优化ALV报表,最主要就是优化取数逻辑 和数据库查询。因为几乎在所有的程序中都会用到数据库查询,所以这篇文章的内容也不仅局限于SAP、ABAP程序,虽然ABAP有其特殊之处。
优化的时候我遵从以下几个原则:
1.把数据库连接视为一种极其珍贵的资源,大量的数据库操作会增加网络负载,增加程序的运行、等待时间,降低程序性能。因此有以下的注意事项:
(1)因此数据库操作能少则少 ,严禁在循环中写SQL语句 对数据库进行操作;
(2)应该将数据读取到内存中 ,对内存中的数据进行操作,如排序和运算等,而不是直接对数据库表进行;
2.多表连接查询时,连接的表的数量尽量不超过2-3张 。当表的数量过多、数据量大时,会极大程度影响性能。应该先将数据读取到内表(类似于数组)中,使用FOR ALL ENTRIES IN来和其余需要连接的表进行关联。且簇表无法连接,只能使用FOR ALL ENTRIES IN的方法。 虽然我看到有开发规范说尽可能只连接1张表,但是实际的业务需求中经常只是取其他表的1、2个字段,为了这1、2个字段单独建结构,然后用FOR ALL ENTRIES IN查询实在是太麻烦,这里把限制放宽到2-3张也算是为了方便和为了性能的折中考虑吧。
3.尽可能使用系统提供的方法,而不是自己实现。比如使用SQL的聚合函数进行统计、计算,而不是自己实现。
4.少循环。当数据量比较大时,多次循环会消耗大量的时间和性能。所以循环语句应该近可能少,尽量避免嵌套循环,尽可能将操作放在一次循环中进行。
5.使用一些高效的写法(至少我认为是高效的),在编程和优化过程中不断的参照了一些Performance Examples里的一些写法。主要是以下几点:
(1)需要修改内表中的某行的某字段值时,我选择使用FIELD-SYMBOLS (类似指针), LOOP ... ASSIGNING field-symbols 和READ TABLE itab ASSIGNING field-symbols 这样的写法,而不是使用LOOP ... INTO wa READ TABLE itab INTO wa 修改完后再MODIFY TABLE itab FROM wa;
(2)声明的变量尽可能指明类型、长度 ;
(3)对于长度较长、长度可变的字符串使用STRING类型替代C类型;
当然难免有产生冲突的情况,比如:有时多次循环、嵌套循环不可避免,使用聚合函数进行统计需要额外的一次数据库查询等,这就需要具体情况具体分析,选择一种折中、合适的方法。
一些优化实例:
1.使用了动态查询条件,适用于查询字段相同,只是条件不同的情况,主要是减少了重复代码,说不上能改善性能。


2.将两次循环合并成一次循环进行
将原来的两段循环:


合并成:

3.使用SELECT......ENDSELECT-LOOP
这个类似于常规SQL中的游标,能每次对查询结果中的单条数据进行处理和操作。这个一定程度上弥补了ABAP的OPEN-SQL无法对查询字段做运算和SELECT 常量的操作:例如select a+b from tab 和 select '常量',但感觉上使用SELECT......ENDSELECT-LOOP会增加数据库连接的占用时间。
我使用SELECT......ENDSELECT-LOOP筛选出COSS~WTG004和COSP~WTG004相加为零的结果,将原来一次额外的LOOP写到SELECT......ENDSELECT-LOOP中。


OPEN-SQL没法SELECT常量,所以只能查询后再手动修改,我将修改的一次额外循环也合并到SELECT......ENDSELECT-LOOP。
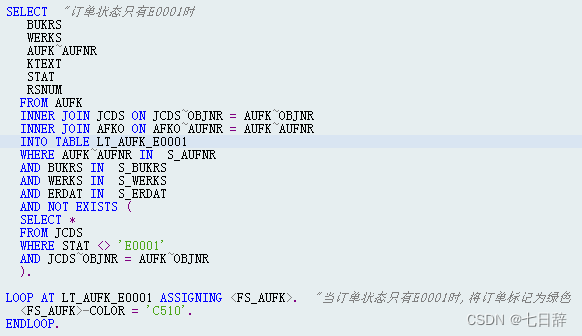

4.使用子查询,这在ABAP性能实例中也提到过,当需要判断是否存在时使用EXISTS加子查询,而不要在SELECT......ENDSELECT-LOOP再次查询是否存在,这样相当于循环中执行SQL。
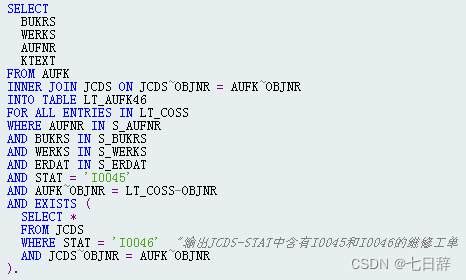
5.使用聚合函数,而不是自己实现统计功能,尤其是需要进行分组统计时。

6.在需要获取内表长度的时候,用ABAP关键字DESCRIBE TABLE itab LINES length,而不是自己循环内表进行统计。
