transformer-XL论文源码难点记录
这篇论文我看了差不多快10天,555~主要我确实太菜了,代码也看不明白,花了好久的时间才勉强啃下来。
现在来记录一下看这篇论文的一些想法。
论文背景
这篇论文是基于 vanilla transformer语言模型提出来的,这个模型我没有看过,就不多说了。
transformerXL提出的重要原因是解决长距离依赖的问题,它的两个创新点也就是解决方法分别是: 状态复用的片段级递归和相对位置编码。用大白话说就是重复使用了前一片段的隐状态;在每一个注意力计算层加入相对位置来考虑位置因素。关于具体怎么复用和怎么加入,可以参考这位博主的文章(强力推荐,博主写得太清楚明白了,我也是看了他写的才明白很多地方):
链接 : https://blog.csdn.net/Magical_Bubble/article/details/89060213
接下来,我重点讲解一下我对于源代码的一些理解(个人菜鸟,不一定全对):
数据处理部分我就不说了。
跑通代码配置
首先:要跑通源码的话,需要注意进行以下配置:
数据处理部分我就不说了。
首先:要跑通源码的话,需要注意进行以下配置:
在算力上:租用了2080Ti 4个gpu 因为在网上查到的信息是30系列和40系列跑不了老版本的cuda和pytorch

此外别的什么下载相关数据集我就不赘述了,就按照作者的readme来就可以跑通,跑通这个代码我研究了好久,故记录一下。
别的配置我试过cuda11.3什么的都跑不通,而上面这个配置是我自己可以正常运行不报错的。
训练的话需要4个gpu或者更多,否则会报错(我自己租1个gpu训练报内存不够之类的错误),但是如果只是想跑几个batch看看模型的构造和数据的流转,只租1个gpu也可以。
代码核心部分解读
代码比较核心的部分是注意力的计算:源码和我自己跑代码时的注解如下:
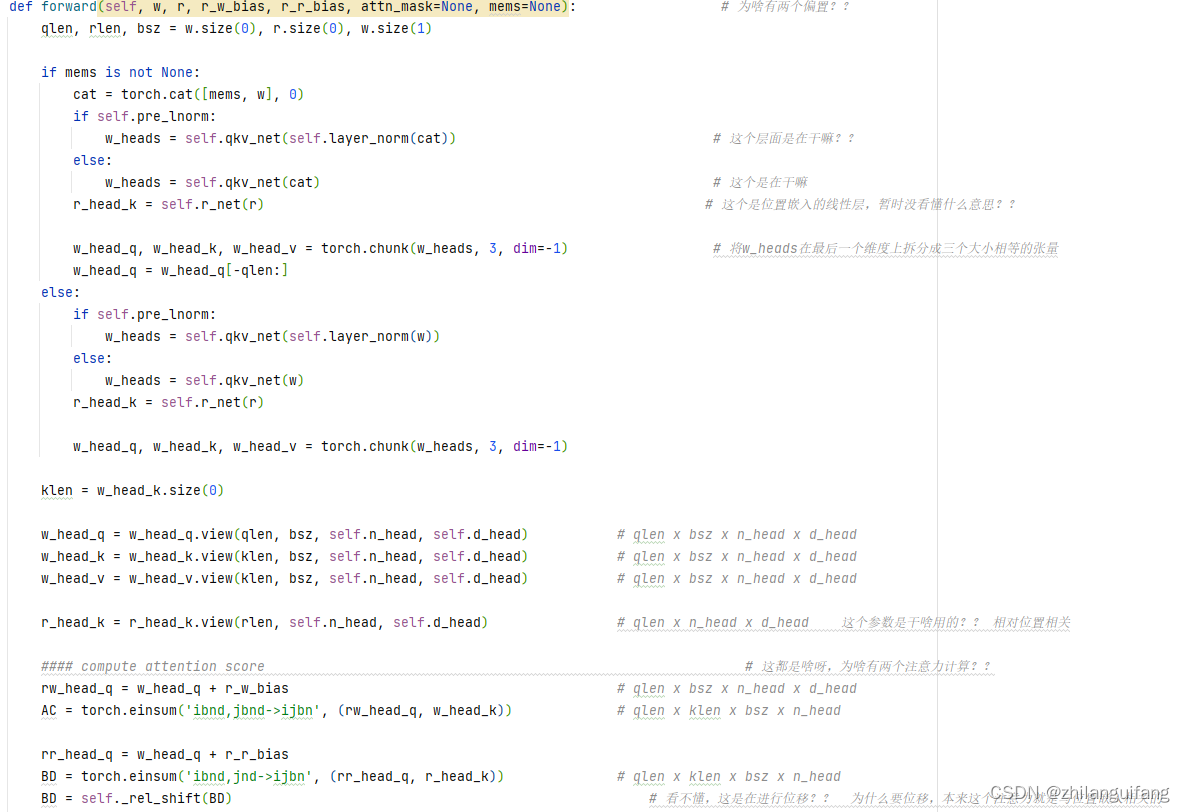 其中,我自己看了很久才明白的地方是AC和BD的计算,torch.einsum('ibnd,jbnd->ijbn',(rw_head_q,w_head_k))个人的理解是针对查询向量中的每一个向量对键向量中的每一个向量会计算一个注意力分数,这个分数跟batch_size,n都没有关系,所以bn保持不变,但是需要在d上进行求和(也就是每一个token的d个维度求和)。
其中,我自己看了很久才明白的地方是AC和BD的计算,torch.einsum('ibnd,jbnd->ijbn',(rw_head_q,w_head_k))个人的理解是针对查询向量中的每一个向量对键向量中的每一个向量会计算一个注意力分数,这个分数跟batch_size,n都没有关系,所以bn保持不变,但是需要在d上进行求和(也就是每一个token的d个维度求和)。
然后就是注意力掩码这里:

这里表示明天再写!!
注:个人理解,仅供参考,欢迎留言~