【TJU】研究生应用统计学课程笔记(1)------第一章 数理统计的基本知识
- [前置 复习概率基本概念](#前置 复习概率基本概念)
-
- 一、随机变量及其分布
-
- [1️⃣ 随机变量](#1️⃣ 随机变量)
- [2️⃣ 分布函数](#2️⃣ 分布函数)
- [3️⃣ 常见的随机变量分布](#3️⃣ 常见的随机变量分布)
- 二、随机变量数字特征
-
- [1️⃣ 随机变量的期望与方差计算](#1️⃣ 随机变量的期望与方差计算)
- [2️⃣ 期望与方差的性质](#2️⃣ 期望与方差的性质)
- [3️⃣ 协方差与相关系数](#3️⃣ 协方差与相关系数)
- 三、极限定理
-
- [0️⃣ 前置知识](#0️⃣ 前置知识)
- [1️⃣ 极限定理](#1️⃣ 极限定理)
- [2️⃣ 辛钦大数定理](#2️⃣ 辛钦大数定理)
- [3️⃣ 伯努利大数定理](#3️⃣ 伯努利大数定理)
- [4️⃣ 独立同分布的中心极限定理](#4️⃣ 独立同分布的中心极限定理)
- [5️⃣ 大数定理与中心极限定理的区别](#5️⃣ 大数定理与中心极限定理的区别)
- [1.1 数理统计的基本内容](#1.1 数理统计的基本内容)
- [1.2 数理统计的基本概念](#1.2 数理统计的基本概念)
-
- 一、总体和样本
-
- [1️⃣ 总体与个体](#1️⃣ 总体与个体)
- [2️⃣ 样本与样本容量](#2️⃣ 样本与样本容量)
- [3️⃣ 样本的二重性](#3️⃣ 样本的二重性)
- [4️⃣ 简单随机样本及其联合分布](#4️⃣ 简单随机样本及其联合分布)
- [5️⃣ 有放回抽样与无放回抽样](#5️⃣ 有放回抽样与无放回抽样)
- 二、直方图
-
- [1️⃣ 数据分析---频率直方图](#1️⃣ 数据分析—频率直方图)
- [2️⃣ 数据分布的特征](#2️⃣ 数据分布的特征)
- [3️⃣ 数据均值的测度](#3️⃣ 数据均值的测度)
- [4️⃣ 整理数据的方法](#4️⃣ 整理数据的方法)
- 三、统计量
-
- [1️⃣ 统计量的定义](#1️⃣ 统计量的定义)
- [2️⃣ 常用的统计量](#2️⃣ 常用的统计量)
- [3️⃣ 常用统计量的期望和方差](#3️⃣ 常用统计量的期望和方差)
- [4️⃣ 次序统计量与经验分布函数](#4️⃣ 次序统计量与经验分布函数)
前置 复习概率基本概念
一、随机变量及其分布
1️⃣ 随机变量
定义:样本空间到实数集的函数。按取值类型可分为离散型随机变量和连续型随机变量。
离散型随机变量 通常用概率质量函数描述: P ( X = x i ) = p i , i = 1 , 2 , . . . P(X = x_i) = p_i, i = 1, 2, ... P(X=xi)=pi,i=1,2,...
连续型随机变量 通常用概率密度函数描述: f ( x ) > = 0 , ∫ f ( x ) d x = 1 f(x) >= 0, ∫ f(x) dx = 1 f(x)>=0,∫f(x)dx=1
2️⃣ 分布函数
定义为: F ( x ) = P ( X < = x ) F(x) = P(X <= x) F(x)=P(X<=x)
分布函数的基本性质
- 单调不减
- 取值范围在
[0, 1]- 满足: l i m x − > − ∞ F ( x ) = 0 lim_{x -> -∞} F(x) = 0 limx−>−∞F(x)=0, l i m x − > + ∞ F ( x ) = 1 lim_{x -> +∞} F(x) = 1 limx−>+∞F(x)=1
3️⃣ 常见的随机变量分布
(1) 0-1 分布
定义:若随机变量 X X X 只可能取两个值 0 0 0 和 1 1 1,且 P ( X = 1 ) = p , P ( X = 0 ) = 1 − p , 0 < p < 1 P(X = 1) = p, \quad P(X = 0) = 1-p, \quad 0<p<1 P(X=1)=p,P(X=0)=1−p,0<p<1,则称 X X X 服从 0-1 分布,记为: X ∼ B ( 1 , p ) X \sim B(1,p) X∼B(1,p)
数学期望与方差: E ( X ) = p , D ( X ) = p ( 1 − p ) E(X)=p, \quad D(X)=p(1-p) E(X)=p,D(X)=p(1−p)
(2) 二项分布
定义:设进行 n n n 次独立重复试验,每次试验中事件 A A A 发生的概率均为 p p p,随机变量 X X X 表示 n n n 次试验中事件 A A A 发生的次数,则 X X X 服从二项分布,记为: X ∼ B ( n , p ) X \sim B(n,p) X∼B(n,p)
其分布列为: P ( X = x i ) = ( n x i ) p x i ( 1 − p ) n − x i , x i = 0 , 1 , 2 , ... , n P(X = x_i) = \binom{n}{x_i} p^{x_i}(1-p)^{n-x_i}, \quad x_i = 0,1,2,\ldots,n P(X=xi)=(xin)pxi(1−p)n−xi,xi=0,1,2,...,n
数学期望与方差: E ( X ) = n p , D ( X ) = n p ( 1 − p ) E(X)=np, \quad D(X)=np(1-p) E(X)=np,D(X)=np(1−p)
(3) 泊松分布
定义:若随机变量 X X X 的分布列为: P ( X = x i ) = λ x i e − λ x i ! , x i = 0 , 1 , 2 , ... , λ > 0 P(X = x_i) = \frac{\lambda^{x_i} e^{-\lambda}}{x_i!}, \quad x_i = 0,1,2,\ldots,\ \lambda>0 P(X=xi)=xi!λxie−λ,xi=0,1,2,..., λ>0,则称 X X X 服从参数为 λ \lambda λ 的泊松分布,记为: X ∼ P ( λ ) X \sim P(\lambda) X∼P(λ)
数学期望与方差: E ( X ) = λ , D ( X ) = λ E(X)=\lambda, \quad D(X)=\lambda E(X)=λ,D(X)=λ
补充:当 n n n 很大、 p p p 很小,且 n p = λ np=\lambda np=λ 时,二项分布可近似为泊松分布。
(4) 均匀分布
定义:若连续型随机变量 X X X 在区间 a , b a,b a,b 上的概率密度为: f ( x ) = { 1 b − a , a ≤ x ≤ b 0 , 其他 f(x)=\begin{cases} \frac{1}{b-a}, & a \le x \le b \\ 0, & \text{其他} \end{cases} f(x)={b−a1,0,a≤x≤b其他,则称 X X X 在区间 a , b a,b a,b 上服从均匀分布,记为: X ∼ U ( a , b ) X \sim U(a,b) X∼U(a,b)
分布函数为: F ( x ) = { 0 , x < a x − a b − a , a ≤ x ≤ b 1 , x > b F(x)=\begin{cases}0, & x<a \\ \frac{x-a}{b-a}, & a \le x \le b \\1, & x>b \end{cases} F(x)=⎩ ⎨ ⎧0,b−ax−a,1,x<aa≤x≤bx>b
数学期望与方差: E ( X ) = a + b 2 , D ( X ) = ( b − a ) 2 12 E(X)=\frac{a+b}{2}, \quad D(X)=\frac{(b-a)^2}{12} E(X)=2a+b,D(X)=12(b−a)2
(5) 正态分布
定义:若连续型随机变量 X X X 的概率密度为: f ( x ) = 1 2 π σ exp − ( x − μ ) 2 2 σ 2 , − ∞ < x < + ∞ , σ > 0 f(x)=\frac{1}{\sqrt{2\pi}\sigma}\exp^{-\frac{(x-\mu)^2}{2\sigma^2}}, \quad -\infty<x<+\infty,\ \sigma>0 f(x)=2π σ1exp−2σ2(x−μ)2,−∞<x<+∞, σ>0,则称 X X X 服从参数为 μ , σ 2 \mu,\sigma^2 μ,σ2 的正态分布,记为: X ∼ N ( μ , σ 2 ) X \sim N(\mu,\sigma^2) X∼N(μ,σ2)
数学期望与方差: E ( X ) = μ , D ( X ) = σ 2 E(X)=\mu, \quad D(X)=\sigma^2 E(X)=μ,D(X)=σ2
标准正态分布记为: X ∼ N ( 0 , 1 ) X \sim N(0,1) X∼N(0,1)
若 X ∼ N ( μ , σ 2 ) X \sim N(\mu,\sigma^2) X∼N(μ,σ2),则标准化后: U = X − μ σ ∼ N ( 0 , 1 ) U=\frac{X-\mu}{\sigma} \sim N(0,1) U=σX−μ∼N(0,1)
(6) 指数分布
定义:若连续型随机变量 X X X 的概率密度为: f ( x ) = { λ e − λ x , x > 0 0 , x ≤ 0 λ > 0 f(x)=\begin{cases} \lambda e^{-\lambda x}, & x>0 \\ 0, & x \le 0 \end{cases} \quad \lambda>0 f(x)={λe−λx,0,x>0x≤0λ>0,则称 X X X 服从参数为 λ \lambda λ 的指数分布。
分布函数为: F ( x ) = { 0 , x ≤ 0 1 − e − λ x , x > 0 F(x)=\begin{cases} 0, & x \le 0 \\ 1-e^{-\lambda x}, & x>0 \end{cases} F(x)={0,1−e−λx,x≤0x>0
数学期望与方差: E ( X ) = 1 λ , D ( X ) = 1 λ 2 E(X)=\frac{1}{\lambda}, \quad D(X)=\frac{1}{\lambda^2} E(X)=λ1,D(X)=λ21
常见性质:指数分布具有无记忆性。
多维随机变量的联合分布:独立时,联合等于边缘的乘积: F ( x , y ) = F X ( x ) F Y ( y ) F(x,y) =F_X(x)F_Y(y) F(x,y)=FX(x)FY(y), f ( x , y ) = f X ( x ) f Y ( y ) f(x,y)=f_X(x)f_Y(y) f(x,y)=fX(x)fY(y)
二、随机变量数字特征
1️⃣ 随机变量的期望与方差计算
数学期望:数学期望反映随机变量取值的平均水平,是随机变量的一个重要数字特征。
离散型: E ( X ) = Σ x i p i E(X) = Σ x_i p_i E(X)=Σxipi,连续型: E ( X ) = ∫ − ∞ + ∞ x f ( x ) d x E(X) = \int_{- \infty}^{+ \infty} x f(x) dx E(X)=∫−∞+∞xf(x)dx
离散型随机变量函数的期望: E g ( X ) = Σ g ( x i ) p i Eg(X) = Σ g(x_i)p_i Eg(X)=Σg(xi)pi
连续性随机变量函数的期望: E g ( X ) = ∫ − ∞ + ∞ g ( x ) f ( x ) d x Eg(X) = \int_{- \infty}^{+ \infty} g(x)f(x)dx Eg(X)=∫−∞+∞g(x)f(x)dx
方差 :方差反映随机变量取值相对于其数学期望的离散程度。其形式表达为: D ( X ) = V a r ( X ) = E ( X − E ( X ) ) 2 D(X) = Var(X) = E(X - E(X))\^2 D(X)=Var(X)=E(X−E(X))2。
常用计算式: D ( X ) = E ( X 2 ) − E ( X ) 2 D(X) = E(X^2) - E(X)^2 D(X)=E(X2)−E(X)2
2️⃣ 期望与方差的性质
线性性质 : E ( a X + b ) = a E ( X ) + b E(aX + b) = aE(X) + b E(aX+b)=aE(X)+b
方差性质 : V a r ( a X + b ) = a 2 V a r ( X ) Var(aX + b) = a^2 Var(X) Var(aX+b)=a2Var(X)
若 X, Y 独立,则: E ( X + Y ) = E ( X ) + E ( Y ) V a r ( X + Y ) = V a r ( X ) + V a r ( Y ) E(X + Y) = E(X) + E(Y) \\ Var(X + Y) = Var(X) + Var(Y) E(X+Y)=E(X)+E(Y)Var(X+Y)=Var(X)+Var(Y)
更一般地(不独立时): V a r ( X + Y ) = V a r ( X ) + V a r ( Y ) + 2 C o v ( X , Y ) Var(X + Y) = Var(X) + Var(Y) + 2Cov(X, Y) Var(X+Y)=Var(X)+Var(Y)+2Cov(X,Y)
3️⃣ 协方差与相关系数
协方差 :用于描述两个随机变量共同变化的方向和程度。协方差定义为: C o v ( X , Y ) = E ( X − E ( X ) ) ( Y − E ( Y ) ) \mathrm{Cov}(X,Y)=E(X-E(X))(Y-E(Y)) Cov(X,Y)=E(X−E(X))(Y−E(Y)),也可写为: C o v ( X , Y ) = E ( X Y ) − E ( X ) E ( Y ) \mathrm{Cov}(X,Y)=E(XY)-E(X)E(Y) Cov(X,Y)=E(XY)−E(X)E(Y)。
若二维离散型随机变量 ( X , Y ) (X,Y) (X,Y) 的联合分布为 P ( X = x i , Y = y j ) = p i j P(X=x_i,Y=y_j)=p_{ij} P(X=xi,Y=yj)=pij,则 E ( X ) = ∑ i ∑ j x i p i j , E ( Y ) = ∑ i ∑ j y j p i j E(X)=\sum_i \sum_j x_i p_{ij}, \quad E(Y)=\sum_i \sum_j y_j p_{ij} E(X)=∑i∑jxipij,E(Y)=∑i∑jyjpij, E ( X Y ) = ∑ i ∑ j x i y j p i j E(XY)=\sum_i \sum_j x_i y_j p_{ij} E(XY)=∑i∑jxiyjpij。
因此:
C o v ( X , Y ) = ∑ i ∑ j ( x i − E ( X ) ) ( y j − E ( Y ) ) p i j \mathrm{Cov}(X,Y)=\sum_i \sum_j (x_i-E(X))(y_j-E(Y))p_{ij} Cov(X,Y)=i∑j∑(xi−E(X))(yj−E(Y))pij
基本理解:
- 协方差大于 0 0 0,表示两个变量总体上同向变化。
- 协方差小于 0 0 0,表示两个变量总体上反向变化。
- 协方差等于 0 0 0,表示二者不相关,但不一定独立。
相关系数是在协方差基础上进行标准化得到的量,用来衡量线性相关程度。
相关系数定义为: ρ X Y = C o v ( X , Y ) σ X σ Y \rho_{XY}=\frac{\mathrm{Cov}(X,Y)}{\sigma_X \sigma_Y} ρXY=σXσYCov(X,Y)。协方差反映两个变量变化方向是否一致,相关系数刻画线性相关程度。
其中: − 1 ≤ ρ X Y ≤ 1 -1 \le \rho_{XY} \le 1 −1≤ρXY≤1。并且:
- ∣ ρ X Y ∣ |\rho_{XY}| ∣ρXY∣ 越接近 1 1 1,线性相关程度越强。
- ρ X Y = 1 \rho_{XY}=1 ρXY=1 表示完全正线性相关。
- ρ X Y = − 1 \rho_{XY}=-1 ρXY=−1 表示完全负线性相关。
- ρ X Y = 0 \rho_{XY}=0 ρXY=0 表示无线性相关,但不一定独立。
- ρ X Y > 0 \rho_{XY}>0 ρXY>0 表示正线性相关
- ρ X Y < 0 \rho_{XY}<0 ρXY<0 表示负线性相关
三、极限定理
0️⃣ 前置知识
(1)切比雪夫不等式 :设随机变量 X X X 的数学期望为 E ( X ) E(X) E(X),方差为 D ( X ) D(X) D(X),则对任意 ε > 0 \varepsilon>0 ε>0,有: P { ∣ X − E ( X ) ∣ ≥ ε } ≤ D ( X ) ε 2 P\{|X-E(X)|\geq \varepsilon\}\leq \frac{D(X)}{\varepsilon^2} P{∣X−E(X)∣≥ε}≤ε2D(X)。若记 σ 2 = D ( X ) \sigma^2=D(X) σ2=D(X),则也可写为: P { ∣ X − E ( X ) ∣ ≥ ε } ≤ σ 2 ε 2 P\{|X-E(X)|\geq \varepsilon\}\leq \frac{\sigma^2}{\varepsilon^2} P{∣X−E(X)∣≥ε}≤ε2σ2。等价地: P { ∣ X − E ( X ) ∣ < ε } ≥ 1 − D ( X ) ε 2 P\{|X-E(X)|< \varepsilon\}\geq 1-\frac{D(X)}{\varepsilon^2} P{∣X−E(X)∣<ε}≥1−ε2D(X)。
基本理解:切比雪夫不等式刻画了随机变量偏离其均值的概率上界。方差越小,随机变量偏离均值较远的可能性越小。它是证明大数定理的重要工具之一。
(2)依概率收敛 :设随机变量序列为: X 1 , X 2 , ... , X n , ... X_1,X_2,\ldots,X_n,\ldots X1,X2,...,Xn,...,若对任意 ε > 0 \varepsilon>0 ε>0,都有: lim n → ∞ P { ∣ X n − a ∣ < ε } = 1 \lim_{n\to\infty} P\{|X_n-a|<\varepsilon\}=1 limn→∞P{∣Xn−a∣<ε}=1,或等价地: lim n → ∞ P { ∣ X n − a ∣ ≥ ε } = 0 \lim_{n\to\infty} P\{|X_n-a|\geq \varepsilon\}=0 limn→∞P{∣Xn−a∣≥ε}=0,则称随机变量序列 X n X_n Xn 依概率收敛于常数 a a a,记为: X n → P a X_n \xrightarrow{P} a XnP a。
基本理解:当 n n n 充分大时, X n X_n Xn 取值落在 a a a 附近的概率越来越大。依概率收敛强调的是"概率意义下的接近"。大数定理中的样本均值收敛,本质上就是依概率收敛。
1️⃣ 极限定理
设随机变量序列为: X 1 , X 2 , ... , X n , ... X_1,X_2,\ldots,X_n,\ldots X1,X2,...,Xn,...,常见研究对象包括:随机变量的和、随机变量的均值、标准化后的随机变量和。其中样本和与样本均值分别为: S n = X 1 + X 2 + ⋯ + X n = ∑ i = 1 n x i S_n=X_1+X_2+\cdots+X_n=\sum_{i=1}^n x_i Sn=X1+X2+⋯+Xn=∑i=1nxi, X ˉ = 1 n ∑ i = 1 n x i \bar X=\frac{1}{n}\sum_{i=1}^n x_i Xˉ=n1∑i=1nxi。
极限定理主要回答两个问题:
- 当 n n n 很大时, X ˉ \bar X Xˉ 是否稳定在某个常数附近
- 当 n n n 很大时, S n S_n Sn 或 X ˉ \bar X Xˉ 的分布是否可由某个简单分布近似
2️⃣ 辛钦大数定理
独立同分布的随机变量序列的算数平均值依概率收敛于期望。
若 X 1 , X 2 , . . . , X n X_1, X_2, ..., X_n X1,X2,...,Xn 独立同分布,且期望存在,记: X ˉ = 1 n ∑ i = 1 n x i \bar X=\frac{1}{n}\sum_{i=1}^n x_i Xˉ=n1∑i=1nxi,则:
X ˉ → P E ( X ) \bar X \xrightarrow{P} E(X) XˉP E(X)
含义:当样本量充分大时,样本均值会稳定在总体均值附近。它揭示了"用样本均值估计总体均值"在概率意义下是可靠的。
基本理解:大数定理讨论的是"收敛到哪个值"。其核心结论是样本均值依概率收敛于数学期望。
3️⃣ 伯努利大数定理
独立重复试验中,频率依概率收敛于概率。
设在 n n n 次独立重复试验中,事件 A A A 发生了 m m m 次,记事件发生频率为: m n \frac{m}{n} nm,若每次试验中事件 A A A 发生的概率均为 p p p,则当 n → ∞ n \to \infty n→∞ 时:
m n → P p \frac{m}{n} \xrightarrow{P} p nmP p
基本理解:伯努利大数定理是大数定理在独立重复试验中的典型形式。它说明当试验次数足够多时,频率可以作为概率的近似。
4️⃣ 独立同分布的中心极限定理
独立同分布随机变量序列之和近似服从正态分布。
若 X 1 , X 2 , . . . , X n X_1, X_2, ..., X_n X1,X2,...,Xn 独立同分布,且: E ( X i ) = μ , D ( X i ) = σ 2 , i = 1 , 2 , ... , n E(X_i)=\mu, \quad D(X_i)=\sigma^2, \quad i=1,2,\ldots,n E(Xi)=μ,D(Xi)=σ2,i=1,2,...,n,则标准化后的和(或均值)在 n n n 足够大时近似服从正态分布:
∑ i = 1 n x i − n μ σ n ≈ N ( 0 , 1 ) \frac{\sum_{i=1}^n x_i-n\mu}{\sigma\sqrt{n}} \approx N(0,1) σn ∑i=1nxi−nμ≈N(0,1)
等价地:
X ˉ − μ σ / n ≈ N ( 0 , 1 ) \frac{\bar X-\mu}{\sigma/\sqrt{n}} \approx N(0,1) σ/n Xˉ−μ≈N(0,1)
理解:样本量大时,许多统计量可用正态分布近似,这是区间估计、假设检验等方法的重要理论基础。
基本理解:中心极限定理讨论的是"标准化后近似服从什么分布"。它说明大量独立随机因素叠加后往往表现出正态规律,这是数理统计中正态近似方法的理论依据。
5️⃣ 大数定理与中心极限定理的区别
- 大数定理说明样本均值会趋于总体均值,关注"收敛"。
- 中心极限定理说明标准化后的样本和或样本均值近似服从正态分布,关注"近似分布"。
- 前者回答"会不会稳定下来",后者回答"偏离均值时如何分布"。
1.1 数理统计的基本内容
- 什么是统计数据
- 什么是统计学与数理统计
- 数理统计研究什么问题
- 总体、个体、样本、样本容量等基本对象
- 参数与统计量的区别
- 描述统计与推断统计的基本思路
一、统计数据与统计学
统计工作的结果形成一系列数字资料。因此,统计数据可以理解为:通过调查、试验、观测、测量等方式收集得到的数据资料,用于反映研究对象数量特征、结构特征和变化规律的信息载体。
统计学是研究有关收集、整理和分析数据,从而对研究对象加深认识并作出一定结论的方法和理论。
二、数理统计的基本任务
数理统计就是研究如何有效地收集、整理和分析带有随机性的数据,以对所考察的问题作出推断和预测,直至为采取一定的决策和行动提供依据和建议。
( 1 )数据收集 = { 抽样技术 试验设计 (1)数据收集=\begin{cases} 抽样技术 \\ 试验设计 \end{cases} (1)数据收集={抽样技术试验设计
( 2 )统计推断 = { 参数估计 假设检验 (2)统计推断=\begin{cases} 参数估计 \\ 假设检验 \end{cases} (2)统计推断={参数估计假设检验
例:某钢厂日产某型号钢筋 10000 根,质量检查员每天抽查 50 根的强度,于是有:
(1)如何从仅有的 50 根钢筋强度数据估计整批钢筋强度的平均值?又如何估计整批钢筋强度偏离平均值的离散程度?------参数估计
(2)若规定了这种型号的钢筋强度,从抽查的 50 个强度数据如何判断整批钢筋强度的平均强度与规定标准有无差异?------假设检验
(3)若采用不同工艺,抽样的 50 个强度数据有大有小,那么强度呈现的差异是由工艺不同造成的,还是仅仅由随机因素造成的?------方差分析
(4)若钢筋强度与某种原料成分的含量有关,那么从抽查 50 根得到的强度与该成分含量的对应数据,如何表达整批钢筋强度与该成分含量之间的关系?------回归分析
三、数理统计的应用
数理统计是应用性很强的学科。在工农业生产、医药卫生、生物、环境、经济、管理、金融、保险等领域发挥着重大作用。
软件:Matlab、SPSS、 SAS、R软件(http://cran.r-project.org/bin/windows/base)。
1.2 数理统计的基本概念
一、总体和样本
1️⃣ 总体与个体
总体:研究对象的某个数量指标的全体组成的集合。
个体:总体中的每个元素称为个体。
例:研究某批灯泡的寿命,则该批灯泡寿命数据的集合就构成一个总体,其中每个灯泡的寿命就是一个个体。
2️⃣ 样本与样本容量
总体是具有随机分布的随机变量,常用 X , Y , Z X,Y,Z X,Y,Z 表示。对总体的研究归结为对随机变量 X X X 的分布及其主要数字特征的研究。如果 X X X 的分布函数为 F ( X ) F(X) F(X),则称这一总体 X X X 为具有分布函数 F ( X ) F(X) F(X) 的总体。
为了对总体的分布规律进行研究,要对总体进行抽样观测。根据观测结果来推断总体的性质。
从总体 X X X中随机抽取 n n n个个体, X 1 , X 2 , ⋯ , X n X_1, X_2, \cdots, X_n X1,X2,⋯,Xn,由这 n n n个个体组成的向量 ( X 1 , X 2 , ⋯ , X n ) (X_1, X_2, \cdots, X_n) (X1,X2,⋯,Xn)称为总体 X X X的一个样本。
样本中个体的数目 n n n 称为样本容量 或样本大小。
样本 ( X 1 , X 2 , ... , X n ) (X_1, X_2, \dots, X_n) (X1,X2,...,Xn) 可能取值的全体称为样本空间。
3️⃣ 样本的二重性
样本的二重性:既有数的属性,又有随机变量的属性。
-
一方面,在一次具体的试验或观测中,得到样本的具体数据 ( x 1 , x 2 , ... , x n ) (x_1, x_2, \dots, x_n) (x1,x2,...,xn) (样本观测值 ),称为样本 ( X 1 , X 2 , ... , X n ) (X_1, X_2, \dots, X_n) (X1,X2,...,Xn) 的一个观测值。
-
另一方面,每一个 X i X_i Xi 都是随机变量,样本 ( X 1 , X 2 , ... , X n ) (X_1, X_2, \dots, X_n) (X1,X2,...,Xn) 构成一个 n n n 维随机向量。
4️⃣ 简单随机样本及其联合分布
为使样本尽可能反映总体的特征使数据分析具有较好的性质,对抽样方法提出一定的要求。
简单随机样本:满足以下两条性质:
-
(1) 代表性 :对每个个体的观测应在完全相同的条件下进行,即 X 1 , ... , X n X_1, \dots, X_n X1,...,Xn 中的每一个 X i X_i Xi 都应该与总体 X X X 有相同的分布。
-
(2) 独立性 :对每个个体的观测应是独立进行的,即 X 1 , ... , X n X_1, \dots, X_n X1,...,Xn 是相互独立的随机变量。
简单随机样本的联合分布 :设随机变量 X X X 的分布函数为 F ( X ) F(X) F(X),则简单随机样本 ( X 1 , X 2 , ⋯ , X n ) (X_1, X_2, \cdots, X_n) (X1,X2,⋯,Xn) 的联合分布函数为 ∏ i = 1 n F ( X i ) \prod_{i=1}^n F(X_i) ∏i=1nF(Xi),联合密度函数为 ∏ i = 1 n f ( x i ) \prod_{i=1}^n f(x_i) ∏i=1nf(xi)。
例: 某城市居民收入服从正态分布 N ( μ , σ 2 ) N(\mu, \sigma^2) N(μ,σ2),概率密度函数为 f ( x ) = 1 2 π σ 2 exp − ( x − μ ) 2 2 σ 2 , − ∞ < x < ∞ f(x) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp^{-\frac{(x - \mu)^2}{2\sigma^2}}, -\infty < x < \infty f(x)=2πσ2 1exp−2σ2(x−μ)2,−∞<x<∞。随机抽取样本 ( X 1 , ⋯ , X n ) (X_1, \cdots, X_n) (X1,⋯,Xn),其联合密度为 ∏ i = 1 n f ( x i ) = ( 2 π σ 2 ) − n / 2 exp − ∑ i = 1 n ( x i − μ ) 2 2 σ 2 \prod_{i=1}^n f(x_i) = (2\pi\sigma^2)^{-n/2} \exp^{-\frac{\sum_{i=1}^n (x_i - \mu)^2}{2\sigma^2}} i=1∏nf(xi)=(2πσ2)−n/2exp−2σ2∑i=1n(xi−μ)2
如果把离散型随机变量的概率分布律也记为 f ( x ; θ ) f(x; \theta) f(x;θ),即 P { X = x } = ^ f ( x ; θ ) P\{X = x\} \hat{=} f(x; \theta) P{X=x}=^f(x;θ),则样本的联合概率分布律可表示为: f ( x 1 , x 2 , ⋯ , x n ; θ ) = ∏ i = 1 n f ( x i ; θ ) f(x_1, x_2, \cdots, x_n; \theta) = \prod_{i=1}^n f(x_i; \theta) f(x1,x2,⋯,xn;θ)=i=1∏nf(xi;θ)
例: 设总体 X X X 服从两点分布 B ( 1 , p ) B(1, p) B(1,p),其中 0 < p < 1 0 < p < 1 0<p<1, ( X 1 , X 2 , ⋯ , X n ) (X_1, X_2, \cdots, X_n) (X1,X2,⋯,Xn) 是来自总体的样本,求样本 ( X 1 , X 2 , ⋯ , X n ) (X_1, X_2, \cdots, X_n) (X1,X2,⋯,Xn) 的联合概率分布律。
解: 总体 X X X 的概率分布律为 f ( x ; p ) = P { X = x } = p x ( 1 − p ) 1 − x , x = 0 , 1 f(x; p) = P\{X = x\} = p^x (1 - p)^{1 - x}, \quad x = 0, 1 f(x;p)=P{X=x}=px(1−p)1−x,x=0,1
所以 ( X 1 , X 2 , ⋯ , X n ) (X_1, X_2, \cdots, X_n) (X1,X2,⋯,Xn) 的联合概率分布律为 f ( x 1 , x 2 , ⋯ , x n ; p ) = ∏ i = 1 n f ( x i ; p ) = ∏ i = 1 n ( p x i ( 1 − p ) 1 − x i ) = p ∑ i = 1 n x i ( 1 − p ) n − ∑ i = 1 n x i f(x_1, x_2, \cdots, x_n; p) = \prod_{i=1}^n f(x_i; p) = \prod_{i=1}^n \left( p^{x_i} (1 - p)^{1 - x_i} \right)= p^{\sum_{i=1}^n x_i} (1 - p)^{n - \sum_{i=1}^n x_i} f(x1,x2,⋯,xn;p)=i=1∏nf(xi;p)=i=1∏n(pxi(1−p)1−xi)=p∑i=1nxi(1−p)n−∑i=1nxi
其中 x 1 , x 2 , ⋯ , x n x_1, x_2, \cdots, x_n x1,x2,⋯,xn 在集合 { 0 , 1 } \{0, 1\} {0,1} 中取值。
5️⃣ 有放回抽样与无放回抽样
有放回抽样:每次抽样在完全相同的条件下进行,且相互独立。所得样本是简单随机样本。
无放回抽样:每次取后不放回。前一次抽样的结果会影响下一次抽样的概率。不是简单随机样本。
实际的抽样常常是无放回抽样(不满足简单随机样本)。但当产品总数 N 很大,而样本数 n 相对不大时,可以将无放回抽样所得到的样本近似的看成简单随机样本。
二、直方图
1️⃣ 数据分析---频率直方图
总体分布未知,根据观测结果估计总体概率密度。
绘制方法:
首先找出样本观测值的最小值和最大值,并把包含它们的区间 a , b a, b a,b 分成 m m m 等份,记 h = ( b − a ) / m h = (b - a)/m h=(b−a)/m,称为组距 (Class Interval) ,各分点为 a = c 0 < c 1 < ⋯ < c m = b a = c_0 < c_1 < \cdots < c_m = b a=c0<c1<⋯<cm=b。
分组的多少应与样本大小 n n n 相适应,分组过少会使结果太粗而丧失了一些有用的信息,分组过多会突出随机性的影响而降低稳定性。分组多少还与总体的分布性质有关。一般以 7 ∼ 18 7 \sim 18 7∼18 组为宜。有人建议一个经验法则,以 m = 1 + 3.32 lg n m = 1 + 3.32 \lg n m=1+3.32lgn 作为组数。数出样本观测值落在各区间 ( c i − 1 , c i ] (c_{i-1}, c_i] (ci−1,ci] 中的个数 n i n_i ni,称为第 i i i 组的组频数 (Class Absolute Frequency) , f i = n i / n f_i = n_i / n fi=ni/n 称为第 i i i 组的组频率 (Class Relative Frequency),有时也称前者为绝对频数,后者为相对频数。
经分组后,同一组的数据都看成是相同的,它们都等于组中值 (Mid-point of Class) ( c i − 1 + c i ) / 2 (c_{i-1} + c_i)/2 (ci−1+ci)/2,如此即得分组整理表。
如果进一步在 x x x 轴上标出点 c i ( i = 0 , 1 , ⋯ , m ) c_i (i = 0, 1, \cdots, m) ci(i=0,1,⋯,m),以各区间 ( c i − 1 , c i ] (c_{i-1}, c_i] (ci−1,ci] 为底,组频率与组距之比 y i = f i / h = n i / ( n h ) y_i = f_i / h = n_i / (nh) yi=fi/h=ni/(nh) 为高作矩形,这种图称为频率直方图 (Frequency Histogram),它是总体密度曲线的一种近似。
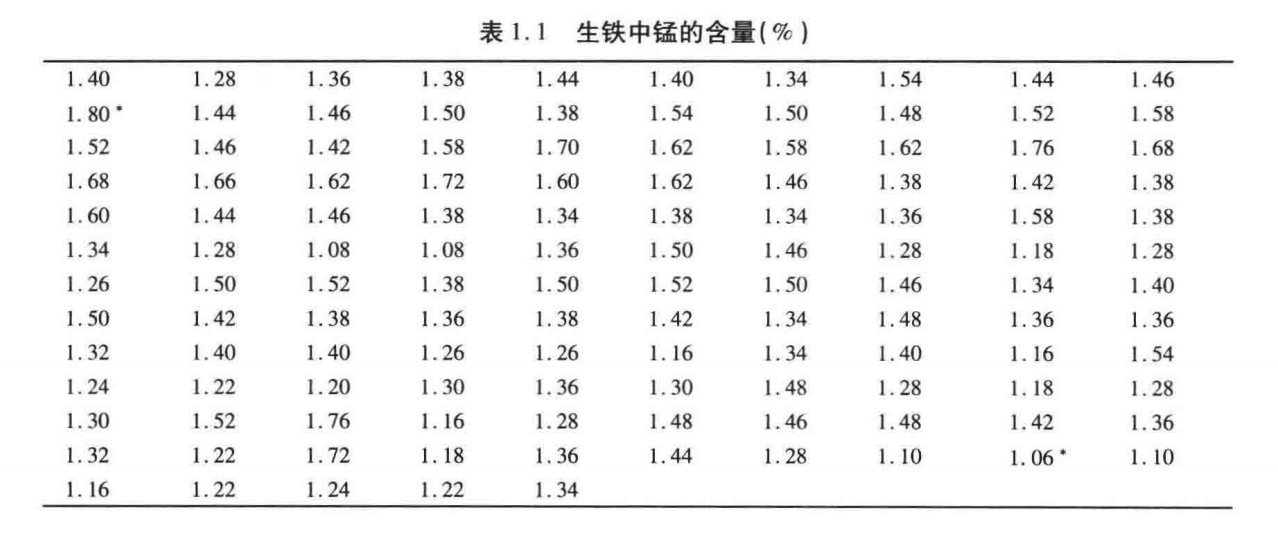
例:表中125个数据表示某高炉所炼生铁中锰的含量。R函数 hist 用于画频率直方图
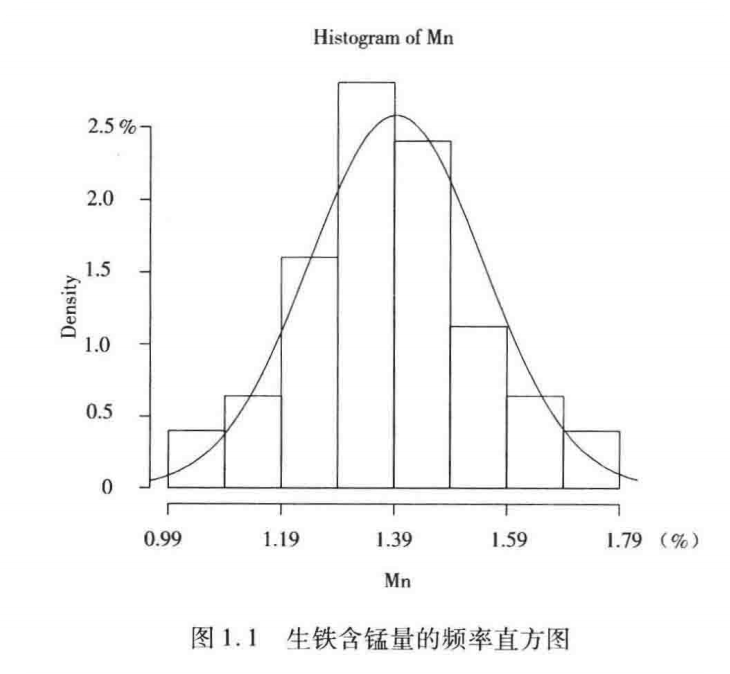

2️⃣ 数据分布的特征
从频率直方图可以看出数据分布的三个特征:
1、数据的均值(众数、算术平均值、中位数);
2、数据的变异性------极差(最大值与最小值之差)
3、曲线的形式------单峰?对称?
3️⃣ 数据均值的测度
众数:出现次数最多的变量值;具有不唯一性。
中位数:排序后处于中间位置上的值;不受极端值的影响;数据偏斜程度较大时适用。
分位数:中位数的推广,常见有四分位数。
算数平均值:有良好数学性质,集中趋势的最常用测度值,易受极端值的影响(切尾均值)。
4️⃣ 整理数据的方法
1、用图、表等将数据表达成直观的形式:频率直方图、茎叶图、箱线图。
2、构造样本的某种函数------统计量。该函数应汇集样本中与总体有关的主要信息,舍弃无关的次要部分,且不包含未知参数。
三、统计量
1️⃣ 统计量的定义
设 ( X 1 , X 2 , ⋯ , X n ) (X_1, X_2, \cdots, X_n) (X1,X2,⋯,Xn) 是来自总体 X X X 的样本, T = T ( x 1 , x 2 , ⋯ , x n ) T = T(x_1, x_2, \cdots, x_n) T=T(x1,x2,⋯,xn) 是样本空间上的实值函数,若 T ( X 1 , X 2 , ⋯ , X n ) T(X_1, X_2, \cdots, X_n) T(X1,X2,⋯,Xn) 也是随机变量,且不依赖于任何未知参数,则称 T ( X 1 , X 2 , ⋯ , X n ) T(X_1, X_2, \cdots, X_n) T(X1,X2,⋯,Xn) 为统计量(Statistics)。
借助统计量可以把样本中所包含的信息进行浓缩加工,有利于把握实质分析数据。
统计量具有二重性:既有数的属性,又有随机变量的属性。
例:设总体 X X X 服从参数为 p p p 的两点分布,即 X ∼ b ( 1 , p ) X \sim b(1, p) X∼b(1,p),其中 0 < p < 1 0 < p < 1 0<p<1 是未知参数, ( X 1 , X 2 , ⋯ , X 5 ) (X_1, X_2, \cdots, X_5) (X1,X2,⋯,X5) 是从中抽取的一个样本。则下列样本函数中,哪些是统计量,哪些不是统计量,为什么?
- T 1 = 1 5 ( X 1 + X 2 + ⋯ + X 5 ) T_1 = \frac{1}{5}(X_1 + X_2 + \cdots + X_5) T1=51(X1+X2+⋯+X5) 是
- T 2 = E ( X 1 + X 2 ) T_2 = E(X_1 + X_2) T2=E(X1+X2) 不是(两点分布的期望计算包含未知参数概率 p p p,所以它不是统计量)
- T 3 = X 1 + X 2 − 2 p T_3 = X_1 + X_2 - 2p T3=X1+X2−2p 不是(包含未知参数 p p p,所以它不是统计量)
- T 4 = max ( X 1 , X 2 , ⋯ , X 5 ) T_4 = \max(X_1, X_2, \cdots, X_5) T4=max(X1,X2,⋯,X5) 是
2️⃣ 常用的统计量
设 ( X 1 , X 2 , ⋯ , X n ) (X_1, X_2, \cdots, X_n) (X1,X2,⋯,Xn) 是取自总体 X X X 的大小为 n n n 的样本,记 X ˉ = 1 n ∑ i = 1 n X i , S 2 = 1 n − 1 ∑ i = 1 n ( X i − X ˉ ) 2 \bar{X} = \frac{1}{n} \sum_{i=1}^n X_i, \quad S^2 = \frac{1}{n-1} \sum_{i=1}^n (X_i - \bar{X})^2 Xˉ=n1i=1∑nXi,S2=n−11i=1∑n(Xi−Xˉ)2
它们都是统计量,分别称 X ˉ \bar{X} Xˉ 和 S 2 S^2 S2 为样本均值 (Sample Mean) 和样本方差 (Sample Variance)。
一般分别称统计量: A k = 1 n ∑ i = 1 n X i k , B k = 1 n ∑ i = 1 n ( X i − X ˉ ) k A_k = \frac{1}{n} \sum_{i=1}^n X_i^k, \quad B_k = \frac{1}{n} \sum_{i=1}^n (X_i - \bar{X})^k Ak=n1i=1∑nXik,Bk=n1i=1∑n(Xi−Xˉ)k
为样本的 k k k 阶(原点)矩 ( k k k-th Moment of Sample) 和样本的 k k k 阶中心矩 ( k k k-th Central Moment of Sample)。二阶中心矩 B 2 B_2 B2 有时记为 S ~ 2 \tilde{S}^2 S~2,即 S ~ 2 = 1 n ∑ i = 1 n ( X i − X ˉ ) 2 \tilde{S}^2 = \frac{1}{n} \sum_{i=1}^n (X_i - \bar{X})^2 S~2=n1∑i=1n(Xi−Xˉ)2
特别地, A 1 = X ˉ , B 2 = S ~ 2 = n − 1 n S 2 A_1 = \bar{X}, B_2 = \tilde{S}^2 = \frac{n-1}{n} S^2 A1=Xˉ,B2=S~2=nn−1S2。容易得到 S 2 = 1 n − 1 ( ∑ i = 1 n X i 2 − n X ˉ 2 ) . S^2 = \frac{1}{n-1} \left( \sum_{i=1}^n X_i^2 - n \bar{X}^2 \right). S2=n−11(i=1∑nXi2−nXˉ2).
推导过程: S 2 = 1 n − 1 ∑ i = 1 n ( X i − X ˉ ) 2 \quad S^2 = \frac{1}{n-1} \sum_{i=1}^n (X_i - \bar{X})^2 S2=n−11∑i=1n(Xi−Xˉ)2
∑ i = 1 n ( X i − X ˉ ) 2 = ∑ i = 1 n ( X i 2 − 2 X i X ˉ + X ˉ 2 ) = ∑ i = 1 n X i 2 − 2 X ˉ ∑ i = 1 n X i + n X ˉ 2 = ∑ i = 1 n X i 2 − 2 X ˉ ⋅ n X ˉ + n X ˉ 2 = ∑ i = 1 n X i 2 − n X ˉ 2 \sum_{i=1}^n (X_i - \bar{X})^2 = \sum_{i=1}^n (X_i^2 - 2X_i\bar{X} + \bar{X}^2) = \sum_{i=1}^n X_i^2 - 2\bar{X} \sum_{i=1}^n X_i + n\bar{X}^2 \\ = \sum_{i=1}^n X_i^2 - 2\bar{X} \cdot n\bar{X} + n\bar{X}^2 = \sum_{i=1}^n X_i^2 - n\bar{X}^2 i=1∑n(Xi−Xˉ)2=i=1∑n(Xi2−2XiXˉ+Xˉ2)=i=1∑nXi2−2Xˉi=1∑nXi+nXˉ2=i=1∑nXi2−2Xˉ⋅nXˉ+nXˉ2=i=1∑nXi2−nXˉ2
结论: S 2 = 1 n − 1 ( ∑ i = 1 n X i 2 − n X ˉ 2 ) S^2 = \frac{1}{n-1} \left( \sum_{i=1}^n X_i^2 - n\bar{X}^2 \right) S2=n−11(i=1∑nXi2−nXˉ2)
分别称 b s = B 3 B 2 3 / 2 , b k = B 4 B 2 2 − 3 b_s = \frac{B_3}{B_2^{3/2}}, \quad b_k = \frac{B_4}{B_2^2} - 3 bs=B23/2B3,bk=B22B4−3 为样本的偏度 (Skewness) 和峰度 (Kurtosis)。称 V = S / X ˉ V = S / \bar{X} V=S/Xˉ 为样本的变异系数 (Coefficient of Variation)。
与标准正态分布比较
- 峰度为0表示数据分布与标准正态分布的陡缓程度相同
- 偏度为0表示数据分布是对称的
变异系数(又称离散系数)是反映数据离散程度的统计量。其优点是不受数据量纲和测量尺度的影响。
3️⃣ 常用统计量的期望和方差
定理1 :设总体 X X X 的分布函数 F ( x ) F(x) F(x) 存在二阶矩, ( X 1 , X 2 , ⋯ , X n ) (X_1, X_2, \cdots, X_n) (X1,X2,⋯,Xn) 是取自这个总体的一个样本,则对样本均值 X ˉ \bar{X} Xˉ,有 E ( X ˉ ) = μ , Var ( X ˉ ) = σ 2 n . E(\bar{X}) = \mu, \quad \text{Var}(\bar{X}) = \frac{\sigma^2}{n}. E(Xˉ)=μ,Var(Xˉ)=nσ2.
证明:
E ( X ˉ ) = E ( 1 n ∑ i = 1 n X i ) = 1 n ∑ i = 1 n E ( X i ) = 1 n ∑ i = 1 n μ = μ , E(\bar{X}) = E\left(\frac{1}{n} \sum_{i=1}^n X_i\right) = \frac{1}{n} \sum_{i=1}^n E(X_i) = \frac{1}{n} \sum_{i=1}^n \mu = \mu, E(Xˉ)=E(n1i=1∑nXi)=n1i=1∑nE(Xi)=n1i=1∑nμ=μ,Var ( X ˉ ) = Var ( 1 n ∑ i = 1 n X i ) = 1 n 2 ∑ i = 1 n Var ( X i ) = 1 n 2 ∑ i = 1 n σ 2 = σ 2 n . \text{Var}(\bar{X}) = \text{Var}\left(\frac{1}{n} \sum_{i=1}^n X_i\right) = \frac{1}{n^2} \sum_{i=1}^n \text{Var}(X_i) = \frac{1}{n^2} \sum_{i=1}^n \sigma^2 = \frac{\sigma^2}{n}. Var(Xˉ)=Var(n1i=1∑nXi)=n21i=1∑nVar(Xi)=n21i=1∑nσ2=nσ2.
定理2 : 设总体 X X X 的分布函数 F ( x ) F(x) F(x) 存在二阶矩, ( X 1 , X 2 , ⋯ , X n ) (X_1, X_2, \cdots, X_n) (X1,X2,⋯,Xn) 是取自这个总体的一个样本,则对样本方差 S 2 S^2 S2,有 E ( S 2 ) = σ 2 . E(S^2) = \sigma^2. E(S2)=σ2.
证明:
E ( S 2 ) = E 1 n − 1 ( ∑ i = 1 n X i 2 − n X ˉ 2 ) = 1 n − 1 ∑ i = 1 n E ( X i 2 ) − n E ( X ˉ 2 ) = 1 n − 1 ∑ i = 1 n ( σ 2 + μ 2 ) − n ( σ 2 n + μ 2 ) = σ 2 . E(S^2) = E\left\\frac{1}{n-1} \\left(\\sum_{i=1}\^n X_i\^2 - n\\bar{X}\^2\\right)\\right = \frac{1}{n-1} \left\\sum_{i=1}\^n E(X_i\^2) - nE(\\bar{X}\^2)\\right \\ = \frac{1}{n-1} \left\\sum_{i=1}\^n (\\sigma\^2 + \\mu\^2) - n\\left(\\frac{\\sigma\^2}{n} + \\mu\^2\\right)\\right = \sigma^2. E(S2)=En−11(i=1∑nXi2−nXˉ2)=n−11i=1∑nE(Xi2)−nE(Xˉ2)=n−11i=1∑n(σ2+μ2)−n(nσ2+μ2)=σ2.证明中利用了公式: E ( X 2 ) = Var ( X ) + E ( X ) 2 E(X^2) = \text{Var}(X) + E(X)^2 E(X2)=Var(X)+E(X)2。
- 对于单个样本 X i X_i Xi,其 E ( X i 2 ) = σ 2 + μ 2 E(X_i^2) = \sigma^2 + \mu^2 E(Xi2)=σ2+μ2。
- 对于样本均值 X ˉ \bar{X} Xˉ,其 E ( X ˉ 2 ) = σ 2 n + μ 2 E(\bar{X}^2) = \frac{\sigma^2}{n} + \mu^2 E(Xˉ2)=nσ2+μ2。
记 E ( X ) ≜ μ , Var ( X ) ≜ σ 2 , E ( X k ) ≜ α k , E ( X − μ ) k ≜ μ k E(X) \triangleq \mu, \quad \text{Var}(X) \triangleq \sigma^2, \quad E(X^k) \triangleq \alpha_k, \quad E(X - \mu)^k \triangleq \mu_k E(X)≜μ,Var(X)≜σ2,E(Xk)≜αk,E(X−μ)k≜μk 分别表示总体的均值、方差、 k k k 阶原点矩、 k k k 阶中心矩。
并且约定,当用到 α k \alpha_k αk 或 μ k \mu_k μk 时,假定它们是存在的。显然, α 1 = μ , μ 2 = σ 2 \alpha_1 = \mu, \mu_2 = \sigma^2 α1=μ,μ2=σ2。
定理3 : 设总体 X X X 的分布函数 F ( x ) F(x) F(x) 存在 2 k 2k 2k 阶矩, ( X 1 , X 2 , ⋯ , X n ) (X_1, X_2, \cdots, X_n) (X1,X2,⋯,Xn) 是取自这个总体的一个样本,则对 k k k 阶样本矩 A k A_k Ak,有 E ( A k ) = α k , Var ( A k ) = α 2 k − α k 2 n . E(A_k) = \alpha_k, \quad \text{Var}(A_k) = \frac{\alpha_{2k} - \alpha_k^2}{n}. E(Ak)=αk,Var(Ak)=nα2k−αk2.
证明:
E ( A k ) = E ( 1 n ∑ i = 1 n X i k ) = 1 n ∑ i = 1 n E ( X i k ) = α k . E(A_k) = E\left(\frac{1}{n} \sum_{i=1}^n X_i^k\right) = \frac{1}{n} \sum_{i=1}^n E(X_i^k) = \alpha_k. E(Ak)=E(n1i=1∑nXik)=n1i=1∑nE(Xik)=αk.
Var ( A k ) = E ( A k 2 ) − E ( A k ) 2 = E ( 1 n ∑ i = 1 n X i k ) 2 − α k 2 = E ( 1 n 2 ∑ i = 1 n X i 2 k + 1 n 2 ∑ ∑ i ≠ j X i k X j k ) − α k 2 = 1 n α 2 k + 1 n 2 n ( n − 1 ) α k 2 − α k 2 = α 2 k − α k 2 n . \text{Var}(A_k) = E(A_k^2) - E(A_k)^2 = E\left(\frac{1}{n} \sum_{i=1}^n X_i^k\right)^2 - \alpha_k^2 \\ = E\left(\frac{1}{n^2} \sum_{i=1}^n X_i^{2k} + \frac{1}{n^2} \sum \sum_{i \neq j} X_i^k X_j^k\right) - \alpha_k^2 \\ = \frac{1}{n} \alpha_{2k} + \frac{1}{n^2} n(n-1) \alpha_k^2 - \alpha_k^2 = \frac{\alpha_{2k} - \alpha_k^2}{n}. Var(Ak)=E(Ak2)−E(Ak)2=E(n1i=1∑nXik)2−αk2=E n21i=1∑nXi2k+n21∑i=j∑XikXjk −αk2=n1α2k+n21n(n−1)αk2−αk2=nα2k−αk2.
样本矩的以上性质是普遍成立的,而不论总体分布 F ( x ) F(x) F(x) 具有什么形式。
4️⃣ 次序统计量与经验分布函数
次序统计量 :设 ( X 1 , X 2 , ⋯ , X n ) (X_1, X_2, \cdots, X_n) (X1,X2,⋯,Xn) 为来自总体 X X X 的样本, ( x 1 , x 2 , ⋯ , x n ) (x_1, x_2, \cdots, x_n) (x1,x2,⋯,xn) 是样本观测值,将它们由小到大排序为: x 1 ∗ ≤ x 2 ∗ ≤ ⋯ ≤ x n ∗ x_1^* \leq x_2^* \leq \cdots \leq x_n^* x1∗≤x2∗≤⋯≤xn∗
当 ( X 1 , X 2 , ⋯ , X n ) (X_1, X_2, \cdots, X_n) (X1,X2,⋯,Xn) 取值为 ( x 1 , x 2 , ⋯ , x n ) (x_1, x_2, \cdots, x_n) (x1,x2,⋯,xn) 时,定义随机变量 X ( k ) = x k ∗ , k = 1 , 2 , ⋯ , n X_{(k)} = x_k^*, \quad k = 1, 2, \cdots, n X(k)=xk∗,k=1,2,⋯,n,则称统计量 X ( 1 ) , X ( 2 ) , ⋯ , X ( n ) X_{(1)}, X_{(2)}, \cdots, X_{(n)} X(1),X(2),⋯,X(n) 为次序统计量。称 X ( i ) X_{(i)} X(i) 为第 i i i 个次序统计量。
注: X ( 1 ) , X ( 2 ) , ⋯ , X ( n ) X_{(1)}, X_{(2)}, \cdots, X_{(n)} X(1),X(2),⋯,X(n) 不独立。称 X ( 1 ) = min { X 1 , X 2 , ⋯ , X n } X_{(1)} = \min \{X_1, X_2, \cdots, X_n\} X(1)=min{X1,X2,⋯,Xn} 为最小次序统计量, X ( n ) = max { X 1 , X 2 , ⋯ , X n } X_{(n)} = \max \{X_1, X_2, \cdots, X_n\} X(n)=max{X1,X2,⋯,Xn} 为最大次序统计量,称 D n = X ( n ) − X ( 1 ) D_n = X_{(n)} - X_{(1)} Dn=X(n)−X(1) 为极差。
次序统计量的分布
最大次序统计量 X ( n ) X_{(n)} X(n) 分布函数为: F ( n ) ( x ) = P { X ( n ) ≤ x } = P { X 1 ≤ x , X 2 ≤ x , ⋯ , X n ≤ x } F_{(n)}(x) = P\{X_{(n)} \leq x\} = P\{X_1 \leq x, X_2 \leq x, \cdots, X_n \leq x\} F(n)(x)=P{X(n)≤x}=P{X1≤x,X2≤x,⋯,Xn≤x} = P { X 1 ≤ x } ⋅ P { X 2 ≤ x } ⋯ P { X n ≤ x } = F ( x ) n = P\{X_1 \leq x\} \cdot P\{X_2 \leq x\} \cdots P\{X_n \leq x\} = F(x)^n =P{X1≤x}⋅P{X2≤x}⋯P{Xn≤x}=F(x)n
(1) 最小次序统计量 X ( 1 ) X_{(1)} X(1) 的概率密度为 f X ( 1 ) ( x ; θ ) = n 1 − F ( x ; θ ) n − 1 f ( x ; θ ) f_{X_{(1)}}(x; \theta) = n1 - F(x; \\theta)^{n-1} f(x; \theta) fX(1)(x;θ)=n1−F(x;θ)n−1f(x;θ)
分布函数为 F ( 1 ) ( x ) = 1 − 1 − F ( x ) n F_{(1)}(x) = 1 - 1 - F(x)^n F(1)(x)=1−1−F(x)n
(2) 最大次序统计量 X ( n ) X_{(n)} X(n) 的概率密度为 f X ( n ) ( x ; θ ) = n F ( x ; θ ) n − 1 f ( x ; θ ) f_{X_{(n)}}(x; \theta) = nF(x; \\theta)^{n-1} f(x; \theta) fX(n)(x;θ)=nF(x;θ)n−1f(x;θ)
分布函数为 F ( n ) ( x ) = F ( x ) n F_{(n)}(x) = F(x)^n F(n)(x)=F(x)n
例: 设总体 X X X 服从 ( 0 , θ ) (0, \theta) (0,θ) 上的均匀分布, ( X 1 , ⋯ , X n ) (X_1, \cdots, X_n) (X1,⋯,Xn) 是来自 X X X 的样本. 分别求最小次序统计量 X ( 1 ) X_{(1)} X(1) 和最大次序统计量 X ( n ) X_{(n)} X(n) 的概率密度函数.
解: 总体 X X X 的概率密度为 f ( x ; θ ) = { 1 θ , 0 ≤ x ≤ θ ; 0 , 其他. f(x; \theta) = \begin{cases} \frac{1}{\theta}, & 0 \leq x \leq \theta; \\ 0, & \text{其他.} \end{cases} f(x;θ)={θ1,0,0≤x≤θ;其他.
X X X 的分布函数为 F ( x ; θ ) = { 0 , x < 0 ; x θ , 0 ≤ x < θ ; 1 , θ ≤ x . F(x; \theta) = \begin{cases} 0, & x < 0; \\ \frac{x}{\theta}, & 0 \leq x < \theta; \\ 1, & \theta \leq x. \end{cases} F(x;θ)=⎩ ⎨ ⎧0,θx,1,x<0;0≤x<θ;θ≤x.所以, X ( 1 ) X_{(1)} X(1) 的概率密度为 f X ( 1 ) ( x ; θ ) = { n θ ( 1 − x θ ) n − 1 , 0 ≤ x ≤ θ ; 0 , 其他. f_{X_{(1)}}(x; \theta) = \begin{cases} \frac{n}{\theta} \left( 1 - \frac{x}{\theta} \right)^{n-1}, & 0 \leq x \leq \theta; \\ 0, & \text{其他.} \end{cases} fX(1)(x;θ)={θn(1−θx)n−1,0,0≤x≤θ;其他.
X ( n ) X_{(n)} X(n) 的概率密度为 f X ( n ) ( x ; θ ) = { n θ n x n − 1 , 0 ≤ x ≤ θ ; 0 , 其他. f_{X_{(n)}}(x; \theta) = \begin{cases} \frac{n}{\theta^n} x^{n-1}, & 0 \leq x \leq \theta; \\ 0, & \text{其他.} \end{cases} fX(n)(x;θ)={θnnxn−1,0,0≤x≤θ;其他.。
第 i 个次序统计量的分布
用 v n ( x ) v_n(x) vn(x) 表示 ( X 1 , X 2 , ⋯ , X n ) (X_1, X_2, \cdots, X_n) (X1,X2,⋯,Xn) 中不超过 x x x 的观测值的个数。 ∵ F ( x ) = P { X ≤ x } \because F(x) = P\{X \leq x\} ∵F(x)=P{X≤x},则 v n ( x ) ∼ b ( n , F ( x ) ) v_n(x) \sim b(n, F(x)) vn(x)∼b(n,F(x))(服从二项分布)。第 i i i 个次序统计量的分布函数为 F ( i ) ( x ) = P { X ( i ) ≤ x } = P { v n ( x ) ≥ i } F_{(i)}(x) = P\{X_{(i)} \leq x\} = P\{v_n(x) \geq i\} F(i)(x)=P{X(i)≤x}=P{vn(x)≥i}
由二项分布的分布律 = ∑ k = i n ( n k ) F ( x ) k 1 − F ( x ) n − k = \sum_{k=i}^n \binom{n}{k} F(x)^k 1 - F(x)^{n-k} =k=i∑n(kn)F(x)k1−F(x)n−k
第 i 个次序统计量 X ( i ) X_{(i)} X(i)的分布密度函数为: f i ( x ) = n ! ( i − 1 ) ! ( n − i ) ! F ( x ) i − 1 1 − F ( x ) n − i f ( x ) f_i(x) = \frac{n!}{(i-1)!(n-i)!} F(x)^{i-1} 1 - F(x)^{n-i} f(x) fi(x)=(i−1)!(n−i)!n!F(x)i−11−F(x)n−if(x)
例: 设总体 X X X 的密度函数为 f ( x ) = { 2 x , 0 < x < 1 0 , 其他 f(x) = \begin{cases} 2x, & 0 < x < 1 \\ 0, & \text{其他} \end{cases} f(x)={2x,0,0<x<1其他, ( X 1 , X 2 , X 3 , X 4 ) (X_1, X_2, X_3, X_4) (X1,X2,X3,X4) 为取自总体的一个样本,求 X ( 3 ) X_{(3)} X(3) 的分布函数,并计算 P ( X ( 3 ) > 1 2 ) P(X_{(3)} > \frac{1}{2}) P(X(3)>21)。
F 3 ( x ) = ∑ k = 3 4 ( 4 k ) F ( x ) k 1 − F ( x ) 4 − k = { 0 , x ≤ 0 4 x 6 − 3 x 8 , 0 < x ≤ 1 1 , x > 1 F_3(x) = \sum_{k=3}^4 \binom{4}{k} F(x)^k 1 - F(x)^{4-k} = \begin{cases} 0, & x \leq 0 \\ 4x^6 - 3x^8, & 0 < x \leq 1 \\ 1, & x > 1 \end{cases} F3(x)=k=3∑4(k4)F(x)k1−F(x)4−k=⎩ ⎨ ⎧0,4x6−3x8,1,x≤00<x≤1x>1 P ( X ( 3 ) > 1 2 ) = 243 256 P\left(X_{(3)} > \frac{1}{2}\right) = \frac{243}{256} P(X(3)>21)=256243
经验分布函数
定义 :设 ( X 1 , X 2 , ... , X n ) (X_1, X_2, \dots, X_n) (X1,X2,...,Xn) 是取自分布函数为 F ( x ) F(x) F(x) 的总体 X X X 的一个样本,则称 F n ( x ) = v n ( x ) n F_n(x) = \frac{v_n(x)}{n} Fn(x)=nvn(x)
为经验分布函数 (Empirical Distribution Function),简记为 EDF。
易见,对每一个样本观测值 ( x 1 , x 2 , ... , x n ) (x_1, x_2, \dots, x_n) (x1,x2,...,xn), F n ( x ) F_n(x) Fn(x) 是一分布函数。事实上,把 x 1 , x 2 , ... , x n x_1, x_2, \dots, x_n x1,x2,...,xn 按大小排列为 x ( 1 ) ≤ x ( 2 ) ≤ ⋯ ≤ x ( n ) x_{(1)} \leq x_{(2)} \leq \dots \leq x_{(n)} x(1)≤x(2)≤⋯≤x(n),那么, F n ( x ) = { 0 , x < x ( 1 ) ; k n , x ( k ) ≤ x < x ( k + 1 ) , k = 1 , 2 , ... , n − 1 ; 1 , x ( n ) ≤ x . F_n(x) = \begin{cases} 0, & x < x_{(1)}; \\ \frac{k}{n}, & x_{(k)} \leq x < x_{(k+1)}, k=1, 2, \dots, n-1; \\ 1, & x_{(n)} \leq x. \end{cases} Fn(x)=⎩ ⎨ ⎧0,nk,1,x<x(1);x(k)≤x<x(k+1),k=1,2,...,n−1;x(n)≤x.
因此, 0 ≤ F n ( x ) ≤ 1 0 \leq F_n(x) \leq 1 0≤Fn(x)≤1,且作为 x x x 的函数是一个非减右连续函数,在 x = x ( k ) x = x_{(k)} x=x(k) 有间断点,在每个间断点上有跃度 1 n \frac{1}{n} n1。 F n ( x ) F_n(x) Fn(x) 具备分布函数所要求的性质,故称为经验分布函数。
设总体 X X X 服从两点分布 b ( 1 , p ) b(1, p) b(1,p), ( X 1 , X 2 , ⋯ , X n ) (X_1, X_2, \cdots, X_n) (X1,X2,⋯,Xn) 为取自这个总体的样本,设样本观测值 ( x 1 , x 2 , ⋯ , x n ) (x_1, x_2, \cdots, x_n) (x1,x2,⋯,xn) 中有 m m m 个 0 , n − m 0, n-m 0,n−m 个 1 1 1,则此样本的经验分布函数为 _____ F n ( x ) = { 0 , x < 0 m n , 0 ≤ x < 1 1 , x ≥ 1 F_n(x) = \begin{cases} 0, & x < 0 \\ \frac{m}{n}, & 0 \leq x < 1 \\ 1, & x \geq 1 \end{cases} Fn(x)=⎩ ⎨ ⎧0,nm,1,x<00≤x<1x≥1
经验分布函数的性质
F n ( x ) F_n(x) Fn(x) 满足分布函数的特征,是一个分布函数。
0 ≤ F n ( x ) ≤ 1 0 \leq F_n(x) \leq 1 0≤Fn(x)≤1; F n ( x ) F_n(x) Fn(x) 单调不减;右连续;
F n ( x ) F_n(x) Fn(x) 在 x = x ( k ) x = x_{(k)} x=x(k) 有间断点,在每个间断点上有跃度 1 n \frac{1}{n} n1。
经验分布函数与分布函数的关系
(1) F n ( x ) = ν n ( x ) n F_n(x) = \frac{\nu_n(x)}{n} Fn(x)=nνn(x) 表示 { X ≤ x } \{X \le x\} {X≤x} 的频率,若记 F ( x ) = P { X ≤ x } F(x) = P\{X \le x\} F(x)=P{X≤x},则 ν n ( x ) ∼ b ( n , F ( x ) ) \nu_n(x) \sim b(n, F(x)) νn(x)∼b(n,F(x))。由二项分布知 E ν n ( x ) = n F ( x ) E\\nu_n(x) = nF(x) Eνn(x)=nF(x),则 E F n ( x ) = F ( x ) EF_n(x) = F(x) EFn(x)=F(x)。$
(2) F n ( x ) F_n(x) Fn(x) 依概率收敛于 F ( x ) F(x) F(x)。即 lim n → ∞ P { ∣ F n ( x ) − F ( x ) ∣ < ϵ } = 1 ( ∀ ϵ > 0 ) \lim_{n \to \infty} P\{ |F_n(x) - F(x)| < \epsilon \} = 1 \quad (\forall \epsilon > 0) limn→∞P{∣Fn(x)−F(x)∣<ϵ}=1(∀ϵ>0)。
Glivenko 定理 : 设总体 X X X 的分布函数为 F ( x ) F(x) F(x),经验分布函数为 F n ( x ) F_n(x) Fn(x),记 D n = sup − ∞ < x < + ∞ ∣ F n ( x ) − F ( x ) ∣ , D_n = \sup_{-\infty < x < +\infty} | F_n(x) - F(x) |, Dn=−∞<x<+∞sup∣Fn(x)−F(x)∣,
则有 P { lim n → ∞ D n = 0 } = 1 P\{\lim_{n \to \infty} D_n = 0\} = 1 P{limn→∞Dn=0}=1,经验分布函数以概率 1 收敛于分布函数。
D n D_n Dn 代表了经验分布函数(那个锯齿状的阶梯)与理论分布函数(平滑曲线)之间最大的垂直距离。
sup \sup sup (上确界):意味着要找在整个 x x x 轴上,这两个函数"离得最远"的地方。
注:(1) 当 n n n 很大时,由每一组样本观测值得到的经验分布函数 F n ( x ) F_n(x) Fn(x) 都是总体分布 F ( x ) F(x) F(x) 的一个良好近似。(样本推断总体)
(2) 两种近似方法: 频率直方图(密度);经验分布函数(分布)
p p p 分位数
设 p p p 满足 0 < p < 1 0 < p < 1 0<p<1,若 x p x_p xp 使 P { X ≤ x p } = F ( x p ) = p P\{X \leq x_p\} = F(x_p) = p P{X≤xp}=F(xp)=p,则称 x p x_p xp 为该分布的 p p p 分位数。
例如,若 X ∼ N ( 0 , 1 ) X \sim N(0, 1) X∼N(0,1),则 P { X ≤ x } = Φ ( x ) P\{X \leq x\} = \Phi(x) P{X≤x}=Φ(x),查标准正态分布表得, Φ ( 1.645 ) = 0.95 \Phi(1.645) = 0.95 Φ(1.645)=0.95,即 P { X ≤ 1.645 } = 0.95 P\{X \leq 1.645\} = 0.95 P{X≤1.645}=0.95。记 u p u_p up 为标准正态分布的 p p p 分位数,则 u 0.95 = 1.645 u_{0.95} = 1.645 u0.95=1.645
样本分位数
定义: 设 ( X 1 , ⋯ , X n ) (X_1, \cdots, X_n) (X1,⋯,Xn) 为总体 X X X 的一个样本, ( X ( 1 ) , ⋯ , X ( n ) ) (X_{(1)}, \cdots, X_{(n)}) (X(1),⋯,X(n)) 为次序统计量,对任 0 < p < 1 0 < p < 1 0<p<1,称 x p ∗ = X ( n p + 1 ) x_p^* = X_{(np + 1)} xp∗=X(np+1) 为样本 p p p 分位数。其中 a a a 表示不超过 a a a 的最大整数,特别当 p = 1 2 p = \frac{1}{2} p=21 时, x 1 2 ∗ x_{\frac{1}{2}}^* x21∗ 称为样本中位数。 x 1 2 ∗ = { X ( n + 1 2 ) , 当 n 为奇数 ; 1 2 X ( n 2 ) + X ( n 2 + 1 ) , 当 n 为偶数 . x_{\frac{1}{2}}^* = \begin{cases} X_{(\frac{n+1}{2})}, & \text{当 } n \text{ 为奇数}; \\ \frac{1}{2} \left X_{(\\frac{n}{2})} + X_{(\\frac{n}{2}+1)} \\right, & \text{当 } n \text{ 为偶数}. \end{cases} x21∗={X(2n+1),21X(2n)+X(2n+1),当 n 为奇数;当 n 为偶数.
样本 p p p 分位数与总体 p p p 分位数的关系
定理: 设总体 X X X 具有密度函数 f ( x ) f(x) f(x), x p x_p xp 为 p p p 分位数 ( 0 < p < 1 0 < p < 1 0<p<1),若 f ( x ) f(x) f(x) 在 x = x p x = x_p x=xp 处连续且不为零,则样本 p p p 分位数 x p ∗ x_p^* xp∗ 渐近服从正态分布: N ( x p , p ( 1 − p ) n f 2 ( x p ) ) N\left(x_p, \frac{p(1-p)}{nf^2(x_p)}\right) N(xp,nf2(xp)p(1−p))