由香港科技大学、快手科技提出的UNIC(统一上下文视频编辑)是一个简单而有效的框架,它以上下文的方式统一单个模型中的各种视频编辑任务。从此,视频编辑用着一个工具就够了!
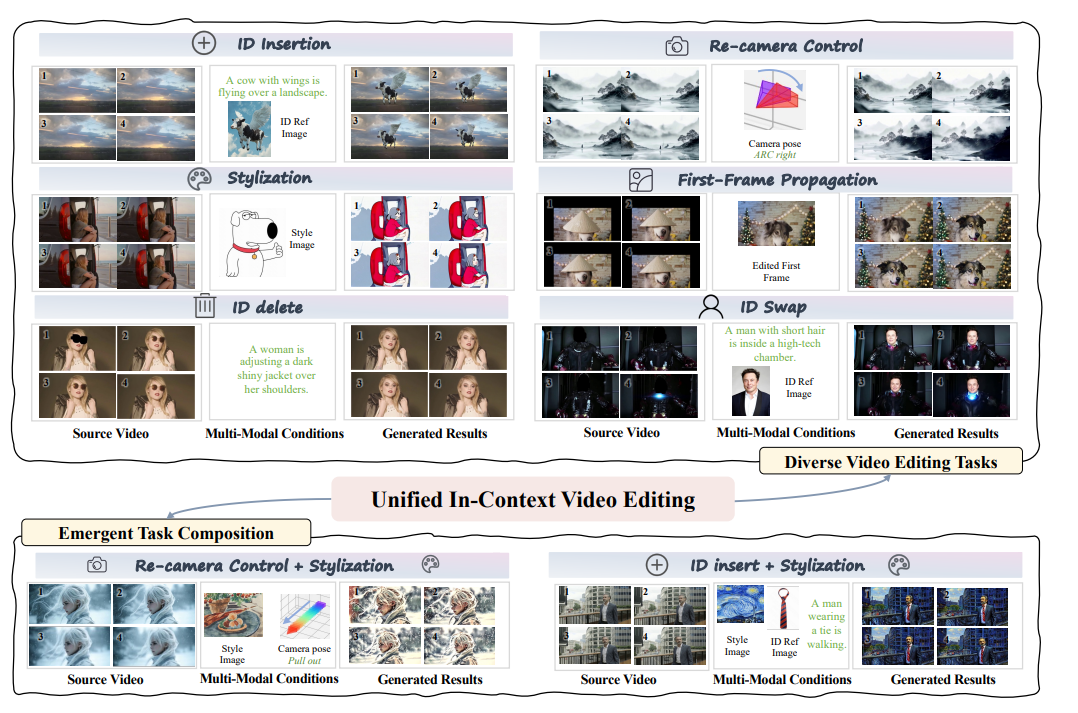
ID插入

ID交换

删除ID

相机控制

风格化

第一帧传播

紧急任务组合
UNIC 还表现出了新兴任务组合能力。
重新拍摄+风格化
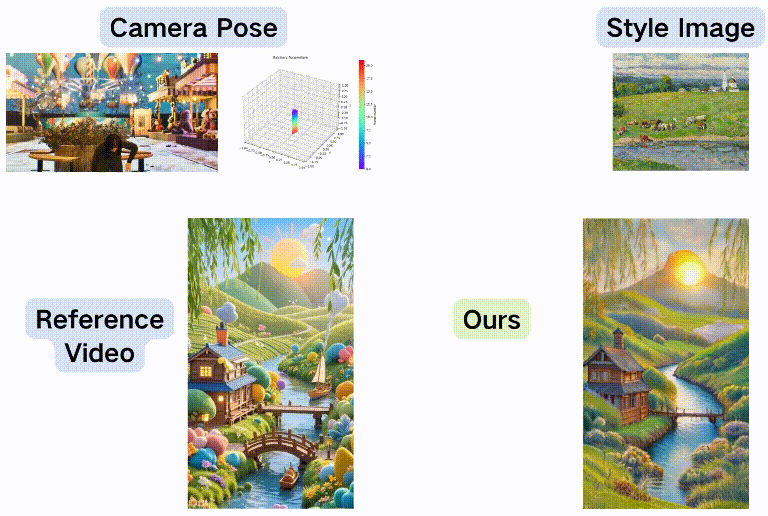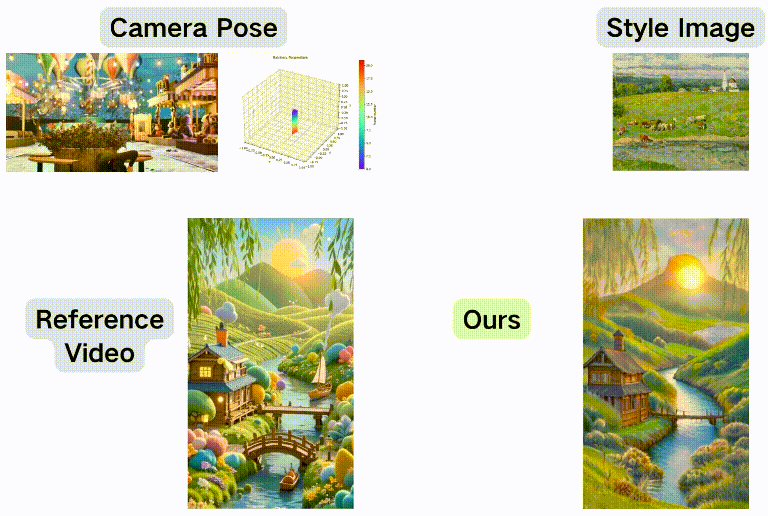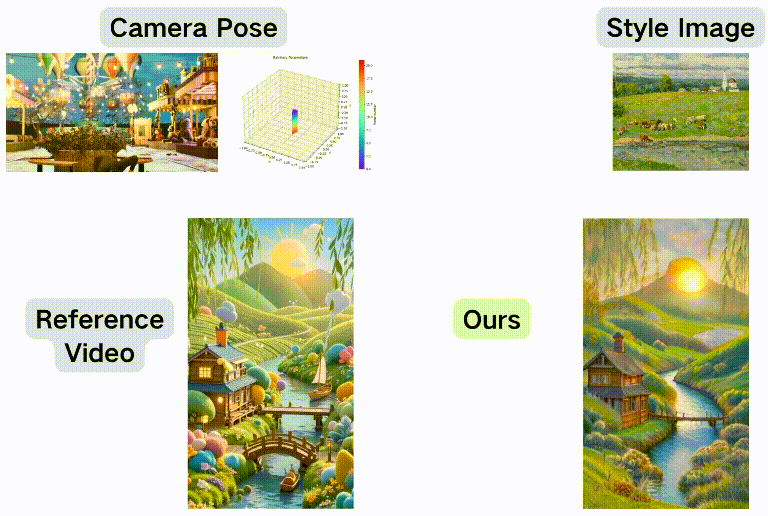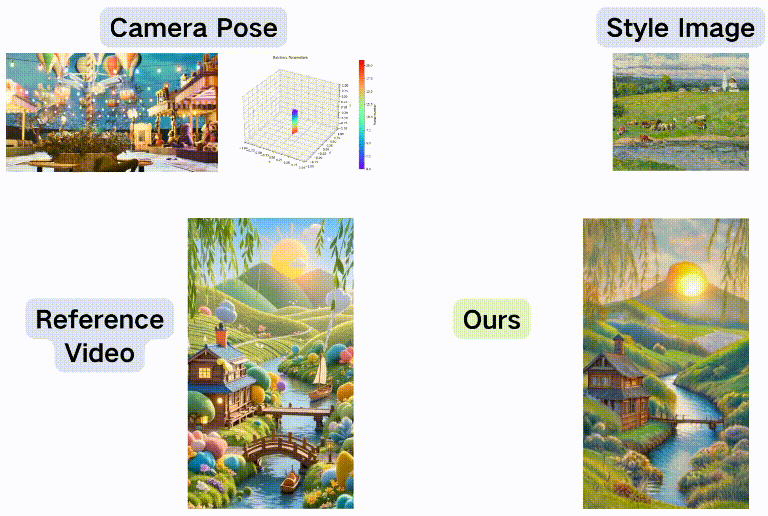
ID+风格化

相关链接
论文名:UNIC:Unified In-Context Video Editing
论文介绍

UNIC:框架和设计
动机
-
基于DDIM反转的方法(例如Video-P2P、FLATTEN):性能欠佳。 附加阶段,使推理步骤和总体成本加倍。
-
基于适配器的方法:需要修改模型架构。通过添加适配器模块引入参数冗余。
它们通常是针对特定任务的,需要针对每个不同的条件信号训练单独的模块。这严重阻碍了任务的可扩展性和各种编辑功能的统一。
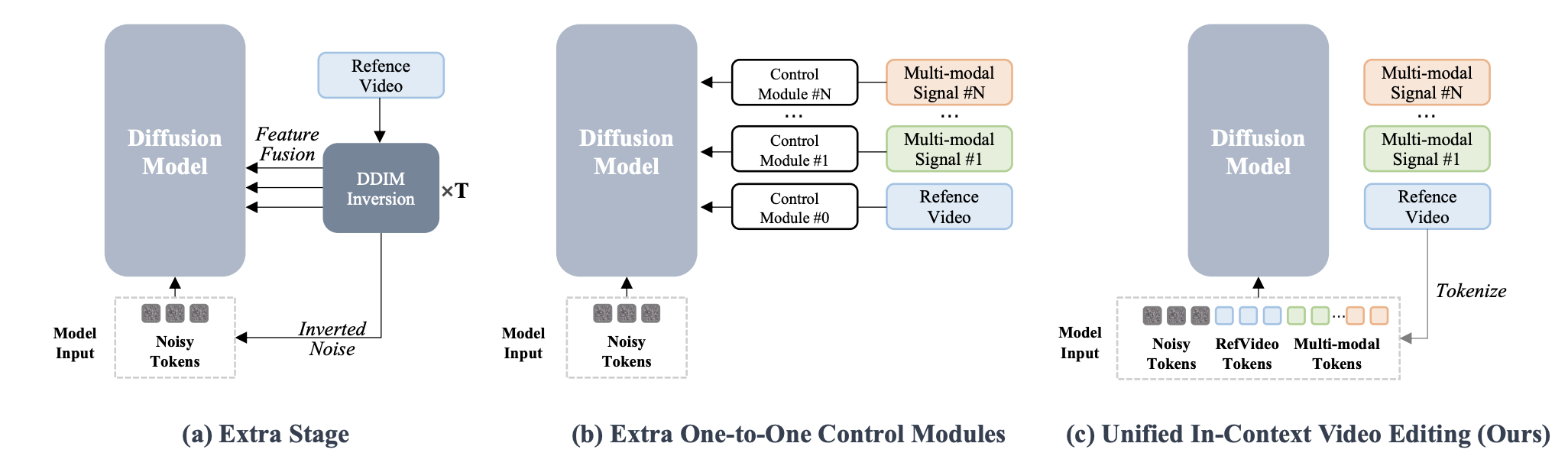
统一上下文框架
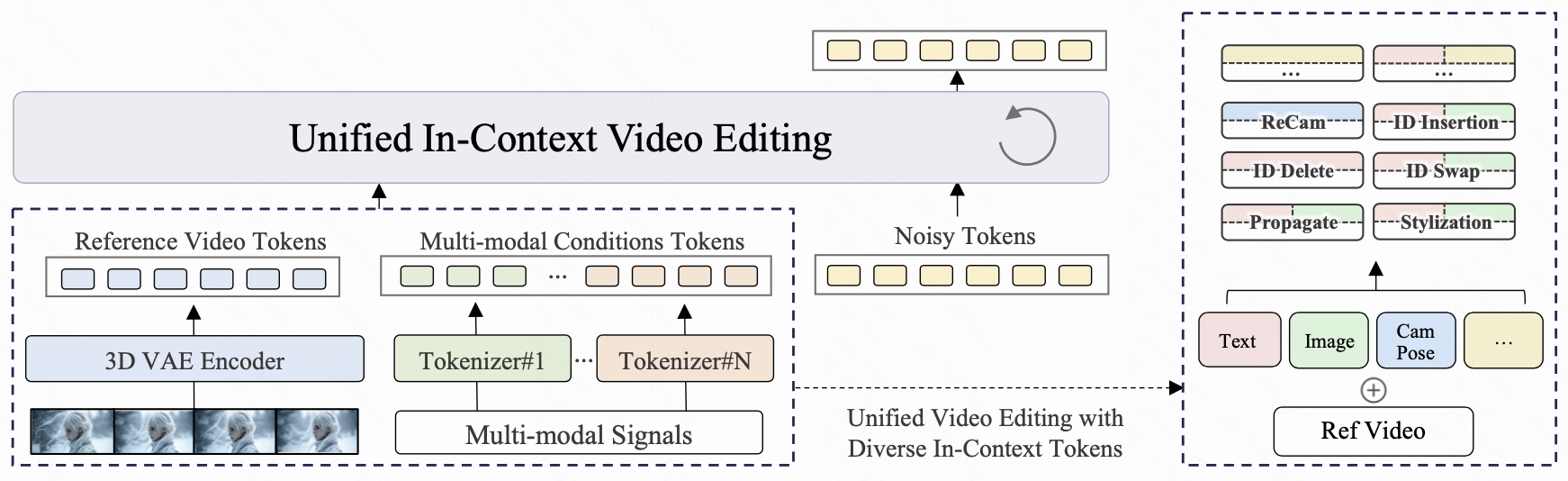
UNIC 通过将所有输入(含噪视频潜伏信号、参考视频标记以及各种多模态条件标记)处理为一个组合序列来统一视频编辑。这使得扩散变换器 (DiT) 的原生注意力机制能够"在上下文中"学习复杂的编辑任务,从而提供灵活性和简便性。
-
针对不同任务的统一模型。
-
将输入标记定义为三种类型。
-
没有特定任务的适配器模块。
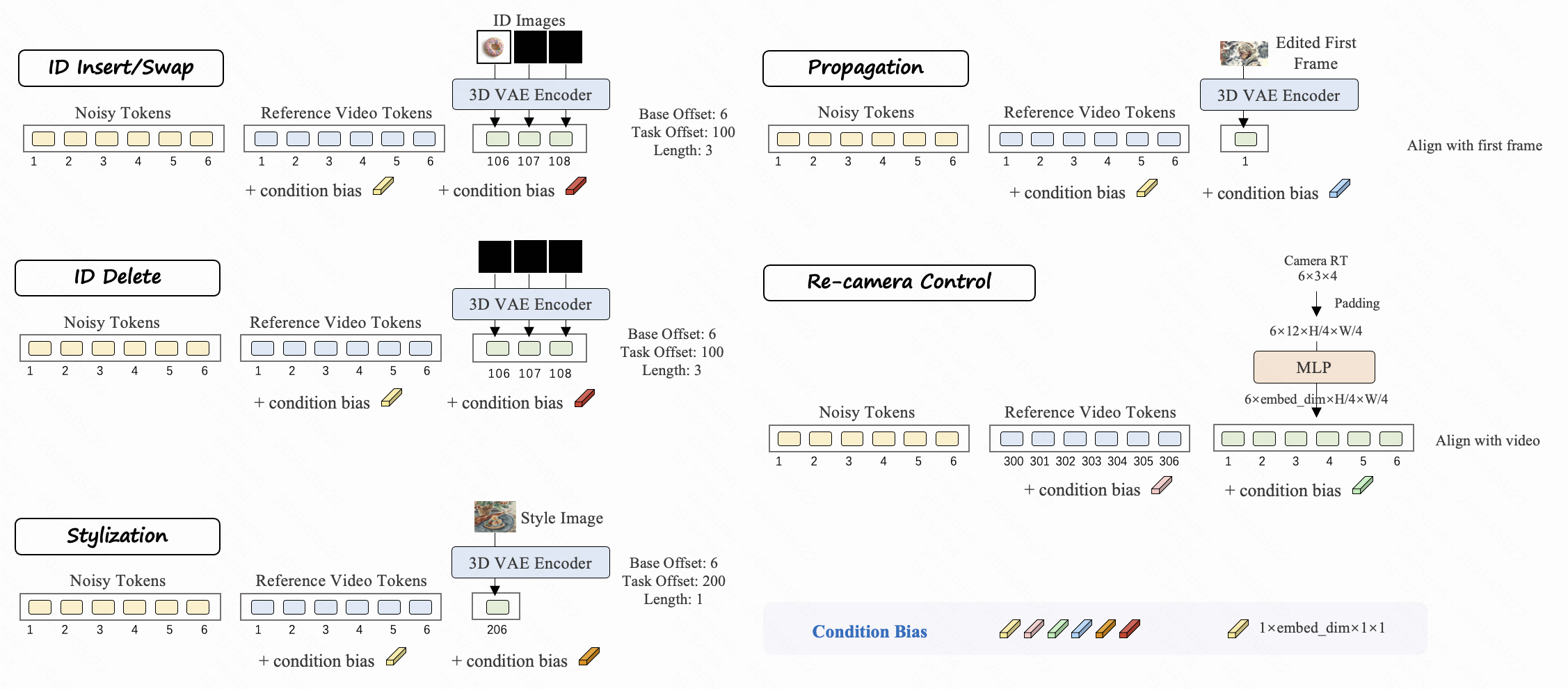
任务感知 RoPE
根据任务类型和视频长度动态分配唯一的旋转位置嵌入 (RoPE) 帧索引。这确保了在不同条件下对时间的理解和正确对齐。
条件偏差
为条件标记添加特定于任务的可学习嵌入。这有助于模型在模态重叠时区分目标任务,从而有效解决歧义。
结论
论文提出的统一的上下文内视频编辑UNIC是一个简单而有效的框架,它以上下文内的方式将不同的视频编辑任务统一到一个模型中。为此,我们将不同视频编辑任务的输入表示为三种类型的标记,并将它们集成为一个统一的标记序列,并与扩散变换器 (Diffusion Transformer) 的原始全注意力机制联合建模。凭借设计的任务感知 RoPE 和条件偏差,该方法可以灵活地执行不同的编辑任务并支持它们的组合。为了便于评估,论文还构建了一个统一的视频编辑基准。在六个代表性视频编辑任务上进行的大量实验表明,该模型在每项任务上都表现出卓越的性能,并展现出新兴的任务组合能力。