论文地址:https://arxiv.org/pdf/2211.05953
一、宏观印象
这篇论文提出了一种名为**Breadth-First Pipeline Parallelism(广度优先流水线并行,BF-PP)**的新型分布式训练调度方法。它主要解决了在大规模GPU集群上训练大语言模型时,训练时间、成本和内存使用效率之间难以平衡的核心矛盾。
下面是论文的关键要点、对系统架构设计的借鉴意义,以及在主流框架中的体现。
1)论文核心关键要点
论文的核心目标是在保持高GPU利用率的同时,尽可能降低每块GPU上的批次大小。传统方法(如Megatron的3D并行)为了填满流水线、提高利用率,不得不使用较大的每GPU批次大小,但这会降低随机梯度下降的优化效率,增加总训练成本。BF-PP通过两项关键技术解决了这个问题:
-
循环流水线:不同于传统流水线将模型层按顺序分配到不同设备,BF-PP采用"循环"分配策略。例如,一个有4层的模型在4个设备上,传统方法会分配每设备1层,而循环分配会让设备1处理第1、5、9...层,设备2处理第2、6、10...层,以此类推。
- 优点:缩短了流水线气泡(设备空闲等待时间),从而允许使用更小的批次大小来达到高利用率。
-
广度优先调度 :这是BF-PP的核心创新。传统流水线并行(如GPipe)使用深度优先调度:一次性将多个微批次送入流水线的第一阶段,逐层向前推进。这会导致较早阶段的激活值在内存中留存很长时间,内存占用高。
- 广度优先调度 :让一个微批次尽快走完全程。具体来说,一旦一个微批次完成了某一层的计算,就立刻被送到下一层的设备,而不是等待同一阶段的其他微批次。
- 优势 :
- 内存占用极低 :激活值在设备上的留存时间大幅缩短,峰值内存显著下降,这使得结合全分片数据并行成为可能。
- 通信与计算重叠更好:由于微批次在设备间流动更快、更连续,网络通信更容易被计算时间覆盖,减少了通信瓶颈。
简单来说,BF-PP = 循环流水线 + 广度优先调度 + 全分片数据并行 。这个组合拳使得它能在β_min(理论上每GPU最低批次大小,通常为1)附近高效运行,从而在总批次大小不变的情况下,可以使用更多的GPU进行数据并行,最终实现更短的训练时间和更低的成本。论文在520亿参数模型上的实验显示,相比Megatron-LM,BF-PP在相近配置下实现了高达43%的训练吞吐量提升。
2)从Infra角度的借鉴之处
这篇论文的贡献远不止一个新调度算法,它在分布式训练的系统设计思路上提供了关键的借鉴:
-
重新审视"气泡-内存-通信"的权衡三角 :传统流水线并行主要在"流水线气泡"和"内存占用"之间权衡(用更多内存缓存激活来减少气泡)。BF-PP引入了第三个维度------通信。它的广度优先调度证明,通过优化通信模式(实现更好的通信计算重叠),可以同时减少气泡和内存占用,打破了传统权衡。这对设计新的并行策略有启发意义。
-
将调度策略提升为核心优化维度 :过去,优化重点常放在模型切分(张量并行)、数据分配和重计算上。BF-PP表明,微批次在设备间的调度顺序本身就是一个强大的优化杠杆,能系统性影响内存、通信和利用率。这提示系统开发者需要将调度器设计为更灵活、可插拔的模块。
-
为"极致小批次"场景提供系统支持 :BF-PP明确瞄准了
β_min附近的高效训练。这对应了两种重要趋势:①在固定总计算预算下,用极大规模集群加速训练 ;②在资源受限(如单批内存小)的情况下训练大模型。论文为此类场景提供了经过验证的系统级解决方案。 -
拥抱异构集群通信拓扑 :BF-PP的通信模式(广度优先)能更好地适应GPU集群内NVLink(高速)和InfiniBand(相对低速)的异构网络。它让设备间频繁交换的小规模通信更多发生在节点内高速链路,有利于整体效率。这种对网络拓扑敏感的设计越来越重要。
3)在主流框架中的思想体现与参数映射
BF-PP的思想尚未被任何主流框架完全原生实现,但其核心设计理念,特别是广度优先调度 和对内存的极致优化,已经影响了后续框架的设计,并能在一些现有特性中找到影子。
| 框架 | BF-PP思想相关特性/参数 | 具体说明 |
|---|---|---|
| Megatron-LM | pipeline 模型类型 |
Megatron的流水线并行默认是循环分配 的(即论文中的"looping"或"interleaved")。可通过--num-layers-per-virtual-pipeline-stage等参数配置虚拟流水线阶段,这是BF-PP循环分配的基础。但其调度默认是深度优先。 |
| FairScale/ PyTorch FSDP | 分片策略与计算重叠 | 全分片数据并行 是BF-PP能实现低内存的关键支柱。FSDP的sharding_strategy(如FULL_SHARD)以及limit_all_gathers=True等参数旨在优化通信与计算的重叠,体现了BF-PP"最大化通信计算重叠"的核心原则。 |
| DeepSpeed | Zero-3 与 流水线并行 | DeepSpeed的ZeRO-3 阶段实现了比FSDP更激进的全参数分片,是低内存的基石。其流水线并行模块支持训练大模型,但调度器更接近传统方法。不过,DeepSpeed对通信重叠的持续优化(如通过timeline规划)与BF-PP目标一致。 |
| VarI (Verl) | 1F1B调度策略 | VarI (Verl) 等研究型框架明确实现了1F1B (One Forward One Backward) 调度。这是广度优先调度的一种经典实现,与BF-PP思想同源。其核心是让每个设备尽快执行一次前向和一次后向,这正是BF-PP降低内存的关键机制。 |
目前,要完整复现论文中的BF-PP,通常需要修改框架源码或使用研究型代码库。关键修改点集中在调度器部分:将默认的深度优先调度器替换为广度优先(或1F1B)调度器,并确保其与循环流水线分配和全分片数据并行正确协同工作。
4)总结
总而言之,Breadth-First Pipeline Parallelism的核心贡献在于,它通过广度优先调度 这一巧妙的系统设计,系统性地降低了流水线并行的内存开销和通信瓶颈 ,从而允许训练系统在更小的每GPU批次大小下高效运行。这打破了传统并行策略的 scaling 限制,为在超大规模集群上以更低成本、更快速度训练巨型模型提供了一条新的技术路径。它的思想正在逐渐被社区吸收,并影响着下一代分布式训练框架的设计。
二、精读论文
摘要
我们提出"广度优先流水线并行"这一创新训练方案,通过优化流水线并行与数据并行的协同作用,显著提升训练效率。该方案通过高GPU利用率与小批量处理相结合,同时充分利用完全分片的数据并行特性,有效降低训练时间、成本和内存占用。实验数据显示,相较于Megatron-LM模型,采用小批量处理的520亿参数模型训练吞吐量最高提升43%,若在大型GPU集群上实施,训练时间和成本的节省幅度同样可达43%。
关键图表
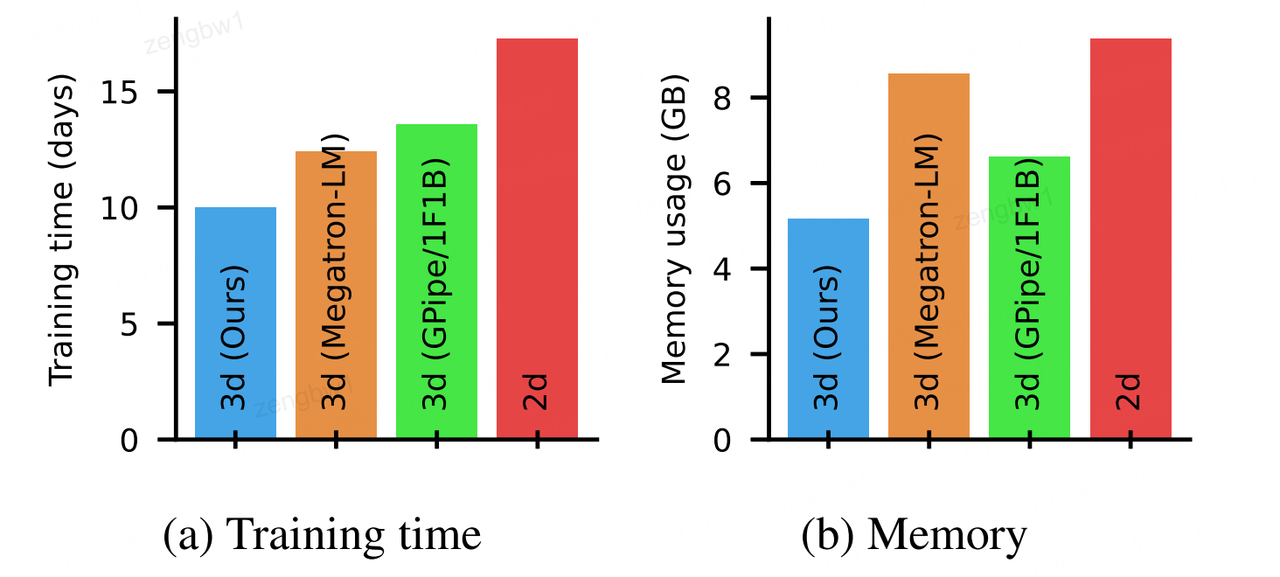
图1:采用我们的方法(广度优先流水线并行性)在4096个Nvidia V100 GPU集群上运行520亿参数模型时,预测的训练时间(a)与内存使用量(b)对比3D和2D基线模型。
Q1:论文中提到的2D和3D基线指的是什么,采用什么方法
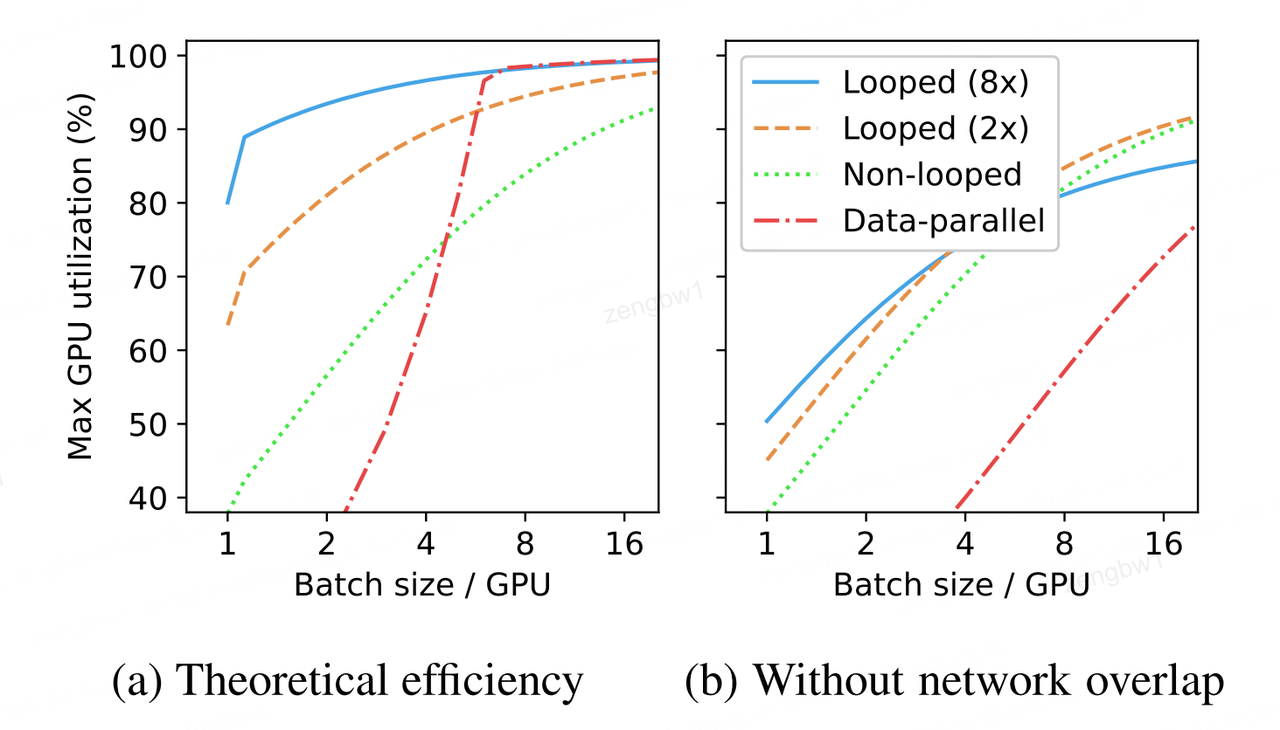
图2:(a)比较循环与非循环流水线及纯数据并行处理的理论效率随GPU批量大小变化的函数关系,以 βnet =6、NTP=1为例。注意 βmin =1附近与流水线-并行网络重叠相关的显著跃升。(b)相同配置下无数据与流水线网络重叠的理论效率,该图凸显了循环流水线中网络重叠的重新重要性。

图3:16层模型中标准层与环状层位置的对比。数字(及x轴)表示各层的索引。

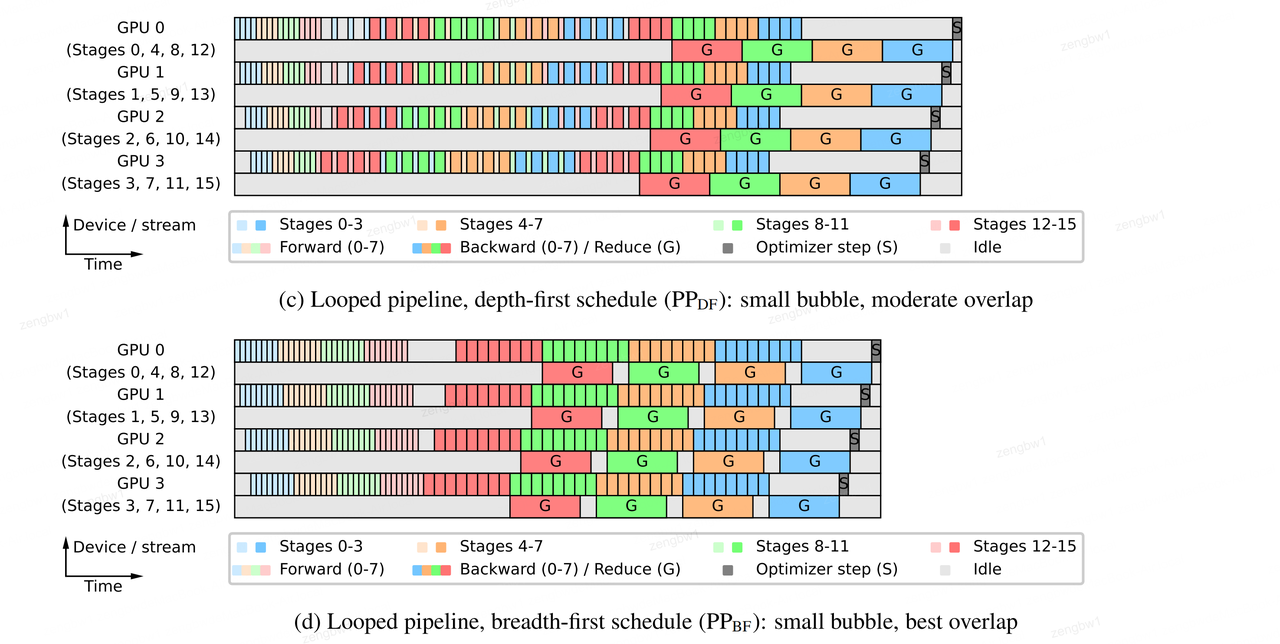
图4:本文对比分析了四种流水线调度方案(扩展时间),针对16层模型在4个流水线设备上运行,采用8个顺序微批次(编号0-7),并考虑数据并行性。图中同时展示了计算(偶数行)和数据并行通信(奇数行)的 CUDA 流并行运行情况(为简化起见,省略了流水线并行通信部分)。结果显示,循环调度方案的运行速度显著优于非循环方案,其中 PPBF 方案表现最佳。
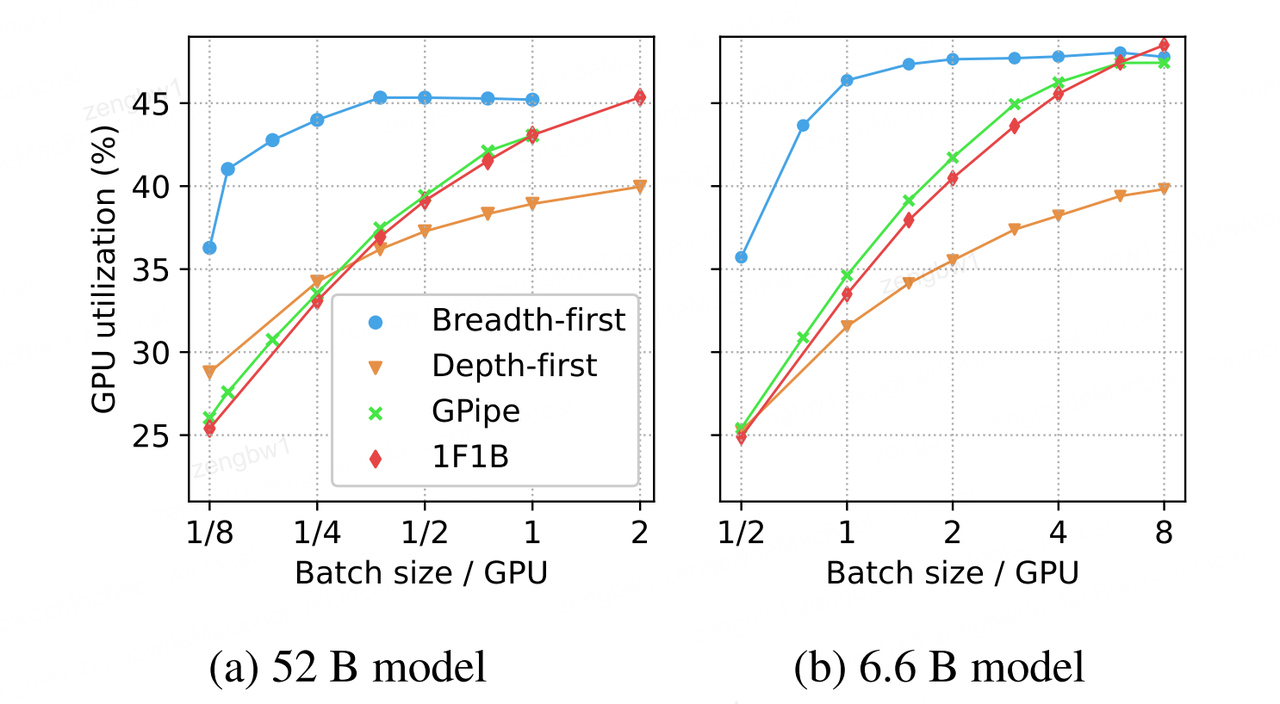
图5:循环调度(Nloop = 4)与非循环调度的GPU利用率随顺序微批次数(Smb = 1)变化的函数关系,分别对应(a) 52B模型(NPP = NTP = 8,NDP = 1)和(b) 6.6B模型(NPP = 4,NTP = 2,NDP = 8)。