TF-IDF
TF-IDF是TF(词频,Term Frequency)和IDF(逆文档频率,Inverse Document Frequency)的乘积。我们先来看他们分别是怎么计算的:
TF的计算有多种方式,常见的是
 除以文章总词数是为了标准化
除以文章总词数是为了标准化
IDF为:

如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数,求log是为了归一化,保证IDF不会过大。
所以TF-IDF 的计算就是:
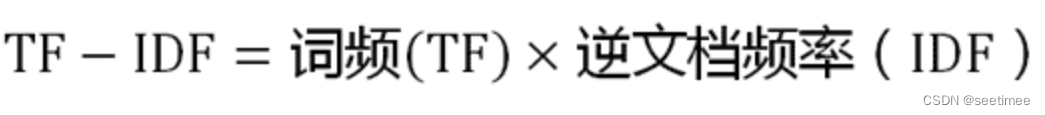

以下有几个细节点的理解:
- IDF表征的是区分度、稀缺性,用以评估一个单词在语料库中的重要程度,一个词在少数几篇文档中出现的次数越多,它的IDF值越高,如果这个词在大多数文档中都出现了,这个值就不大了。从公式也可以看出来,由于log函数是单增函数,当文档总数固定时,包含该词的文档数越少,IDF值越大,稀缺性越强。背后的思想是某个词或者短语在一篇文章中出现的频率高(TF大),并且在其他文档中很少出现(IDF也大),则认为该词或短语具备很好的类别区分能力(TF-IDF就越大)。
- TF刻画了词语w对某篇文档的重要性,IDF刻画了w对整个文档集的重要性。TF与IDF没有必然联系,TF低并不一定伴随着IDF高。实际上我们可以看出来,IDF其实是给TF加了一个权重。
优点与不足
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。这会导致TF-IDF法的精度并不是很高。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。(常用的一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。)同时TF-IDF没有考虑词频上限的问题。
BM25
因为在TF-IDF 中去停用词被认为是一种标准实践,故TF-IDF没有考虑词频上限的问题(因为高频停用词已经被移除了)。而在某些频率较高的停用词不被去除的情况下,停用词的权重会被无意义地放大。比如文中提到的:
Elasticsearch 的
standard标准分析器(string字段默认使用)不会移除停用词,因为尽管这些词的重要性很低,但也不是毫无用处。这导致:在一个相当长的文档中,像the和and这样词出现的数量会高得离谱,以致它们的权重被人为放大。
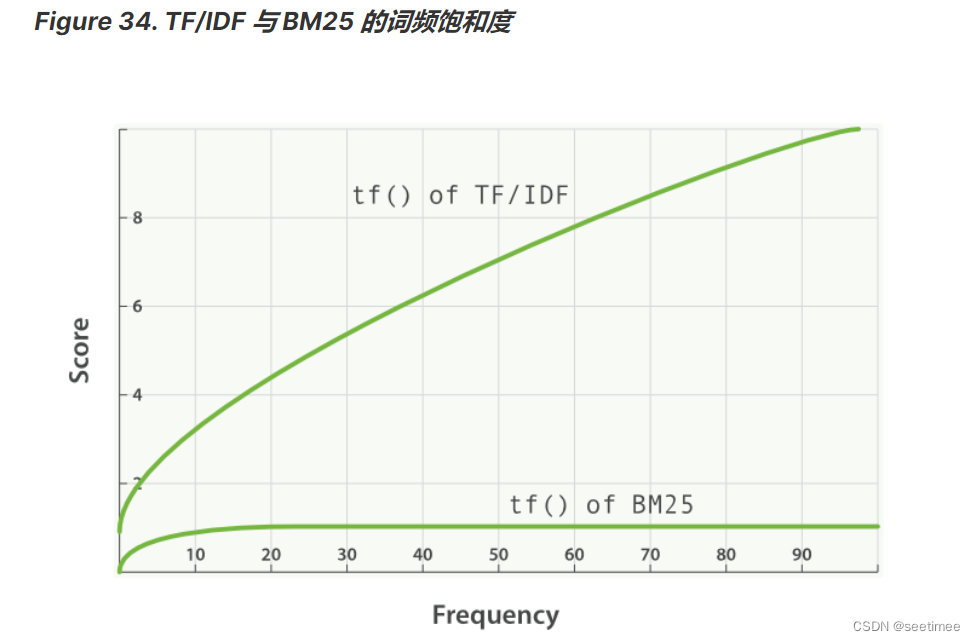
这就是所谓的词频饱和度,TF-IDF的词频饱和度是线性的,而BM25的词频饱和度是非线性的:
公式:
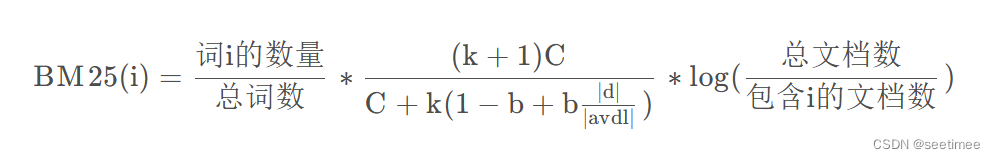
C = tf = ,k > 0,
,d为文档的长度,
是文档的平均长度
BM25和tfidf的计算结果很相似,唯一的区别在于中多了一项,这一项是用来对tf的结果进行的一种变换。把中的b看成0,那么此时项的结果为
,通过设置一个k,就能够保证其最大值为1,达到限制tf过大的目的。
即:
上下同除tf
k不变的情况下,上式随着tf的增大而增大,上限为k + 1,但是增加的程度会变小,如下图所示。在一个句子中,某个词重要程度应该是随着词语的数量逐渐衰减的,所以中间项对词频进行了一定罚,随着次数的增加,影响程度的增加会越来越小。通过设置k值,能够保证其最大值为k + 1,k往往取值1.2。
其变化如下图(无论k为多少,中间项的变化程度会随着次数的增加,越来越小):
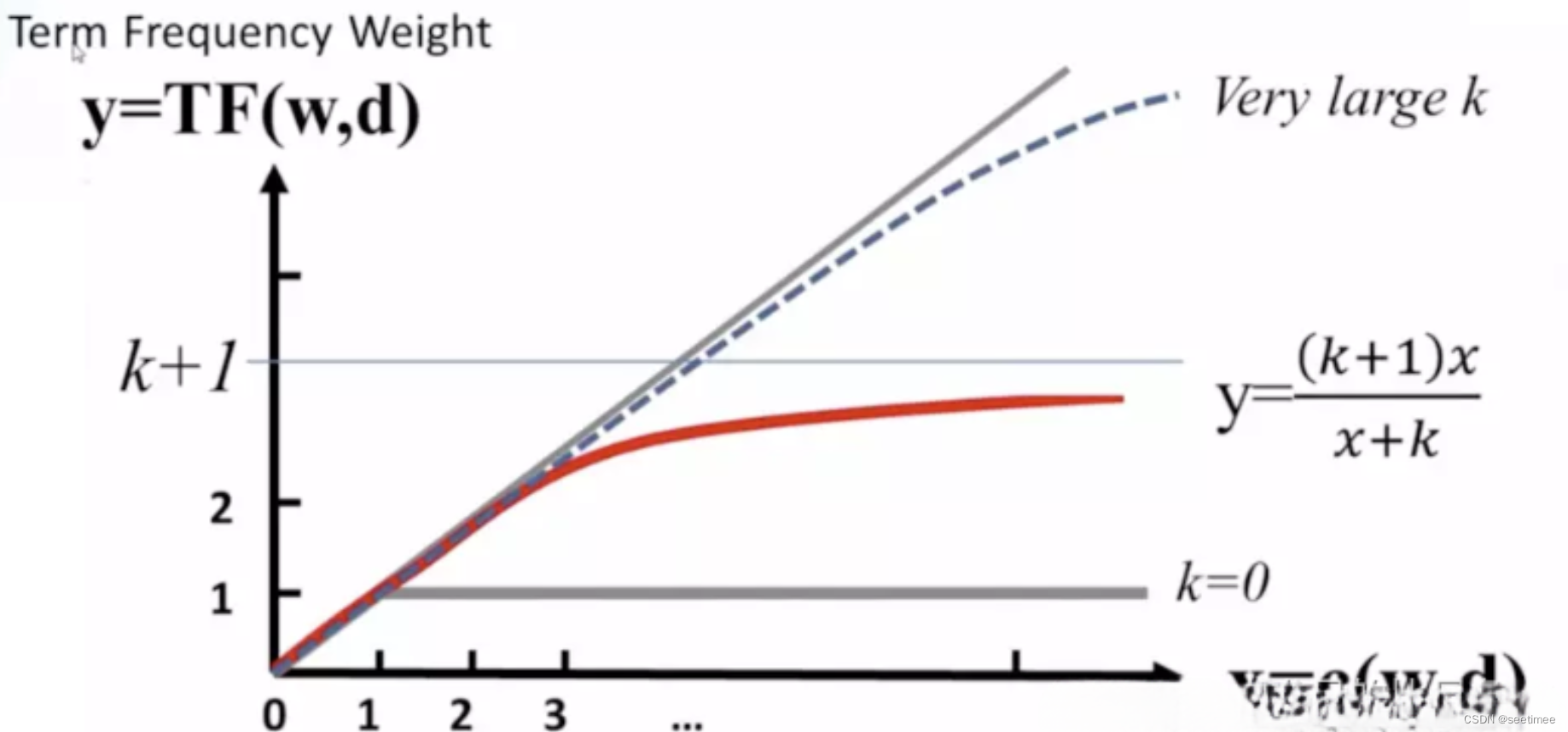
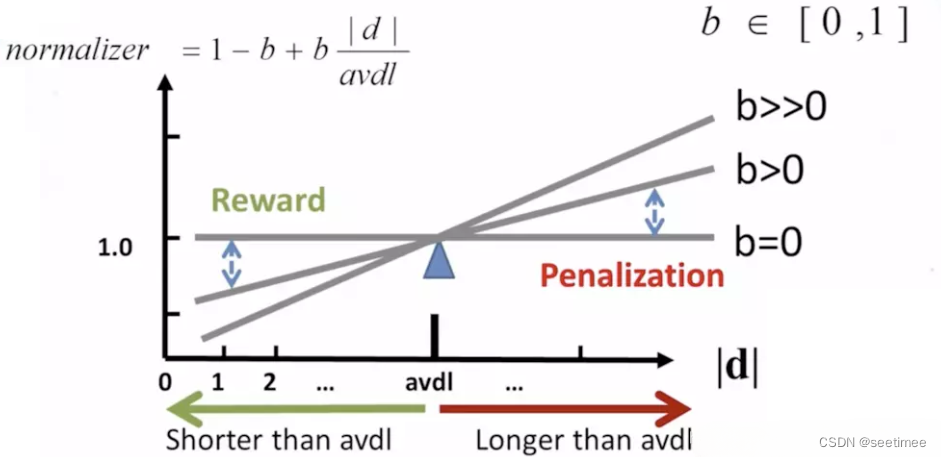
的作用是用来对文本的长度进行归一化。
例如在考虑整个句子的 tdidf 的时候,如果句子的长度太短,那么计算的总的 tdidf 的值是要比长句子的 tdidf 的值要低的。所以可以考虑对句子的长度进行归一化处理。
可以看到,当句子的长度越短, 的值是越小,作为分母的位置,会让整个第二项越大,从而达到提高短文本句子的 BM25 的值的效果。当 b 的值为 0,可以禁用归一化,b 往往取值 0.75。