面试经历分享 
日期 : 4月22日
时长: 50分钟
意外之喜
没想到在面试过程中,我再次被选中进行下一轮,这确实让我感到有些意外和欣喜。这次面试经历对我而言,不仅是一次技能的检验,更是一次知识的深入学习和成长的机会。
方向与选择
当面试官问及为何从测试方向转向研发方向时,我诚实地回应,表达了研发方向对我吸引力的一部分原因在于其相对较高的薪资水平。但同时,我也强调了自己对技术探索的热爱和对编程的浓厚兴趣,这些都是驱使我转向研发方向的动力。
技能与优势
尽管我在测试方向有实习经验,但我坚信在研发方向上也有我的独特优势。我具备扎实的编程基础,对常见的数据结构如数组、链表、栈、队列等都有深入了解。此外,我能够灵活运用图的两种搜索方式DFS(深度优先搜索)和BFS(广度优先搜索),以及多种算法排序(如冒泡排序、快速排序、归并排序等),并清楚它们的时间复杂度和空间复杂度。
技术与细节
当被问及基数排序时,我能够清晰地解释其工作原理和优势。在数据库方面,我对MySQL的ACID特性(原子性、一致性、隔离性、持久性)有深入的理解,并能够解释不同隔离级别的区别和适用场景。对于none和空字符串的区别、深拷贝与浅拷贝的差异、C++野指针的危害等知识点,我都能够准确而详细地回答。
此外,我还对try语句块中的finally子句有清晰的认识,知道它无论如何都会被执行。对于构造函数和析构函数的特点,以及析构函数是否能调用虚函数等问题,我也给出了准确的回答。
实际应用与场景
在面试过程中,我还被问及缓存穿透的场景以及Redis如何实现可持久化。我能够结合实际应用场景,解释缓存穿透的成因和解决方案,并阐述Redis通过RDB(快照)和AOF(追加文件)两种方式实现数据持久化的原理。
对于MVC(模型-视图-控制器)模型和DDD(领域驱动设计)模型,我也能够阐述它们的基本概念和在实际软件开发中的应用。同时,我对HTTP常用的状态码也有深入的了解,并能够解释它们各自的含义和用途。
实战能力
在手撕代码环节,我面临了"分割IP"这一题目。在短暂的思考后,我迅速制定了解决方案,并通过编写代码成功实现了IP地址的分割。这一环节不仅检验了我的编程能力,也展现了我在面对实际问题时的快速响应和解决问题的能力。
总结
这次面试经历对我来说是一次宝贵的经验。通过面试,我不仅展示了自己的技能和优势,也学习到了许多新的知识点和解决方案。我相信,这些经验和知识将对我未来的职业发展产生积极的影响。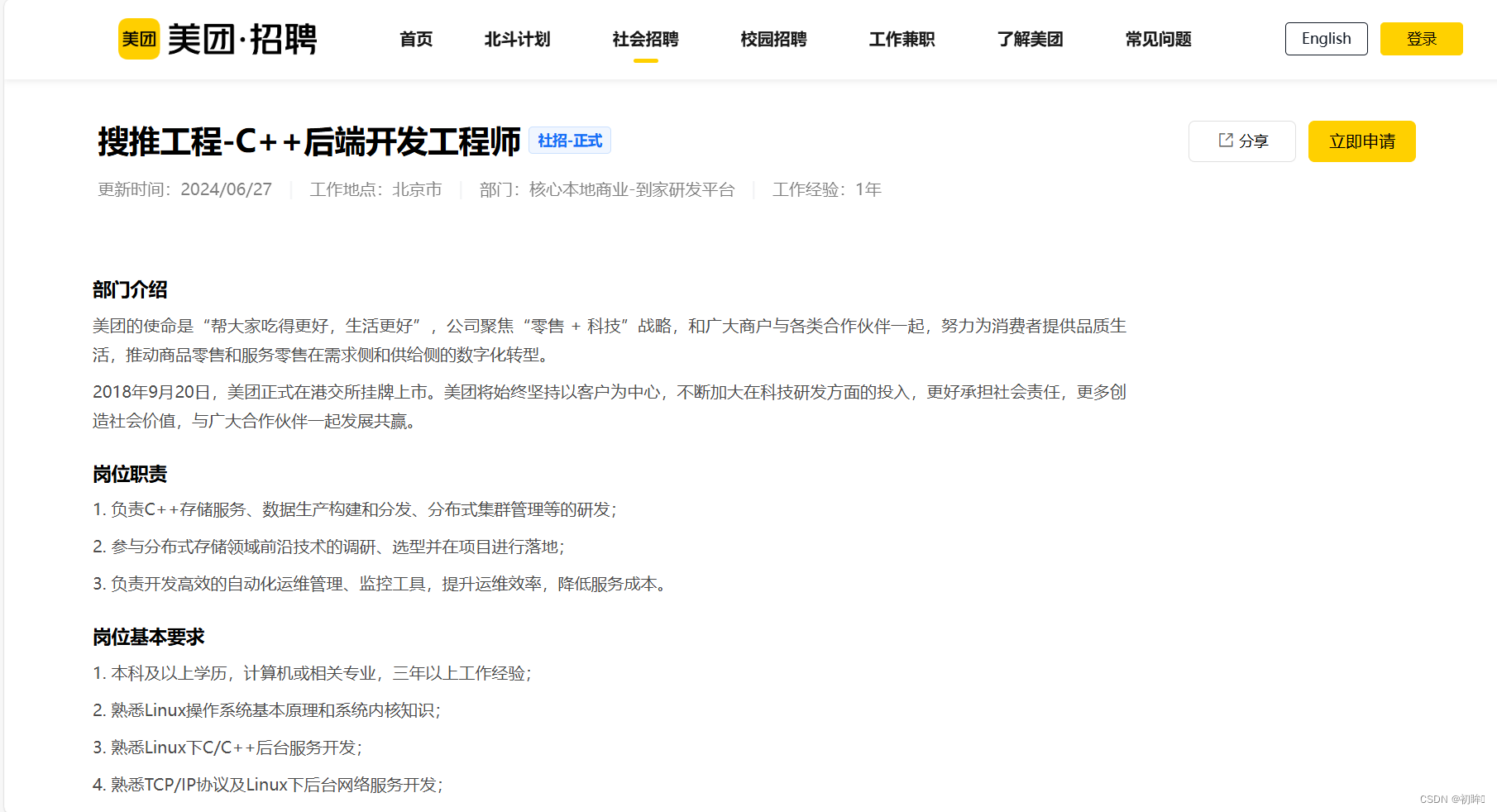
面试问题提炼与回答建议
为什么从测试转向研发?
回答建议:在实习期间,我深入了解了测试领域,并积累了丰富的经验。然而,我逐渐发现,研发工作能够更直接地参与到产品的核心开发中,实现更多创新。此外,研发工作的薪酬通常更高,这也是吸引我转向研发的一个重要因素。我相信,凭借我的测试背景和对技术的深入理解,我能够在研发领域发挥出色的作用。
相对于测试,你在研发方向的优势是什么?
回答建议:在测试实习期间,我培养了严谨的逻辑思维和细致的观察力,能够迅速发现系统中的潜在问题。这些能力在研发中同样重要,可以帮助我编写出更健壮、更可靠的代码。此外,我对技术的深入理解和快速学习能力也将使我能够快速适应研发工作,为团队贡献价值。
请举例几种常见的数据结构。
回答示例:常见的数据结构包括数组、链表、栈、队列、树(如二叉树、红黑树等)、图等。
请介绍图的两种搜索方式:DFS和BFS。
回答示例:DFS(深度优先搜索)是从某个顶点出发,尽可能深地遍历图,直到达到没有未访问过的顶点的叶子节点,然后回溯到前一个节点,继续搜索未访问过的节点。BFS(广度优先搜索)则是从某个顶点出发,先访问所有相邻的节点,然后再访问这些节点的相邻节点,层层递进,直到遍历完整个图。
介绍几种算法排序的例子,以及他们的空间复杂度。
回答示例:常见的排序算法有冒泡排序、插入排序、选择排序、快速排序、归并排序等。例如,冒泡排序的空间复杂度为O(1),因为它只需要一个额外的空间来交换元素。而归并排序的空间复杂度为O(n),因为它需要额外的空间来存储归并过程中的临时数据。
你了解基数排序吗?
回答示例:是的,我了解基数排序。基数排序是一种非比较型整数排序算法,其通过将整数按位数切割成不同的数字,然后按每个位数分别比较进行排序。基数排序通常用于对大量整数进行排序,其时间复杂度为O(nk)(其中n是待排序元素个数,k是数字的位数)。
请介绍MySQL的ACID功能。
回答示例:MySQL的ACID特性保证了数据库事务的原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。这些特性确保了数据库在多个事务并发执行时的正确性和可靠性。
你知道MySQL的哪些隔离级别?
回答示例:MySQL支持四种隔离级别,分别是读未提交、读已提交、可重复读和串行化。这些隔离级别提供了不同程度的数据可见性和并发性能。
none和空字符串的区别是什么?
回答示例:none通常表示一个空值或不存在的值,在Python中None是一个特殊的常量,表示没有值或空值。而空字符串是一个长度为0的字符串,即它不包含任何字符。在数据库中,NULL(类似于Python中的None)和空字符串是两种不同的概念,前者表示缺失值或未知值,后者表示一个明确的、但不包含任何内容的字符串。
SELECT NULL=NULL会怎么样?
回答示例:在SQL中,NULL表示一个未知或缺失的值。因此,NULL=NULL的比较结果不是TRUE,而是NULL。这是因为NULL不代表任何具体的值,所以无法确定两个NULL是否相等。
深拷贝和浅拷贝的区别是什么?
回答示例:深拷贝会创建一个新的对象,并复制原始对象的所有内容,包括其内部的子对象。这样,修改新对象不会影响原始对象。而浅拷贝则只复制原始对象的顶层结构和引用,不会递归地复制内部子对象。因此,修改浅拷贝中的子对象可能会影响原始对象。
C++中的野指针是什么?
回答示例:野指针是指已经被释放的内存,但是指针的值没有被置为NULL,仍然指向原来的内存地址。这样的指针是危险的,因为它们可能会导致程序崩溃或数据损坏。
try里面的finally你了解吗?一定会被执行吗?
回答示例:finally块是Java异常处理机制的一部分,用于在try块和catch块之后执行清理代码。无论try块中的代码是否抛出异常,finally块中的代码都会被执行。但是,如果在finally块执行之前程序被终止(如System.exit()方法被调用或JVM崩溃),则finally块可能不会被执行。
构造函数的特点是什么?
回答示例:构造函数是一种特殊的方法,用于初始化新创建的对象。它的特点包括:构造函数名与类名相同,没有返回值类型,可以在创建对象时自动调用,可以重载但不能被继承,主要用于完成对象的初始化工作。
析构函数是否能调用虚函数?
回答示例:在C++中,析构函数中可以调用虚函数,但通常不建议这样做。因为当析构函数被调用时,对象的生命周期即将结束,此时调用虚函数可能会导致不确定的行为,特别是如果虚函数依赖于对象的某些状态或资源,而这些状态或资源在析构过程中可能已经被释放或不再有效。
缓存穿透的场景是什么?
回答示例:缓存穿透是指查询一个不存在的数据,由于缓存中也没有,导致每次都要去数据库中查询,造成缓存和数据库资源的浪费,甚至可能让数据库崩溃。常见的解决方案是将空对象也缓存起来或者采用布隆过滤器等数据结构来快速判断数据是否存在。
Redis如何实现可持久化?
回答示例:Redis提供了两种持久化方式:RDB(Redis DataBase)和AOF(Append Only File)。RDB是默认的持久化方式,它按照一定的时间间隔将数据快照写入二进制文件。AOF持久化则是通过记录Redis的所有写命令并追加到一个文件中来实现数据的持久化,这种方式可以提供更好的数据安全性,但可能会影响Redis的性能。
MVC模型和DDD模型是什么?
回答示例:MVC(Model-View-Controller)模型是一种软件设计模式,它将应用程序分为三个主要部分:模型(Model)表示数据和业务逻辑,视图(View)表示用户界面,控制器(Controller)处理用户输入并根据输入更新模型和视图。DDD(Domain-Driven Design)模型则是一种软件开发方法论,它强调将业务逻辑和领域知识作为软件设计的核心,通过建立丰富的领域模型来指导系统的设计和开发。
HTTP常用的状态码有哪些?
回答示例:HTTP状态码是服务器对客户端请求的响应状态的一个三位数字代码。常见的状态码包括:200(OK,请求成功)、404(Not Found,未找到资源)、403(Forbidden,禁止访问)、500(Internal Server Error,服务器内部错误)等。
手撕代码:分割IP
题目描述:给定一个字符串形式的IP地址,如"192.168.1.1",请编写一个函数将其分割成四个部分并返回一个包含这四个部分的列表。
示例代码(Python):
python
def split_ip(ip_address):
return ip_address.split('.')
# 测试代码
ip = "192.168.1.1"
print(split_ip(ip)) # 输出:['192', '168', '1', '1'] 请注意,以上代码和回答示例是基于常见的面试问题和知识点整理的,具体回答时还需要根据面试的实际情况和语境进行适当的调整和补充。