目录
[一、MapReduce 示例程序的导入并运行测试](#一、MapReduce 示例程序的导入并运行测试)
[二、准备 4 个小文件(文件大小分别为 1.7M,5.1M,3.4M,6.8M)](#二、准备 4 个小文件(文件大小分别为 1.7M,5.1M,3.4M,6.8M))
[1. 第一种情况,默认分片:不修改程序代码,直接使用 WordCount 源程序](#1. 第一种情况,默认分片:不修改程序代码,直接使用 WordCount 源程序)
[2. 第二种情况,在代码中增加如下内容](#2. 第二种情况,在代码中增加如下内容)
[3. 第三种情况,将数值设为 20M](#3. 第三种情况,将数值设为 20M)
[三、对 sogou.500w.utf8 数据进行分析,使用 MapReduce 编写程序完成。](#三、对 sogou.500w.utf8 数据进行分析,使用 MapReduce 编写程序完成。)
[1. 程序源代码](#1. 程序源代码)
[2. 程序输出结果](#2. 程序输出结果)
一、MapReduce 示例程序的导入并运行测试
步骤 1 :在 eclipse 中创建 Java Project → new Package
步 骤 2 : 将 /home/2130502441ryx/hadoop-3.1.3-src/hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples 目录下的 WordCount.java 文件通过复制命令 cp 放到桌面/home/gdpu/Desktop,如下所示:
bash
// 解压压缩包
tar -zxvf /home/2130502441ryx/hadoop-3.1.3-src.tar.gz /home/2130502441ryx
bash
// 复制文件
cp /home/2130502441ryx/hadoop-3.1.3-src/hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/WordCount.java

步骤 3:将 WordCount.java 文件通过复制粘贴,拷贝至 eclipse 对应项目的包下。
步骤 4:导入依赖包 External jars,将以下文件夹里面的 jar 加入到项目的 build path。
\share\hadoop\common
\share\hadoop\common\lib
\share\hadoop\hdfs
\share\hadoop\mapreduce
\share\hadoop\yarn步骤 5:将项目打包成 jar 包,项目点右键---> export ---> Java(JAR file)。

步骤 6:在 HDFS 文件系统上创建文件夹 input,并上传一些文本文件到该目录,文件自行在操作系统上选取。
bash
hdfs dfs -mkdir /input
hdfs dfs -ls /
bash
hdfs dfs -put /home/2130502441ryx/testWordCount /input
hdfs dfs -ls /input
hdfs dfs -cat /input/testWordCount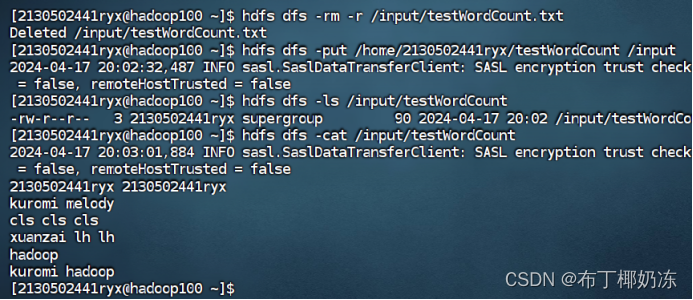
步骤 7:运行 WordCount 示例程序,将运行程序的命令和结果截图在下面。
bash
hadoop jar /home/2130502441ryx/MapReduceTest.jar org/ryx/WordCount /input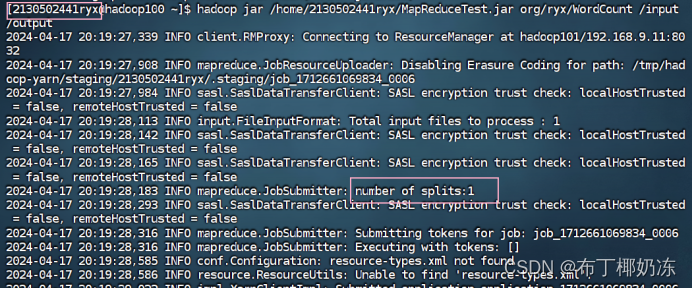
bash
hdfs dfs -ls /output
hdfs dfs -cat /output/part-r-00000
二、准备 4 个小文件(文件大小分别为 1.7M,5.1M,3.4M,6.8M)
a.txt在我上传的资源中,可以免费下载!!
https://download.csdn.net/download/m0_67830223/89498183?spm=1001.2014.3001.5503
bash
cat a.txt >>b.txt
cat a.txt >>b.txt
cat a.txt >>c.txt
cat a.txt >>c.txt
cat a.txt >>c.txt
cat a.txt >>d.txt
cat a.txt >>d.txt
cat a.txt >>d.txt
cat a.txt >>d.txt 

将上述 4 个文件上传至 HDFS 文件系统作为 WordCount 的输入,运行WordCount 程序观察分片情况。
bash
hdfs dfs -ls /input1
1. 第一种情况,默认分片:不修改程序代码,直接使用 WordCount 源程序
bash
hadoop jar /home/2130502441ryx/MapReduceTest.jar org/ryx/WordCount /input1 /output1
2. 第二种情况,在代码中增加如下内容
java
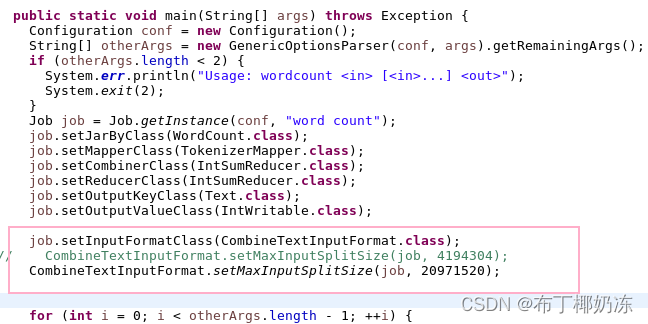
job.setInputFormatClass(CombineTextInputFormat.class);
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);添加代码如下:

运行截图:
bash
hadoop jar /home/2130502441ryx/MapReduceTest.jar org/ryx/WordCount /input1 /output2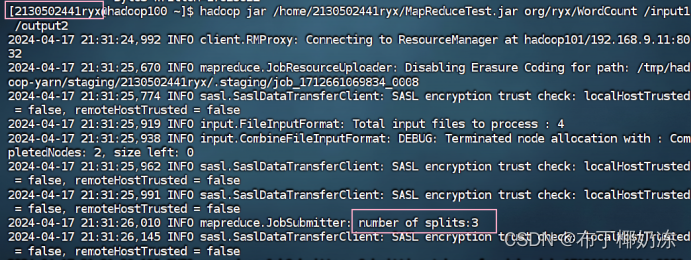
3. 第三种情况,将数值设为 20M
java
CombineTextInputFormat.setMaxInputSplitSize(job, 20971520);修改代码如下:
运行截图:
bash
hadoop jar /home/2130502441ryx/MapReduceTest.jar org/ryx/WordCount /input1 /output3
三、对 sogou.500w.utf8 数据进行分析,使用 MapReduce 编写程序完成。
将程序主要代码复制或者截图在下面,包括主要的 Mapper 类,Reducer 类和 Partition 类,并将打包运行后的结果输出并截图。
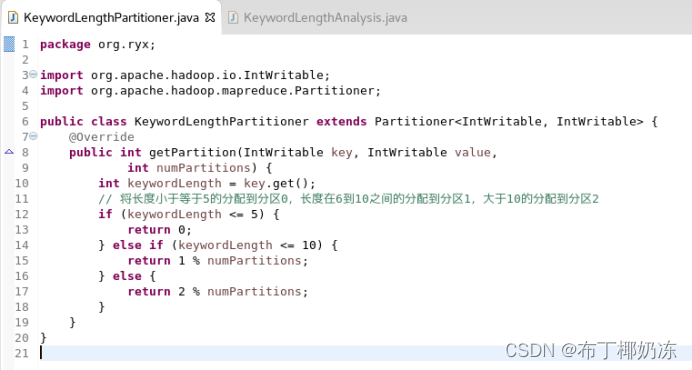
分析统计用户查询关键字长度的次数分布,关键字长度为 1 的搜索次数,长度为 2 的搜索次数,...,长度为 N 的搜索次数。输出结果将按搜索长度分为 3 组,长度在小于等于 5 的分一组,长度在 6 到 10 之间的分一组,大于 10 的分一组。
bash
hdfs dfs -ls /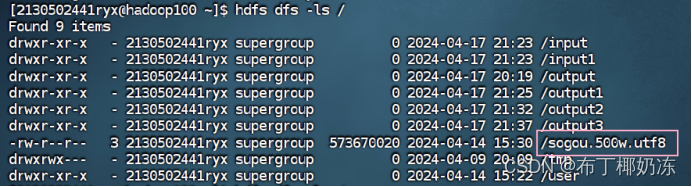
1. 程序源代码
① KeywordLengthMapper
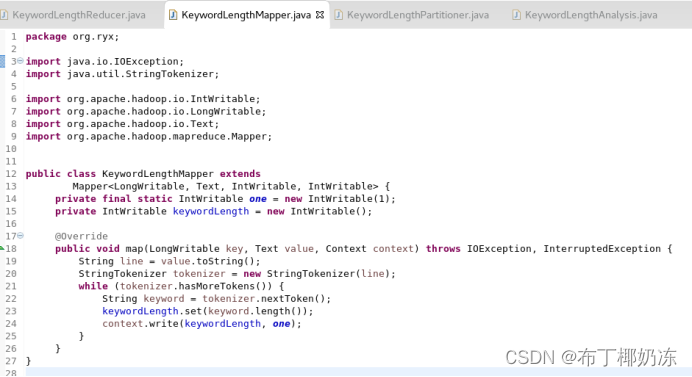
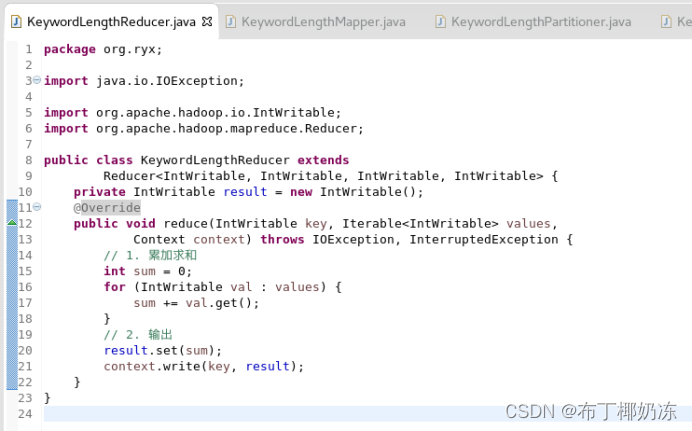
② KeywordLengthReducer
③ KeywordLengthPartitioner
④ KeywordLengthAnalysis

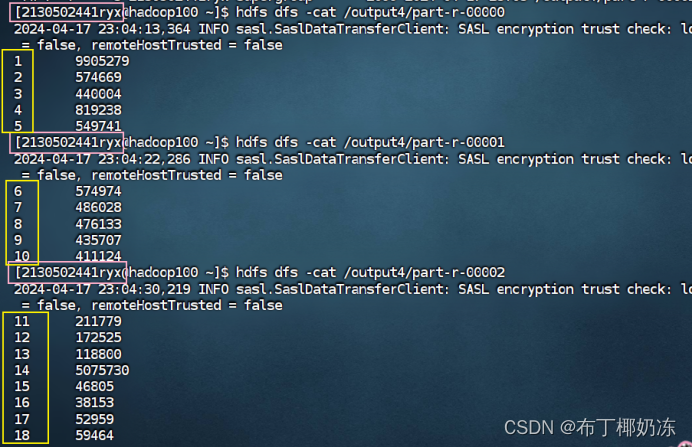
2. 程序输出结果
bash
hadoop jar /home/2130502441ryx/MapReduceTest.jar org/ryx/KeyWordLengthAnalysis /sogou.500.utf8 /output4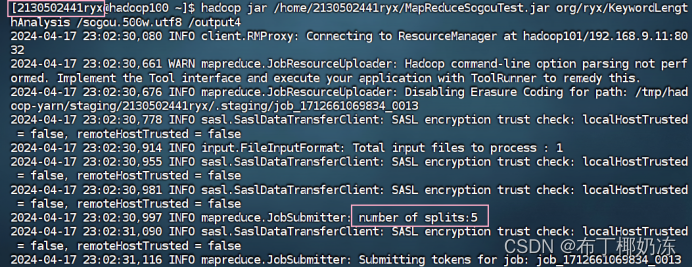
bash
hdfs dfs -ls /output4
bash
hdfs dfs -cat /output4/part-r-00000
hdfs dfs -cat /output4/part-r-00001
hdfs dfs -cat /output4/part-r-00002