1st author: Bowen Jin | Ph.D. Student @ UIUC
paper: [2503.09516 Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning](https://arxiv.org/abs/2503.09516)
5. 总结 (结果先行)
Search-R1 提出了一种有前景的思路:通过强化学习赋予 LLM 动态规划和执行信息检索行为的能力。它将搜索引擎视为环境的一部分,让 LLM 在与环境的交互中学习如何更好地"利用工具"来辅助其推理和生成。实验结果表明,这种主动学习搜索的范式能够显著提升 LLM 在知识密集型和复杂推理任务上的表现。
这项工作为未来如何更深度地融合 LLM 的推理能力与外部知识源的利用能力提供了一个有价值的探索方向,特别是在构建更自主、更智能的 AI Agent 方面具有启示意义。
当然,奖励函数的设计、探索与利用的平衡、以及在更开放领域任务上的泛化能力,仍是未来值得持续研究的课题。
1. 思想
论文的核心思想是,与其 让大型语言模型 (LLM) 仅仅被动地接收检索到的信息 (如传统 RAG),或者依赖于固定的、可能并非最优的提示工程来与搜索引擎交互 (如某些 Tool-use 方法),不如 通过强化学习 (RL) 直接训练 LLM 学会如何主动、有效地利用搜索引擎进行多轮次的查询和推理。
作者认为,LLM 本身可能并不具备与搜索引擎进行最优交互的内在能力,这种能力需要被"教会"。Search-R1 试图将搜索过程本身也纳入 LLM 的学习和优化范畴,使其能够根据任务的复杂度和当前推理状态,动态地决定何时搜索、搜索什么以及如何整合搜索结果。
2. 方法
Search-R1 构建了一个 RL 框架,使得大型语言模型 (LLM) 能够学习自主地、多轮次地与搜索引擎交互,以优化其在复杂问答任务中的推理和答案生成能力。其方法可以分解为以下几个关键组成部分:
2.1 RL 环境与智能体
- 智能体 (Agent) : 待训练的 LLM,即策略模型 π θ \pi_{\theta} πθ,其参数为 θ \theta θ。
- 环境 (Environment) : 由输入问题 x x x、搜索引擎 R R R 以及与模型交互的整个过程构成。智能体的动作是生成 token 序列 y t y_t yt (可以是思考、查询、或答案的一部分),环境根据这些动作和搜索引擎的反馈给出状态转移和最终奖励。
2.2 轨迹生成与动作空间
模型生成的轨迹 y y y 是一个交错序列,形式为 y = ( s 0 , a 0 , s 1 , a 1 , . . . , s T , a T ) y = (s_0, a_0, s_1, a_1, ..., s_T, a_T) y=(s0,a0,s1,a1,...,sT,aT),其中:
- s t s_t st 是在 t t t 时刻的输入状态 (包含原始问题、历史思考、历史搜索结果等)。
- a t a_t at 是模型在状态 s t s_t st 下采取的动作,即生成的一段 token 序列。这些动作可以归为几类:
- 思考 (Think) : 模型生成
<think>...</think>标记内的文本,进行内部推理。 - 搜索 (Search) : 模型生成
<search>query</search>标记,系统提取query并调用搜索引擎 R R R。 - 整合 (Integrate) : 搜索引擎返回的结果 d = R ( q u e r y ) d = R(query) d=R(query) 被封装为
<information>d</information>并追加到当前轨迹中,成为下一时刻状态的一部分。 - 回答 (Answer) : 模型生成
<answer>final_answer</answer>标记,给出最终答案。
- 思考 (Think) : 模型生成
2.3 强化学习目标
-
RL 目标函数 : 核心优化目标可以形式化为:
max π θ E x ∼ D , y ∼ π θ ( ⋅ ∣ x ; R ) r ϕ ( x , y ) − β D K L π θ ( y ∣ x ; R ) ∣ ∣ π r e f ( y ∣ x ; R ) \max_{\pi_{\theta}} \mathbb{E}{x \sim D, y \sim \pi{\theta}(\cdot|x;R)} r_{\\phi}(x,y) - \beta D_{KL}\\pi_{\\theta}(y\|x;R) \|\| \\pi_{ref}(y\|x;R) πθmaxEx∼D,y∼πθ(⋅∣x;R)rϕ(x,y)−βDKLπθ(y∣x;R)∣∣πref(y∣x;R)其中:
- x x x 是从数据集 D D D 中抽取的输入问题。
- y y y 是模型生成的完整轨迹 (trajectory),包含 LLM 生成的思考、搜索查询和最终答案。
- π θ \pi_{\theta} πθ 是待优化的策略 LLM (policy LLM),参数为 θ \theta θ。
- R R R 代表搜索引擎,它作为环境的一部分,模型通过 R R R 进行实时检索。 y ∼ π θ ( ⋅ ∣ x ; R ) y \sim \pi_{\theta}(\cdot|x;R) y∼πθ(⋅∣x;R) 表示轨迹 y y y 是在给定输入 x x x 和搜索引擎 R R R 的条件下,由策略 LLM π θ \pi_{\theta} πθ 生成的。这可以理解为模型的生成过程 π θ ( ⋅ ∣ x ) \pi_{\theta}(\cdot|x) πθ(⋅∣x) 与搜索引擎 R R R 的交互 ( \\pi_{\\theta}(\\cdot\|x) \\otimes R ,如论文第 4 页所述, ,如论文第4页所述, ,如论文第4页所述,\\otimes 表示交错的检索与推理)。
- r ϕ ( x , y ) r_{\phi}(x,y) rϕ(x,y) 是奖励函数,用于评估生成轨迹 y y y 的质量,论文中采用了简单的基于最终答案的 outcome-based 奖励 (精确匹配 (Exact Match), 正确奖励为 1,否则为 0)。
- π r e f \pi_{ref} πref 是参考 LLM (reference LLM),通常是预训练模型或其微调版本,用于正则化。
- D K L ⋅ ∣ ∣ ⋅ D_{KL}\\cdot \|\| \\cdot DKL⋅∣∣⋅ 是 KL 散度,用于惩罚策略 LLM π θ \pi_{\theta} πθ 过度偏离参考 LLM π r e f \pi_{ref} πref,以维持生成质量和训练稳定性。
- β \beta β 是 KL 散度的权重超参数。
-
多轮交错的推理与搜索 :
LLM 的输出轨迹包含特殊的控制标记:
<think>...</think>: LLM 的内部思考和推理步骤。<search>query</search>: LLM 生成的搜索查询。系统捕获此查询并调用搜索引擎 R R R。<information>retrieved_content</information>: 搜索引擎返回的检索内容,被包裹后送回给 LLM 作为后续生成的上下文。<answer>final_answer</answer>: LLM 最终给出的答案。
这个过程可以迭代进行多轮。
-
检索内容损失掩码 (Retrieved Token Masking):
在计算梯度和更新模型参数时,对于轨迹 y y y 中的 token,只有那些由 LLM 主动生成 的 token (例如,
<think>内的思考,<search>内的查询,<answer>内的答案) 才会被计算损失并参与反向传播。而那些由搜索引擎返回并插入到轨迹中的 检索内容 (即<information>...</information>内部的 token) 则会被掩码掉,其对应的损失项为 0。这个机制的目的是:
- 稳定训练: 防止模型试图去"拟合"或"预测"外部知识库的内容,因为这既困难也不符合学习目标。
- 聚焦学习: 确保模型专注于学习如何进行有效的推理、生成恰当的查询、以及如何利用检索到的信息,而不是学习复述检索内容。
2.4 策略优化算法
论文中主要探索了两种策略梯度方法:PPO (Proximal Policy Optimization) 和 GRPO (Group Relative Policy Optimization)。
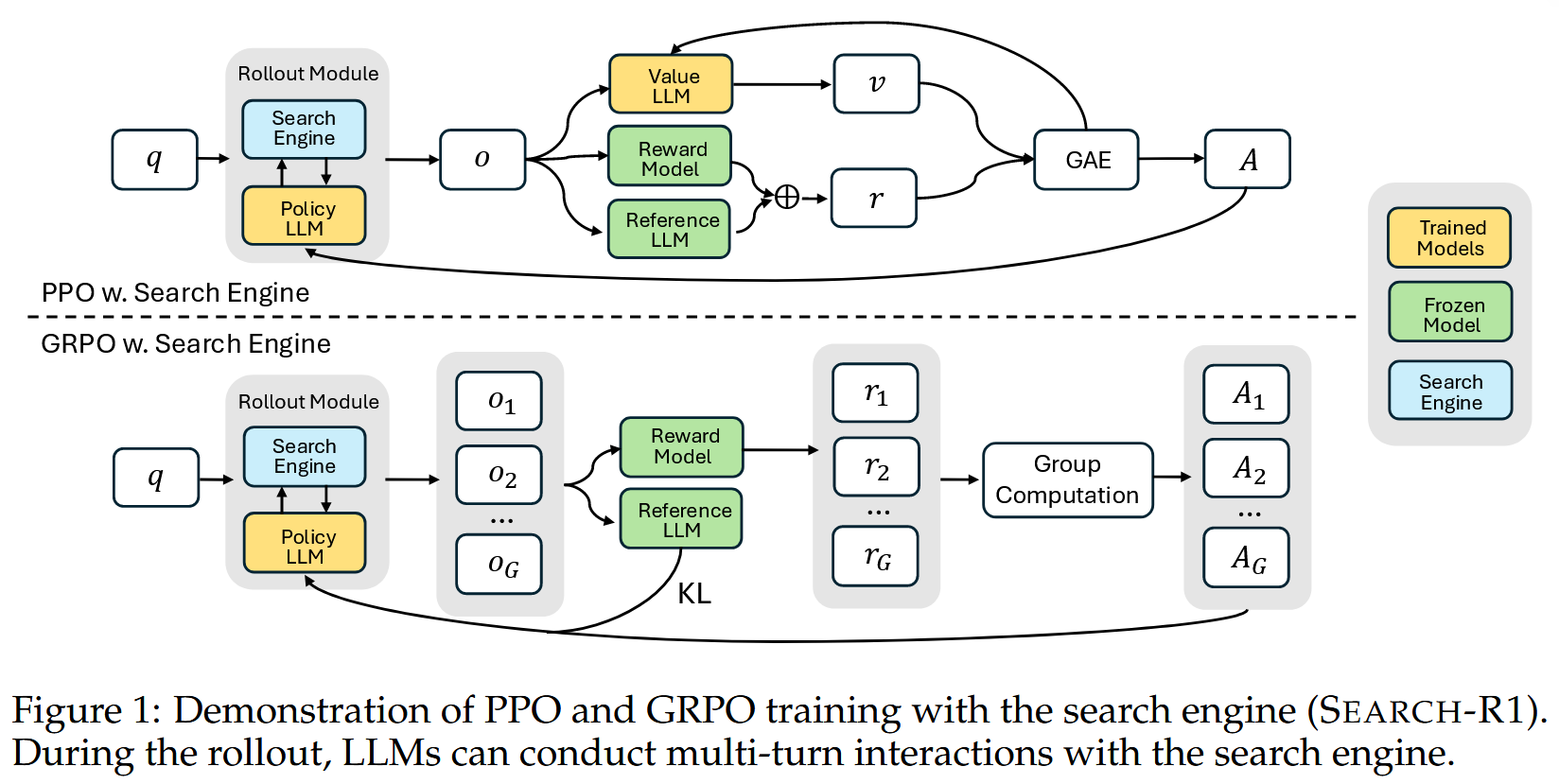
2.5 训练模板
为了引导初始 LLM 遵循预期的多轮交互格式,论文使用了一个简单的结构化模板 (如 Table 1 所示)。这个模板仅规定了输出的基本结构 (思考-搜索-整合-回答的循环),而没有对内容本身做过多限制,以保证 LLM 在 RL 训练中能够自由探索和学习其内在的决策逻辑。

3. 优势
相较于现有方法,Search-R1 的主要优势在于:
- 主动学习搜索策略: LLM 不再是被动的信息接收者,而是主动学习何时、为何以及如何进行搜索,从而可能发现比固定提示或单轮 RAG 更优的搜索和信息整合策略。
- 端到端优化: 通过 RL,整个"推理-搜索-整合"的链条是朝着最终任务目标 (如问答正确率) 进行优化的,而不仅仅是优化检索的召回率或生成流畅性。
- 对复杂问题的适应性: 多轮交互机制使得模型能够分解复杂问题,通过迭代搜索和推理逐步逼近答案,这对于需要多跳推理的任务尤其重要。
- 训练稳定性与效率: 检索内容损失掩码有助于稳定 RL 训练;采用简单的 outcome-based 奖励避免了设计复杂的过程奖励 (process rewards) 的麻烦,也减少了对高质量人工标注轨迹的依赖。
- 通用性: 该框架可以与不同的 RL 算法 (PPO, GRPO) 和不同规模的 LLM 结合。
4. 实验
-
数据集: 在 7 个不同的问答数据集上进行了评估,包括通用 QA (NQ, TriviaQA, PopQA) 和多跳 QA (HotpotQA, 2WikiMultiHopQA, Musique, Bamboogle),覆盖了不同难度和类型的挑战。
-
基线模型: 与多种基线进行了对比,包括无检索的直接推理和 CoT、基于检索的 RAG、IRCoT、Search-o1,以及基于微调的 SFT 和 R1 (仅用 RL 优化推理而不进行搜索)。
-
主要发现 :
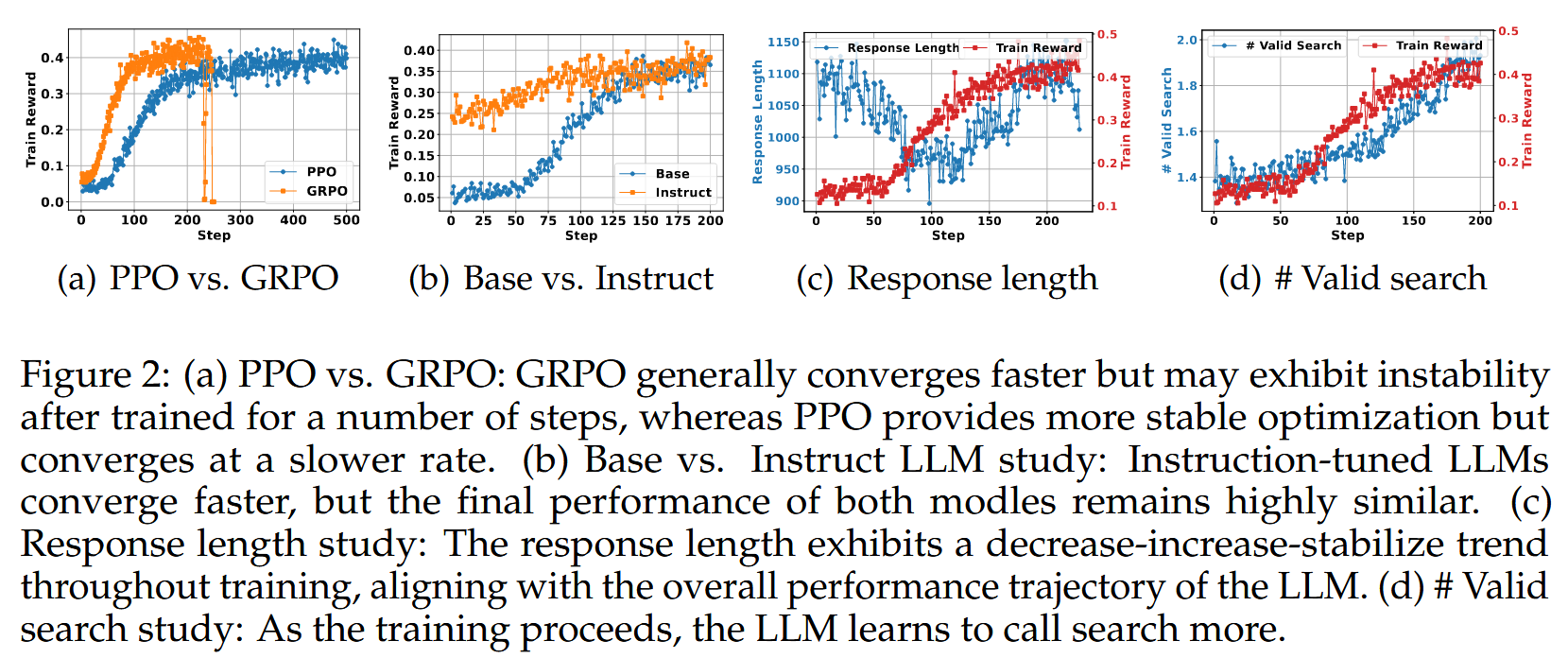
- Search-R1 在 Qwen2.5-7B 和 Qwen2.5-3B 模型上,相较于 RAG 基线分别取得了平均 41% 和 20% 的显著相对性能提升。
- 无论是在域内还是域外数据集上均表现出色。
- 优于仅进行 RL 推理优化的 R1 模型,证明了学习搜索的价值。
- 对基础模型 (base model) 和指令微调模型 (instruct model) 均有效。
- PPO 相较于 GRPO 在此场景下展现出更好的训练稳定性,但 GRPO 收敛更快。
- 检索内容损失掩码对于性能提升和稳定训练至关重要。