爬虫目的
本文是想通过爬取拉勾网 Python相关岗位数据,简单梳理Requests和xpath的使用方法。
代码部分并没有做封装,数据请求也比较简单,所以该项目只是为了熟悉requests爬虫的基本原理,无法用于稳定的爬虫项目。
爬虫工具
这次使用Requests库发送http请求,然后用lxml.etree解析HTML文档对象,并使用xpath获取职位信息。
Requests简介
Requests是一款目前非常流行的http请求库,使用python编写,能非常方便的对网页Requests进行爬取。
官网里介绍说:Requests is an elegant and simple HTTP library for Python, built for human beings.
Requests优雅、简易,专为人类打造!
总而言之,Requests用起来简单顺手。
Requests库可以使用pip或者conda安装,本文python环境为py3.6。
试试对百度首页进行数据请求:
python
# 导入requests模块
import requests<br>
# 发出http请求
re = requests.get("https://www.baidu.com/")
# 查看响应状态
print(re.status_code)
# 查看url
print(re.url)
# 查看响应内容
print(re.text)
# 查看编码
print(re.encoding)
# 二进制响应内容
print(re.content)
# json响应内容
print(re.json)xpath简介
xpath 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
对获取的数据进行解析需要用到lxml库,lxml库是Python的一个解析库,支持HTML和XML的解析,支持XPath。
开始数据采集
1、请求地址:
https://www.lagou.com/zhaopin/Python/
2、需要爬取的内容
获取职位概况信息,包括:
- 职位名称
- 公司名称
- 公司简介
- 薪水
- 职位招聘对象
- 工作职责
- 工作要求
3、查看html
如果你使用chrome浏览器,登陆拉勾网,按F12可以进入开发者工具页面:
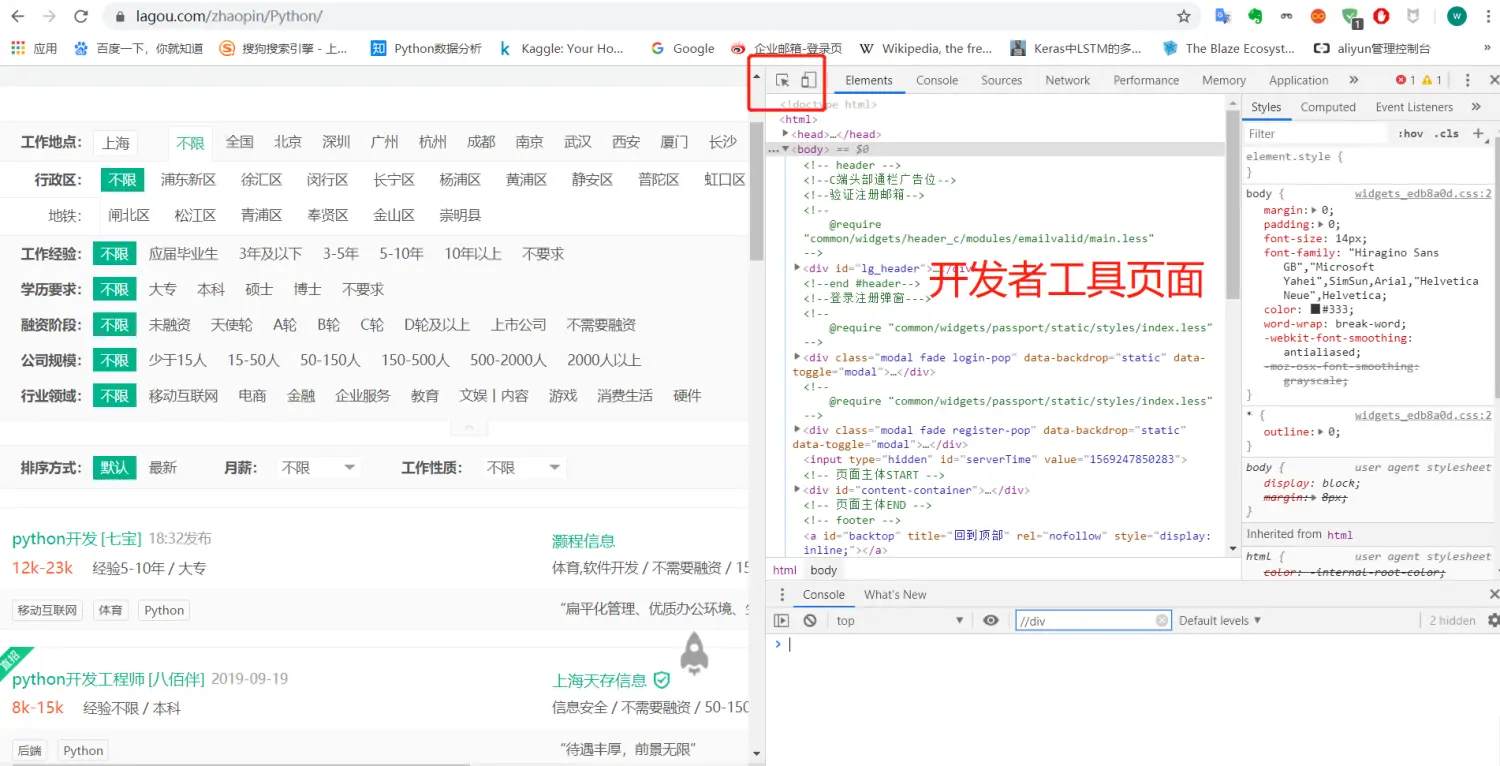
这时候你会看到该页面的html网页源码。
接下来需要寻找岗位信息对应的源码,比如说我想要获取职位名称:

你会看到开发者工具页面左上角有个箭头标志,你需要点击它,然后再点击岗位名称,就能看到对应的源码。
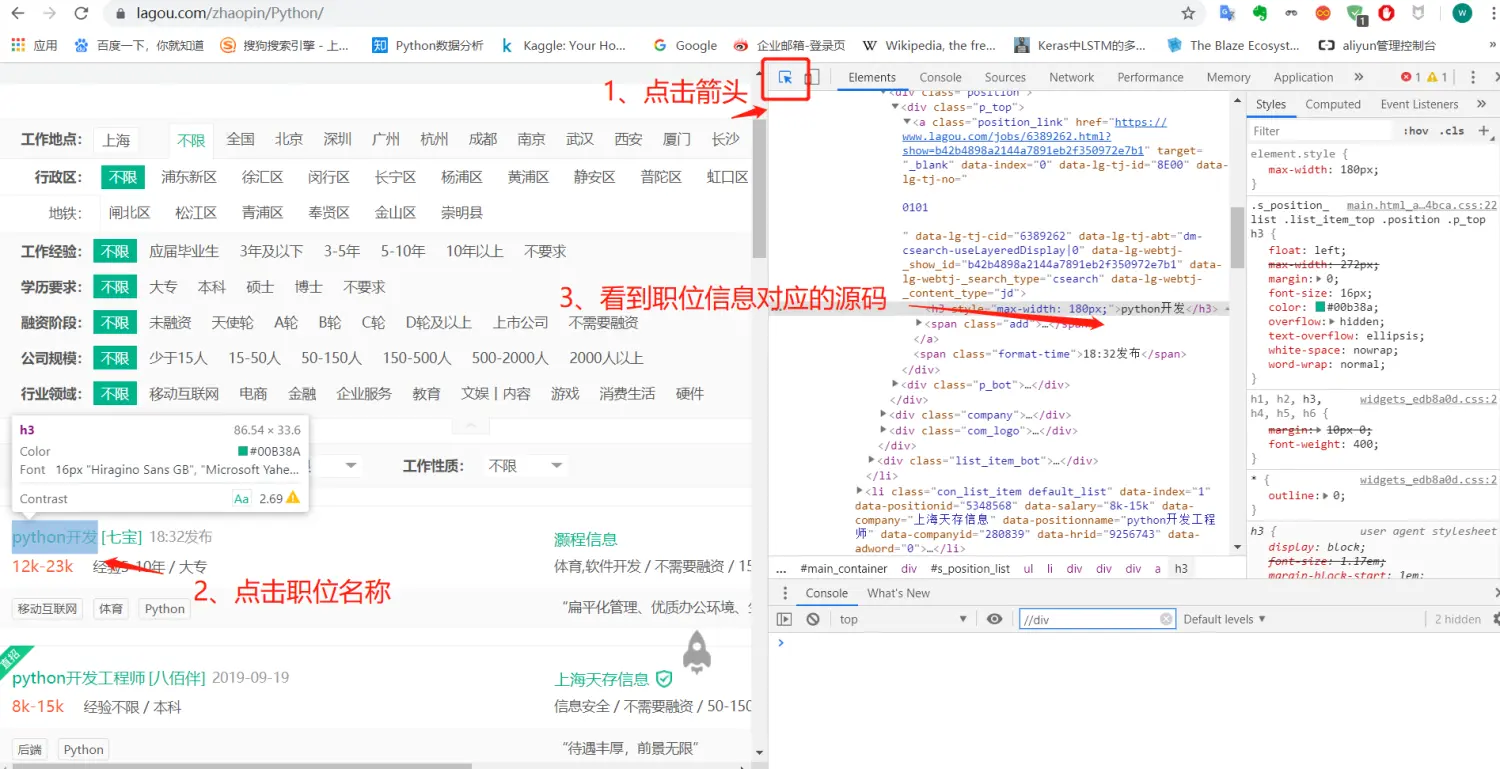
知道对应的源码后,我们就可以利用xpath提取里面的文本。
4、利用requests发出数据请求
python
# 请求头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36 Core/1.47.933.400 QQBrowser/9.4.8699.400',
}
# 发出数据请求,返回response响应对象
r = requests.get('https://www.lagou.com/zhaopin/Python/',headers=headers)
# 进行utf-8编码
r.encoding = "utf-8"5、利用xpath提取数据
python
# 构造一个xpath解析对象
selector = etree.HTML(r.text)
# 职位编号,一页共有14个职位,所以这里可以传递0~13任意数字
row_num = str(0)
'''获取职位概况信息,包括:职位名称、公司名称、公司简介、薪水、职位招聘对象'''
# p_name 职位名称
p_name = selector.xpath('//ul[@class="item_con_list"]/li[@data-index={}]//h3/text()'.format(row_num))[0]
# p_company 招聘公司名称
p_company = selector.xpath('//ul[@class="item_con_list"]/li[@data-index={}]//div[@class="company_name"]/a/text()'.format(row_num))[0]
# p_industry 招聘公司简介
p_industry = selector.xpath('//ul[@class="item_con_list"]/li[@data-index={}]//div[@class="industry"]/text()'.format(row_num))[0]
# p_money 职位薪资
p_money = selector.xpath('//ul[@class="item_con_list"]/li[@data-index={}]//span[@class="money"]/text()'.format(row_num))[0]
# p_require 职位招聘对象
p_require = selector.xpath('//ul[@class="item_con_list"]/li[@data-index={}]//div[@class="li_b_l"]/text()'.format(row_num))[2]
# 该职位详细信息跳转链接
p_href = selector.xpath('//ul[@class="item_con_list"]/li[@data-index={}]//a[@class="position_link"]/@href'.format(row_num))[0]岗位职责和要求的信息在另外的网页,所以要先获取对应网址,再进行数据请求。
python
''' 获取工作职责和工作要求等详细信息'''
# 返回response响应对象
r_detail = requests.get(p_href,headers=headers)
# 进行utf-8编码
r_detail.encoding = "utf-8"
# 解析HTML对象
selector_detail = etree.HTML(r_detail.text)
# p_detail 工作职责和工作要求信息
p_detail = selector_detail.xpath('//div[@class="job-detail"]/p//text()')将所有信息放进列表并打印:
python
'''将获取到的有效信息放到列表中'''
p_list = [p_name, p_company, p_industry.strip(), p_money, p_require.strip(),"\n ".join(p_detail)]
for i in p_list:
print(i)输出:

总结
本文使用requests和xpath工具对拉勾网python职位数据进行爬取并解析,旨在了解requests和xpath的使用方法。
对于想翻页爬取所有岗位信息,本文并无介绍。有兴趣的童鞋可以更改地址参数,对代码进行动态包装,尝试爬取所有python岗位信息。
最后,推荐一款不错的自动化爬虫工具-亮数据。
亮数据平台提供了强大的数据采集工具,比如Web Scraper IDE、亮数据浏览器、SERP API等,能够自动化地从网站上抓取所需数据,无需分析目标平台的接口,直接使用亮数据提供的方案即可安全稳定地获取数据。
网站:https://get.brightdata.com/weijun
亮数据浏览器支持对多个网页进行批量数据抓取,适用于需要JavaScript渲染的页面或需要进行网页交互的场景。

另外,亮数据浏览器内置了自动网站解锁功能,能够应对各种反爬虫机制,确保数据的顺利抓取。它能兼容多种自动化工具,如Puppeteer、Playwright和Selenium等,用户可以根据需求选择合适的工具进行数据抓取。