一、简介
官网:Apache Spark™ - Unified Engine for large-scale data analytics
Apache的顶级项目,用于大规模数据处理的统一分析引擎。
支持语言:Java、Scala、Python和R (源码为Scala)
高级工具:
1、SparkSQL用于SQL和结构化数据处理
2、提供Pandas API 可提供在 Apache Spark 上运行的、与 Pandas 等效的 API,从而填补这Pandas 不会横向扩展到大数据的空白
3、MLlib用于机器学习
4、GraphX用于图形处理, 和结构化流 用于增量计算和流处理
二、术语
|-----------------|-----------------------------------------------------------------------------------------------------------|
| Application | 基于Spark构建的用户程序。由集群上的驱动程序和执行程序组成 |
| Application jar | 包含用户的Spark应用程序的jar。在某些情况下,用户希望创建一个包含其应用程序及其依赖项的"uber jar"。用户的jar永远不应该包含Hadoop或Spark库,但是,这些库将在运行时添加。下·下·下· |
| Driver program | 运行应用程序main()函数并创建SparkContext的进程 |
| Cluster manager | 用于获取集群上资源的外部服务(例如独立管理器、Mesos、YARN) |
| Deploy mode | 区分驱动程序进程运行的位置。在"cluster"模式下,框架在集群内部启动驱动程序。在"client"模式下,提交者在集群外启动驱动程序。 |
| Worker node | 任何可以在集群中运行应用程序代码的节点 |
| Executor | 为工作节点上的应用程序启动的进程,该进程运行任务并将数据保存在内存或磁盘存储中。每个应用程序都有自己的执行器。 |
| Task | 将发送到一个执行器的工作单元 |
| Job | 由响应Spark操作而产生的多个任务组成的并行计算 (例如save、collect); |
| Stage | 每个作业被分成称为阶段的较小任务集,这些任务相互依赖(类似于MapReduce中的map和duce阶段); |
三、架构
我看下官方的架构图:

SparkContext 连接到 ClusterManager(可以是Spark自己的独立集群管理器、Mesos或YARN), ClusterManager在应用程序之间分配资源。一旦连接,Spark就会在集群中的WorkerNode上获取Executor,WorkerNode上会为应用程序启动一个可以计算和存储数据的进程,并把应用程序代码发送给Executor。最后,SparkContext将任务发送给Executor运行。
注意:
1、不同的应用程序之间要想共享数据必须写入外部存储系统
2、Driver program会一直监听Executor的执行情况
四、开发环境构建
选择File>New>Project

选择Maven,搜索scala,找到图中选中的模板

选择路径并填写项目名称

设置本地maven

修改pom.xml文件,添加对spark的支持,完整的pom.xml如下:
XML
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.study</groupId>
<artifactId>spark</artifactId>
<version>1.0-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.10.4</scala.version>
<spark.version>2.2.0</spark.version>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>同步maven
五、入门程序WordCount
1、数据制作

2、代码编写
Scala
package org.study
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//可以通过 SparkConf 为 Spark 绝大多数配置设置参数,且这些参数的优先级要高于系统属性
//注意:一旦 SparkConf 传递给 Spark 后,就无法再对其进行修改,因为Spark不支持运行时修改
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
//Spark 的主要入口点 SparkContext 表示到Spark集群的连接,用于在该集群上创建RDD、累加器、广播变量
//每个JVM只能有一个 SparkContext 处于活动状态
val sc = new SparkContext(conf)
//从HDFS、本地文件系统(在所有节点上都可用)或任何Hadoop支持的文件系统URI读取文本文件,并将其作为字符串的RDD返回。
val sourceRdd = sc.textFile("file/word_count_data.txt")
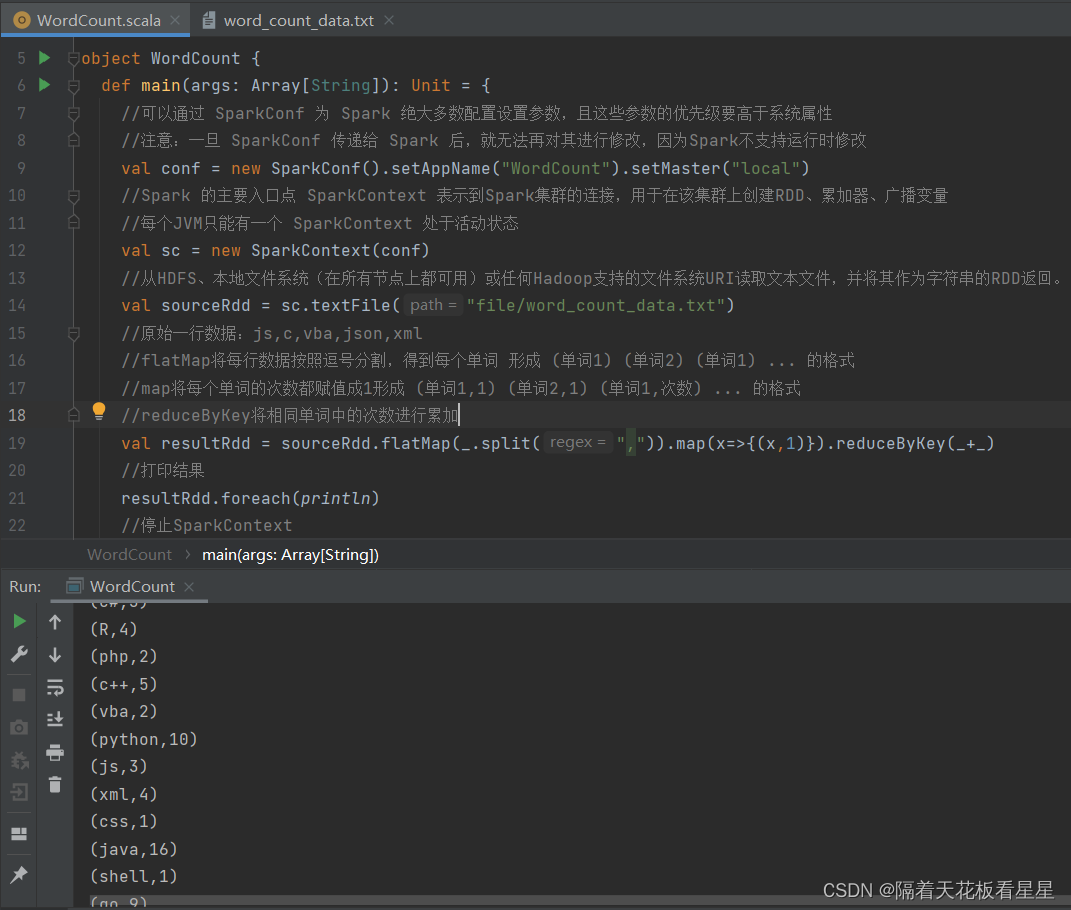
//原始一行数据:js,c,vba,json,xml
//flatMap将每行数据按照逗号分割,得到每个单词 形成 (单词1) (单词2) (单词1) ... 的格式
//map将每个单词的次数都赋值成1形成 (单词1,1) (单词2,1) (单词1,次数) ... 的格式
//reduceByKey将相同单词中的次数进行累加
val resultRdd = sourceRdd.flatMap(_.split(",")).map(x=>{(x,1)}).reduceByKey(_+_)
//打印结果
resultRdd.foreach(println)
//停止SparkContext
sc.stop()
}
}3、下载源码
4、本地运行
六、运行模式
1、本地运行
通过SparkConf的setMaster方法设置成local或者localn(表示本地起n个核跑任务)
一般用于本地开发调试程序
2、Standalone
Spark自带的任务调度模式(不常用)
3、Spark on Yarn (常用)
通过spark-submit 中的 --deploy-mode 指定,默认为client
a、client模式
Driver program 运行在执行spark-submit脚本的机器上,并接收集群上各个Executor的汇报,因此压力较大(本机挂了任务就失败了),但日志都会在本节点打印,适用于调试。
b、cluster模式
Driver program 运行在集群环境中,如果Driver程序挂了还可以利用Yarn的失败重试机制重新运行,且大大降低和Executor通信的网络开销。
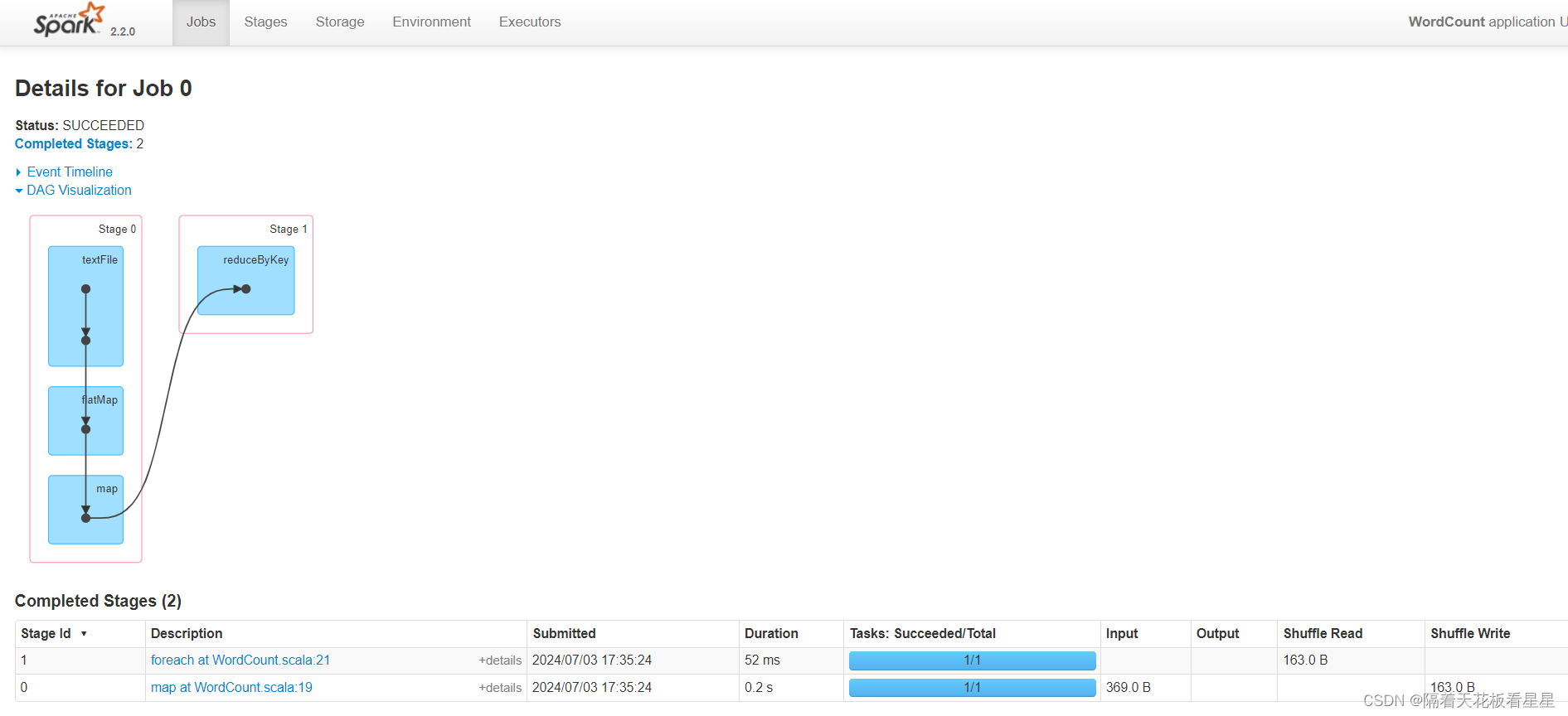
七、监控
默认情况下,每个SparkContext都会在端口4040上启动一个Web UI,该UI显示有关应用程序的有用信息。这包括:
1、Job、Stage、Task详细信息
2、RDD大小和内存使用情况摘要
3、环境信息
4、可视化的DAG
如果多个SparkContext在同一主机上运行,它们将绑定到连续的端口 从4040(4041、4042等)
注意: 此信息仅在应用程序期间可用。 若要在事后查看Web UI,请在启动之前将其(spark.eventLog.enabled )设置为true
启动历史服务器,默认端口为18080
./sbin/start-history-server.sh