【TJU】研究生应用统计学课程笔记(2)------第一章 数理统计的基本知识
- [1.3 统计中常用的分布族](#1.3 统计中常用的分布族)
-
- [1.3.1 Gamma分布族](#1.3.1 Gamma分布族)
-
- [1️⃣ Gamma分布族的定义](#1️⃣ Gamma分布族的定义)
- [2️⃣ Gamma分布族的性质](#2️⃣ Gamma分布族的性质)
- [1.3.1 卡方分布族](#1.3.1 卡方分布族)
-
- [1️⃣ 卡方分布的定义](#1️⃣ 卡方分布的定义)
- [2️⃣ 卡方分布的性质](#2️⃣ 卡方分布的性质)
- [1.3.3 Beta 分布族](#1.3.3 Beta 分布族)
-
- [1️⃣ Beta 分布族的定义](#1️⃣ Beta 分布族的定义)
- [2️⃣ Beta 分布族的性质](#2️⃣ Beta 分布族的性质)
- [1.3.4 F分布族](#1.3.4 F分布族)
-
- [1️⃣ F分布族的定义](#1️⃣ F分布族的定义)
- [2️⃣ F分布族的性质](#2️⃣ F分布族的性质)
- [1.3.4 t分布族](#1.3.4 t分布族)
-
- [1️⃣ t分布族的定义](#1️⃣ t分布族的定义)
- [2️⃣ t分布族的性质](#2️⃣ t分布族的性质)
- [1.3.5 分位数](#1.3.5 分位数)
-
- [1️⃣ p分位数定义及其性质](#1️⃣ p分位数定义及其性质)
- [2️⃣ 三大分布的分位数表](#2️⃣ 三大分布的分位数表)
- [1.3.6 多元正态分布](#1.3.6 多元正态分布)
-
- [1️⃣ 多元正态分布的定义](#1️⃣ 多元正态分布的定义)
- [2️⃣ 多元正态分布的期望和方差](#2️⃣ 多元正态分布的期望和方差)
- [3️⃣ 多元正态分布的协方差和相关系数](#3️⃣ 多元正态分布的协方差和相关系数)
- [4️⃣ 多元正态分布的性质](#4️⃣ 多元正态分布的性质)
- [1.3.7 指数型分布族](#1.3.7 指数型分布族)
-
- [1️⃣ 指数型分布族的定义](#1️⃣ 指数型分布族的定义)
1.3 统计中常用的分布族
分布函数族 : F ( x ; θ ) F(x; \theta) F(x;θ) 表示 X X X 的分布,参数 θ \theta θ 可能取值的集合称为参数空间,记作 Θ \Theta Θ,称 { F ( x ; θ ) : θ ∈ Θ } \{F(x; \theta) : \theta \in \Theta\} {F(x;θ):θ∈Θ} 为 X X X 的分布函数族。
(1) 正态分布族 : { N ( μ , σ 2 ) : θ ∈ Θ } \{N(\mu, \sigma^2) : \theta \in \Theta\} {N(μ,σ2):θ∈Θ},其中 Θ = { ( μ , σ 2 ) : − ∞ < μ < ∞ , σ 2 > 0 } \Theta = \{(\mu, \sigma^2) : -\infty < \mu < \infty, \sigma^2 > 0\} Θ={(μ,σ2):−∞<μ<∞,σ2>0}
(2) 二项分布族 : { b ( n , p ) : 0 < p < 1 } \{b(n, p) : 0 < p < 1\} {b(n,p):0<p<1}
(3) Possion 分布族 : { P ( λ ) : λ > 0 } \{P(\lambda) : \lambda > 0\} {P(λ):λ>0}
(4) 均匀分布族 : { R ( a , b ) : − ∞ < a < b < ∞ } \{R(a, b) : -\infty < a < b < \infty\} {R(a,b):−∞<a<b<∞}
(5) 指数分布族 : { E x p ( λ ) : λ > 0 } \{Exp(\lambda) : \lambda > 0\} {Exp(λ):λ>0}
1.3.1 Gamma分布族
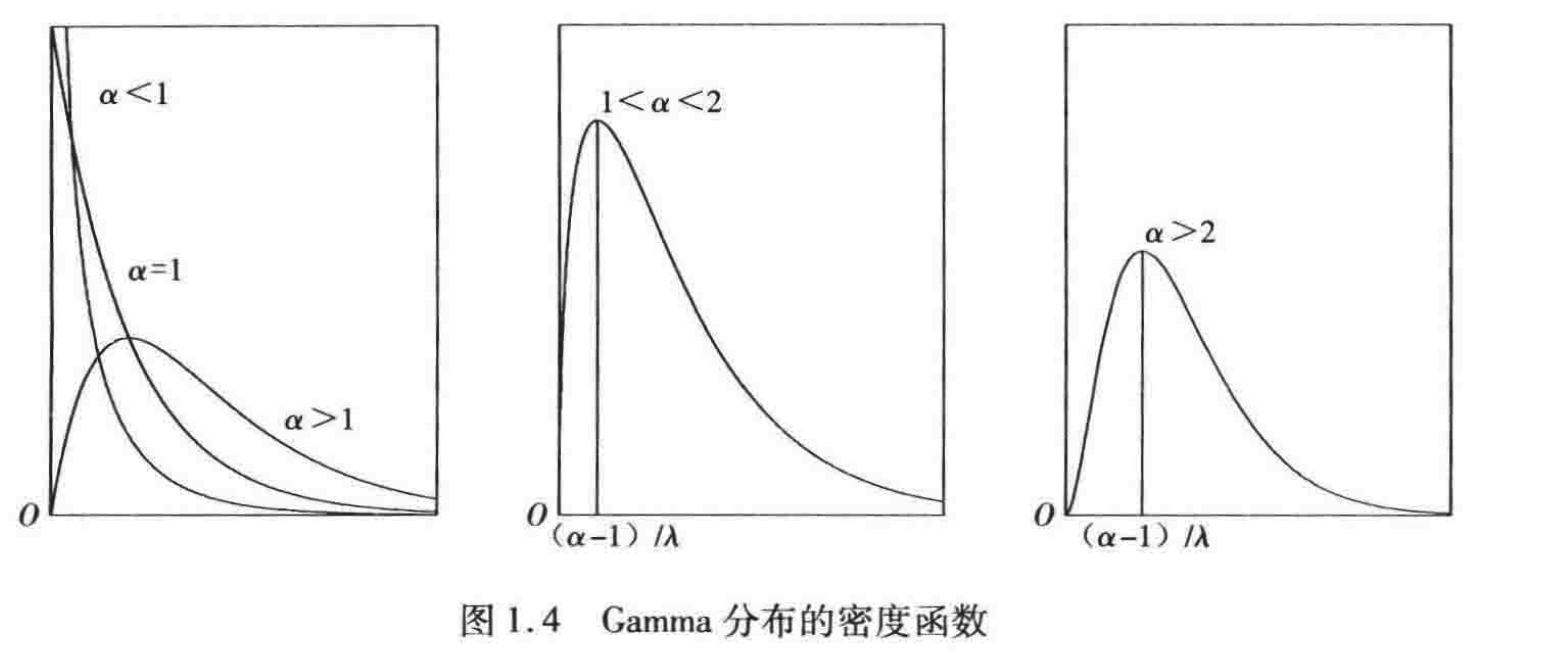
1️⃣ Gamma分布族的定义
若随机变量 X X X 具有密度函数 f ( x : α , λ ) = λ α Γ ( α ) x α − 1 e − λ x , x > 0 f(x : \alpha, \lambda) = \frac{\lambda^\alpha}{\Gamma(\alpha)} x^{\alpha-1} e^{-\lambda x}, \quad x > 0 f(x:α,λ)=Γ(α)λαxα−1e−λx,x>0
则称 X X X 所服从的分布为 Gamma 分布,记作 G a ( α , λ ) Ga(\alpha, \lambda) Ga(α,λ)。其中: α > 0 \alpha > 0 α>0 是形状参数。 λ > 0 \lambda > 0 λ>0 是尺度参数。 { G a ( α , λ ) : α > 0 , λ > 0 } \{Ga(\alpha, \lambda) : \alpha > 0, \lambda > 0\} {Ga(α,λ):α>0,λ>0} 称为 Gamma 分布族。
Γ \Gamma Γ-函数: Γ ( a ) = ∫ 0 + ∞ x a − 1 e − x d x \Gamma(a) = \int_0^{+\infty} x^{a-1} e^{-x} dx Γ(a)=∫0+∞xa−1e−xdx
常用性质: Γ ( 1 2 ) = π \Gamma\left(\frac{1}{2}\right) = \sqrt{\pi} Γ(21)=π ; Γ ( 1 ) = 1 \Gamma(1) = 1 Γ(1)=1; Γ ( n + 1 ) = n Γ ( n ) \Gamma(n+1) = n\Gamma(n) Γ(n+1)=nΓ(n)。
由定义可知,当 α = 1 \alpha = 1 α=1 时, G a ( 1 , λ ) Ga(1, \lambda) Ga(1,λ) 就是参数为 λ \lambda λ 的指数分布。
2️⃣ Gamma分布族的性质
(1) 若 X ∼ G a ( α , λ ) X \sim Ga(\alpha, \lambda) X∼Ga(α,λ),则 E ( X ) = α λ , D ( X ) = α λ 2 E(X) = \frac{\alpha}{\lambda},\quad D(X) = \frac{\alpha}{\lambda^2} E(X)=λα,D(X)=λ2α。
证明: ∵ f ( x ) = λ α Γ ( α ) x α − 1 e − λ x , x > 0 \because f(x) = \frac{\lambda^\alpha}{\Gamma(\alpha)} x^{\alpha-1} e^{-\lambda x}, \quad x > 0 ∵f(x)=Γ(α)λαxα−1e−λx,x>0
E X = ∫ − ∞ + ∞ x f ( x ) d x = ∫ 0 + ∞ λ α Γ ( α ) x α e − λ x d x = 1 Γ ( α ) ∫ 0 + ∞ ( λ x ) α e − λ x d x EX = \int_{-\infty}^{+\infty} x f(x) dx = \int_0^{+\infty} \frac{\lambda^\alpha}{\Gamma(\alpha)} x^\alpha e^{-\lambda x} dx = \frac{1}{\Gamma(\alpha)} \int_0^{+\infty} (\lambda x)^\alpha e^{-\lambda x} dx EX=∫−∞+∞xf(x)dx=∫0+∞Γ(α)λαxαe−λxdx=Γ(α)1∫0+∞(λx)αe−λxdx = 1 λ Γ ( α ) ∫ 0 + ∞ t α e − t d t = 1 λ Γ ( α ) Γ ( α + 1 ) = α λ = \frac{1}{\lambda \Gamma(\alpha)} \int_0^{+\infty} t^\alpha e^{-t} dt = \frac{1}{\lambda \Gamma(\alpha)} \Gamma(\alpha + 1) = \frac{\alpha}{\lambda} =λΓ(α)1∫0+∞tαe−tdt=λΓ(α)1Γ(α+1)=λα类似地, E X 2 = α ( α + 1 ) λ 2 EX^2 = \frac{\alpha(\alpha + 1)}{\lambda^2} EX2=λ2α(α+1)所以 D X = E X 2 − ( E X ) 2 = α λ 2 DX = EX^2 - (EX)^2 = \frac{\alpha}{\lambda^2} DX=EX2−(EX)2=λ2α
(2)可加性: 设 X 1 ∼ G a ( α 1 , λ ) , X 2 ∼ G a ( α 2 , λ ) X_1 \sim Ga(\alpha_1, \lambda), X_2 \sim Ga(\alpha_2, \lambda) X1∼Ga(α1,λ),X2∼Ga(α2,λ),且 X 1 X_1 X1 与 X 2 X_2 X2 相互独立,则 X 1 + X 2 ∼ G a ( α 1 + α 2 , λ ) X_1 + X_2 \sim Ga(\alpha_1 + \alpha_2, \lambda) X1+X2∼Ga(α1+α2,λ)。
例 1: 设 X ∼ G a ( α , λ ) X \sim Ga(\alpha, \lambda) X∼Ga(α,λ),其中 α > 0 , λ > 0 \alpha > 0, \lambda > 0 α>0,λ>0 为常数, ( X 1 , ⋯ , X n ) (X_1, \cdots, X_n) (X1,⋯,Xn) 是取自总体的样本,求样本和 ∑ i = 1 n X i \sum_{i=1}^{n} X_i ∑i=1nXi 的分布密度函数。
解: 因为 Gamma 分布具有可加性,且 X i X_i Xi 独立同分布,所以 ∑ i = 1 n X i ∼ G a ( n α , λ ) \sum_{i=1}^{n} X_i \sim Ga(n\alpha, \lambda) ∑i=1nXi∼Ga(nα,λ)
例 2:设 X ∼ G a ( α , λ ) , Y = k X X \sim Ga(\alpha, \lambda), Y = kX X∼Ga(α,λ),Y=kX,证明: Y ∼ G a ( α , λ k ) , k > 0 Y \sim Ga\left(\alpha, \frac{\lambda}{k}\right), k > 0 Y∼Ga(α,kλ),k>0,并求 X ˉ \bar{X} Xˉ 的分布。
解: ∵ X ∼ G a ( α , λ ) , ∴ f ( x ) = λ α Γ ( α ) x α − 1 e − λ x , x > 0 \because X \sim Ga(\alpha, \lambda), \therefore f(x) = \frac{\lambda^\alpha}{\Gamma(\alpha)} x^{\alpha-1} e^{-\lambda x}, x > 0 ∵X∼Ga(α,λ),∴f(x)=Γ(α)λαxα−1e−λx,x>0
引理: 若对严格单调且可导函数 Y = g ( X ) , X = h ( Y ) Y=g(X), X=h(Y) Y=g(X),X=h(Y),则 f Y ( y ) = f X h ( y ) ∣ h ′ ( y ) ∣ , α < y < β f_Y(y) = f_Xh(y) |h'(y)|, \alpha < y < \beta fY(y)=fXh(y)∣h′(y)∣,α<y<β
∵ Y = k X , ∴ X = Y / k , X ′ = 1 / k \because Y = kX, \therefore X = Y/k, X' = 1/k ∵Y=kX,∴X=Y/k,X′=1/k
f ( y ) = λ α Γ ( α ) ( y k ) α − 1 e − λ y k ⋅ 1 k = 1 Γ ( α ) ( λ k ) α y α − 1 e − λ y k ∼ G a ( α , λ k ) f(y) = \frac{\lambda^\alpha}{\Gamma(\alpha)} \left(\frac{y}{k}\right)^{\alpha-1} e^{-\lambda \frac{y}{k}} \cdot \frac{1}{k} = \frac{1}{\Gamma(\alpha)} \left(\frac{\lambda}{k}\right)^\alpha y^{\alpha-1} e^{-\frac{\lambda y}{k}} \sim Ga\left(\alpha, \frac{\lambda}{k}\right) f(y)=Γ(α)λα(ky)α−1e−λky⋅k1=Γ(α)1(kλ)αyα−1e−kλy∼Ga(α,kλ)又 ∵ ∑ i = 1 n X i ∼ G a ( n α , λ ) \because \sum_{i=1}^{n} X_i \sim Ga(n\alpha, \lambda) ∵∑i=1nXi∼Ga(nα,λ)
∴ X ˉ = 1 n ∑ i = 1 n X i ∼ G a ( n α , n λ ) \therefore \bar{X} = \frac{1}{n} \sum_{i=1}^{n} X_i \sim Ga(n\alpha, n\lambda) ∴Xˉ=n1∑i=1nXi∼Ga(nα,nλ)
例 3:证明:设 X ∼ N ( 0 , σ 2 ) X \sim N(0, \sigma^2) X∼N(0,σ2),则 Y = X 2 ∼ G a ( 1 2 , 1 2 σ 2 ) Y = X^2 \sim Ga\left(\frac{1}{2}, \frac{1}{2\sigma^2}\right) Y=X2∼Ga(21,2σ21)。
解: 当 y > 0 y > 0 y>0 时, Y Y Y 的分布函数为: F Y ( y ) = P { Y ≤ y } = P { X 2 ≤ y } = P { − y ≤ X ≤ y } F_Y(y) = P\{Y \le y\} = P\{X^2 \le y\} = P\{-\sqrt{y} \le X \le \sqrt{y}\} FY(y)=P{Y≤y}=P{X2≤y}=P{−y ≤X≤y } = F X ( y ) − F X ( − y ) = F_X(\sqrt{y}) - F_X(-\sqrt{y}) =FX(y )−FX(−y )
其分布密度函数为: f Y ( y ) = f X ( y ) + f X ( − y ) 1 2 y = 1 2 π σ y − 1 2 e − y 2 σ 2 f_Y(y) = f_X(\\sqrt{y}) + f_X(-\\sqrt{y}) \frac{1}{2\sqrt{y}} = \frac{1}{\sqrt{2\pi}\sigma} y^{-\frac{1}{2}} e^{-\frac{y}{2\sigma^2}} fY(y)=fX(y )+fX(−y )2y 1=2π σ1y−21e−2σ2y因为 Γ ( 1 2 ) = π \Gamma\left(\frac{1}{2}\right) = \sqrt{\pi} Γ(21)=π ,因此 Y ∼ G a ( 1 2 , 1 2 σ 2 ) Y \sim Ga\left(\frac{1}{2}, \frac{1}{2\sigma^2}\right) Y∼Ga(21,2σ21)。
推论: X X X 服从 N ( 0 , 1 ) N(0, 1) N(0,1) 时, Y = X 2 Y = X^2 Y=X2 服从 G a ( 1 2 , 1 2 ) Ga\left(\frac{1}{2}, \frac{1}{2}\right) Ga(21,21)。
1.3.1 卡方分布族
1️⃣ 卡方分布的定义
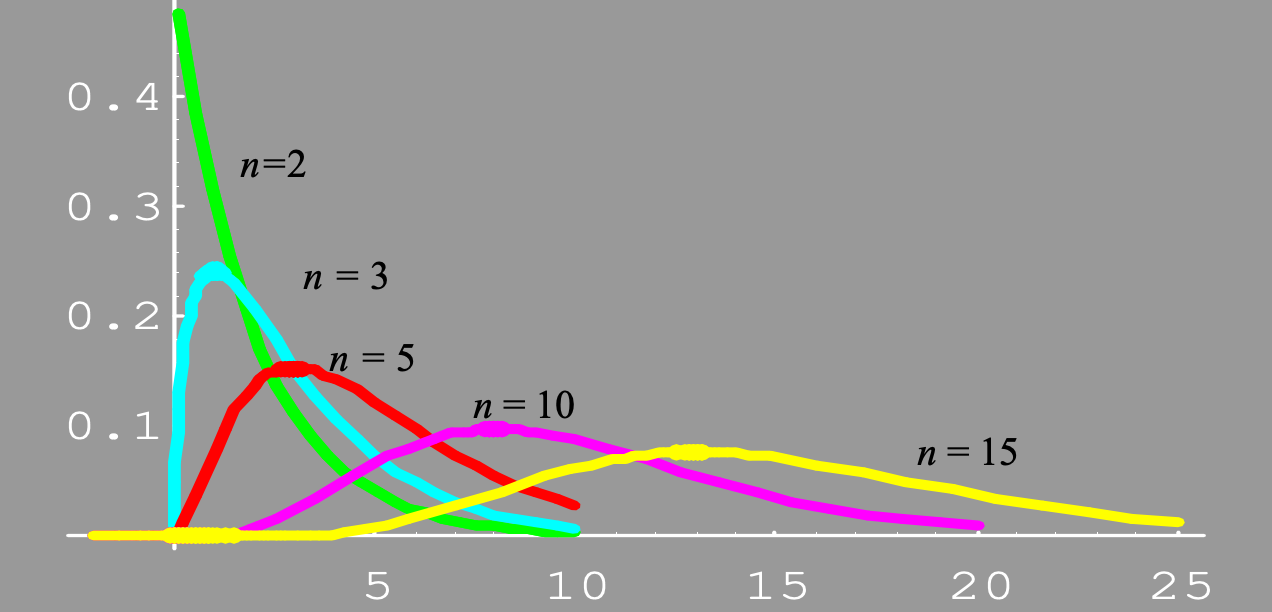
定义: G a ( n 2 , 1 2 ) Ga\left(\frac{n}{2}, \frac{1}{2}\right) Ga(2n,21) 称为 n n n 个自由度的 χ 2 \chi^2 χ2 分布,记作 χ 2 ( n ) \chi^2(n) χ2(n) 分布。 χ 2 ( n ) \chi^2(n) χ2(n) 分布的密度函数为: f ( x , n ) = 1 2 n 2 Γ ( n 2 ) x n 2 − 1 e − x 2 , x > 0 f(x, n) = \frac{1}{2^{\frac{n}{2}} \Gamma\left(\frac{n}{2}\right)} x^{\frac{n}{2}-1} e^{-\frac{x}{2}}, \quad x > 0 f(x,n)=22nΓ(2n)1x2n−1e−2x,x>0
推论 : X X X 服从 N ( 0 , 1 ) N(0, 1) N(0,1), Y = X 2 Y = X^2 Y=X2 服从 G a ( 1 2 , 1 2 ) Ga\left(\frac{1}{2}, \frac{1}{2}\right) Ga(21,21),即 χ 2 ( 1 ) \chi^2(1) χ2(1)。
χ 2 \chi^2 χ2 分布另一种定义方式:
(1) 若 X i ∼ N ( 0 , 1 ) X_i \sim N(0, 1) Xi∼N(0,1) iid,则 Y = X 1 2 + X 2 2 + ⋯ + X n 2 ∼ χ 2 ( n ) Y = X_1^2 + X_2^2 + \cdots + X_n^2 \sim \chi^2(n) Y=X12+X22+⋯+Xn2∼χ2(n)
(2) 若 X i ∼ N ( μ , σ 2 ) X_i \sim N(\mu, \sigma^2) Xi∼N(μ,σ2),则 ∑ i = 1 n ( x i − μ σ ) 2 ∼ χ 2 ( n ) \sum_{i=1}^{n} \left(\frac{x_i - \mu}{\sigma}\right)^2 \sim \chi^2(n) ∑i=1n(σxi−μ)2∼χ2(n)
注: 自由度是指独立随机变量的个数。
在概率统计中,iid(或 I.I.D.)是 Independent and Identically Distributed 的缩写,中文翻译为独立同分布。
2️⃣ 卡方分布的性质
(1)若 X X X 服从 χ 2 ( n ) \chi^2(n) χ2(n),则 E ( X ) = n , D ( X ) = 2 n E(X) = n, D(X) = 2n E(X)=n,D(X)=2n。
(2)若 X 1 X_1 X1 服从 χ 2 ( n 1 ) \chi^2(n_1) χ2(n1), X 2 X_2 X2 服从 χ 2 ( n 2 ) \chi^2(n_2) χ2(n2),且 X 1 X_1 X1 和 X 2 X_2 X2 相互独立,则 X 1 + X 2 X_1 + X_2 X1+X2 服从 χ 2 ( n 1 + n 2 ) \chi^2(n_1 + n_2) χ2(n1+n2)。
(3)因为 G a ( 1 , λ ) = E x p ( λ ) , G a ( n 2 , 1 2 ) = χ 2 ( n ) Ga(1, \lambda) = Exp(\lambda), \quad Ga\left(\frac{n}{2}, \frac{1}{2}\right) = \chi^2(n) Ga(1,λ)=Exp(λ),Ga(2n,21)=χ2(n),所以 χ 2 ( 2 ) = G a ( 1 , 1 2 ) = E x p ( 1 2 ) \chi^2(2) = Ga\left(1, \frac{1}{2}\right) = Exp\left(\frac{1}{2}\right) χ2(2)=Ga(1,21)=Exp(21)
性质 1 告诉我们卡方分布的期望(均值)正好等于它的自由度 n n n。
性质 2 是可加性,独立卡方变量的和依然是卡方分布,自由度相加。
性质 3 揭示了分布之间的内在联系:当卡方分布的自由度为 2 时,它退化为一个特殊的指数分布。
卡方分布的图像:
Cochran 分解定理 :设 X 1 , X 2 , ... , X n X_1, X_2, \dots, X_n X1,X2,...,Xn 是独立同分布的随机变量, X i X_i Xi 服从 N ( 0 , 1 ) , i = 1 , 2 , ... , n N(0, 1), i = 1, 2, \dots, n N(0,1),i=1,2,...,n。 Q i ( i = 1 , 2 , ... , k ) Q_i (i = 1, 2, \dots, k) Qi(i=1,2,...,k) 是 X 1 , X 2 , ... , X n X_1, X_2, \dots, X_n X1,X2,...,Xn 的二次型,其秩为 n i n_i ni。
如果 Q 1 + Q 2 + ⋯ + Q k = ∑ i = 1 k X i 2 Q_1 + Q_2 + \dots + Q_k = \sum_{i=1}^k X_i^2 Q1+Q2+⋯+Qk=∑i=1kXi2,且 ∑ i = 1 k n i = n \sum_{i=1}^k n_i = n ∑i=1kni=n,
则 Q i ∼ χ 2 ( n i ) , i = 1 , 2 , ... , k Q_i \sim \chi^2(n_i), i = 1, 2, \dots, k Qi∼χ2(ni),i=1,2,...,k 且 Q 1 , Q 2 , ... , Q k Q_1, Q_2, \dots, Q_k Q1,Q2,...,Qk 相互独立。
Cochran 定理是卡方分布性质 2 的逆定理,在方差分析(ANOVA)中有重要作用。
这个定理的核心在于二次型的分解。它告诉我们,如果我们将标准正态分布变量的平方和分解成若干个二次型之和,只要这些二次型的秩相加等于原变量的个数,那么这些二次型就不仅相互独立,而且各自都服从卡方分布。
例 1:设 ( X 1 , X 2 , X 3 , X 4 ) (X_1, X_2, X_3, X_4) (X1,X2,X3,X4) 是来自正态总体 N ( 0 , 2 2 ) N(0, 2^2) N(0,22) 的样本, T = a ( X 1 − 2 X 2 ) 2 + b ( 3 X 3 − 4 X 4 ) 2 T = a (X_1 - 2X_2)^2 + b (3X_3 - 4X_4)^2 T=a(X1−2X2)2+b(3X3−4X4)2,求常数 a , b a, b a,b,使得 T ∼ χ 2 ( 2 ) T \sim \chi^2(2) T∼χ2(2)。
解:因为 X 1 − 2 X 2 ∼ N ( 0 , 20 ) ⇒ X 1 − 2 X 2 2 5 ∼ N ( 0 , 1 ) ⇒ 1 20 ( X 1 − 2 X 2 ) 2 ∼ χ 2 ( 1 ) X_1 - 2X_2 \sim N(0, 20) \Rightarrow \frac{X_1 - 2X_2}{2\sqrt{5}} \sim N(0, 1) \Rightarrow \frac{1}{20}(X_1 - 2X_2)^2 \sim \chi^2(1) X1−2X2∼N(0,20)⇒25 X1−2X2∼N(0,1)⇒201(X1−2X2)2∼χ2(1)同理可得 3 X 3 − 4 X 4 ∼ N ( 0 , 100 ) ⇒ 3 X 3 − 4 X 4 10 ∼ N ( 0 , 1 ) ⇒ 1 100 ( 3 X 3 − 4 X 4 ) 2 ∼ χ 2 ( 1 ) 3X_3 - 4X_4 \sim N(0, 100) \Rightarrow \frac{3X_3 - 4X_4}{10} \sim N(0, 1) \Rightarrow \frac{1}{100}(3X_3 - 4X_4)^2 \sim \chi^2(1) 3X3−4X4∼N(0,100)⇒103X3−4X4∼N(0,1)⇒1001(3X3−4X4)2∼χ2(1)由于 X 1 − 2 X 2 X_1 - 2X_2 X1−2X2 与 3 X 3 − 4 X 4 3X_3 - 4X_4 3X3−4X4 相互独立,所以 1 20 ( X 1 − 2 X 2 ) 2 + 1 100 ( 3 X 3 − 4 X 4 ) 2 ∼ χ 2 ( 2 ) \frac{1}{20}(X_1 - 2X_2)^2 + \frac{1}{100}(3X_3 - 4X_4)^2 \sim \chi^2(2) 201(X1−2X2)2+1001(3X3−4X4)2∼χ2(2)所以当 a = 1 20 , b = 1 100 a = \frac{1}{20}, b = \frac{1}{100} a=201,b=1001 时, T ∼ χ 2 ( 2 ) T \sim \chi^2(2) T∼χ2(2)。
求解过程补充:
- 方差计算:由于 X i ∼ N ( 0 , 4 ) X_i \sim N(0, 4) Xi∼N(0,4),根据独立正态变量线性组合的性质, V a r ( X 1 − 2 X 2 ) = 1 2 ⋅ 4 + ( − 2 ) 2 ⋅ 4 = 20 Var(X_1 - 2X_2) = 1^2 \cdot 4 + (-2)^2 \cdot 4 = 20 Var(X1−2X2)=12⋅4+(−2)2⋅4=20。
- 标准化:将正态变量减去均值并除以标准差( 20 \sqrt{20} 20 )即可得到标准正态变量 N ( 0 , 1 ) N(0, 1) N(0,1)。
- 构造卡方:标准正态变量的平方服从自由度为 1 的卡方分布 χ 2 ( 1 ) \chi^2(1) χ2(1)。
- 可加性:两个独立的 χ 2 ( 1 ) \chi^2(1) χ2(1) 变量相加,得到 χ 2 ( 2 ) \chi^2(2) χ2(2)。
1.3.3 Beta 分布族
1️⃣ Beta 分布族的定义
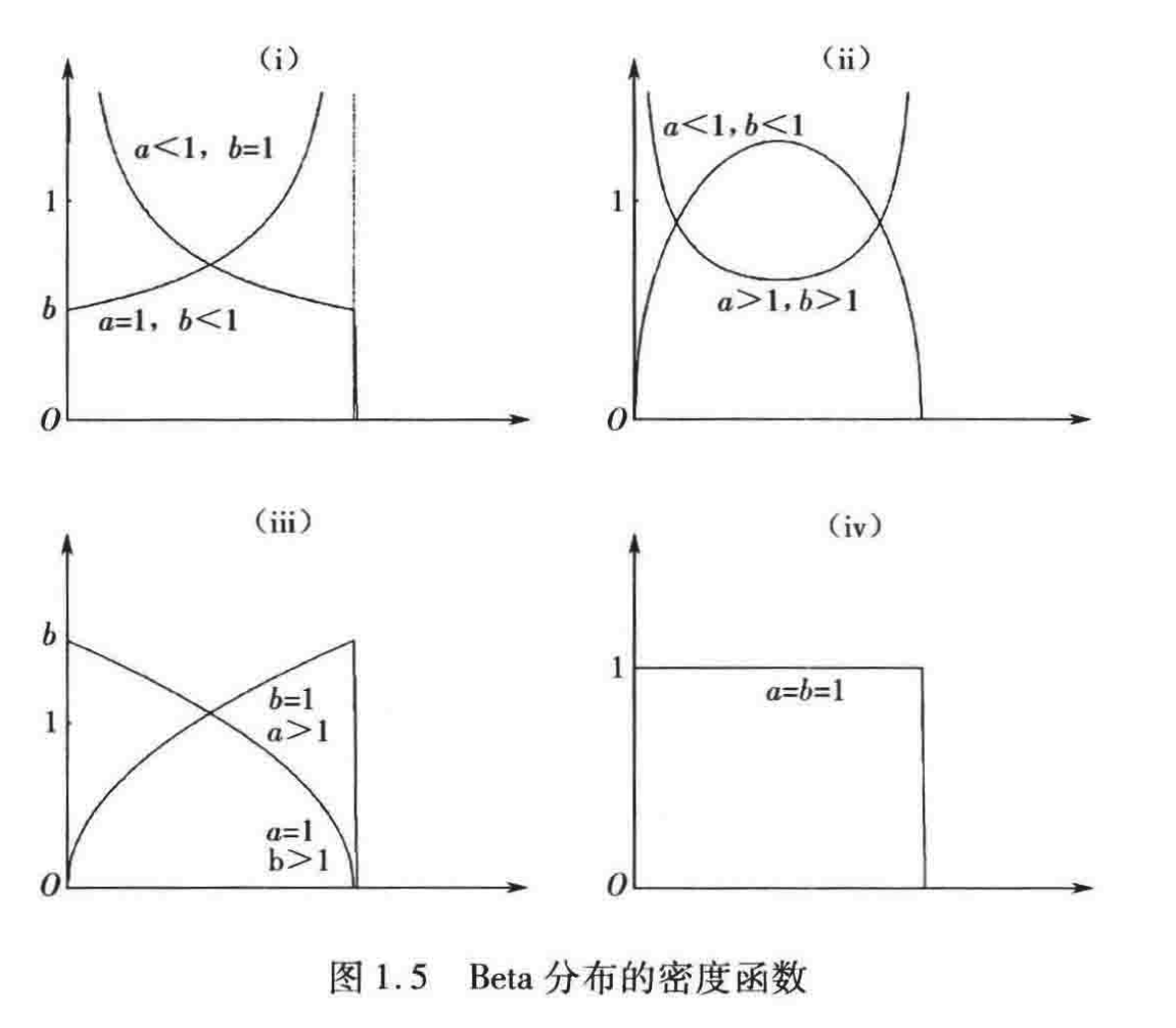
定义: 若随机变量 X X X 具有密度函数 f ( x ; a , b ) = Γ ( a + b ) Γ ( a ) Γ ( b ) x a − 1 ( 1 − x ) b − 1 , 0 < x < 1 f(x; a, b) = \frac{\Gamma(a+b)}{\Gamma(a)\Gamma(b)}x^{a-1}(1-x)^{b-1}, \quad 0 < x < 1 f(x;a,b)=Γ(a)Γ(b)Γ(a+b)xa−1(1−x)b−1,0<x<1
则称 X X X 所服从的分布为 Beta 分布,记作 B e ( a , b ) Be(a, b) Be(a,b),其中 a > 0 , b > 0 a > 0, b > 0 a>0,b>0 是两个参数。 { B e ( a , b ) : a > 0 , b > 0 } \{Be(a, b) : a > 0, b > 0\} {Be(a,b):a>0,b>0} 称为 Beta 分布族。
注: 当 a = b = 1 a = b = 1 a=b=1 时, B e ( 1 , 1 ) Be(1, 1) Be(1,1) 分布就是 ( 0 , 1 ) (0, 1) (0,1) 上的均匀分布 R ( 0 , 1 ) R(0, 1) R(0,1)。
2️⃣ Beta 分布族的性质
结论 :如果 X ∼ B e ( a , b ) X \sim Be(a, b) X∼Be(a,b),则 E ( X ) = a a + b , D ( X ) = a b ( a + b ) 2 ( a + b + 1 ) E(X) = \frac{a}{a+b}, \quad D(X) = \frac{ab}{(a+b)^2(a+b+1)} E(X)=a+ba,D(X)=(a+b)2(a+b+1)ab
证明:已知 X ∼ B e ( a , b ) X \sim Be(a, b) X∼Be(a,b),其概率密度函数为: f ( x ) = Γ ( a + b ) Γ ( a ) Γ ( b ) x a − 1 ( 1 − x ) b − 1 , 0 < x < 1 f(x) = \frac{\Gamma(a+b)}{\Gamma(a)\Gamma(b)} x^{a-1}(1-x)^{b-1}, \quad 0 < x < 1 f(x)=Γ(a)Γ(b)Γ(a+b)xa−1(1−x)b−1,0<x<1
期望的定义式为: E X = ∫ − ∞ + ∞ x f ( x ) d x = Γ ( a + b ) Γ ( a ) Γ ( b ) ∫ 0 1 x a ( 1 − x ) b − 1 d x EX = \int_{-\infty}^{+\infty} x f(x) dx = \frac{\Gamma(a+b)}{\Gamma(a)\Gamma(b)} \int_0^1 x^a(1-x)^{b-1} dx EX=∫−∞+∞xf(x)dx=Γ(a)Γ(b)Γ(a+b)∫01xa(1−x)b−1dx
证明思路:注意到,若 X ∼ B e ( a + 1 , b ) X \sim Be(a+1, b) X∼Be(a+1,b),其密度函数为: f ( x ) = Γ ( a + 1 + b ) Γ ( a + 1 ) Γ ( b ) x a ( 1 − x ) b − 1 , 0 < x < 1 f(x) = \frac{\Gamma(a+1+b)}{\Gamma(a+1)\Gamma(b)} x^a(1-x)^{b-1}, \quad 0 < x < 1 f(x)=Γ(a+1)Γ(b)Γ(a+1+b)xa(1−x)b−1,0<x<1根据密度函数的全概率性质(积分等于 1): ∫ − ∞ + ∞ f ( x ) d x = Γ ( a + b + 1 ) Γ ( a + 1 ) Γ ( b ) ∫ 0 1 x a ( 1 − x ) b − 1 d x = 1 \int_{-\infty}^{+\infty} f(x) dx = \frac{\Gamma(a+b+1)}{\Gamma(a+1)\Gamma(b)} \int_0^1 x^a(1-x)^{b-1} dx = 1 ∫−∞+∞f(x)dx=Γ(a+1)Γ(b)Γ(a+b+1)∫01xa(1−x)b−1dx=1由此可得出积分项的结果: ∫ 0 1 x a ( 1 − x ) b − 1 d x = Γ ( a + 1 ) Γ ( b ) Γ ( a + b + 1 ) \int_0^1 x^a(1-x)^{b-1} dx = \frac{\Gamma(a+1)\Gamma(b)}{\Gamma(a+b+1)} ∫01xa(1−x)b−1dx=Γ(a+b+1)Γ(a+1)Γ(b)最终计算: E X = Γ ( a + b ) Γ ( a ) Γ ( b ) ⋅ Γ ( a + 1 ) Γ ( b ) Γ ( a + b + 1 ) = a a + b EX = \frac{\Gamma(a+b)}{\Gamma(a)\Gamma(b)} \cdot \frac{\Gamma(a+1)\Gamma(b)}{\Gamma(a+b+1)} = \frac{a}{a+b} EX=Γ(a)Γ(b)Γ(a+b)⋅Γ(a+b+1)Γ(a+1)Γ(b)=a+ba
1.3.4 F分布族
1️⃣ F分布族的定义
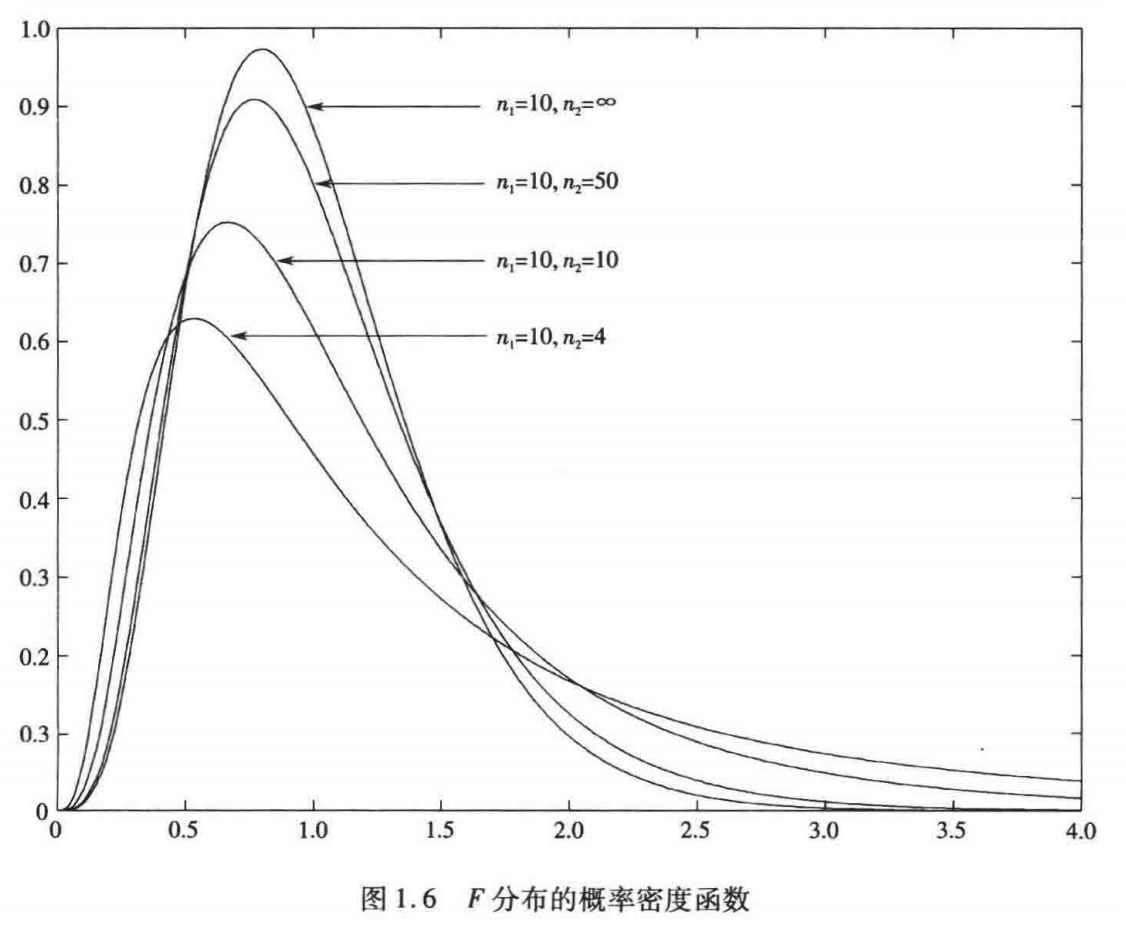
F F F 分布 :自由度为 n , m n, m n,m 的 F ( n , m ) F(n, m) F(n,m) 分布,由英国统计学家 Fisher 和 Snedecor 在 20 世纪 20 年代提出。
定理 :若 X 1 ∼ χ 2 ( n ) , X 2 ∼ χ 2 ( m ) X_1 \sim \chi^2(n), X_2 \sim \chi^2(m) X1∼χ2(n),X2∼χ2(m),且 X 1 , X 2 X_1, X_2 X1,X2 相互独立,则: X 1 X 1 + X 2 ∼ B e ( n 2 , m 2 ) \frac{X_1}{X_1 + X_2} \sim Be\left(\frac{n}{2}, \frac{m}{2}\right) X1+X2X1∼Be(2n,2m) (即服从 Beta 分布), F = X 1 / n X 2 / m ∼ F ( n , m ) F = \frac{X_1 / n}{X_2 / m} \sim F(n, m) F=X2/mX1/n∼F(n,m)。
F F F 分布的概率密度函数为: f ( t ; n , m ) = { Γ ( n + m 2 ) Γ ( n 2 ) Γ ( m 2 ) ( n m ) n 2 t n 2 − 1 ( 1 + n m t ) − n + m 2 , t > 0 0 , t ≤ 0 f(t; n, m) = \begin{cases} \frac{\Gamma\left(\frac{n+m}{2}\right)}{\Gamma\left(\frac{n}{2}\right)\Gamma\left(\frac{m}{2}\right)} \left(\frac{n}{m}\right)^{\frac{n}{2}} t^{\frac{n}{2}-1} \left(1 + \frac{n}{m}t\right)^{-\frac{n+m}{2}}, & t > 0 \\ 0, & t \le 0 \end{cases} f(t;n,m)=⎩ ⎨ ⎧Γ(2n)Γ(2m)Γ(2n+m)(mn)2nt2n−1(1+mnt)−2n+m,0,t>0t≤0
2️⃣ F分布族的性质
(1) 倒数性质:若 F ∼ F ( n , m ) F \sim F(n, m) F∼F(n,m),则 1 / F ∼ F ( m , n ) 1/F \sim F(m, n) 1/F∼F(m,n)。
若 X 1 X_1 X1 服从 χ 2 ( n ) \chi^2(n) χ2(n), X 2 X_2 X2 服从 χ 2 ( m ) \chi^2(m) χ2(m),且 X 1 , X 2 X_1, X_2 X1,X2 相互独立,则 F = X 1 / n X 2 / m F = \frac{X_1 / n}{X_2 / m} F=X2/mX1/n 服从 F ( n , m ) F(n, m) F(n,m)。
(2) k k k 阶矩:若 X X X 服从 F ( n 1 , n 2 ) F(n_1, n_2) F(n1,n2),则对 n 1 < 2 k < n 2 n_1 < 2k < n_2 n1<2k<n2,有: E ( X k ) = ( n 2 n 1 ) k Γ ( k + n 1 2 ) Γ ( n 2 2 − k ) Γ ( n 1 2 ) Γ ( n 2 2 ) E(X^k) = \left(\frac{n_2}{n_1}\right)^k \frac{\Gamma\left(k + \frac{n_1}{2}\right)\Gamma\left(\frac{n_2}{2} - k\right)}{\Gamma\left(\frac{n_1}{2}\right)\Gamma\left(\frac{n_2}{2}\right)} E(Xk)=(n1n2)kΓ(2n1)Γ(2n2)Γ(k+2n1)Γ(2n2−k)
特别地,对 n 2 > 4 n_2 > 4 n2>4,有:期望 E ( X ) = n 2 n 2 − 2 E(X) = \frac{n_2}{n_2 - 2} E(X)=n2−2n2,方差 D ( X ) = 2 n 2 2 ( n 1 + n 2 − 2 ) n 1 ( n 2 − 2 ) 2 ( n 2 − 4 ) D(X) = \frac{2n_2^2(n_1 + n_2 - 2)}{n_1(n_2 - 2)^2(n_2 - 4)} D(X)=n1(n2−2)2(n2−4)2n22(n1+n2−2)。
1.3.4 t分布族
1️⃣ t分布族的定义
定义 : 设随机变量 X ∼ N ( 0 , 1 ) , Y ∼ χ 2 ( n ) X \sim N(0, 1), Y \sim \chi^2(n) X∼N(0,1),Y∼χ2(n),且 X , Y X, Y X,Y 相互独立,则 T = X Y / n T = \frac{X}{\sqrt{Y/n}} T=Y/n X
服从自由度为 n n n 的 t t t 分布,记作 T ∼ t ( n ) T \sim t(n) T∼t(n)。
背景介绍:这个分布是由 S. Gosset 以笔名 Student 于 1908 年提出的,因此有时也称学生分布。当时他是英国一家酿酒厂(健力士酿酒厂)的酿酒化学技师。
其概率密度函数为: f ( t ; n ) = Γ ( n + 1 2 ) n π Γ ( n 2 ) ( 1 + t 2 n ) − n + 1 2 , − ∞ < t < + ∞ f(t; n) = \frac{\Gamma\left(\frac{n+1}{2}\right)}{\sqrt{n\pi}\Gamma\left(\frac{n}{2}\right)} \left(1 + \frac{t^2}{n}\right)^{-\frac{n+1}{2}}, \quad -\infty < t < +\infty f(t;n)=nπ Γ(2n)Γ(2n+1)(1+nt2)−2n+1,−∞<t<+∞
推论:若 X ∼ N ( μ , σ 2 ) , Y / σ 2 ∼ χ 2 ( n ) X \sim N(\mu, \sigma^2), \quad Y/\sigma^2 \sim \chi^2(n) X∼N(μ,σ2),Y/σ2∼χ2(n),且 X , Y X, Y X,Y 相互独立,则 T = X − μ Y / n T = \frac{X - \mu}{\sqrt{Y/n}} T=Y/n X−μ 服从 t ( n ) t(n) t(n)。
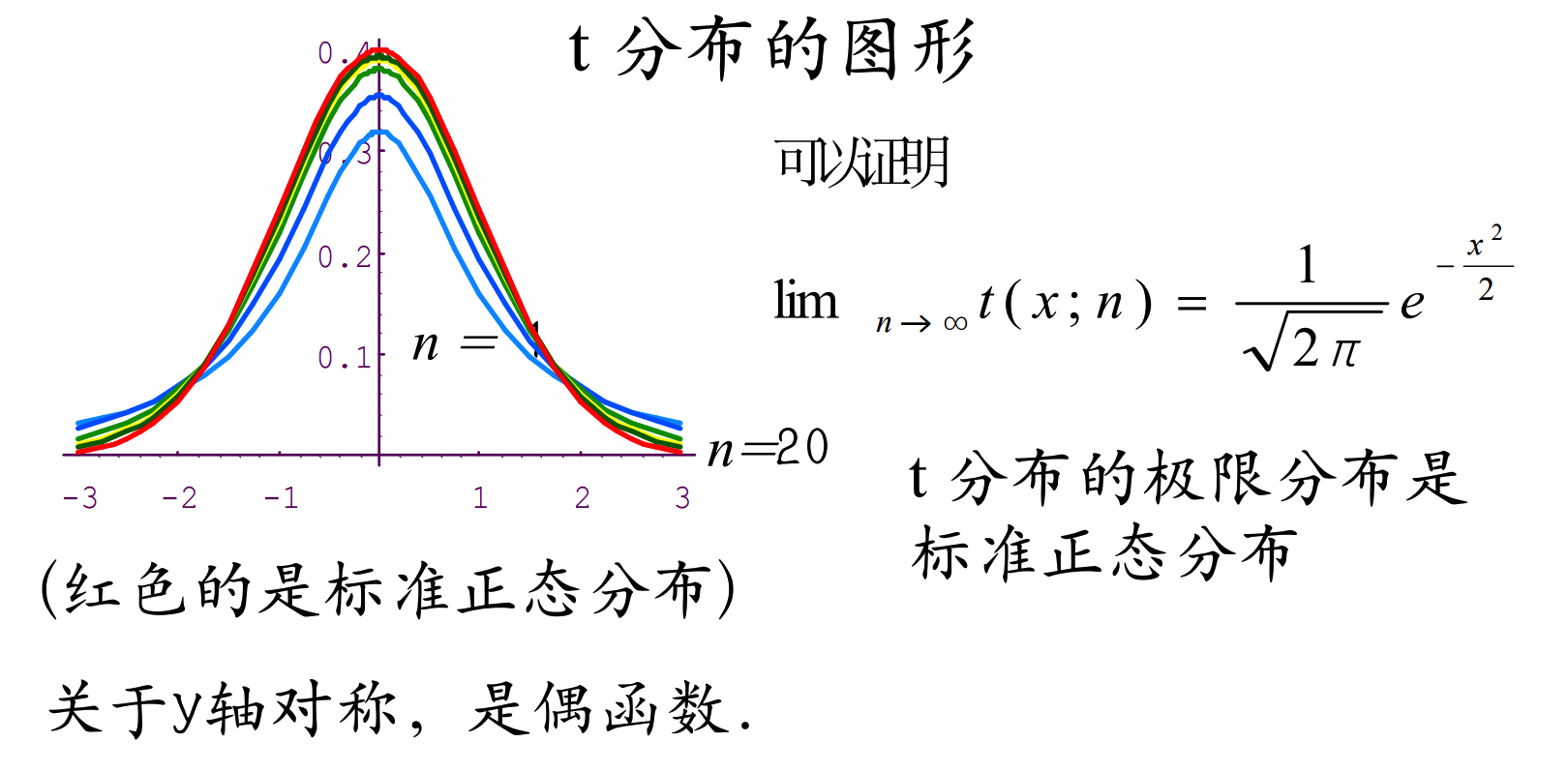
2️⃣ t分布族的性质
(1) 特殊情况与矩的性质:当 n = 1 n=1 n=1 时, t ( x ; 1 ) = 1 π 1 1 + x 2 t(x; 1) = \frac{1}{\pi} \frac{1}{1+x^2} t(x;1)=π11+x21,即为 Cauchy 分布。当 n > 2 n > 2 n>2 时,期望 E ( T ) = 0 E(T) = 0 E(T)=0,方差 D ( T ) = n n − 2 D(T) = \frac{n}{n-2} D(T)=n−2n。
若 X ∼ t ( n ) X \sim t(n) X∼t(n),则 X X X 只存在 k ( < n ) k (< n) k(<n) 阶矩。 t t t 分布是厚尾的。
(2) 与 F F F 分布的关系:若 T ∼ t ( n ) T \sim t(n) T∼t(n),则 T 2 ∼ F ( 1 , n ) T^2 \sim F(1, n) T2∼F(1,n)。
T = X Y / n T = \frac{X}{\sqrt{Y/n}} T=Y/n X,其中 X ∼ N ( 0 , 1 ) , Y ∼ χ 2 ( n ) X \sim N(0, 1), Y \sim \chi^2(n) X∼N(0,1),Y∼χ2(n),且 X , Y X, Y X,Y 相互独立。那么 T 2 = X 2 Y / n T^2 = \frac{X^2}{Y/n} T2=Y/nX2,其中 X 2 ∼ χ 2 ( 1 ) X^2 \sim \chi^2(1) X2∼χ2(1)。
1.3.5 分位数
1️⃣ p分位数定义及其性质
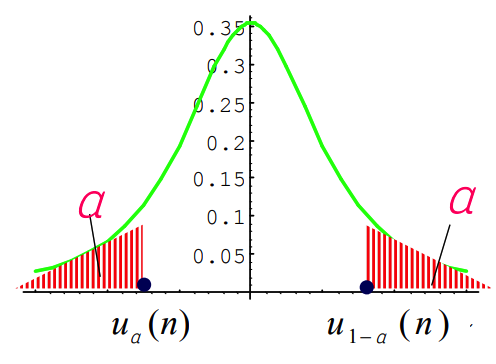
p p p 分位数定义 :设 p p p 满足 0 < p < 1 0 < p < 1 0<p<1,若 x p x_p xp 使 P { X ≤ x p } = F ( x p ) = p P\{X \le x_p\} = F(x_p) = p P{X≤xp}=F(xp)=p,则称 x p x_p xp 为该分布的 p p p 分位数。
例如, X ∼ N ( 0 , 1 ) X \sim N(0, 1) X∼N(0,1):查正态分布函数表,得 Φ ( 1.96 ) = 0.975 \Phi(1.96) = 0.975 Φ(1.96)=0.975。即 P { X ≤ 1.96 } = 0.975 P\{X \le 1.96\} = 0.975 P{X≤1.96}=0.975。则标准正态分布的 0.975 0.975 0.975 分位数为 u 0.975 = 1.96 u_{0.975} = 1.96 u0.975=1.96。
对称性性质: u a = − u 1 − a u_a = -u_{1-a} ua=−u1−a。
2️⃣ 三大分布的分位数表
χ 2 \chi^2 χ2 分布表:例如: χ 0.95 2 ( 10 ) = 18.307 \chi^2_{0.95}(10) = 18.307 χ0.952(10)=18.307,即若 X ∼ χ 2 ( 10 ) X \sim \chi^2(10) X∼χ2(10),则 P ( X ≤ 18.307 ) = 0.95 P(X \le 18.307) = 0.95 P(X≤18.307)=0.95
t t t 分布表: t 1 − a ( n ) = − t a ( n ) t_{1-a}(n) = -t_a(n) t1−a(n)=−ta(n)
F F F 分布表: F 1 − a ( n 1 , n 2 ) = 1 F a ( n 2 , n 1 ) F_{1-a}(n_1, n_2) = \frac{1}{F_a(n_2, n_1)} F1−a(n1,n2)=Fa(n2,n1)1
证:设 F ∼ F ( n 1 , n 2 ) F \sim F(n_1, n_2) F∼F(n1,n2),根据分位数的定义有: P { F ≤ F 1 − a ( n 1 , n 2 ) } = 1 − a P\{F \le F_{1-a}(n_1, n_2)\} = 1 - a P{F≤F1−a(n1,n2)}=1−a
对不等式两边取倒数,不等号方向改变: P { 1 F > 1 F 1 − a ( n 1 , n 2 ) } = 1 − a P\left\{\frac{1}{F} > \frac{1}{F_{1-a}(n_1, n_2)}\right\} = 1 - a P{F1>F1−a(n1,n2)1}=1−a
由对立事件的概率可知: P { 1 F ≤ 1 F 1 − a ( n 1 , n 2 ) } = a P\left\{\frac{1}{F} \le \frac{1}{F_{1-a}(n_1, n_2)}\right\} = a P{F1≤F1−a(n1,n2)1}=a
根据 F F F 分布的性质,已知 1 F ∼ F ( n 2 , n 1 ) \frac{1}{F} \sim F(n_2, n_1) F1∼F(n2,n1)。
由 a a a 分位数的定义有: P { 1 F < F a ( n 2 , n 1 ) } = a P\left\{\frac{1}{F} < F_a(n_2, n_1)\right\} = a P{F1<Fa(n2,n1)}=a
对比上述两个概率等式,可得: 1 F 1 − a ( n 1 , n 2 ) = F a ( n 2 , n 1 ) \frac{1}{F_{1-a}(n_1, n_2)} = F_a(n_2, n_1) F1−a(n1,n2)1=Fa(n2,n1),即: F 1 − a ( n 1 , n 2 ) = 1 F a ( n 2 , n 1 ) F_{1-a}(n_1, n_2) = \frac{1}{F_a(n_2, n_1)} F1−a(n1,n2)=Fa(n2,n1)1
1.3.6 多元正态分布
1️⃣ 多元正态分布的定义
符号说明 :记 X = ( X 1 , X 2 , ⋯ , X n ) T X = (X_1, X_2, \cdots, X_n)^T X=(X1,X2,⋯,Xn)T, a = ( a 1 , a 2 , ⋯ , a n ) T a = (a_1, a_2, \cdots, a_n)^T a=(a1,a2,⋯,an)T, x = ( x 1 , x 2 , ⋯ , x n ) T x = (x_1, x_2, \cdots, x_n)^T x=(x1,x2,⋯,xn)T 表示列向量。
定义 :若随机向量 X X X 的联合分布密度函数为 f ( x ) = 1 ( 2 π ) n 2 ∣ B ∣ 1 2 exp { − 1 2 ( x − a ) ′ B − 1 ( x − a ) } f(x) = \frac{1}{(2\pi)^{\frac{n}{2}} |B|^{\frac{1}{2}}} \exp\left\{-\frac{1}{2}(x - a)' B^{-1} (x - a)\right\} f(x)=(2π)2n∣B∣211exp{−21(x−a)′B−1(x−a)},其中: B B B 为正定阵(" B B B 的各阶顺序主子式都大于零")。 ∣ B ∣ |B| ∣B∣ 为其行列式。 B − 1 B^{-1} B−1 是 B B B 的逆矩阵。则称随机向量 X X X 所服从的分布为多元正态分布,简记为 X ∼ N n ( a , B ) X \sim N_n(a, B) X∼Nn(a,B)。
2️⃣ 多元正态分布的期望和方差
多元正态分布的期望 :设 X = ( X 1 , ⋯ , X n ) ′ X = (X_1, \cdots, X_n)' X=(X1,⋯,Xn)′, Y = ( Y 1 , ⋯ , Y m ) ′ Y = (Y_1, \cdots, Y_m)' Y=(Y1,⋯,Ym)′ 是两个随机向量, Z = ( Z i j ) r × s Z = (Z_{ij})_{r \times s} Z=(Zij)r×s 是随机矩阵,记:
- 向量期望: E ( X ) = ( E ( X 1 ) , ⋯ , E ( X n ) ) ′ E(X) = (E(X_1), \cdots, E(X_n))' E(X)=(E(X1),⋯,E(Xn))′
- 矩阵期望: E ( Z ) = ( E ( Z i j ) ) r × s E(Z) = (E(Z_{ij}))_{r \times s} E(Z)=(E(Zij))r×s
注: 这里使用角分符号 ( ′ ) (') (′) 表示转置,说明期望向量是由各个分量的期望组成的列向量。
多元正态分布的方差 : D ( X ) = E ( X − E ( X ) ) ( X − E ( X ) ) ′ D(X) = E(X - E(X))(X - E(X))' D(X)=E(X−E(X))(X−E(X))′
其矩阵展开形式为: D ( X ) = ( D ( X 1 ) Cov ( X 1 , X 2 ) ⋯ Cov ( X 1 , X n ) Cov ( X 2 , X 1 ) D ( X 2 ) ⋯ Cov ( X 2 , X n ) ⋮ ⋮ ⋱ ⋮ Cov ( X n , X 1 ) Cov ( X n , X 2 ) ⋯ D ( X n ) ) D(X) = \begin{pmatrix} D(X_1) & \text{Cov}(X_1, X_2) & \cdots & \text{Cov}(X_1, X_n) \\ \text{Cov}(X_2, X_1) & D(X_2) & \cdots & \text{Cov}(X_2, X_n) \\ \vdots & \vdots & \ddots & \vdots \\ \text{Cov}(X_n, X_1) & \text{Cov}(X_n, X_2) & \cdots & D(X_n) \end{pmatrix} D(X)= D(X1)Cov(X2,X1)⋮Cov(Xn,X1)Cov(X1,X2)D(X2)⋮Cov(Xn,X2)⋯⋯⋱⋯Cov(X1,Xn)Cov(X2,Xn)⋮D(Xn)
其中: D ( X i ) D(X_i) D(Xi) 为 X i X_i Xi 的方差(分布在对角线上)。 Cov ( X i , X j ) \text{Cov}(X_i, X_j) Cov(Xi,Xj) 为 X i X_i Xi 和 X j X_j Xj 的协方差(分布在非对角线上)。
3️⃣ 多元正态分布的协方差和相关系数
协方差:
Cov ( X , Y ) = ( Cov ( Y , X ) ) ′ = E ( X − E ( X ) ) ( Y − E ( Y ) ) ′ \text{Cov}(X, Y) = (\text{Cov}(Y, X))' = E(X - E(X))(Y - E(Y))' Cov(X,Y)=(Cov(Y,X))′=E(X−E(X))(Y−E(Y))′ = ( Cov ( X 1 , Y 1 ) ⋯ Cov ( X 1 , Y m ) ⋮ ⋱ ⋮ Cov ( X n , Y 1 ) ⋯ Cov ( X n , Y m ) ) = \begin{pmatrix} \text{Cov}(X_1, Y_1) & \cdots & \text{Cov}(X_1, Y_m) \\ \vdots & \ddots & \vdots \\ \text{Cov}(X_n, Y_1) & \cdots & \text{Cov}(X_n, Y_m) \end{pmatrix} = Cov(X1,Y1)⋮Cov(Xn,Y1)⋯⋱⋯Cov(X1,Ym)⋮Cov(Xn,Ym)
ρ i j = Cov ( X i , X j ) D ( X i ) D ( X j ) \rho_{ij} = \frac{\text{Cov}(X_i, X_j)}{\sqrt{D(X_i)D(X_j)}} ρij=D(Xi)D(Xj) Cov(Xi,Xj) 称为 X i X_i Xi 与 X j X_j Xj 之间的线性相关系数,简称为相关系数。
4️⃣ 多元正态分布的性质
性质 1 : 若 X ∼ N n ( a , B ) \mathbf{X} \sim N_n(\mathbf{a}, \mathbf{B}) X∼Nn(a,B),则对 X \mathbf{X} X 的任一子向量 X ~ T = ( X k 1 , X k 2 , ... , X k m ) ( m ≤ n ) \mathbf{\tilde{X}}^T = (X_{k_1}, X_{k_2}, \dots, X_{k_m}) \quad (m \le n) X~T=(Xk1,Xk2,...,Xkm)(m≤n),有 X ~ ∼ N m ( a ~ , B ~ ) \mathbf{\tilde{X}} \sim N_m(\mathbf{\tilde{a}}, \mathbf{\tilde{B}}) X~∼Nm(a~,B~)。其中: a ~ T = ( a k 1 , a k 2 , ... , a k m ) \mathbf{\tilde{a}}^T = (a_{k_1}, a_{k_2}, \dots, a_{k_m}) a~T=(ak1,ak2,...,akm) B ~ \mathbf{\tilde{B}} B~ 是 B \mathbf{B} B 中保留 k 1 , k 2 , ... , k m k_1, k_2, \dots, k_m k1,k2,...,km 行和列所得的 m m m 阶子矩阵。
⚠️ 多元正态分布的边缘分布仍是正态分布,但反之未必成立。
性质 2 :若 X \mathbf{X} X 服从 N n ( a , B ) N_n(\mathbf{a}, \mathbf{B}) Nn(a,B),则 E ( X ) = a , V a r ( X ) = B E(\mathbf{X}) = \mathbf{a}, Var(\mathbf{X}) = \mathbf{B} E(X)=a,Var(X)=B。
核心结论: n n n 元正态分布由它的前二阶矩(均值向量和协方差矩阵)完全确定。
公式对比:
- 多元: f ( x ) = 1 ( 2 π ) n 2 ∣ B ∣ 1 2 exp { − 1 2 ( x − a ) ′ B − 1 ( x − a ) } f(x) = \frac{1}{(2\pi)^{\frac{n}{2}} |B|^{\frac{1}{2}}} \exp\left\{-\frac{1}{2}(x - a)' B^{-1} (x - a)\right\} f(x)=(2π)2n∣B∣211exp{−21(x−a)′B−1(x−a)}
- 一元: f ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 f(x) = \frac{1}{\sqrt{2\pi}\sigma} e^{-\frac{(x - \mu)^2}{2\sigma^2}} f(x)=2π σ1e−2σ2(x−μ)2
记 X = ( X 1 X 2 ) , a = ( a 1 a 2 ) , B = ( B 11 B 12 B 21 B 22 ) \mathbf{X} = \begin{pmatrix} \mathbf{X}1 \\ \mathbf{X}2 \end{pmatrix}, \mathbf{a} = \begin{pmatrix} \mathbf{a}1 \\ \mathbf{a}2 \end{pmatrix}, \mathbf{B} = \begin{pmatrix} \mathbf{B}{11} & \mathbf{B}{12} \\ \mathbf{B}{21} & \mathbf{B}{22} \end{pmatrix} X=(X1X2),a=(a1a2),B=(B11B21B12B22),使 X 1 , a 1 \mathbf{X}_1, \mathbf{a}_1 X1,a1 是 n 1 n_1 n1 维向量, X 2 , a 2 \mathbf{X}_2, \mathbf{a}_2 X2,a2 是 n 2 n_2 n2 维向量, n 1 + n 2 = n n_1 + n_2 = n n1+n2=n,将 B \mathbf{B} B 也作适当分块。
性质 3 :若 X = ( X 1 X 2 ) ∼ N n ( a , B ) \mathbf{X} = \begin{pmatrix} \mathbf{X}_1 \\ \mathbf{X}_2 \end{pmatrix} \sim N_n(\mathbf{a}, \mathbf{B}) X=(X1X2)∼Nn(a,B),这里 X 1 ∼ N n 1 ( a 1 , B 11 ) , X 2 ∼ N n 2 ( a 2 , B 22 ) \mathbf{X}1 \sim N{n_1}(\mathbf{a}1, \mathbf{B}{11}), \mathbf{X}2 \sim N{n_2}(\mathbf{a}2, \mathbf{B}{22}) X1∼Nn1(a1,B11),X2∼Nn2(a2,B22) 是 X \mathbf{X} X 的两个子向量, n 1 + n 2 = n n_1 + n_2 = n n1+n2=n。则 X 1 , X 2 \mathbf{X}_1, \mathbf{X}_2 X1,X2 相互独立的充分必要条件为: C o v ( X 1 , X 2 ) = B 12 = 0 Cov(\mathbf{X}_1, \mathbf{X}2) = \mathbf{B}{12} = 0 Cov(X1,X2)=B12=0
类似地, X \mathbf{X} X 的子向量 X 1 , X 2 , ... , X k \mathbf{X}_1, \mathbf{X}_2, \dots, \mathbf{X}k X1,X2,...,Xk 两两独立的充分必要条件为: B i j = C o v ( X i , X j ) = 0 , i ≠ j , i , j = 1 , 2 , ... , k \mathbf{B}{ij} = Cov(\mathbf{X}_i, \mathbf{X}_j) = 0, \quad i \neq j, i, j = 1, 2, \dots, k Bij=Cov(Xi,Xj)=0,i=j,i,j=1,2,...,k
性质 4 :若 X ∼ N n ( a , B ) \mathbf{X} \sim N_n(\mathbf{a}, \mathbf{B}) X∼Nn(a,B), A \mathbf{A} A 是秩为 m m m 的 m × n m \times n m×n 阶矩阵, b = ( b 1 , b 2 , ... , b m ) T \mathbf{b} = (b_1, b_2, \dots, b_m)^T b=(b1,b2,...,bm)T 是 m m m 维实向量。设 Y = A X + b \mathbf{Y} = \mathbf{AX} + \mathbf{b} Y=AX+b,则 Y ∼ N m ( A a + b , A B A T ) \mathbf{Y} \sim N_m(\mathbf{Aa} + \mathbf{b}, \mathbf{ABA}^T) Y∼Nm(Aa+b,ABAT)。
核心结论: 正态变量在线性变换下还是正态变量。
性质 5 :若 X \mathbf{X} X 服从 N n ( a , B ) N_n(\mathbf{a}, \mathbf{B}) Nn(a,B),则存在一个正交变换 Γ \mathbf{\Gamma} Γ,使 Y = Γ ( X − a ) \mathbf{Y} = \mathbf{\Gamma}(\mathbf{X} - \mathbf{a}) Y=Γ(X−a) 的各分量是相互独立、均值都为零的正态变量。
特别地:若 X \mathbf{X} X 服从 N n ( 0 , σ 2 I n ) N_n(\mathbf{0}, \sigma^2 \mathbf{I}_n) Nn(0,σ2In),则 Y = Γ X \mathbf{Y} = \mathbf{\Gamma X} Y=ΓX 服从 N n ( 0 , σ 2 I n ) N_n(\mathbf{0}, \sigma^2 \mathbf{I}_n) Nn(0,σ2In)。
推论: 由独立标准正态随机变量 X 1 , X 2 , ... , X n X_1, X_2, \dots, X_n X1,X2,...,Xn 组成的随机向量 X \mathbf{X} X,在正交变换 Γ \mathbf{\Gamma} Γ 下保持分布不变性。
1.3.7 指数型分布族
1️⃣ 指数型分布族的定义
设 F = { f ( x ; θ ) : θ ∈ Θ } \mathcal{F} = \{f(x; \theta) : \theta \in \Theta\} F={f(x;θ):θ∈Θ} 是分布族,若样本 ( X 1 , ... , X n ) (X_1, \dots, X_n) (X1,...,Xn) 的密度函数(或分布列) f ( x 1 , ... , x n ; θ ) f(x_1, \dots, x_n; \theta) f(x1,...,xn;θ) 可以表示成: f ( x 1 , ... , x n ; θ ) = a ( θ ) exp { ∑ j = 1 k Q j ( θ ) T j ( x 1 , ... , x n ) } h ( x 1 , ... , x n ) f(x_1, \dots, x_n; \theta) = a(\theta) \exp \left\{ \sum_{j=1}^k Q_j(\theta) T_j(x_1, \dots, x_n) \right\} h(x_1, \dots, x_n) f(x1,...,xn;θ)=a(θ)exp{j=1∑kQj(θ)Tj(x1,...,xn)}h(x1,...,xn)并且它的支撑 { x : f ( x 1 , ... , x n ; θ ) > 0 } \{x : f(x_1, \dots, x_n; \theta) > 0\} {x:f(x1,...,xn;θ)>0} 不依赖于 θ \theta θ,则称此分布族为指数型分布族,简称指数族。
例1:证明二项分布族 { b ( m , p ) : 0 < p < 1 } \{b(m, p) : 0 < p < 1\} {b(m,p):0<p<1} 是单参数指数型分布族 f ( x ) = ( m x ) p x ( 1 − p ) m − x ; x = 0 , 1 , 2 , ... , m f(x) = \binom{m}{x} p^x (1-p)^{m-x}; \quad x = 0, 1, 2, \dots, m f(x)=(xm)px(1−p)m−x;x=0,1,2,...,m
证明:首先,其支撑与参数 p p p 无关。另一方面,样本 ( X 1 , ... , X n ) (X_1, \dots, X_n) (X1,...,Xn) 的联合概率分布为: f ( x 1 , ... , x n ; p ) = ∏ i = 1 n f ( x i ) = ∏ i = 1 n ( m x i ) p ∑ i = 1 n x i ( 1 − p ) n m − ∑ i = 1 n x i f(x_1, \dots, x_n; p) = \prod_{i=1}^n f(x_i) = \left \\prod_{i=1}\^n \\binom{m}{x_i} \\right p^{\sum_{i=1}^n x_i} (1-p)^{nm - \sum_{i=1}^n x_i} f(x1,...,xn;p)=i=1∏nf(xi)=i=1∏n(xim)p∑i=1nxi(1−p)nm−∑i=1nxi对比指数族定义的标准形式: f ( x 1 , ... , x n ; θ ) = a ( θ ) exp { ∑ j = 1 k Q j ( θ ) T j ( x 1 , ... , x n ) } h ( x 1 , ... , x n ) f(x_1, \dots, x_n; \theta) = a(\theta) \exp \left\{ \sum_{j=1}^k Q_j(\theta) T_j(x_1, \dots, x_n) \right\} h(x_1, \dots, x_n) f(x1,...,xn;θ)=a(θ)exp{j=1∑kQj(θ)Tj(x1,...,xn)}h(x1,...,xn)继续对联合分布进行变形: f ( x 1 , ... , x n ; p ) = ∏ i = 1 n ( m x i ) p ∑ i = 1 n x i ( 1 − p ) n m ( 1 1 − p ) ∑ i = 1 n x i f(x_1, \dots, x_n; p) = \left \\prod_{i=1}\^n \\binom{m}{x_i} \\right p^{\sum_{i=1}^n x_i} (1-p)^{nm} \left( \frac{1}{1-p} \right)^{\sum_{i=1}^n x_i} f(x1,...,xn;p)=i=1∏n(xim)p∑i=1nxi(1−p)nm(1−p1)∑i=1nxi = ( 1 − p ) n m exp { ( ∑ i = 1 n x i ) ln p 1 − p } ⋅ ∏ i = 1 n ( m x i ) = (1-p)^{nm} \exp \left\{ \left( \sum_{i=1}^n x_i \right) \ln \frac{p}{1-p} \right\} \cdot \prod_{i=1}^n \binom{m}{x_i} =(1−p)nmexp{(i=1∑nxi)ln1−pp}⋅i=1∏n(xim)只要使: a ( p ) = ( 1 − p ) n m a(p) = (1-p)^{nm} a(p)=(1−p)nm, Q 1 ( p ) = ln p 1 − p Q_1(p) = \ln \frac{p}{1-p} Q1(p)=ln1−pp, T 1 ( x 1 , ... , x n ) = ∑ i = 1 n x i T_1(x_1, \dots, x_n) = \sum_{i=1}^n x_i T1(x1,...,xn)=∑i=1nxi, h ( x 1 , ... , x n ) = ∏ i = 1 n ( m x i ) h(x_1, \dots, x_n) = \prod_{i=1}^n \binom{m}{x_i} h(x1,...,xn)=∏i=1n(xim)即可证明。
例 2:均匀分布族 { R ( − θ , θ ) : θ > 0 } \{R(-\theta, \theta) : \theta > 0\} {R(−θ,θ):θ>0} 不是指数型分布族。
这是因为它的支撑 { x : f ( x ; θ ) > 0 } = ( − θ , θ ) \{x : f(x; \theta) > 0\} = (-\theta, \theta) {x:f(x;θ)>0}=(−θ,θ) 依赖于未知参数 θ \theta θ。
例 3:正态分布族 { N ( μ , σ 2 ) : − ∞ < μ < ∞ , σ 2 > 0 } \{N(\mu, \sigma^2) : -\infty < \mu < \infty, \sigma^2 > 0\} {N(μ,σ2):−∞<μ<∞,σ2>0} 是指数型分布族。
其样本的联合密度函数推导如下: f ( x ; μ , σ 2 ) = ( 1 2 π σ ) n exp { − ∑ i = 1 n 1 2 σ 2 ( x i − μ ) 2 } f(x; \mu, \sigma^2) = \left( \frac{1}{\sqrt{2\pi}\sigma} \right)^n \exp \left\{ - \sum_{i=1}^n \frac{1}{2\sigma^2}(x_i - \mu)^2 \right\} f(x;μ,σ2)=(2π σ1)nexp{−i=1∑n2σ21(xi−μ)2} = ( 1 2 π σ ) n exp { − n μ 2 2 σ 2 + n μ σ 2 x ˉ − ∑ i = 1 n x i 2 2 σ 2 } = \left( \frac{1}{\sqrt{2\pi}\sigma} \right)^n \exp \left\{ -\frac{n\mu^2}{2\sigma^2} + \frac{n\mu}{\sigma^2}\bar{x} - \sum_{i=1}^n \frac{x_i^2}{2\sigma^2} \right\} =(2π σ1)nexp{−2σ2nμ2+σ2nμxˉ−i=1∑n2σ2xi2} = ( 1 2 π σ ) n exp { − n μ 2 2 σ 2 } exp { n μ σ 2 x ˉ − 1 2 σ 2 ∑ i = 1 n x i 2 } = \left( \frac{1}{\sqrt{2\pi}\sigma} \right)^n \exp \left\{ -\frac{n\mu^2}{2\sigma^2} \right\} \exp \left\{ \frac{n\mu}{\sigma^2}\bar{x} - \frac{1}{2\sigma^2} \sum_{i=1}^n x_i^2 \right\} =(2π σ1)nexp{−2σ2nμ2}exp{σ2nμxˉ−2σ21i=1∑nxi2}
只要使: a ( μ , σ 2 ) = ( 1 2 π σ ) n exp { − n μ 2 2 σ 2 } a(\mu, \sigma^2) = \left( \frac{1}{\sqrt{2\pi}\sigma} \right)^n \exp \left\{ -\frac{n\mu^2}{2\sigma^2} \right\} a(μ,σ2)=(2π σ1)nexp{−2σ2nμ2}, Q 1 ( μ , σ 2 ) = n μ σ 2 , T 1 ( x ) = x ˉ Q_1(\mu, \sigma^2) = \frac{n\mu}{\sigma^2}, \quad T_1(x) = \bar{x} Q1(μ,σ2)=σ2nμ,T1(x)=xˉ, Q 2 ( μ , σ 2 ) = − 1 2 σ 2 , T 2 ( x ) = ∑ i = 1 n x i 2 Q_2(\mu, \sigma^2) = -\frac{1}{2\sigma^2}, \quad T_2(x) = \sum_{i=1}^n x_i^2 Q2(μ,σ2)=−2σ21,T2(x)=∑i=1nxi2, h ( x ) = 1 h(x) = 1 h(x)=1即可证明其属于指数型分布族。