contents
-
- 前言
- [第1章 事件与概率](#第1章 事件与概率)
-
- [1.1 随机事件与样本空间](#1.1 随机事件与样本空间)
-
- [1.1.1 样本空间](#1.1.1 样本空间)
- [1.1.2 随机事件](#1.1.2 随机事件)
- [1.1.3 事件之间的关系与运算](#1.1.3 事件之间的关系与运算)
- [1.2 概率的三种定义及其性质](#1.2 概率的三种定义及其性质)
-
- [1.2.1 概率的统计定义](#1.2.1 概率的统计定义)
- [1.2.2 概率的古典定义](#1.2.2 概率的古典定义)
- [1.2.3 概率的几何定义](#1.2.3 概率的几何定义)
- [1.2.4 概率的性质](#1.2.4 概率的性质)
- [1.3 常用概型公式](#1.3 常用概型公式)
-
- [1.3.1 条件概率计算公式](#1.3.1 条件概率计算公式)
- [1.3.2 乘法原理计算公式](#1.3.2 乘法原理计算公式)
- [1.3.3 全概公式](#1.3.3 全概公式)
- [1.3.4 贝叶斯公式](#1.3.4 贝叶斯公式)
- [1.4 事件的独立性及伯努利概型](#1.4 事件的独立性及伯努利概型)
-
- [1.4.1 独立性](#1.4.1 独立性)
- [1.4.2 伯努利概型](#1.4.2 伯努利概型)
- [第2章 随机事件及其分布](#第2章 随机事件及其分布)
-
- [2.1 随机变量及其概率分布](#2.1 随机变量及其概率分布)
-
- [2.1.1 随机变量的概念](#2.1.1 随机变量的概念)
- [2.1.2 随机变量的分布函数](#2.1.2 随机变量的分布函数)
- [2.2 离散型随机变量及其分布列](#2.2 离散型随机变量及其分布列)
-
- [2.2.1 离散性随机变量的分布列](#2.2.1 离散性随机变量的分布列)
- [2.2.2 常用离散性随机变量及其分布列](#2.2.2 常用离散性随机变量及其分布列)
- [2.3 连续型随机变量及其概率密度函数](#2.3 连续型随机变量及其概率密度函数)
-
- [2.3.1 连续型随机变量的密度函数](#2.3.1 连续型随机变量的密度函数)
- [2.3.2 常用连续型随机变量及其密度函数](#2.3.2 常用连续型随机变量及其密度函数)
- [2.4 随机变量函数的分布](#2.4 随机变量函数的分布)
-
- [2.4.1 离散型随机变量函数的分布](#2.4.1 离散型随机变量函数的分布)
- [2.4.2 连续型随机变量函数的分布](#2.4.2 连续型随机变量函数的分布)
- [第3章 随机向量及其分布](#第3章 随机向量及其分布)
-
- [3.1 二维随机向量的联合分布](#3.1 二维随机向量的联合分布)
-
- [3.1.1 联合分布函数](#3.1.1 联合分布函数)
- [3.1.2 联合分布列](#3.1.2 联合分布列)
- [3.1.3 联合密度函数](#3.1.3 联合密度函数)
- [3.2 二维随机向量的边缘分布](#3.2 二维随机向量的边缘分布)
-
- [3.2.1 边缘分布函数](#3.2.1 边缘分布函数)
- [3.2.2 边缘分布列](#3.2.2 边缘分布列)
- [3.2.3 边缘密度函数](#3.2.3 边缘密度函数)
- [3.3 随机向量的条件分布](#3.3 随机向量的条件分布)
-
- [3.3.1 离散型随机向量的条件分布列和条件分布函数](#3.3.1 离散型随机向量的条件分布列和条件分布函数)
- [3.3.2 连续型随机向量的条件密度函数和条件分布函数](#3.3.2 连续型随机向量的条件密度函数和条件分布函数)
- [3.4 随机变量的独立性](#3.4 随机变量的独立性)
- [3.5 随机向量函数的分布](#3.5 随机向量函数的分布)
-
- [3.5.1 离散型随机向量函数的分布](#3.5.1 离散型随机向量函数的分布)
- [3.5.2 连续型随机向量函数的分布](#3.5.2 连续型随机向量函数的分布)
- [第4章 随机变量的数字特征](#第4章 随机变量的数字特征)
-
- [4.1 数学期望](#4.1 数学期望)
-
- [4.1.1 随机变量的数学期望](#4.1.1 随机变量的数学期望)
- [4.1.2 随机变量函数的数学期望](#4.1.2 随机变量函数的数学期望)
- [4.1.3 数学期望的性质](#4.1.3 数学期望的性质)
- [4.2 方差](#4.2 方差)
-
- [4.2.1 方差的定义](#4.2.1 方差的定义)
- [4.2.2 方差的性质](#4.2.2 方差的性质)
- [4.3 结论与推导(补)](#4.3 结论与推导(补))
- [4.4 协方差与相关系数](#4.4 协方差与相关系数)
-
- [4.4.1 协方差](#4.4.1 协方差)
- [4.4.2 相关系数](#4.4.2 相关系数)
- [4.4.3 独立性与线性相关性(补)](#4.4.3 独立性与线性相关性(补))
前言
更好的阅读体验:https://blog.dwj601.cn/GPA/4th-term/ProbAndStat/
笔记范围:一至四章。五至八章请跳转:https://blog.csdn.net/qq_73408594/article/details/140190576
教材情况:
| 课程名称 | 选用教材 | 版次 | 作者 | 出版社 | ISBN号 |
|---|---|---|---|---|---|
| 概率论与数理统计Ⅰ | 概率论与数理统计 | 第一版 | 刘国祥王晓谦 等主编 | 科学出版社 | 978-7-03-038317-4 |
学习资源:
第1章 事件与概率
1.1 随机事件与样本空间
1.1.1 样本空间
随机事件发生的总集合 Ω \Omega Ω
1.1.2 随机事件
事件是否发生取决于观察结果的事件
1.1.3 事件之间的关系与运算
- 包含: A ⊂ B A \subset B A⊂B or B ⊂ A B \subset A B⊂A
- 相等: A = B A=B A=B
- 并(和): A ∪ B A \cup B A∪B
- 交(积): A ∩ B ( A B ) A \cap B \quad (AB) A∩B(AB)
- 互斥 (互不相容): A B = Φ AB=\Phi AB=Φ
- 对立事件 (余事件): A ∩ B = Φ ∧ A ∪ B = Ω A \cap B=\Phi \land A \cup B=\Omega A∩B=Φ∧A∪B=Ω
- 差: A − B = A ∩ B ‾ = A B ‾ A-B=A \cap \overline{B} = A \overline B A−B=A∩B=AB
- 德摩根律
将事件发生的概率论转化为集合论进行计算与分析
1.2 概率的三种定义及其性质
1.2.1 概率的统计定义
从频率出发得到。
1.2.2 概率的古典定义
特征:
- 样本空间是有限集
- 等可能性(试验中每个基本事件发生的概率是等可能的)
内容:
- 模型与计算公式
- 基本组合分析公式
- 乘法、加法原理
- 排列公式
- 组合公式
- 实例
- 超几何概率
- 分房问题
- 生日问题
- 古典概率的基本性质
1.2.3 概率的几何定义
特征:
- 样本空间不可列
- 等可能性
内容:
- 模型与计算公式
- 实例
- 一维几何图形:公交车乘车问题
- 二维几何图形:会面问题、蒲丰(Buffon)投针问题
- 几何概率的基本性质
1.2.4 概率的性质
pass
1.3 常用概型公式
1.3.1 条件概率计算公式
P ( B ∣ A ) = P ( A B ) P ( A ) P(B|A) = \frac{P(AB)}{P(A)} P(B∣A)=P(A)P(AB)
1.3.2 乘法原理计算公式
-
基本 : 前提 : P ( A ) > 0 \text{基本}:\text{前提}:P(A)>0 基本:前提:P(A)>0
P ( A B ) = P ( A ) P ( B ∣ A ) P(AB) = P(A)P(B|A) P(AB)=P(A)P(B∣A) -
推广 : 前提 : P ( A 1 A 2 , . . . , A n ) > 0 \text{推广}:\text{前提}:P(A_1A_2,...,A_n)>0 推广:前提:P(A1A2,...,An)>0
P ( A 1 A 2 . . . A n ) = P ( A 1 ) P ( A 2 ∣ A 1 ) P ( A 3 ∣ A 1 A 2 ) ⋯ P ( A n ∣ A 1 A 2 . . . A n − 1 ) P(A_1A_2...A_n) = P(A_1)P(A_2|A_1)P(A_3|A_1A_2) \cdots P(A_n|A_1A_2...A_{n-1}) P(A1A2...An)=P(A1)P(A2∣A1)P(A3∣A1A2)⋯P(An∣A1A2...An−1)
1.3.3 全概公式
我们将样本空间 Ω \Omega Ω 完全划分为 n n n 个互斥的区域,即 Ω = ∑ i = 1 n A i \Omega = \displaystyle \sum_{i=1}^{n} A_i Ω=i=1∑nAi ,则在样本空间中事件 B B B 发生的概率 P ( B ) P(B) P(B) 就是在各子样本空间中概率之和,经过上述乘法公式变形,计算公式如下:
P ( B ) = P ( B Ω ) = P ( B A 1 ) + P ( B A 2 ) + ⋯ + P ( B A n ) = P ( A 1 ) P ( B ∣ A 1 ) + P ( A 2 ) P ( B ∣ A 2 ) + ⋯ + P ( A n ) P ( B ∣ A n ) = ∑ i = 1 n P ( A i ) P ( B ∣ A i ) \begin{equation*} \begin{aligned} P(B) &= P(B \Omega) \\ &= P(BA_1) + P(BA_2) + \cdots + P(BA_n) \\ &= P(A_1)P(B|A_1) + P(A_2)P(B|A_2) + \cdots + P(A_n)P(B|A_n) \\ &= \sum_{i=1}^n P(A_i)P(B|A_i) \end{aligned} \end{equation*} P(B)=P(BΩ)=P(BA1)+P(BA2)+⋯+P(BAn)=P(A1)P(B∣A1)+P(A2)P(B∣A2)+⋯+P(An)P(B∣An)=i=1∑nP(Ai)P(B∣Ai)
1.3.4 贝叶斯公式
在上述全概公式的背景之下,现在希望求解事件 B B B 在第 j j j 个子样本空间 A j A_j Aj 中发生的概率,或者说第 j j j 个子样本空间对于事件 B B B 的发生贡献了多少概率,记作 P ( A j ∣ B ) P(A_j|B) P(Aj∣B) ,计算公式如下:
P ( A j ∣ B ) = P ( A j ) P ( B ∣ A j ) ∑ i = 1 n P ( A i ) P ( B ∣ A i ) P(A_j|B) = \frac{P(A_j)P(B|A_j)}{\displaystyle \sum_{i=1}^n P(A_i)P(B|A_i)} P(Aj∣B)=i=1∑nP(Ai)P(B∣Ai)P(Aj)P(B∣Aj)
{% note light %}
可以发现全概公式是计算事件发生的所有子样本空间的概率贡献,而贝叶斯公式是计算事件发生的总概率中某些子样本空间的概率贡献,前者是正向思维,后者是逆向思维
{% endnote %}
1.4 事件的独立性及伯努利概型
1.4.1 独立性
定义
-
基本:若 A , B A,B A,B 相互独立,则满足:
P ( A B ) = P ( A ) P ( B ) P(AB)=P(A)P(B) P(AB)=P(A)P(B) -
推广:若 A 1 , A 2 , . . . , A n A_1,A_2,...,A_n A1,A2,...,An 相互独立,则满足:
∀ 1 ≤ i 1 < i 2 < ⋯ < i k ≤ n ( k = 2 , 3 , ⋯ , n ) s . t . P ( A i 1 A i 2 ⋯ A i k ) = P ( A i 1 ) P ( A i 2 ) ⋯ P ( A i k ) \begin{aligned} \forall \quad 1 \le i_1<i_2<\cdots<i_k \le n\ (k=2,3,\cdots,n) \\ s.t. \quad P(A_{i_1}A_{i_2}\cdots A_{i_k}) = P(A_{i_1})P(A_{i_2})\cdots P(A_{i_k}) \end{aligned} ∀1≤i1<i2<⋯<ik≤n (k=2,3,⋯,n)s.t.P(Ai1Ai2⋯Aik)=P(Ai1)P(Ai2)⋯P(Aik)
定理
-
基本:若 A , B A,B A,B 相互独立,则 A , B ‾ A,\overline{B} A,B 相互独立; A ‾ , B \overline{A},B A,B 相互独立; A ‾ , B ‾ \overline{A},\overline{B} A,B 相互独立
-
推广:若 A 1 , A 2 , . . . , A n A_1,A_2,...,A_n A1,A2,...,An 相互独立,则其中任意 k ( 2 ≤ k ≤ n ) k(2 \le k \le n) k(2≤k≤n) 个也相互独立,且满足:
P ( A i 1 ^ A i 2 ^ ⋯ A i k ^ ) = P ( A i 1 ^ ) P ( A i 2 ^ ) ⋯ P ( A i k ^ ) s . t . A i j ^ = A o r A ‾ ( j = 1 , 2 , ⋯ , k ) \begin{aligned} P(\hat{A_{i_1}}\hat{A_{i_2}}\cdots \hat{A_{i_k}}) = P(\hat{A_{i_1}})P(\hat{A_{i_2}})\cdots P(\hat{A_{i_k}}) \\ s.t. \quad \hat{A_{i_j}} = A \ or \ \overline{A}\ (j=1,2,\cdots,k) \end{aligned} P(Ai1^Ai2^⋯Aik^)=P(Ai1^)P(Ai2^)⋯P(Aik^)s.t.Aij^=A or A (j=1,2,⋯,k)
概念辨析
-
两两独立:对于 n n n 个事件,两两独立,而不考虑三个及以上的关系。
-
相互独立:对于 n n n 个事件, 2 → n 2 \to n 2→n 个事件的独立关系都需要考虑。
-
总结:对于 n n n 个事件,满足两两独立需要 C n 2 C_n^2 Cn2 个等式关系,对于相互独立需要 2 n − ( n + 1 ) 2^n-(n+1) 2n−(n+1) 个等式关系,因此:
两两独立 ⊂ 相互独立 \text{两两独立} \subset \text{相互独立} 两两独立⊂相互独立
1.4.2 伯努利概型
定义: n n n 重伯努利概型
- n n n 重:发生 n n n 次独立试验
- 伯努利概型:每次试验只有两种可能的结果
模型:
-
二项概率公式:n 次独立重复试验发生 k 次的概率:
C n k p k ( 1 − p ) n − k C_n^k p^k (1-p)^{n-k} Cnkpk(1−p)n−k -
几何概率公式:在第 n 次试验首次成功的概率:
( 1 − p ) n − 1 p (1-p)^{n-1}p (1−p)n−1p
第2章 随机事件及其分布
{% note light %}
我们知道,解决事件发生概率的问题,除了事件表示以外,我们还关心每一个事件发生的概率 P ( X = k ) P(X=k) P(X=k),以及某些事件发生的概率 P ( X = [ r a n g e ) ) P(X=[range)) P(X=[range))。接下来我们将:
- 首先介绍随机变量的概念 以及分布函数的概念
- 接着介绍随机变量对应的概率发生情况组成的集合。离散型的叫分布列 ,连续型的叫概率密度函数,并在其中贯穿分布函数的应用
- 最后介绍分布函数的复合。从离散型和连续型随机变量两个方向展开
{% endnote %}
2.1 随机变量及其概率分布
2.1.1 随机变量的概念
总的来说,随机变量就是一个样本空间与实数集的映射。我们定义样本空间 Ω = { ω } \Omega=\{ \omega \} Ω={ω},其中 ω \omega ω 表示所有可能的事件,实数集 R R R,随机变量 X X X,则随机变量满足以下映射关系
X ( ω ) = R X(\omega)=R X(ω)=R
2.1.2 随机变量的分布函数
- 分布函数的定义: F ( x ) = P ( X ≤ x ) F(x)=P(X \le x) F(x)=P(X≤x)
- 分布函数的性质:
- 非负有界性: 0 ≤ F ( x ) ≤ 1 0 \le F(x) \le 1 0≤F(x)≤1
- 单调不减性:若 x 1 < x 2 x_1 < x_2 x1<x2,则 F ( x 1 ) ≤ F ( x 2 ) F(x_1) \le F(x_2) F(x1)≤F(x2)
- F ( − ∞ ) = lim x → − ∞ F ( x ) = 0 \displaystyle F(-\infty) = \lim_{x \to -\infty} F(x) = 0 F(−∞)=x→−∞limF(x)=0, F ( + ∞ ) = lim x → + ∞ F ( x ) = 1 \displaystyle F(+\infty) = \lim_{x \to +\infty} F(x) = 1 F(+∞)=x→+∞limF(x)=1
- 右连续性: lim x → x 0 + F ( x ) = F ( x 0 ) ( − ∞ < x 0 < + ∞ ) \displaystyle \lim_{x\to x_0^+}F(x) = F(x_0)\quad(-\infty < x_0 < +\infty) x→x0+limF(x)=F(x0)(−∞<x0<+∞)
2.2 离散型随机变量及其分布列
2.2.1 离散性随机变量的分布列
随机变量的取值都是整数,有以下三种表示方法
-
公式法
p k = P ( X = x k ) , k = 1 , 2 , ⋯ , p_k = P(X=x_k),\quad k = 1,2,\cdots, pk=P(X=xk),k=1,2,⋯, -
服从法
X ∼ ( x 1 x 2 x 3 ⋯ p 1 p 2 p 3 ⋯ ) X \sim \begin{pmatrix} x_1 & x_2 & x_3 & \cdots \\ p_1 & p_2 & p_3 & \cdots \end{pmatrix} X∼(x1p1x2p2x3p3⋯⋯) -
表格法
X x 1 x 2 x 3 ⋯ P p 1 p 2 p 3 ⋯ \begin{array}{c|cccc} X & x_1 & x_2 & x_3 & \cdots \\ \hline P & p_1 & p_2 & p_3 & \cdots \end{array} XPx1p1x2p2x3p3⋯⋯
2.2.2 常用离散性随机变量及其分布列
-
0-1分布:即一个事件只有两面性,我们称这样的随机变量服从0-1分布或者两点分布,记作
X ∼ ( 0 1 1 − p p ) X \sim \begin{pmatrix} 0 & 1 \\ 1-p & p \end{pmatrix} X∼(01−p1p) -
二项分布:其实就是 n 重伯努利试验,我们称这样的随机变量服从二项分布,分布列为 P ( X = k ) = C n k p k ( 1 − p ) n − k P(X=k) = C_n^kp^k(1-p)^{n-k} P(X=k)=Cnkpk(1−p)n−k,记作
X ∼ B ( n , p ) X \sim B(n,p) X∼B(n,p) -
几何分布:同样是伯努利事件,现在需要求解第 k k k 次事件首次发生的概率,此时分布列为 P ( X = k ) = ( 1 − p ) k − 1 p P(X=k)=(1-p)^{k-1}p P(X=k)=(1−p)k−1p,记作
X ∼ G ( p ) X \sim G(p) X∼G(p) -
超几何分布:就是在 N 件含有 M 件次品的样品中无放回的抽取 n 件,问其中含有次品数量的分布列,为 P ( X = k ) = C M k C N − M n − k C N n , k = 0 , 1 , 2 , ⋯ , min ( n , M ) \displaystyle P(X=k)=\frac{C_M^k C_{N-M}^{n-k}}{C_N^n}, \quad k=0,1,2,\cdots,\min{(n, M)} P(X=k)=CNnCMkCN−Mn−k,k=0,1,2,⋯,min(n,M),记作
X ∼ 超几何分布 ( n , N , M ) X \sim \text{超几何分布}(n,N,M) X∼超几何分布(n,N,M) -
泊松分布:当二项分布中,试验次数很大或者概率很小时,可以近似为泊松分布,即 P ( X = k ) = C n k p k ( 1 − p ) n − k → λ k k ! e − λ \displaystyle P(X=k)=C_n^k p^k(1-p)^{n-k} \to \frac{\lambda^k}{k!}e^{-\lambda} P(X=k)=Cnkpk(1−p)n−k→k!λke−λ,其中常数 λ > 0 \lambda > 0 λ>0,记作
X ∼ P ( λ ) X \sim P(\lambda) X∼P(λ)显然,泊松分布含有下面两个性质
-
P ( X = k ) > 0 , k = 0 , 1 , ⋯ P(X=k) > 0,k=0,1,\cdots P(X=k)>0,k=0,1,⋯
-
∑ k = 0 ∞ P ( X = k ) = 1 \displaystyle \sum_{k=0}^\infty P(X=k)=1 k=0∑∞P(X=k)=1
{% fold light @泊松分布正规性证明 %}
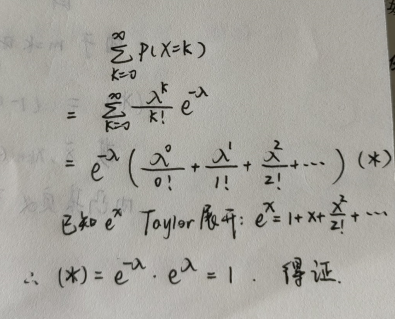
{% endfold %}
-
2.3 连续型随机变量及其概率密度函数
说白了其实就是离散性随机变量的积分加强版。现在随着事件发生的不同取值 x x x,随机变量 X X X 发生的概率 P ( X = x ) P(X=x) P(X=x) 变成了连续的取值了(学名概率密度函数),于是分布函数(离散的叫分布列)的取值就没那么容易求了(其实一重定积分就可以)。接下来就从定义、性质、应用三个角度出发介绍概率密度函数以及相应的随机变量的分布函数。
2.3.1 连续型随机变量的密度函数
概率密度函数,简称:密度函数 or 概率密度
-
定义:设随机变量 X X X 的分布函数为 F ( x ) F(x) F(x),如果存在非负可积函数 p ( x ) p(x) p(x),使下式成立,则称 X X X 为连续型随机变量, p ( x ) p(x) p(x) 为 X X X 的概率密度函数
∀ x ∈ R , F ( x ) = ∫ − ∞ x p ( t ) d t \forall x \in R,F(x) = \int_{-\infty}^{x} p(t)dt ∀x∈R,F(x)=∫−∞xp(t)dt -
性质:
-
非负性: p ( x ) ≥ 0 p(x) \ge 0 p(x)≥0
-
正规性: ∫ − ∞ + ∞ p ( x ) d x = 1 \int_{-\infty}^{+\infty} p(x)dx = 1 ∫−∞+∞p(x)dx=1
-
可积性: ∀ x 1 ≤ x 2 , P ( x 1 ≤ X ≤ x 2 ) = F ( x 2 ) − F ( x 1 ) = ∫ x 1 x 2 p ( x ) d x \forall x_1 \le x_2,P(x_1 \le X \le x_2) = F(x_2) - F(x_1) = \int_{x_1}^{x_2}p(x)dx ∀x1≤x2,P(x1≤X≤x2)=F(x2)−F(x1)=∫x1x2p(x)dx
-
分布函数可导性:若 p ( x ) p(x) p(x) 在点 x x x 处连续,则 F ′ ( x ) = p ( x ) F'(x) = p(x) F′(x)=p(x)
-
已知事件但无意义性: ∀ x ∈ R , P ( X = x ) = F ( x ) − F ( x ) = 0 \forall x \in R, P(X=x) = F(x) - F(x) = 0 ∀x∈R,P(X=x)=F(x)−F(x)=0
- 离散型变量可以通过列举随机变量 X X X 的取值来计算概率,但连续型随机变量这么做是无意义的
- P ( A ) = 0 P(A) = 0 P(A)=0 不能推出 A A A 是不可能事件, P ( A ) = 1 P(A)=1 P(A)=1 不能推出 A A A 是必然事件
- 对于连续型随机变量 X X X 有: P ( x 1 < X < X 2 ) = P ( x 1 < X ≤ X 2 ) = P ( x 1 ≤ X < X 2 ) = P ( x 1 ≤ X ≤ X 2 ) P(x_1 < X < X_2)=P(x_1 < X \le X_2)=P(x_1 \le X < X_2)=P(x_1 \le X \le X_2) P(x1<X<X2)=P(x1<X≤X2)=P(x1≤X<X2)=P(x1≤X≤X2)
-
实际描述性:密度函数的数值反映了随机变量 X X X 取 x x x 的临近值的概率的大小,因为
p ( x ) Δ x ≈ ∫ x x + Δ x p ( t ) d t = F ( x + Δ x ) − F ( x ) = P ( x ≤ X ≤ x + Δ x ) p(x)\Delta x \approx \int_{x}^{x+\Delta x} p(t)dt = F(x+\Delta x) - F(x) = P(x \le X \le x+\Delta x) p(x)Δx≈∫xx+Δxp(t)dt=F(x+Δx)−F(x)=P(x≤X≤x+Δx)
-
2.3.2 常用连续型随机变量及其密度函数
| 分布定义式 | 概率密度函数 | 分布函数 | |
|---|---|---|---|
| 均匀分布 | X ∼ U a , b X \sim Ua,b X∼Ua,b | p ( x ) = { 1 b − a , a ≤ x ≤ b , 0 , 其他 p(x) = \begin{cases} \frac{1}{b-a}, & a \le x \le b, \\ 0, & \text{其他} \end{cases} p(x)={b−a1,0,a≤x≤b,其他 | F ( x ) = { 0 , x < a x − a b − a , a ≤ x < b 1 , x ≥ b F(x) = \begin{cases} 0, & x < a \\ \frac{x - a}{b - a}, & a \le x < b \\ 1, & x \ge b \end{cases} F(x)=⎩ ⎨ ⎧0,b−ax−a,1,x<aa≤x<bx≥b |
| 指数分布 | X ∼ e ( λ ) X \sim e (\lambda) X∼e(λ) | p ( x ) = { 0 , x < 0 λ e − λ x , x ≥ 0 p(x) = \begin{cases} 0, & x < 0 \\ \lambda e^{-\lambda x} , & x \ge 0 \end{cases} p(x)={0,λe−λx,x<0x≥0 | F ( x ) = { 0 , x < 0 1 − e − λ x , x ≥ 0 F(x) = \begin{cases} 0, & x < 0 \\ 1- e^{-\lambda x}, & x \ge 0 \end{cases} F(x)={0,1−e−λx,x<0x≥0 |
| 正态分布 | X ∼ N ( μ , σ 2 ) X \sim N(\mu,\sigma^2) X∼N(μ,σ2) | p ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 , − ∞ < x < + ∞ p(x) = \frac{1}{\sqrt{2 \pi} \sigma } e^{- \frac{(x - \mu)^2}{2 \sigma ^2}} , \quad -\infty < x < + \infty p(x)=2π σ1e−2σ2(x−μ)2,−∞<x<+∞ | F ( x ) = 1 2 π σ ∫ − ∞ x e − ( y − μ ) 2 2 σ 2 d y F(x) = \frac{1}{\sqrt{2 \pi} \sigma } \int_{- \infty}^x e^{- \frac{(y - \mu)^2}{2 \sigma ^2}} dy F(x)=2π σ1∫−∞xe−2σ2(y−μ)2dy |
补充说明:
-
指数分布:其中参数 λ > 0 \lambda >0 λ>0
-
正态分布:一般正态函数 F ( x ) F(x) F(x) 转化为标准正态函数 Φ ( x ) \Phi(x) Φ(x) 公式:
F ( x ) = Φ ( x − μ σ ) F(x) = \Phi(\frac{x - \mu}{\sigma}) F(x)=Φ(σx−μ)于是对于计算一般正态函数的函数值,就可以通过下式将其转化为标准正态函数,最后查表即可:
P ( X ≤ x ) = F ( x ) = Φ ( x − μ σ ) P(X \le x) = F(x) = \Phi (\frac{x - \mu}{\sigma}) P(X≤x)=F(x)=Φ(σx−μ)
2.4 随机变量函数的分布
{% note light %}
本目主要介绍给定一个随机变量 X X X 的分布情况,通过一个关系式 y = g ( x ) y=g(x) y=g(x) 来求解随机变量 Y Y Y 的分布情况
{% endnote %}
2.4.1 离散型随机变量函数的分布
通过关系式 y = g ( x ) y=g(x) y=g(x) 将所有的 Y Y Y 的取值全部枚举出来,然后一一统计即可。
2.4.2 连续型随机变量函数的分布
给定随机变量 X X X 的概率密度函数 p X ( x ) p_X(x) pX(x),以及关系式 y = g ( x ) y=g(x) y=g(x),求解随机变量 Y Y Y 的分布函数 F Y ( y ) F_Y(y) FY(y)、概率密度函数 p Y ( y ) p_Y(y) pY(y)
-
方法一 :先求解随机变量 Y Y Y 的分布函数 F Y ( y ) F_Y(y) FY(y),再通过对其求导得到概率密度函数 p Y ( y ) p_Y(y) pY(y)
即先 F Y ( y ) = P Y ( Y ≤ y ) = P Y ( g ( X ) ≤ y ) = P X ( X ≤ f ( y ) ) = F X ( f ( y ) ) F_Y(y) = P_Y(Y \le y) = P_Y(g(X) \le y) = P_X(X \le f(y)) = F_X(f(y)) FY(y)=PY(Y≤y)=PY(g(X)≤y)=PX(X≤f(y))=FX(f(y)) 得到 Y Y Y 的分布函数
再对 F Y ( y ) F_Y(y) FY(y) 求导得 p Y ( y ) = d d y F Y ( y ) = d d y F X ( f ( y ) ) = F X ′ ( f ( y ) ) ⋅ f ′ ( y ) = p X ( f ( y ) ) ⋅ f ′ ( y ) \displaystyle p_Y(y) = \frac{d}{dy} F_Y(y) = \frac{d}{dy} F_X(f(y)) = F_X'(f(y)) \cdot f'(y) = p_X(f(y)) \cdot f'(y) pY(y)=dydFY(y)=dydFX(f(y))=FX′(f(y))⋅f′(y)=pX(f(y))⋅f′(y)
-
方法二 :如果关系式 y = g ( x ) y=g(x) y=g(x) 单调且反函数 x = h ( y ) x=h(y) x=h(y) 连续可导,则可以直接得出随机变量 Y Y Y 的概率密度函数 p Y ( y ) p_Y(y) pY(y) 为下式。其中 α \alpha α 和 β \beta β 为 Y = g ( X ) Y=g(X) Y=g(X) 的取值范围( x x x 应该怎么取值, h ( y ) h(y) h(y) 就应该怎么取值,从而计算出 y y y 的取值范围)
p Y ( y ) = { p X ( h ( y ) ) ⋅ ∣ h ′ ( y ) ∣ , α < y < β 0 , 其他 p_Y(y) = \begin{cases} p_X(h(y)) \cdot |h'(y)|, & \alpha < y < \beta \\ 0, & \text{其他} \end{cases} pY(y)={pX(h(y))⋅∣h′(y)∣,0,α<y<β其他
第3章 随机向量及其分布
{% note light %}
实际生活中,只采用一个随机变量描述事件往往是不够的。本章引入多维的随机变量概念,构成随机向量,从二维开始,推广到 n n n 维。
{% endnote %}
3.1 二维随机向量的联合分布
{% note light %}
现在我们讨论二维随机向量的联合分布。所谓的联合分布,其实就是一个曲面的概率密度(离散型就是点集),而分布函数就是对其积分得到的三维几何体的体积(散点和)而已。
{% endnote %}
3.1.1 联合分布函数
定义:我们定义满足下式的二元函数 F ( x , y ) F(x,y) F(x,y) 为二维随机向量 ( X , Y ) (X,Y) (X,Y) 的联合分布函数
F ( x , y ) = P ( ( X ≤ x ) ∩ ( Y ≤ y ) ) = P ( X ≤ x , Y ≤ y ) F(x,y) = P((X \le x) \cap (Y \le y)) = P(X \le x, Y \le y) F(x,y)=P((X≤x)∩(Y≤y))=P(X≤x,Y≤y)
{% fold light @几何意义:F(x,y) 即左下方无界矩形的面积 %}
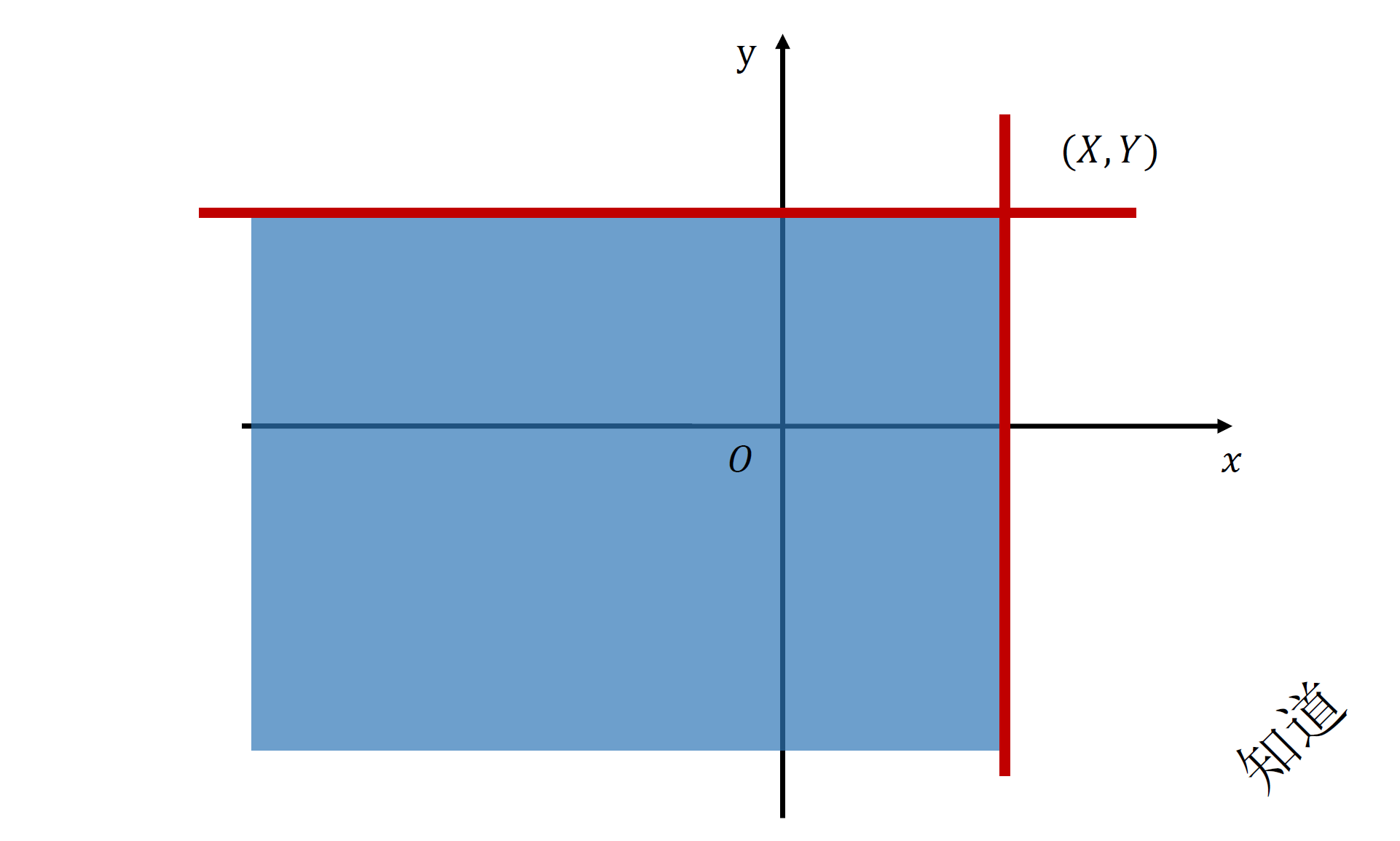
{% endfold %}
性质:其实配合几何意义理解就会很容易了
- 固定某一维度,另一维度是单调不减的
- 对于每个维度都是右连续的
- 固定某一维度,另一维度趋近于负无穷对应的函数值为 0 0 0
- 二维前缀和性质,右上角的矩阵面积 ≥ 0 \ge 0 ≥0
3.1.2 联合分布列
定义:若二维随机向量 ( X , Y ) (X,Y) (X,Y) 的所有可能取值是至多可列的,则称 ( X , Y ) (X,Y) (X,Y) 为二维离散型随机向量
表示:有两种表示二维随机向量分布列的方法,如下
{% fold light @二维随机向量分布列的表示方法 %}
-
公式法
p i j = P ( X = x i , Y = y i ) , i , j = 1 , 2 , ⋯ p_{ij} = P(X=x_i,Y = y_i), \quad i,j=1,2,\cdots pij=P(X=xi,Y=yi),i,j=1,2,⋯ -
表格法:

{% endfold %}
性质:
- 非负性: p i j ≥ 0 , i , j = 1 , 2 , ⋯ p_{ij} \ge 0, \quad i,j=1,2,\cdots pij≥0,i,j=1,2,⋯
- 正规性: ∑ i ∑ j p i j = 1 \displaystyle \sum_{i} \sum_{j} p_{ij} = 1 i∑j∑pij=1
3.1.3 联合密度函数
定义:
F ( x , y ) = ∫ − ∞ x ∫ − ∞ y p ( u , v ) d u d v F(x,y) = \int_{-\infty}^x \int_{-\infty}^y p(u,v)dudv F(x,y)=∫−∞x∫−∞yp(u,v)dudv
性质:
- 非负性: ∀ x , y ∈ R , p ( x , y ) ≥ 0 \forall x,y \in R,p(x,y) \ge 0 ∀x,y∈R,p(x,y)≥0
- 正规性: ∫ − ∞ + ∞ ∫ − ∞ + ∞ p ( x , y ) d x d y = 1 \displaystyle \int_{-\infty}^{+\infty} \int_{-\infty}^{+\infty} p(x,y)dxdy = 1 ∫−∞+∞∫−∞+∞p(x,y)dxdy=1
结论:
- 联合分布函数 相比于一元分布函数,其实就是从概率密度函数与 x x x 轴围成的面积转变为了概率密度曲面与 x O y xOy xOy 平面围成的体积
- 若概率密度曲面在 x O y xOy xOy 平面的投影为点集或线集,则对应的概率显然为零
常见的连续型二维分布:
-
二维均匀分布:假设该曲面与 x O y xOy xOy 面的投影面积为 S S S,则分布函数其实就是一个高为定值 1 S \frac{1}{S} S1 的柱体,密度函数为:
p ( x , y ) = { 1 S , ( x , y ) ∈ G 0 , 其他 p(x,y) = \begin{cases} \frac{1}{S}, &(x,y) \in G \\ 0, &\text{其他} \end{cases} p(x,y)={S1,0,(x,y)∈G其他 -
二元正态分布:不要求掌握密度函数,可以感受一下密度函数的图像:
{% fold light @二元正态分布 - 密度函数的图像%}
{% endfold %}
计算题:往往给出一个二元密度函数,然后让我们求解(1)密度函数中的参数、(2)分布函数、(3)联合事件某个区域下的概率
(1)我们利用二元密度函数的正规性,直接积分值为 1 1 1 即可
(2)划分区间后进行曲面积分即可,在曲面积分时往往结合 X X X 型和 Y Y Y 型的二重积分进行
(3)画出概率密度曲面在 x O y xOy xOy 面的投影,然后积分即可
3.2 二维随机向量的边缘分布
{% note light %}
对于二元分布函数,我们也可以研究其中任意一个随机变量的分布情况,而不需要考虑另一个随机变量的取值情况。举一个实例就是,假如当前的随机向量是身高和体重,所谓的只研究其中一个随机变量,即边缘分布函数的情形就是,我们不考虑身高只考虑体重的分布情况;或者我们不考虑体重,只考虑身高的分布情况。接下来,我们将从边缘分布函数入手,逐渐学习离散型的分布列与连续型的分布函数。
{% endnote %}
3.2.1 边缘分布函数
我们称 F X ( x ) , F Y ( y F_X(x),F_Y(y FX(x),FY(y) 分别为 ( X , Y ) (X,Y) (X,Y) 关于 X , Y X,Y X,Y 的边缘分布函数,定义式为:
F X ( x ) = P ( X ≤ x ) = P ( X ≤ x , Y < + ∞ ) = lim y → + ∞ F ( x , y ) = F ( x , + ∞ ) F Y ( y ) = P ( Y ≤ y ) = P ( X < + ∞ , Y ≤ y ) = lim x → + ∞ F ( x , y ) = F ( + ∞ , y ) \begin{aligned} F_X(x) = P(X \le x) = P(X \le x,Y < +\infty) = \lim_{y \to +\infty} F(x,y) = F(x,+\infty) \\ F_Y(y) = P(Y \le y) = P(X < +\infty, Y \le y) = \lim_{x \to +\infty} F(x,y) = F(+\infty,y) \end{aligned} FX(x)=P(X≤x)=P(X≤x,Y<+∞)=y→+∞limF(x,y)=F(x,+∞)FY(y)=P(Y≤y)=P(X<+∞,Y≤y)=x→+∞limF(x,y)=F(+∞,y)
3.2.2 边缘分布列
所谓的边缘分布列,就是固定一个随机变量,另外的随机变量取遍,组成的分布列。即:
P ( X = x i ) = p i ⋅ = ∑ j = 1 + ∞ p i j , i = 1 , 2 , ⋯ P ( Y = y j ) = p ⋅ j = ∑ i = 1 + ∞ p i j , j = 1 , 2 , ⋯ \begin{aligned} P(X=x_i) = p_{i\cdot}=\sum_{j=1}^{+\infty} p_{ij}, \quad i=1,2,\cdots \\ P(Y=y_j) = p_{\cdot j}=\sum_{i=1}^{+\infty} p_{ij}, \quad j=1,2,\cdots \end{aligned} P(X=xi)=pi⋅=j=1∑+∞pij,i=1,2,⋯P(Y=yj)=p⋅j=i=1∑+∞pij,j=1,2,⋯
我们称:
-
P ( X = x i ) P(X=x_i) P(X=xi) 为随机向量 ( X , Y ) (X,Y) (X,Y) 关于 X X X 的边缘分布列
-
P ( Y = y j ) P(Y=y_j) P(Y=yj) 为随机向量 ( X , Y ) (X,Y) (X,Y) 关于 Y Y Y 的边缘分布列
3.2.3 边缘密度函数
所谓的的边缘密度函数,可以与边缘分布列进行类比,也就是固定一个随机变量,另外的随机变量取遍。只不过连续型的取遍就是无数个点,而离散型的取遍是可列个点,仅此而已。即:
P ( X = x ) = p X ( x ) = d d x F X ( x ) = d d x F ( x , + ∞ ) = d d x ∫ − ∞ x ∫ − ∞ + ∞ p ( u , v ) d v d u = ∫ − ∞ + ∞ p ( x , y ) d y \begin{aligned} P(X=x) &= p_X(x) \\ &= \frac{d}{dx} F_X(x) \\ &= \frac{d}{dx} F(x,+\infty) \\ &= \frac{d}{dx} \int_{-\infty}^{x} \left \\int_{-\\infty}\^{+\\infty} p(u,v) dv \\right du \\ &= \int_{-\infty}^{+\infty} p(x,y) dy \\ \end{aligned} P(X=x)=pX(x)=dxdFX(x)=dxdF(x,+∞)=dxd∫−∞x∫−∞+∞p(u,v)dvdu=∫−∞+∞p(x,y)dy
P ( Y = y ) = p Y ( y ) = d d y F Y ( y ) = d d y F ( + ∞ , y ) = d d y ∫ − ∞ + ∞ ∫ − ∞ y p ( u , v ) d v d u = d d y ∫ − ∞ y ∫ − ∞ + ∞ p ( u , v ) d u d v = ∫ − ∞ + ∞ p ( x , y ) d x \begin{aligned} P(Y=y) &= p_Y(y) \\ &= \frac{d}{dy} F_Y(y) \\ &= \frac{d}{dy} F(+\infty,y) \\ &= \frac{d}{dy} \int_{-\infty}^{+\infty} \left \\int_{-\\infty}\^{y} p(u,v) dv \\right du \\ &= \frac{d}{dy} \int_{-\infty}^{y} \left \\int_{-\\infty}\^{+\\infty} p(u,v) du \\right dv \\ &= \int_{-\infty}^{+\infty} p(x,y) dx \\ \end{aligned} P(Y=y)=pY(y)=dydFY(y)=dydF(+∞,y)=dyd∫−∞+∞∫−∞yp(u,v)dvdu=dyd∫−∞y∫−∞+∞p(u,v)dudv=∫−∞+∞p(x,y)dx
我们称:
-
P ( X = x ) P(X=x) P(X=x) 为随机向量 ( X , Y ) (X,Y) (X,Y) 关于 X X X 的边缘密度函数
-
P ( Y = y ) P(Y=y) P(Y=y) 为随机向量 ( X , Y ) (X,Y) (X,Y) 关于 Y Y Y 的边缘密度函数
3.3 随机向量的条件分布
{% note light %}
本目主要介绍的是条件分布。所谓的条件分布,其实就是在约束一个随机变量为定值的情况下,另外一个随机变量的取值情况。与上述联合分布、边缘分布的区别在于:
- 联合分布、边缘分布的分布函数是一个体积(散点和),概率密度(分布列)是一个曲面(点集)
- 条件分布的分布函数是一个面积(散点和),概率密度(分布列)是一个曲线(点集)
{% endnote %}
3.3.1 离散型随机向量的条件分布列和条件分布函数
条件分布列,即散点情况:
p i ∣ j = P ( X = x i ∣ Y = y j ) = P ( X = x i , Y = y i ) P ( Y = y i ) = p i j p ⋅ j , i = 1 , 2 , ⋯ p j ∣ i = P ( Y = y j ∣ X = x i ) = P ( X = x i , Y = y i ) P ( X = x i ) = p i j p i ⋅ , j = 1 , 2 , ⋯ \begin{aligned} p_{i|j} = P(X=x_i\ |\ Y=y_j) = \frac{P(X=x_i,Y=y_i)}{P(Y=y_i)} = \frac{p_{ij}}{p_{\cdot j}}, \quad i=1,2,\cdots \\ p_{j|i} = P(Y=y_j\ |\ X=x_i) = \frac{P(X=x_i,Y=y_i)}{P(X=x_i)} = \frac{p_{ij}}{p_{i\cdot }}, \quad j=1,2,\cdots \end{aligned} pi∣j=P(X=xi ∣ Y=yj)=P(Y=yi)P(X=xi,Y=yi)=p⋅jpij,i=1,2,⋯pj∣i=P(Y=yj ∣ X=xi)=P(X=xi)P(X=xi,Y=yi)=pi⋅pij,j=1,2,⋯
我们称:
-
p i ∣ j p_{i|j} pi∣j 为在给定 Y = y j Y=y_j Y=yj 的条件下 X X X 的条件分布列
-
p j ∣ i p_{j|i} pj∣i 为在给定 X = x i X=x_i X=xi 的条件下 Y Y Y 的条件分布列
条件分布函数,即点集情况:
F ( x ∣ y j ) = P ( X ≤ x ∣ Y = y j ) = ∑ x i ≤ x p i j p ⋅ j F ( y ∣ x i ) = P ( Y ≤ y ∣ X = x i ) = ∑ y j ≤ y p i j p i ⋅ \begin{aligned} F(x|y_j) = P(X \le x\ | \ Y=y_j) = \sum {x_i\le x} \frac{p{ij}}{p_{\cdot j}} \\ F(y|x_i) = P(Y \le y\ | \ X=x_i) = \sum {y_j\le y} \frac{p{ij}}{p_{i \cdot}} \end{aligned} F(x∣yj)=P(X≤x ∣ Y=yj)=xi≤x∑p⋅jpijF(y∣xi)=P(Y≤y ∣ X=xi)=yj≤y∑pi⋅pij
我们称:
- F ( x ∣ y j ) F(x|y_j) F(x∣yj) 为在给定 Y = y j Y=y_j Y=yj 的条件下 X X X 的条件分布函数
- F ( y ∣ x i ) F(y|x_i) F(y∣xi) 为在给定 X = x i X=x_i X=xi 的条件下 Y Y Y 的条件分布函数
3.3.2 连续型随机向量的条件密度函数和条件分布函数
条件密度函数,即联合分布的概率密度曲面上,约束了某一维度的随机变量为定值,于是条件密度函数的图像就是一个空间曲线:
p ( x ∣ y ) = p ( x , y ) p Y ( y ) , − ∞ < x < + ∞ p ( y ∣ x ) = p ( x , y ) p X ( x ) , − ∞ < y < + ∞ \begin{aligned} p(x|y) = \frac{p(x,y)}{p_Y(y)}, \quad -\infty < x < +\infty \\ p(y|x) = \frac{p(x,y)}{p_X(x)}, \quad -\infty < y < +\infty \end{aligned} p(x∣y)=pY(y)p(x,y),−∞<x<+∞p(y∣x)=pX(x)p(x,y),−∞<y<+∞
我们称:
- p ( x ∣ y ) p(x|y) p(x∣y) 为在给定 Y = y Y=y Y=y 的条件下 X X X 的条件密度函数
- p ( y ∣ x ) p(y|x) p(y∣x) 为在给定 X = x X=x X=x 的条件下 Y Y Y 的条件密度函数
条件分布函数,即上述曲线的分段积分结果:
F ( x ∣ y ) = P ( X ≤ x ∣ Y = y ) = ∫ − ∞ x p ( u , y ) p Y ( y ) d u , − ∞ < x < + ∞ F ( y ∣ x ) = P ( Y ≤ y ∣ X = x ) = ∫ − ∞ y p ( x , v ) p X ( x ) d v , − ∞ < y < + ∞ \begin{aligned} F(x|y) = P(X \le x \ | \ Y=y) = \int_{-\infty}^x \frac{p(u,y)}{p_Y(y)} du,\quad -\infty < x < +\infty \\ F(y|x) = P(Y \le y \ | \ X=x) = \int_{-\infty}^y \frac{p(x,v)}{p_X(x)} dv, \quad -\infty < y < +\infty \end{aligned} F(x∣y)=P(X≤x ∣ Y=y)=∫−∞xpY(y)p(u,y)du,−∞<x<+∞F(y∣x)=P(Y≤y ∣ X=x)=∫−∞ypX(x)p(x,v)dv,−∞<y<+∞
我们称:
- F ( x ∣ y ) F(x|y) F(x∣y) 为在给定 Y = y Y=y Y=y 的条件下 X X X 的条件分布函数
- F ( y ∣ x ) F(y|x) F(y∣x) 为在给定 X = x X=x X=x 的条件下 Y Y Y 的条件分布函数
3.4 随机变量的独立性
{% note light %}
本目主要介绍随机变量的独立性。我们知道随机事件之间是有独立性的,即满足 P ( A B ) = P ( A ) P ( B ) P(AB)=P(A)P(B) P(AB)=P(A)P(B) 的事件,那么随机变量之间也有独立性吗?答案是有的,以生活中的例子为实例,比如我和某个同学进教室,就是独立的两个随机变量。下面开始介绍。
{% endnote %}
-
定义:我们定义如果两个随机变量的分布函数满足下式,则两个随机变量相互独立:
F ( x , y ) = F X ( x ) F Y ( y ) F(x,y)=F_X(x)F_Y(y) F(x,y)=FX(x)FY(y) -
性质:对于随机向量 ( X , Y ) (X,Y) (X,Y)
-
随机变量 X X X 和 Y Y Y 相互独立的充分必要条件是:
离散型: P ( X = x i , Y = y j ) = P ( X = x i ) P ( Y = y j ) 连续型: p ( x , y ) = p X ( x ) p Y ( y ) \begin{aligned} \text{离散型:}& P(X=x_i,Y=y_j) = P(X=x_i)P(Y=y_j) \\ \text{连续型:}& p(x,y) = p_X(x)p_Y(y) \end{aligned} 离散型:连续型:P(X=xi,Y=yj)=P(X=xi)P(Y=yj)p(x,y)=pX(x)pY(y) -
若随机变量 X X X 和 Y Y Y 相互独立,且 h ( ⋅ ) h(\cdot) h(⋅) 和 g ( ⋅ ) g(\cdot) g(⋅) 连续,则 h ( X ) , g ( Y ) h(X),g(Y) h(X),g(Y) 也相互独立
-
3.5 随机向量函数的分布
{% note light %}
在 2.4 目中我们了解到了随机变量函数的分布,现在我们讨论随机向量函数的分布。在生活中,假设我们已经知道了一个人群中所有人的身高和体重的分布情况,现在想要血糖根据身高和体重的分布情况,就需要用到本目的理念。我们从离散型和连续型随机向量 ( X , Y ) (X,Y) (X,Y) 出发,讨论 g ( X , Y ) g(X,Y) g(X,Y) 的分布情况。
{% endnote %}
3.5.1 离散型随机向量函数的分布
按照规则枚举即可。
3.5.2 连续型随机向量函数的分布
与连续型随机变量函数的分布类似,这类题目一般也是:给定随机向量 ( X , Y ) (X,Y) (X,Y) 的密度函数 p ( x , y ) p(x,y) p(x,y) 和 映射函数 g ( x , y ) g(x,y) g(x,y),现在需要求解 Z = g ( X , Y ) Z=g(X,Y) Z=g(X,Y) 的分布函数(若 g ( x , y ) g(x,y) g(x,y) 二元连续,则 Z Z Z 也是连续型随机变量)。方法同理,先求解 Z Z Z 的分布函数,再对 z z z 求导得到密度函数 p Z ( z ) p_Z(z) pZ(z)。接下来我们介绍两种常见随机向量的分布。
(1) 和的分布:
-
先求分布函数 F Z ( z ) F_Z(z) FZ(z):
F Z ( z ) = P ( X + Y ≤ z ) = ∬ x + y ≤ z p ( x , y ) d x d y = ∫ − ∞ z ∫ − ∞ + ∞ p ( x , t − x ) d x d t = ∫ − ∞ z ∫ − ∞ + ∞ p ( t − y , y ) d y d t \begin{aligned} F_Z(z) &= P(X+Y \le z) \\ &= \iint\limits_{x+y \le z} p(x,y) dxdy \\ &\begin{align} &= \int _{-\infty}^z \left \\int_{-\\infty}\^{+\\infty} p(x,t-x)dx \\right dt \\ &= \int _{-\infty}^z \left \\int_{-\\infty}\^{+\\infty} p(t-y,y)dy \\right dt \end{align} \end{aligned} FZ(z)=P(X+Y≤z)=x+y≤z∬p(x,y)dxdy=∫−∞z∫−∞+∞p(x,t−x)dxdt=∫−∞z∫−∞+∞p(t−y,y)dydt -
由分布函数定义:
F X ( x ) = ∫ − ∞ x p ( u ) d u F_X(x) = \int_{-\infty}^xp(u)du FX(x)=∫−∞xp(u)du -
所以可得 Z = X + Y Z=X+Y Z=X+Y 的密度函数 p Z ( z ) p_Z(z) pZ(z) 为:
p Z ( z ) = ∫ − ∞ + ∞ p ( x , z − x ) d x ( 1 ) p Z ( z ) = ∫ − ∞ + ∞ p ( z − y , y ) d y ( 2 ) \begin{aligned} p_Z(z) = \int_{-\infty}^{+\infty} p(x,z-x)dx \quad &(1) \\ p_Z(z) = \int_{-\infty}^{+\infty} p(z-y,y)dy \quad &(2) \\ \end{aligned} pZ(z)=∫−∞+∞p(x,z−x)dxpZ(z)=∫−∞+∞p(z−y,y)dy(1)(2) -
若 X 和 Y 相互独立,还可得卷积式:
p Z ( z ) = ∫ − ∞ + ∞ p ( x , z − x ) d x = ∫ − ∞ + ∞ p X ( x ) ⋅ p Y ( z − x ) d x ( 1 ) p Z ( z ) = ∫ − ∞ + ∞ p ( z − y , y ) d y = ∫ − ∞ + ∞ p X ( z − y ) ⋅ p Y ( y ) d y ( 2 ) \begin{aligned} p_Z(z) &= \int_{-\infty}^{+\infty} p(x,z-x)dx \\ &= \int_{-\infty}^{+\infty} p_X(x)\cdot p_Y(z-x) dx \quad &(1) \\ p_Z(z) &= \int_{-\infty}^{+\infty} p(z-y,y)dy \\ &= \int_{-\infty}^{+\infty} p_X(z-y)\cdot p_Y(y) dy \quad &(2) \end{aligned} pZ(z)pZ(z)=∫−∞+∞p(x,z−x)dx=∫−∞+∞pX(x)⋅pY(z−x)dx=∫−∞+∞p(z−y,y)dy=∫−∞+∞pX(z−y)⋅pY(y)dy(1)(2)
(2) 次序统计量的分布(对于两个相互独立的随机变量 X 和 Y):
-
对于 M = max ( X , Y ) M=\max{(X,Y)} M=max(X,Y) 的分布函数,有:
F M ( z ) = P ( M ≤ z ) = P ( max ( X , Y ) ≤ z ) = P ( X ≤ z , Y ≤ z ) = P ( X ≤ z ) ⋅ P ( Y ≤ z ) = F X ( z ) ⋅ F Y ( z ) \begin{aligned} F_M(z) &= P(M \le z) \\ &= P(\max{(X,Y)} \le z) \\ &= P(X \le z, Y \le z) \\ &= P(X \le z) \cdot P(Y \le z) \\ &= F_X(z) \cdot F_Y(z) \end{aligned} FM(z)=P(M≤z)=P(max(X,Y)≤z)=P(X≤z,Y≤z)=P(X≤z)⋅P(Y≤z)=FX(z)⋅FY(z) -
对于 N = min ( X , Y ) N=\min{(X,Y)} N=min(X,Y) 的分布函数,有:
F N ( z ) = P ( N ≤ z ) = P ( min ( X , Y ) ≤ z ) = 1 − P ( min ( X + Y ) ≥ z ) = 1 − P ( X ≥ z , Y ≥ z ) = 1 − P ( X ≥ z ) ⋅ P ( Y ≥ z ) = 1 − 1 − F X ( z ) ⋅ 1 − F Y ( z ) \begin{aligned} F_N(z) &= P(N \le z) \\ &= P(\min{(X,Y)} \le z) \\ &= 1 - P(\min{(X+Y)} \ge z) \\ &= 1 - P(X \ge z,Y \ge z) \\ &= 1 - P(X \ge z) \cdot P(Y \ge z) \\ &= 1 - 1 - F_X(z) \cdot 1 - F_Y(z) \end{aligned} FN(z)=P(N≤z)=P(min(X,Y)≤z)=1−P(min(X+Y)≥z)=1−P(X≥z,Y≥z)=1−P(X≥z)⋅P(Y≥z)=1−1−FX(z)⋅1−FY(z) -
若拓展到 n n n 个相互独立且同分布的随机变量,则有:
F M ( z ) = F ( z ) n p M ( z ) = n p ( z ) F ( z ) n − 1 \begin{aligned} F_M(z) &= F(z)^n \\ p_M(z) &= np(z)F(z)^{n-1} \end{aligned} FM(z)pM(z)=F(z)n=np(z)F(z)n−1F N ( z ) = 1 − 1 − F ( z ) n p N ( z ) = n p ( z ) 1 − F ( z ) n − 1 \begin{aligned} F_N(z) &= 1 - 1-F(z)^n \\ p_N(z) &= np(z)1-F(z)^{n-1} \end{aligned} FN(z)pN(z)=1−1−F(z)n=np(z)1−F(z)n−1
第4章 随机变量的数字特征
{% note light %}
本章我们将学习随机变量的一些数字特征。所谓的数字特征其实就是随机变量分布的一些内在属性,比如均值、方差、协方差等等,有些分布特性甚至可以通过某个数字特征而直接觉得。其中期望 和方差 往往用来衡量单个随机变量的特征,而协方差 与相关系数则是用来衡量随机变量之间的数字特征。接下来开始介绍。
{% endnote %}
4.1 数学期望
{% note light %}
加权平均概念的严格数学定义。
{% endnote %}
4.1.1 随机变量的数学期望
-
离散型
E X = ∑ i = 1 ∞ x i p i EX = \sum_{i=1}^{\infty} x_i p_i EX=i=1∑∞xipi -
连续型
E X = ∫ − ∞ + ∞ x p ( x ) d x \begin{aligned} &EX = \int_{-\infty}^{+\infty} xp(x)dx \end{aligned} EX=∫−∞+∞xp(x)dx
4.1.2 随机变量函数的数学期望
-
离散型
-
一元
E g ( X ) = ∑ i = 1 ∞ g ( x i ) p i Eg(X) = \sum_{i=1}^{\infty}g(x_i)p_i Eg(X)=i=1∑∞g(xi)pi -
二元
E g ( X , Y ) = ∑ i = 1 ∞ ∑ j = 1 ∞ g ( x i , y i ) p i j Eg(X,Y) = \sum_{i=1}^{\infty}\sum_{j=1}^{\infty}g(x_i,y_i)p_{ij} Eg(X,Y)=i=1∑∞j=1∑∞g(xi,yi)pij
-
-
连续型
-
一元
E g ( X ) = ∫ − ∞ + ∞ g ( x ) p ( x ) d x Eg(X) = \int_{-\infty}^{+\infty}g(x)p(x)dx Eg(X)=∫−∞+∞g(x)p(x)dx -
二元
E g ( X , Y ) = ∫ − ∞ + ∞ ∫ − ∞ + ∞ g ( x i , y i ) p ( x , y ) d x d y Eg(X,Y) = \int_{-\infty}^{+\infty}\int_{-\infty}^{+\infty}g(x_i,y_i)p(x,y)dxdy Eg(X,Y)=∫−∞+∞∫−∞+∞g(xi,yi)p(x,y)dxdy
-
4.1.3 数学期望的性质
- E C = C EC=C EC=C
- E ( C X ) = C E X E(CX)=CEX E(CX)=CEX
- E ( X + Y ) = E X + E Y E(X+Y)=EX+EY E(X+Y)=EX+EY
- 若 X X X 和 Y Y Y 相互独立,则 E ( X Y ) = E X E Y E(XY)=EXEY E(XY)=EXEY
4.2 方差
{% note light %}
随机变量的取值与均值之间的离散程度。
{% endnote %}
4.2.1 方差的定义
我们定义随机变量 X X X 的方差 D ( X ) D(X) D(X) 为:(全部可由期望的性质推导而来)
D ( X ) = E ( X − E X ) 2 = E ( X 2 ) − ( E X ) 2 \begin{aligned} D(X) &= E\left(X-EX)\^2\\right \\ &= E\left ( X^2 \right ) - (EX)^2 \end{aligned} D(X)=E(X−EX)2=E(X2)−(EX)2
4.2.2 方差的性质
下列方差的性质全部可由上述方差的定义式,结合期望的性质推导而来:
-
D ( a X + b ) = a 2 D ( X ) D(aX+b) = a^2D(X) D(aX+b)=a2D(X)
-
若 X 1 , X 2 , ⋯ X_1,X_2,\cdots X1,X2,⋯ 相互独立,则 D ( a X 1 ± b X 2 ± ⋯ ) = a 2 D ( X 1 ) + b 2 D ( X 2 ) + ⋯ D(aX_1 \pm bX_2 \pm \cdots) = a^2D(X_1) + b^2D(X_2) + \cdots D(aX1±bX2±⋯)=a2D(X1)+b2D(X2)+⋯
-
E ( X − E X ) 2 ≤ E ( X − C ) 2 E\left (X-EX)\^2 \\right \le E \left (X-C)\^2 \\right E(X−EX)2≤E(X−C)2
-
切比雪夫不等式 (本以为不要求掌握的,但是被小测拷打了,补一下):
∀ ϵ > 0 , P ( ∣ X − E X ∣ < ϵ ) ≥ 1 − D X ϵ 2 \forall \epsilon >0, P(|X - EX| < \epsilon) \ge 1 - \frac{DX}{\epsilon^2} ∀ϵ>0,P(∣X−EX∣<ϵ)≥1−ϵ2DX
4.3 结论与推导(补)
| 类型 | 分布 | 符号 | 期望 E ( X ) E(X) E(X) | 方差 D ( X ) D(X) D(X) |
|---|---|---|---|---|
| 离散型 | 0-1 分布 | X ∼ ( 0 1 1 − p p ) X \sim \begin{pmatrix} 0 & 1 \\ 1-p & p \end{pmatrix} X∼(01−p1p) | p p p | p ( 1 − p ) p(1-p) p(1−p) |
| --- | *二项分布 | X ∼ B ( n , p ) X \sim B(n,p) X∼B(n,p) | n p np np | n p ( 1 − p ) np(1-p) np(1−p) |
| --- | 几何分布 | X ∼ G ( p ) X \sim G(p) X∼G(p) | 1 p \displaystyle \frac{1}{p} p1 | 1 − p p 2 \displaystyle \frac{1-p}{p^2} p21−p |
| --- | *泊松分布 | X ∼ P ( λ ) X \sim P(\lambda) X∼P(λ) | λ \lambda λ | λ \lambda λ |
| 连续型 | 均匀分布 | X ∼ U a , b X \sim Ua,b X∼Ua,b | a + b 2 \displaystyle \frac{a+b}{2} 2a+b | ( b − a ) 2 12 \displaystyle \frac{(b-a)^2}{12} 12(b−a)2 |
| --- | 指数分布 | X ∼ e ( λ ) X \sim e(\lambda) X∼e(λ) | 1 λ \displaystyle \frac{1}{\lambda} λ1 | 1 λ 2 \displaystyle \frac{1}{\lambda^2} λ21 |
| --- | *正态分布 | X ∼ N ( μ , σ 2 ) X \sim N(\mu,\sigma^2) X∼N(μ,σ2) | μ \mu μ | σ 2 \sigma^2 σ2 |
{% note warning %}
注:打星号表示在两个随机变量 X , Y X,Y X,Y 相互独立时,具备可加性。具体的:
- X ∼ N ( μ 1 , σ 1 2 ) , Y ∼ N ( μ 2 , σ 2 2 ) → X ± Y ∼ N ( μ 1 ± μ 2 , σ 1 2 + σ 2 2 ) X \sim N(\mu_1,\sigma_1^2), Y \sim N(\mu_2,\sigma_2^2) \to X\pm Y\sim N(\mu_1\pm\mu_2,\sigma_1^2+\sigma_2^2) X∼N(μ1,σ12),Y∼N(μ2,σ22)→X±Y∼N(μ1±μ2,σ12+σ22)
- X ∼ B ( n 1 , p ) , Y ∼ B ( n 2 , p ) → X + Y ∼ B ( n 1 + n 2 , p ) X \sim B(n_1,p), Y \sim B(n_2,p) \to X+Y\sim B(n_1+n_2,p) X∼B(n1,p),Y∼B(n2,p)→X+Y∼B(n1+n2,p)
- X ∼ P ( λ 1 ) , Y ∼ P ( λ 2 ) → X + Y ∼ P ( λ 1 + λ 2 ) X \sim P(\lambda_1),Y\sim P(\lambda_2) \to X+Y \sim P(\lambda_1+\lambda_2) X∼P(λ1),Y∼P(λ2)→X+Y∼P(λ1+λ2)
{% endnote %}
{% fold light @推导 %}
推导的根本方式还是从定义出发。当然为了省事也可以从性质出发。
0-1 分布
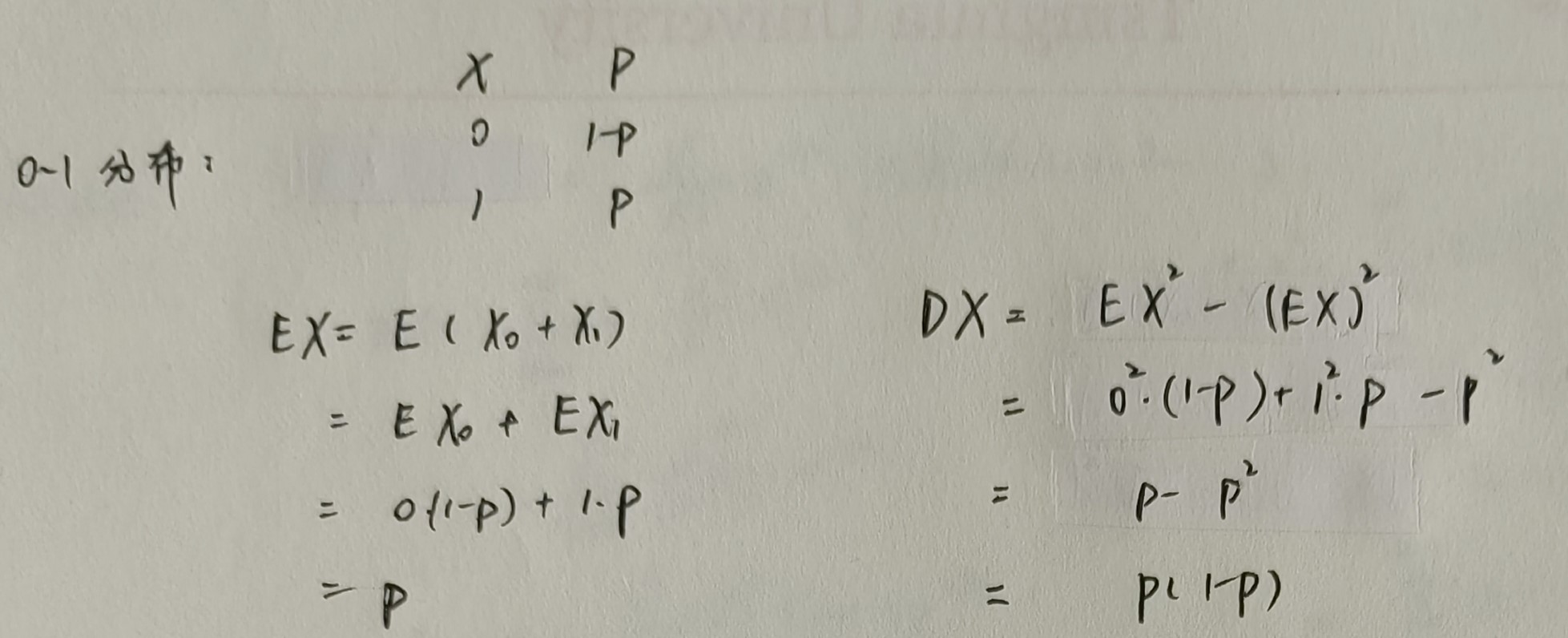
二项分布
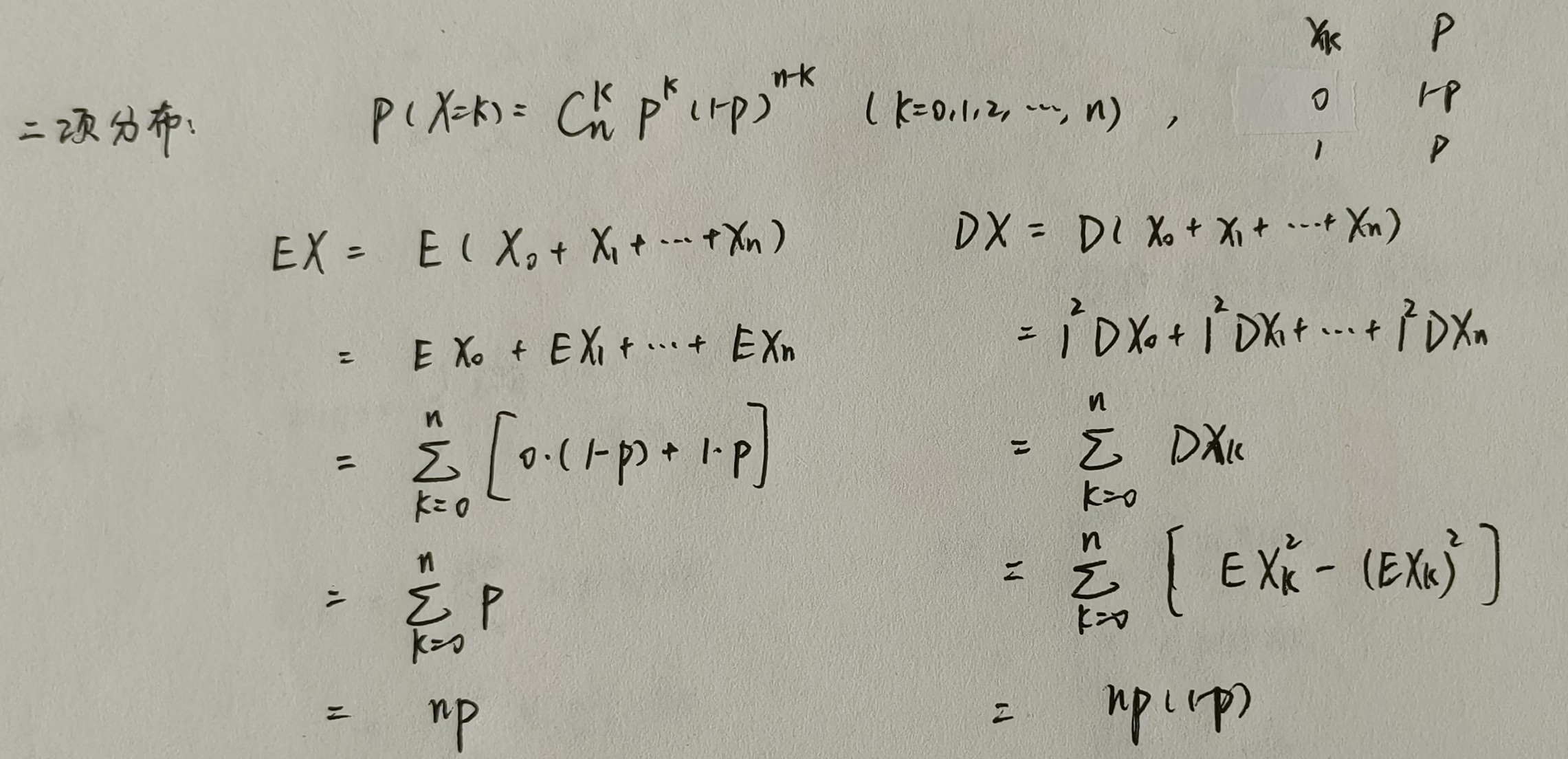
几何分布
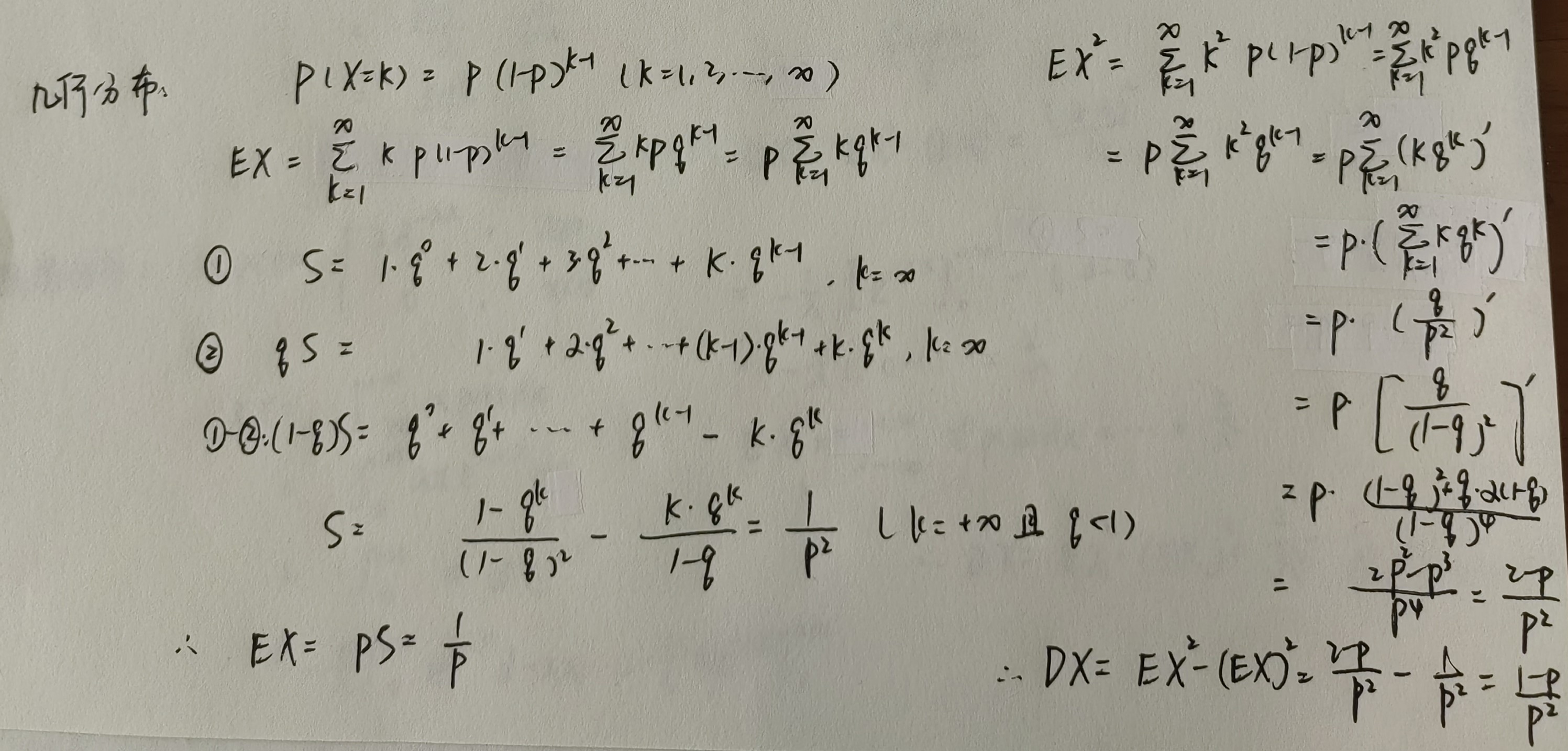
泊松分布
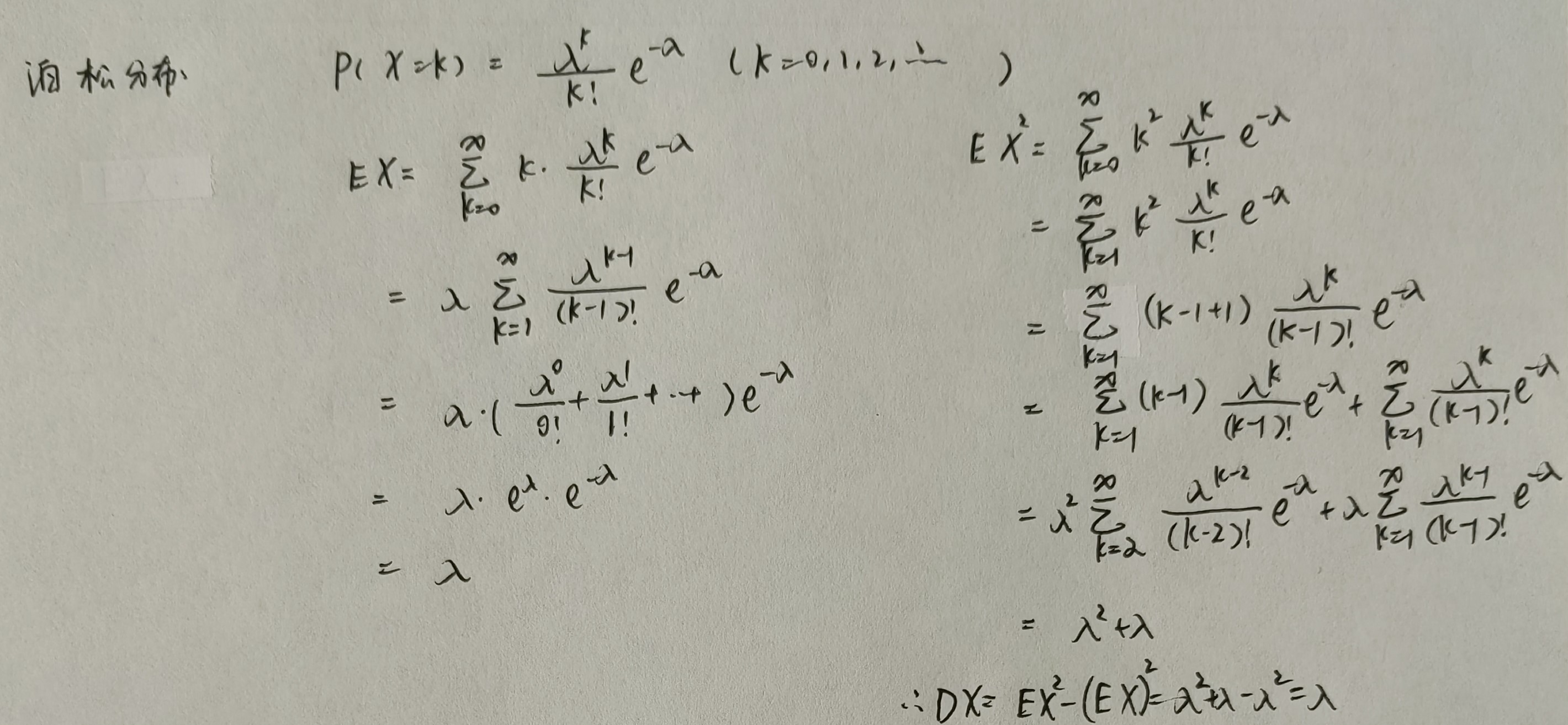
均匀分布
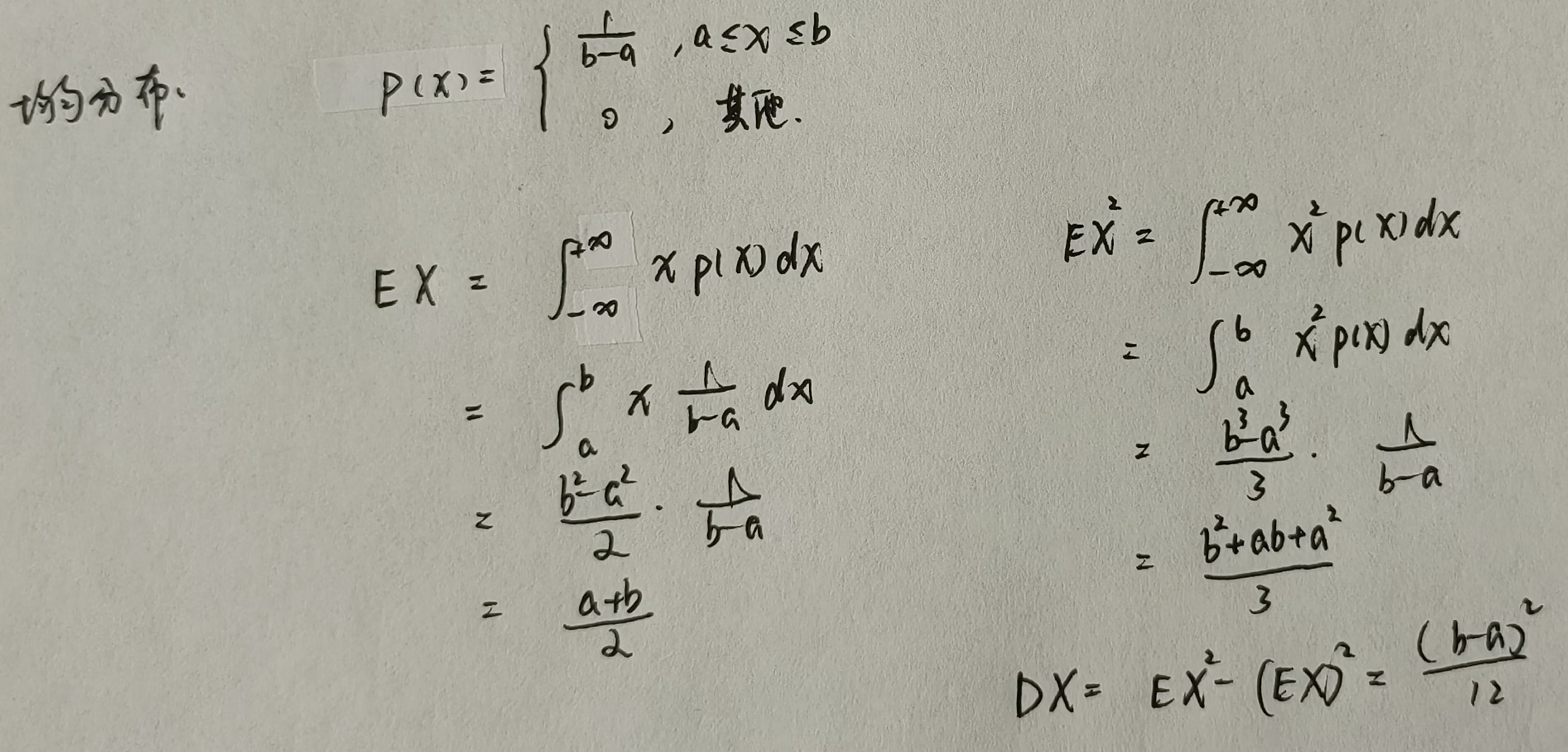
指数分布
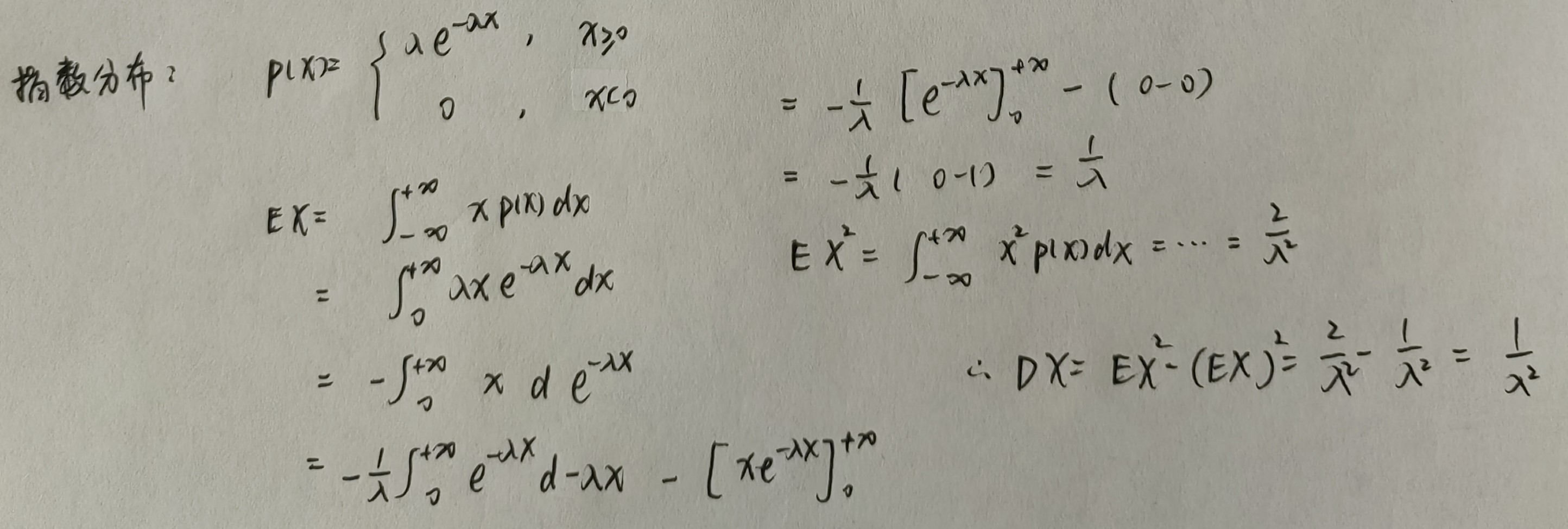
{% endfold %}
4.4 协方差与相关系数
4.4.1 协方差
定义:随机变量 X 与 Y 的协方差 C o v ( X , Y ) Cov(X,Y) Cov(X,Y) 为:
C o v ( X , Y ) = E ( X − E X ) ( Y − E Y ) = E ( X Y ) − E X E Y \begin{aligned} Cov(X,Y)&= E(X-EX)(Y-EY) \\ &= E(XY) - EXEY \end{aligned} Cov(X,Y)=E(X−EX)(Y−EY)=E(XY)−EXEY
特别的:
C o v ( X , X ) = D X Cov(X,X) = DX Cov(X,X)=DX
性质:
- 交换律: C o v ( X , Y ) = C o v ( Y , X ) Cov(X,Y)=Cov(Y,X) Cov(X,Y)=Cov(Y,X)
- 提取率: C o v ( a X , b Y ) = a b C o v ( X , Y ) Cov(aX,bY)=abCov(X,Y) Cov(aX,bY)=abCov(X,Y)
- 分配率: C o v ( X 1 + X 2 , Y ) = C o v ( X 1 , Y ) + C o v ( X 2 , Y ) Cov(X_1+X_2,Y) = Cov(X_1,Y)+Cov(X_2,Y) Cov(X1+X2,Y)=Cov(X1,Y)+Cov(X2,Y)
- 独立性:若 X 与 Y 相互独立,则 C o v ( X , Y ) = 0 Cov(X,Y)=0 Cov(X,Y)=0;反之不一定成立
- 放缩性: C o v ( X , Y ) 2 ≤ D X ⋅ D Y \leftCov(X,Y)\\right^2 \le DX \cdot DY Cov(X,Y)2≤DX⋅DY
4.4.2 相关系数
定义:相关系数 ρ \rho ρ 是用来刻画两个随机变量之间线性 相关关系强弱的一个数字特征,注意是线性关系。 ∣ ρ ∣ |\rho| ∣ρ∣ 越接近 0,则说明两个随机变量越不线性相关; ∣ ρ ∣ |\rho| ∣ρ∣ 越接近 1,则说明两个随机变量越线性相关,定义式为
ρ X , Y = C o v ( X , Y ) D X D Y \rho_{X,Y} = \frac{Cov(X,Y)}{\sqrt{DX}\sqrt{DY}} ρX,Y=DX DY Cov(X,Y)
特别的:
- 若 0 < ρ < 1 0 < \rho < 1 0<ρ<1,则称 X 与 Y 正相关
- 若 − 1 < ρ < 0 -1<\rho<0 −1<ρ<0,则称 X 与 Y 负相关
性质:
- 放缩性(由协方差性质5可得): ∣ ρ ∣ ≤ 1 |\rho| \le 1 ∣ρ∣≤1
- 独立性(由协方差性质4可得):若 X 与 Y 相互独立,则 p = 0 p=0 p=0;反之不一定成立
- 线性相关性(不予证明): ∣ ρ ∣ = 1 |\rho|=1 ∣ρ∣=1 的充分必要条件是存在常数 a ( a ≠ 0 ) , b a(a\ne0),b a(a=0),b 使得 P ( Y = a X + b ) = 1 P(Y=aX+b)=1 P(Y=aX+b)=1
4.4.3 独立性与线性相关性(补)
一般的:对于两个随机变量 X X X 和 Y Y Y
- X X X 和 Y Y Y 相互独立 → \rightarrow → X X X 和 Y Y Y 线性无关(可以用线性相关的定义式结合协方差计算公式导出)
- X X X 和 Y Y Y 相互独立 ↚ \nleftarrow ↚ X X X 和 Y Y Y 线性无关(因为有可能出现 X X X 和 Y Y Y 非线性相关)
特别的:对于满足二维正态分布的随机变量 X X X 和 Y Y Y,即 ( X , Y ) ∼ ( μ 1 , μ 2 , σ 1 2 , σ 2 2 , ρ ) (X,Y) \sim (\mu_1,\mu_2,\sigma_1^2,\sigma_2^2,\rho) (X,Y)∼(μ1,μ2,σ12,σ22,ρ)
- X X X 和 Y Y Y 相互独立 → \rightarrow → X X X 和 Y Y Y 线性无关
- X X X 和 Y Y Y 相互独立 ← \leftarrow ← X X X 和 Y Y Y 线性无关
{% fold light @证明 - 二维正态分布的两个随机变量:相互独立 等价于 线性无关 %}

参考:https://www.zhihu.com/question/29641138
{% endfold %}