深度学习简介
深度学习简介
深度学习例子
猜数字
A: 我现在心里想了一个0-100之间的整数,你猜一下?
B: 60。
A: 低了。
B:80。
A:低了。
B:90。
A:高了
B:88。
A:对了
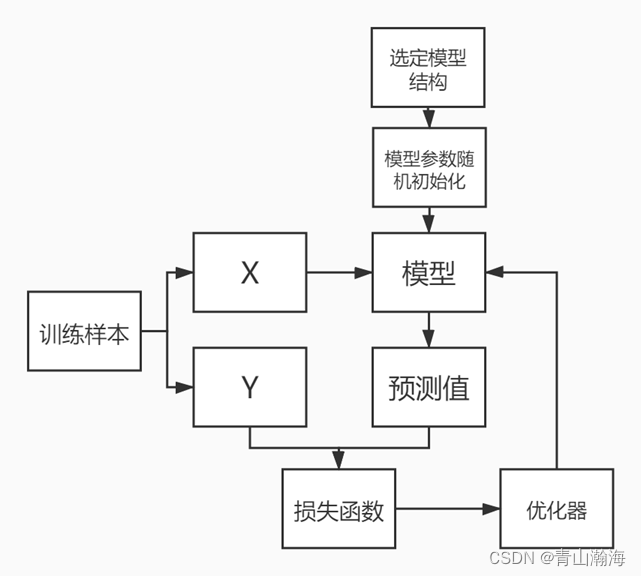
我们可以通过这个典型的例子来学习深度学习的思想。上面的过程中,可以把B当成我们的模型 ,A心里面想的数字 ,是我们想要模型预测的内容。整个过程就是我们训练模型如何快速的预测数字的过程,1-100中,我们猜测的数据就是我们的样本。
备注:一般的样本中,应该是输入和输出1对1的;这里我们可以理解为输入就是1-100的任意一个数,任何都可以,我这里假设输入为100,比较好计算
深度学习过程-拆解:
1.B 随机预测一个数
--模型随机初始化的参数进行输出选择一个模型(函数作为猜的方法)为:
Y = k*X 此时这个样本就是(1-100的数)第一次输出为为60 ,X输入为100,k初始化为0.6
2.计算模型猜出的数字与真正的答案的差距
---计算loss,就是预测和真实值的差距,计算loss的公式叫损失函数=sign(y_true-y_pred)3.根据loss,就可以告诉B是偏大还是偏小
---模型得到loss信息4.B根据获得信息调整自己的预测方案,就是K值
---反向传播5.B中的K可以预先设定调整的幅度大小,比如偏大,则k减小0.1,偏小则k加0.1
---调整的东西叫优化器,调整的幅度大小就是学习率6反复重复上述1-5;直到预测和真实值的差距 loss小于我们预设的值,则停止
--模型训练的轮数
释义: 上述的整个过程,就是深度学习训练模型的过程,就是找到模型(y=kx)中,k取什么值,可以满足xk得到B心中想要的数字。当然咱们这个例子中,这个k不是固定的,一个真实的完整训练模型,最后肯定是为了得到一共固定的k值,在这里只是举例说明。
深度学习训练优化
从猜数字的过程,可以类比为一个模型训练的过程,那么我们的目的是尽快训练出一个满足我们任务的模型,我们可以从以下部分考虑取优化:
1.随机初始化
如果B一开始初始化的值k就是88,那么我们就直接得到正确的模型了
所以
我们根据经验初始化一个值,一定程度上可以帮助计算机更快的找到正确的k。
NLP中预训练模型实际上计算对随机初始化的技术优化
2.优化损失函数
如果: A不是告诉B偏大还是偏小,而是直接告诉它还差多少,那么B就能很快的得到一个正确的k
所以我们可以选择一个好的损失函数,或者计算损失值时,我们可以给到模型准确的值
3.优化器选择
上述的例子中,如果我们采用2分法去预测数据:
50-->75-->88....这样去设置我们预测参数的策略,无疑会更快的找到正确的k
4.选择/调整模型结构
上面我们选择的模型是y=k*x,我们知道这是一条直线;那如果我们预测的规律不是直线,那么不管我们怎么调整,
都无法很好的预测结果,这就和我们选择的模型有关
示例:就像一个只有文科天赋的学生,让他去研究数学一样,即时他已经很努力了,但是效果却差强人意
深度学习常见概念
深度学习中的神经网络是一种拟人化的说法,是为了我们便于理解,本质上就是一系列数学公式。
隐含层/中间层
释义: 神经网络模型输入层和输出层之间的部分
隐含层可以有不同的结构,如下面一些著名的网络结构:
RNN
CNN
DNN
LSTM
Transformer
...上述的网络本质上区别,就是数学公式不同的而已。
随机初始化
释义: 较大的模型,隐含层会包含很多的权重矩阵,这些矩阵需要有初始值,才能开始进行计算。
注意
- 初始值的选择会影响最终训练模型的结果
- 一般情况下,初始值随机初始化也是在一定范围内进行的
- 使用预训练模型时,初始值是提前被训练好的参数
损失函数
释义 :用来计算模型的预测值和真实值之间的差距。
备注
- 损失函数的价值是让我们知道,当前离目标还有多大的差距,这个计算是通过预测值和目标值来计算的。
示例:就像考试,是让我们知道距离想要完全掌握知识还差多少 - 损失函数有很多,需要选择合理的损失函数才能训练出想要的模型。
示例:就像我们想要学好数学,那么就要做数学卷子,我们才知道还差多少
导数与梯度
释义: 导数表示函数曲线的切线斜率,即在该函数值点上的变化率。

作用: 导数可以告诉我们值得变化是增大还是减小;想想我们需要求预测值和真实值之间得差距loss;那么在这里记住,y、x都是输入得值,实际得函数是k和loss之间得关系;现在我们需要找到k得值,使得loss最小;那么是不是要对k在这个预测值得位置求导数,这样我们就知道,k该增大还是减小,才能使loss减小了。
梯度释义: 梯度通常就相当于函数在某个数据导数,由于人工智能计算通常使用向量,所以实际就是函数某一点的方向向量,有方向并且梯度的方向是该点增长最快的点,所以梯度的反方向就是减小最快的点。
所以需要梯度下降: 梯度下降得目的是找到函数得极小值
优化器
释义: 上面例子中调整预测数据大小的整个动作就是人工智能中的优化器。他的作用就是运用一定的调整策略,使得能够较好的找到一个适合的点,使得模型预测准确
相关概念: 学习率(learning rate)就是调整k的幅度大小
动量(Momentum)动量可以理解成物理中的惯性;目的是为了降低模型微调中,脏数据的影响。(即计算梯度方向会和之前的比较,如果完全相反,会继续向之前的方向前进一下步,如果方向相同,会适当的调大学习率)
Mini Batch/epoch
Batch释义: 简单理解就是一次性加入多个训练的语料,进行训练后,将他们梯度综合进行处理;这是避免,单条数据进行训练,梯度一会上一会下,导致最终训练没有办法拟合整体的数据规律。
Mini Batch释义: 但一次也不能太多数据一起训练,数据过多会导致需要的硬件设备太大,计算也较慢;预算成本达不到。
epoch: 是指将完整的训练数据训练完一次。因为在实际的训练中,训练集数据,不是指训练一次;会根据loss来控制或者是指定训练的轮,即epoch数
深度学习训练逻辑图