文章目录
LeNet神经网络是第一个卷积神经网络(CNN),首次采用了卷积层、池化层这两个全新的神经网络组件,接收灰度图像,并输出其中包含的手写数字,在手写字符识别任务上取得了瞩目的准确率。LeNet网络的一系列的版本,以LeNet-5版本最为著名,也是LeNet系列中效果最佳的版本。LeNet神经网络输入图像大小必须为32x32,且所用卷积核大小固定为5x5,模型结构如下:
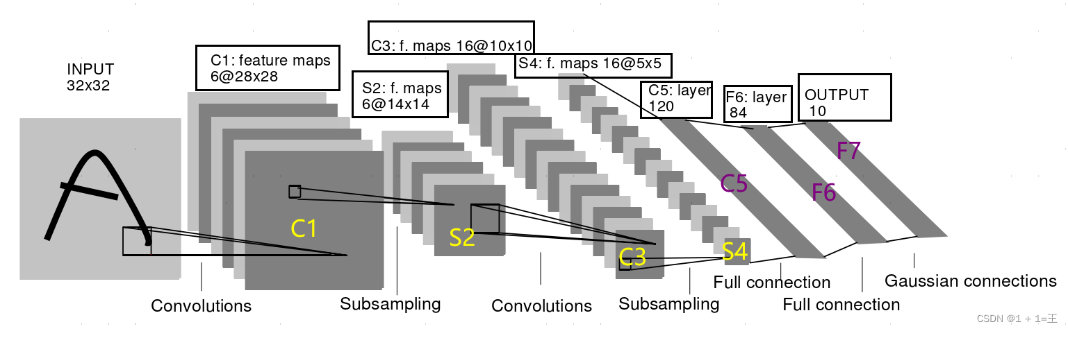
模型参数:
- INPUT(输入层):输入图像尺寸为32x32,且是单通道灰色图像。
- C1(卷积层):使用6个5x5大小的卷积核,步长为1,卷积后得到6张28×28的特征图。
- S2(池化层):使用了6个2×2 的平均池化,池化后得到6张14×14的特征图。
- C3(卷积层):使用了16个大小为5×5的卷积核,步长为1,得到 16 张10×10的特征图。
- S4(池化层):使用16个2×2的平均池化,池化后得到16张5×5 的特征图。
- C5(卷积层):使用120个大小为5×5的卷积核,步长为1,卷积后得到120张1×1的特征图。
- F6(全连接层):输入维度120,输出维度是84(对应7x12 的比特图)。
- OUTPUT(输出层):使用高斯核函数,输入维度84,输出维度是10(对应数字 0 到 9)。
该模型有如下特点:
- 1.首次提出卷积神经网络基本框架: 卷积层,池化层,全连接层。
- 2.卷积层的权重共享,相较于全连接层使用更少参数,节省了计算量与内存空间。
- 3.卷积层的局部连接,保证图像的空间相关性。
- 4.使用映射到空间均值下采样,减少特征数量。
- 5.使用双曲线(tanh)或S型(sigmoid)形式的非线性激活函数。
一、模型实现
1.1数据集的下载
使用torchversion内置的MNIST数据集,训练集大小60000,测试集大小10000,图像大小是1×28×28,包括数字0~9共10个类。
py
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import torchvision
# 下载训练、测试数据集
mnist_train = torchvision.datasets.MNIST(root='./dataset/',
train=True, download=True, transform=transforms.ToTensor())
mnist_test = torchvision.datasets.MNIST(root='./dataset/',
train=False, download=True, transform=transforms.ToTensor())
print('mnist_train基本信息为:',mnist_train)
print('-----------------------------------------')
print('mnist_test基本信息为:',mnist_test)
print('-----------------------------------------')
img,label=mnist_train[0]
print('mnist_train[0]图像大小及标签为:',img.shape,label)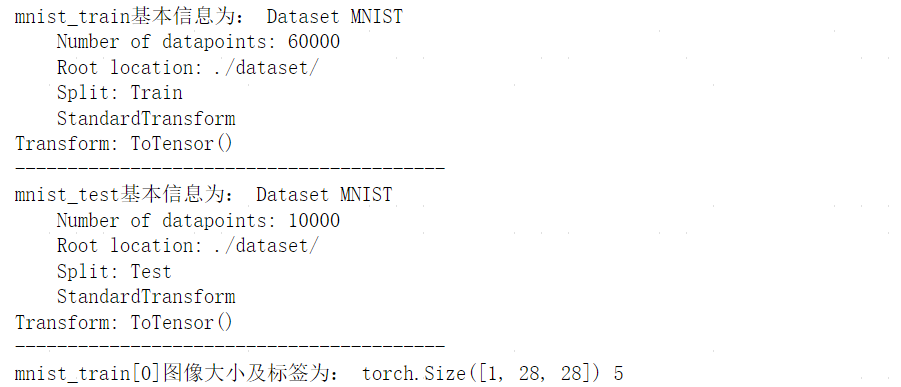
1.2加载数据集
py
trainDataLoader = DataLoader(mnist_train, batch_size=64, num_workers=5, shuffle=True)
testDataLoader = DataLoader(mnist_test, batch_size=64, num_workers=0, shuffle=True)
write = SummaryWriter('./log')
step = 0
for images, labels in testDataLoader:
write.add_images(tag='train', images, global_step=step)
step += 1
write.close() 注意不能使用for images, labels in testDataLoader.dataset,testDataLoader.dataset[0]是保存图像(28
,28)和对应标签的元组,而Tensorboard的add_images只能输入NCHW格式对象,使用该代码会报错:
py
size of input tensor and input format are different. tensor shape: (1, 28, 28), input_format: NCHW数据加载器按batch_size对数据及标签进行封装名,可直接作为输入。查看封装的元组:
py
for data in testDataLoader:
print('type(data):',type(data))
img,label=data
print('type(img):',type(img),'img.shape:',img.shape)
print('type(label):',type(label),'label.shape:',label.shape)
1.3模型训练
LeNet模型的输入为(32,32)的图片,而MNIST数据集为(28,28)的图片,故需对原图片进行填充。搭建模型:
py
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.model = nn.Sequential( #MNIST数据集图像大小为28x28,而LeNet输入为32x32,故需填充
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2), #C1层共六个卷积核,故out_channels=6
nn.AvgPool2d(kernel_size=2, stride=2), #C2层使用平均池化
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Conv2d(in_channels=16 * 5 * 5, out_channels=120),
nn.Linear(in_features=120, out_features=84),
nn.Linear(in_features=84, out_features=10)
)
def forward(self, x):
return self.model(x)
# 初始化模型对象
myLeNet = LeNet()设置损失函数、优化器并训练模型:
py
# 设置损失函数为交叉熵损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 设置优化器,使用Adam优化算法
learning_rate = 1e-2
optimizer = torch.optim.Adam(myLeNet.parameters(), lr=learning_rate)
total_train_step = 0 # 总训练次数
epoch = 10 # 训练轮数
writer = SummaryWriter(log_dir='./runs/LeNet/')
for i in range(epoch):
print("-----第{}轮训练开始-----".format(i + 1))
myLeNet.train() # 训练模式
train_loss = 0
for data in trainDataLoader:
imgs, labels = data
imgs = imgs.to(device) # 适配GPU/CPU
labels = labels.to(device)
outputs = myLeNet(imgs)
loss = loss_fn(outputs, labels)#计算损失函数
optimizer.zero_grad() # 清空之前梯度
loss.backward() # 反向传播
optimizer.step() # 更新参数
total_train_step += 1 # 更新步数
train_loss += loss.item()
writer.add_scalar("train_loss_detail", loss.item(), total_train_step)
writer.add_scalar("train_loss_total", train_loss, i + 1)
writer.close()1.4模型预测
py
myLeNet.eval()
total_test_loss = 0 # 当前轮次模型测试所得损失
total_accuracy = 0 # 当前轮次精确率
with torch.no_grad(): # 关闭梯度反向传播
for data in testDataLoader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = myLeNet(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
writer.add_scalar("test_loss", total_test_loss, i+1)
writer.add_scalar("test_accuracy", total_accuracy/len(mnist_test), i+1)