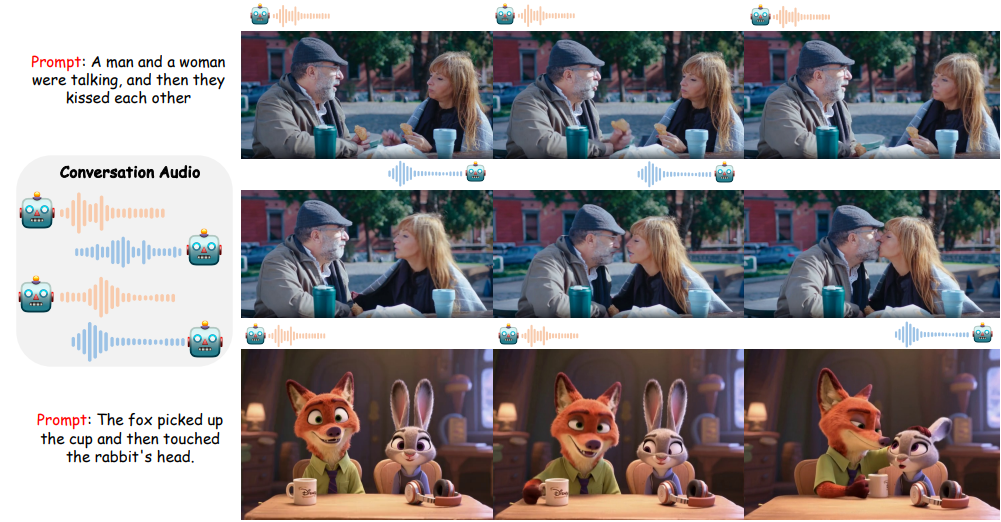
由中山大学、美团、香港科技大学联合提出的MultiTalk是一个用于音频驱动的多人对话视频生成的新框架。给定一个多流音频输入和一个提示,MultiTalk 会生成一个包含提示所对应的交互的视频,其唇部动作与音频保持一致。
相关链接
论文介绍

音频驱动的人体动画方法,例如说话头部和说话身体生成,在生成同步面部动作和引人入胜的视觉质量视频方面取得了显著进展。然而,现有方法主要侧重于单人动画,难以处理多流音频输入,存在音频与人物绑定不正确的问题。此外,它们在指令遵循能力方面也存在局限性。
为了解决这一问题,本文提出了一项新的任务:多人对话视频生成,并引入了一个新框架 MultiTalk 来应对多人生成过程中的挑战。具体来说,对于音频注入,我们研究了多种方案,并提出了标签旋转位置嵌入 (L-RoPE) 方法来解决音频和人物绑定问题。此外,在训练过程中,我们观察到部分参数训练和多任务训练对于保持基础模型的指令遵循能力至关重要。MultiTalk 在多个数据集(包括说话头部、说话身体和多人数据集)上取得了优于其他方法的性能,证明了我们方法强大的生成能力。
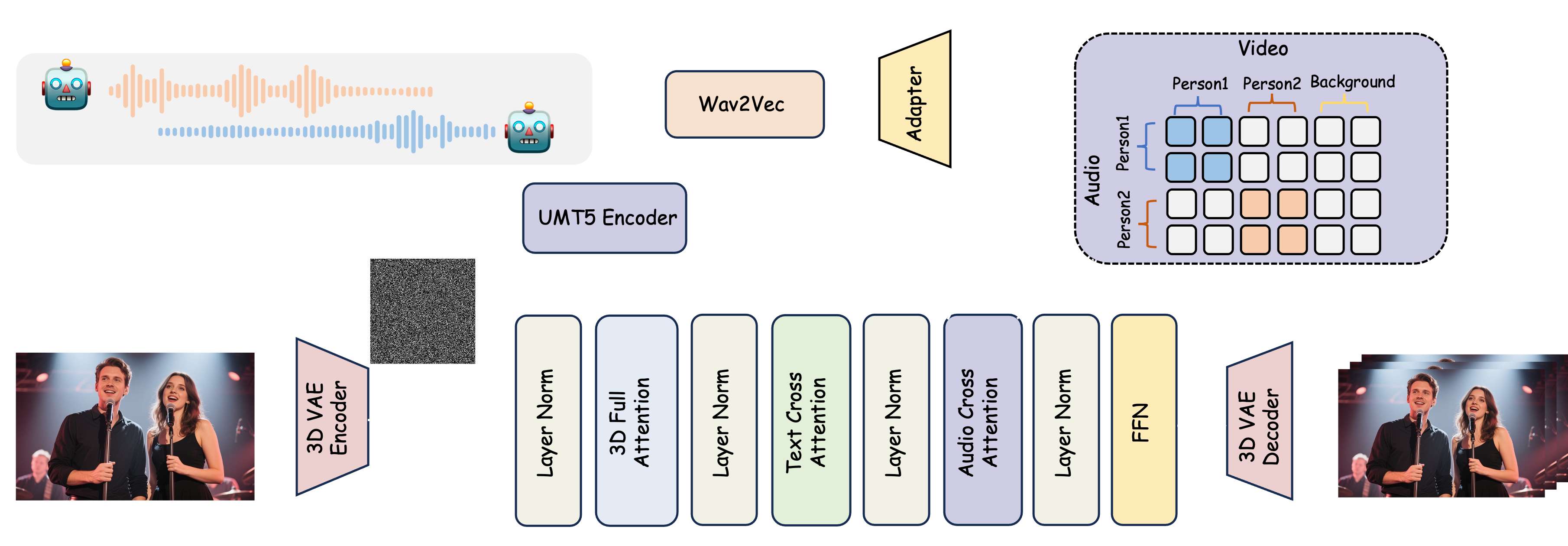
方法
论文提出了一个音频驱动的视频生成框架 MultiTalk。该框架新增了一个音频交叉注意力层,以支持音频条件。为了实现多人对话视频生成,论文提出了一种用于多流音频注入的标签旋转位置嵌入 (L-RoPE)。