。
· Namespace:资源隔离的基本单位,可以简单理解为文件系统中的目录结构。
· Pod:用来描述应用实例,包括镜像地址、资源需求等。 Kubernetes中最核心的对象,也是打通应用和基础架构的秘密武器。
· Service:服务如何将应用发布成服务,本质上是负载均衡和域名服务的声明。
kubetnetes的架构以及主要组件
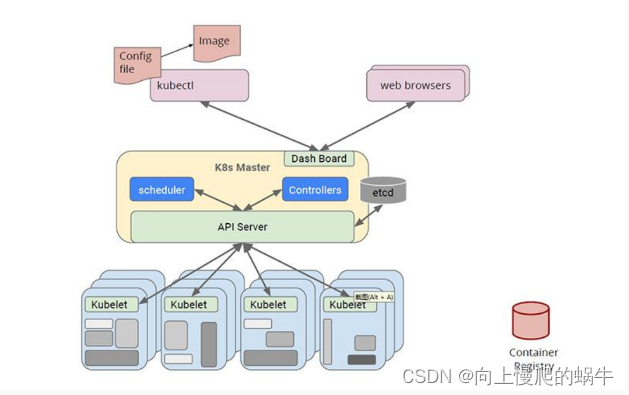
k8s发一个yaml文件的流程
首先通过kubectl发送一个命令式的模板,通过master节点上的bash board或者直接连接到api server,将这个数据进行模板化,序列化,api server会对你这个访问数据进行认证、鉴权、访问控制去做评判,这些数据没问题之后,直接将这些数据丢掉etcd中,形成序列化的模板文件,此时你的模板已经被认证,可以进行发布。此时相应的controllers会监听你会部署什么服务,假如你要部署一个pod,下面就开始进行资源调度部分,在资源调度之前需要调度算法,所以会调用schedule这个模块,确定到底往哪个节点进行部署,当schedule进行计算完成在某个节点部署之后,它会将你你模板文件中hostname字段确定为node1/2等,下面kublet节点会不断监听api server,来确定管道是否被丢进数据,如果被丢进数据,就要去部署或者执行一个什么样的对象。
【注】:在节点上有两类对象,一是kubelet,另一个是kubproce
API server:做流量控制的,
etcd:数据库+消息中间件,etcd的对象的变更会主动推送给apiserver,watch模式,所有节点都会通过API server向etcd监听所关注的数据,通过controller发送模板化文件,这个文件最后会落盘到etcd,根据etcd中所做的模板去做控制
apiserver:restserver,数据传输,做认证、鉴权、校验
scheduler:和brog调度器没啥区别,见brog架构
kubelet:状态/资源信息上报,监控,维护节点上pod生命周期
controller:对每个的抽象对象的控制,有更加高级的功能,做整个集群的自动化配置
kubernetes架构更加细化的图
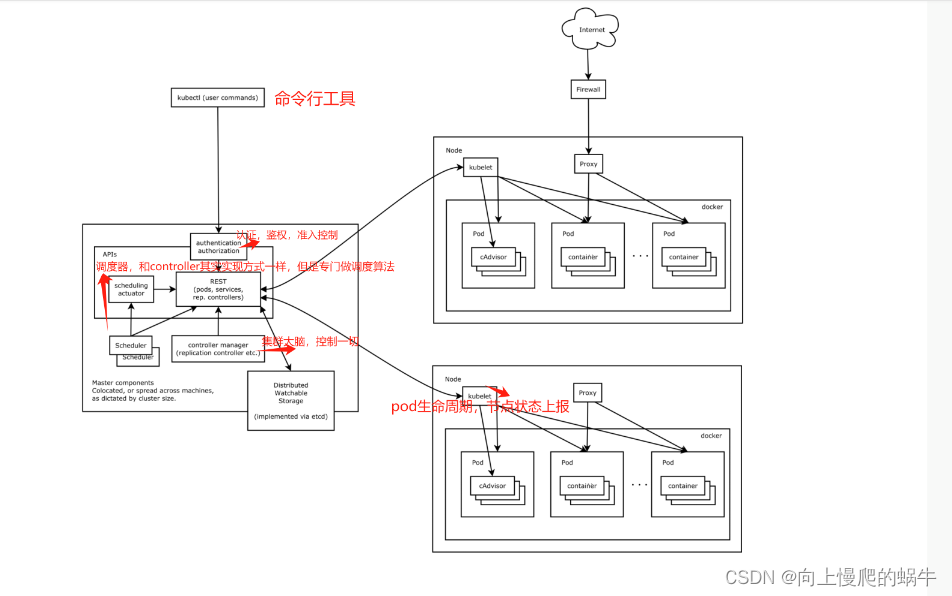
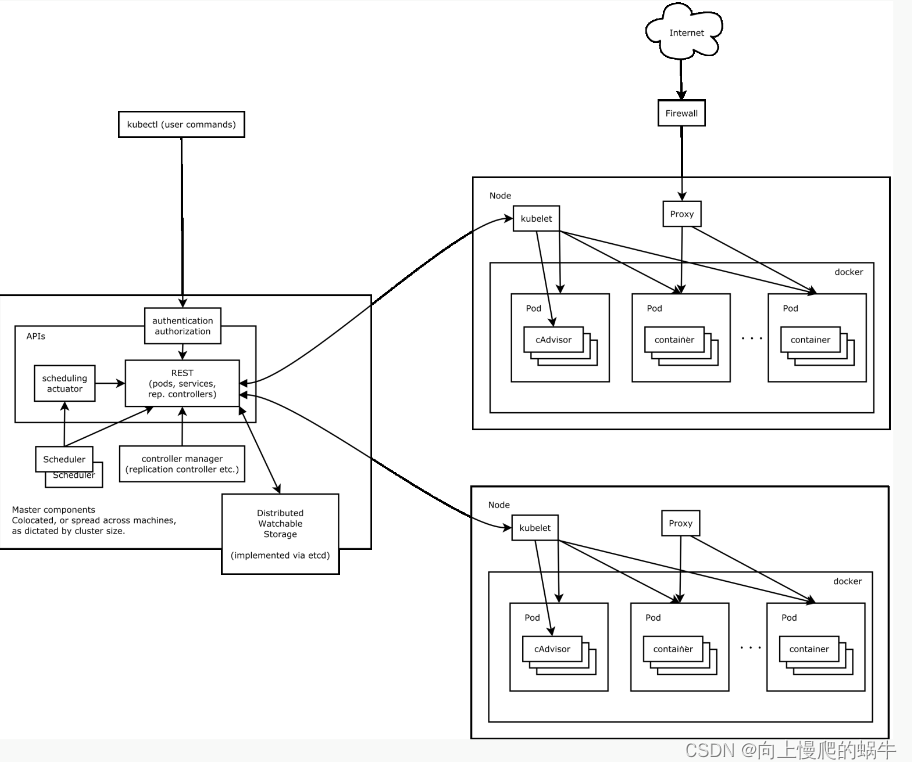
分为两类节点:master和node
master详解
authentication就是认证质询(是否有这个用户,密码是否正确,是否有这个权限,调度的资源是否合理),认证通过之后并且确保可以操作这个对象之后,会进行一个RESTful的操作,就是你要请求的对象是pod是service还是replication还是controllers,它会根据你请求的对象进行一个序列化的模板的文件出来然后输出到etcd中,再放到etcd后,scheduler会去判断调度结果要存放到什么地方要如何进行调度,调度算法和borg中的Worst fit、Best fit和混合模式差不多,调度器就会根据调度算法决定要绑定到哪个节点上,绑定好后会将etcd中的模板文件进行改变,改变之后这个时间就会被触发,触发之后节点上的kubelet就会监听RESTful API,监听到管道中出现了新数据,这个节点应该去消费这个数据,kubelet就会根据模板文件起一个pod,pod内部会有额外的进程,pod是K8S最小的调度单位,pod内部跑的是容器,一个pod可以跑一个或者多个容器,这些容器相当于borg系统中的Tasks,而pod就相当于Job
api server是一个rest api 风格的对象,主要功能是3A(认证、),kubproxy是处理网络联通的组件,当你有一个pod进行启动的时候,在启动pod时候,由kubproxy启动一系列iptables或者是ipvdm/kvs这样的规则链,从而让各个节点之间做到互相发现链
在pod组件中,有一个cadvisor,这个组件不需要你单独部署,是有k8s的kublet自动集成的,它的功能是控制你pod的生命周期,看你pod运行的容器状态,看你节点的状态是否向kublet发起回调发送pod状态
9.kuberntets的主节点和工作节点
都是核心组件,都得启动

API 服务器 API Server **:**etcd之前保护etcd 时序数据库,分布式的数据库;所有的组件都要和API Server进行交流,API Server决定数据发送到哪里,并且可以保护etcd,防止etcd(因为是分布式的所以会有存储压力)批量的请求压垮
集群的数据存储 Cluster Data store :Kubernetes 使用"etcd"。这是一个强大的、稳定的、高可用的键值存储,被Kubernetes 用于长久储存所有的 API对象。时序数据库,分布式
控制管理器 ControllerManager : 被称为"kube-controller manager",它运行着所有处理集群日常任务的控制器。包括了节点控制器、副本控制器、端点(endpoint)控制器以及服务账户等 一个个资源的控制器,控制所有服务行为的大脑,集群的大脑
调度器 Scheduler: 调度器会监控新建的 pods(一组或一个容器)并将其分配给节点。和控制器相差不大,但需要单独部署在master上
工作节点:

- Kubelet:控制pod的生命周期、容器怎么启动/关,收集node节点信息,定期上报
- Kube-proxy:解决集群间网络通信的组件
10.etcd的简单理解认识
etcd可以直接使用命令行工具进入后进行操作
etcdctl有watch操作可以用于监听
每一个数据在etcd中都有一份存储
etcd是一个有状态的集群

etcd是一个数据库,etcdctl连接数据库,相对于mysql、redis来说更适合k8s的存储需求;etcd在k8s中是一个服务发现的中间件,相当于一个注册中心,它是key-value注册的,它是一个基于key的过期服务续约机制,同时etcd有一个watch机制,将其变为长连接
etcd 是 CoreOS 基于 Raft 开发的分布式 key-value 存储,可用于服务发现、共享配置以及一致性保障(如数据库选主、分布式锁等)。
etcd本身是一个分布式的时序数据库,部署etcd需要保证高可用,一般来说是一个基于Raft算法的多实例部署,并且集群间进行心跳检测时做数据同步 存储方式:key-value
etcdctl访问etcd数据库的一个工具
查看这些数据的所有信息
export ETCDCTL_API=3
etcdctl --endpoints https://localhost:2379 \
> --cert /etc/kubernetes/pki/etcd/server.crt \
> --key /etc/kubernetes/pki/etcd/server.key \
> --cacert /etc/kubernetes/pki/etcd/ca.crt \
> get --keys-only=true --prefix /
11.apiserver的简单理解和认识
apiserver是没有状态的,可以轻松的扩展和缩容
apiserver是一个在分布式系统中负责接收和处理API请求的服务器程序。它是整个系统的核心组件之一,具有多种关键职责和功能。

由于api server是无状态的,所以处理的工具内容是一样的, 他主要功能是认证、鉴权、准备、控制,如果都是合法,才会转入etcd、注册中心;还有一个功能是etcd的保护层,减少其他业务对etcd的访问
Mutating 针对需求做额外的扩展(需不需要对你的对象做突变)
Valiatirng 判断额外的需求是否合法

两种认证方式:本地做认证、web做认证 (webhook)
访问etcd的第一步,数据传到API Server的第一步需要APIHandler注册一下,然后做认证,对用户名和密码的认证,并且有可能会有一个单独的认证服务器集群 支持webhook在外部做认证,通过认证之后会有一步是做限流Rate Limit,所有的流量都是通过API Server做的,在k8s的生态圈中是集成了这样一个限流的功能的,限流完成之后会有一步做Auditing审计,认证完成之后所做的操作会留下一个日志记录操作,审计功能做完之后就会做AuthZ鉴权,有了操作权限之后就到了准入控制的部分,准入控制部分就是Aggregator&Mutating&Valiating,来确认资源是否合法,需不需要对对象资源进行一些改变,改变之后的对象是不是合法,准入控制部分都是可以通过webhook交由外部来做的,如果说交由外部的话完全可以通过个人的代码能力写一个API Server,由这个API Server做准入控制的操作,数据在经过这一系列的认证之后认定是可以大家可以共同遵守的模板之后会将这些数据放入etcd之中
12.controller manager的简理认
Controller Manager是集群的大脑,是确保整个集群动起来的关键;
作用 是确保Kubernetes遵循声明式系统规范,确保系统的真实状态(ActualState)与用户定义的期望状态(Desired State)一致;
Controller Manager是多个控制器的组合,每个Controller事实上都是一个control loop,负责侦听其管控的对象,当对象发生变更时完成配置;
Controller配置失败通常会触发自动重试,整个集群会在控制器不断重试的机制下确保最终一致性原则(Eventual Consistency)。
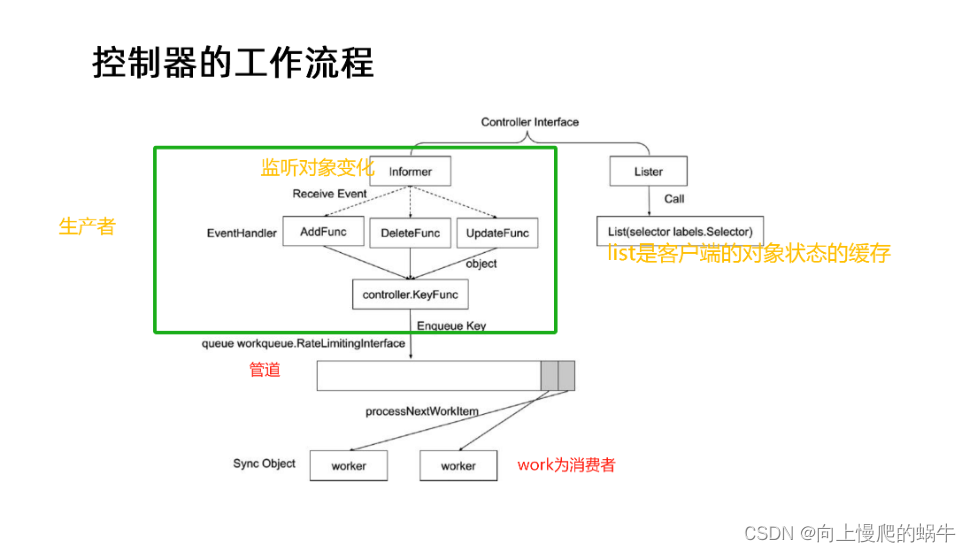
Controller 的工作流程
controller manager内部分为infomer和一个Lister,他会通过lister将一系列的对象拉过来去看有哪些对象,然后通过informer去看哪些对象发生了变化,当监听到变化时会向管道中丢一个event,worker就会去消费管道中产出的这个event而list是对客户端对象的一个缓存,在这个管道中这个对象数据可能非常的多非常的大,如果我们在管道中缓存对象就可能会非常的占用内存,所以在这个管道中存放的是一个key值,worker消费的也是一个key值,他只知道这个对象的名称和变化,worker在从管道中消费到这个event后,会自动的去找list读取缓存去访问对象数据,在拿到缓存后再去做实际的处理
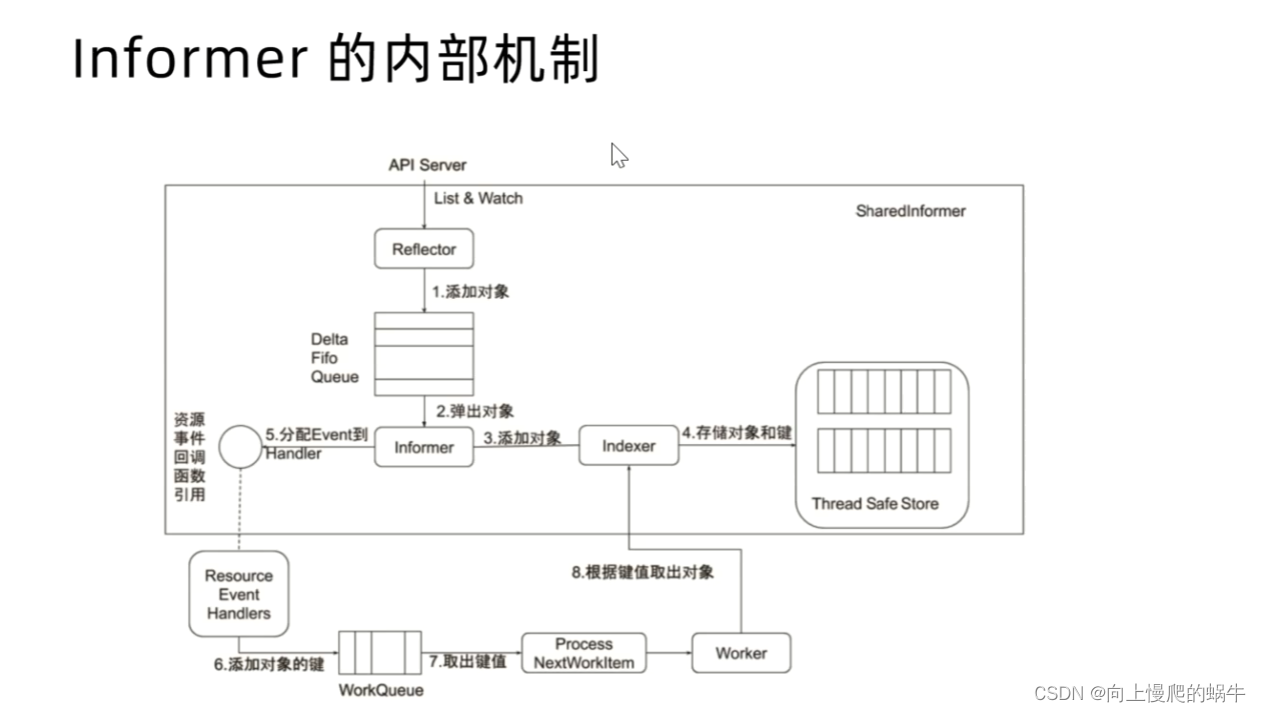
informer的内部机制
流程:
api server通过watch机制,从etcd中监听一些数据的变化,通过反射的机制明确知道有哪些对象要去做事情,这些对象一旦发生event的变化就会有两个事件,第一个是推送event,第二个是添加对象,先添加对象,将对象的键值存到缓存中去,然后给handler去分配一个事件,而work会一直监听是不是有event产生,一旦有event发生,就会取到key-value,然后根据取到的key-value的值,去找index中的缓存,到底是哪个对象要去做操作,要去发生变化
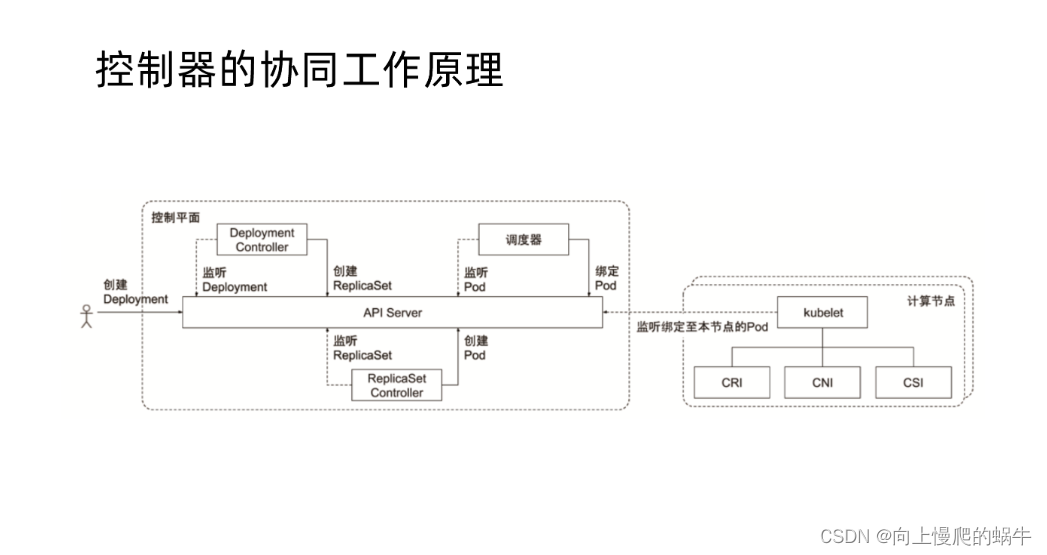
13.控制器的协同工作原理
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 如果我们现在要做一个deployment的发布,控制器会向API Server注册对象,然后API Server经过一系列的认证鉴权准入控制确认这个模板是可以放到etcd的,消费者就要去执行控制器的逻辑了,首先控制器deployment会监听到底什么时候要创建这个deployment,在监听的状态下发现etcd中有一个新的deployment的模板文件,然后控制器就开始创建属于控制器的一个deployment对象,创建出来之后,deployment是通过ReplicaSet去控制pod的,所以还会有一个叫做ReplicaSet的controller,他会监听deployment对象有没有发送任何创建pod的请求,监听到了请求之后创建pod完成之后,他会去向调度器计算请求结果,到底需要在哪个节点上去创建发布pod,请求到结果以后会将这个结果通过调度器绑定到etcd的模板文件的hostname中然后再去通知相应的组件去创建pod,相应的节点也会监听API Server,是不是ReplicaSet发送了创建请求,我这个节点是不是要去创建pod,消费到这条消息以后它会将这个消息拿过来,然后这个kubelet就会通过CRI去创建一个容器,通过容器去创建pod,通过CNI去配置容器的网络,通过CSI去配置容器的存储 |
pod控制器也是replicaset
14.scheduler的简单理解认识
scheduler也是一个控制器
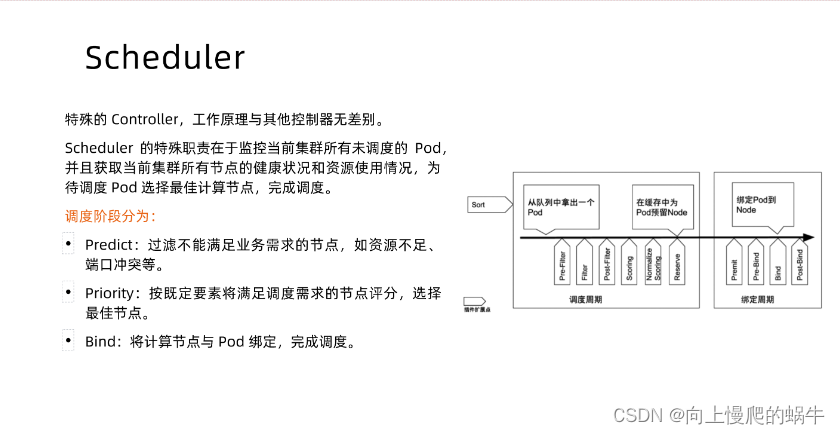
作用:监控当前集群所有未调度的pod,并且监测当前pod的健康状态
调度分为:预选(排除不满足要求的)、优选(优选选定节点之后会和pod进行绑定)、绑定
15.kubelet的简单理解认识
监听谁和自己有关就创谁

图解:
在一系列的控制逻辑层完成之后,它会调用到container Runtime interface,就是kubelet要决定启动容器了,在之前启动容器是通过docker sehll启动的,我们需要去通过CRI接口用gRPC Server转换数据协议,然后通过协议转换之后才能传递给docker shell,就是把k8s的数据形式转换为docker的数据形式,咱后再由dokcer去认知最后通过docker去控制containerd,然后再用containerd去控制runc去启动容器,而1.24版本之后我们可以使用container runtime interface直接通过containerd调用runc去启动容器
kublet本身去控制pod,第二点是向master汇报其健康状况,然后它启pod方式,是在监听api server,要去获取pod清单,获取pod清单中关于节点的所有信息,一旦获取到这个清单,就要把这个清单拉过来,进行启动,
第二种是监听自己配置目录 /etc/kubernetes/manifests/,如果这个文件下有相应yaml的目录,它会直接启动这个pod,然后去轮询这个目录,kublet是将connector抽象成CRI、网络抽象成CNI、容器接口的调用抽象成CSI
16.kubeproxy
配置网络的,每开启pod会生成iptables的规则

17.插件

brog内部默认网络是联通的,域名服务器已经做好了,所以在开源出来,没发布网络,所以为了部署网络环境,需要部署这些插件,去提供网络环境,由于k8s内部有域名解析,kube-dns负责dns服务,要一个方式去集合pod,哪个方式暴露了pod,这时候就用到了ingress插件