概叙
Java web应用性能分析之服务端慢和优化概叙_cpu飙高java-CSDN博客
Java web应用性能分析之【CPU飙升分析概述】_web页面性能分析cpu占满是因为死循环,还是循环过多-CSDN博客
在我们的软件服务中,软件部署的服务器,一般都是linux服务器,也就是装了linux操作系统的服务器,linux服务器是一个统称,其实在我们springboot应用中根据功能不同,还分成:堡垒机服务器、Nginx路由服务器、web服务器/java应用服务器、文件服务器、图片服务器、数据库服务器、redis缓存服务器、KFK消息队列服务器、ES检索服务器、多媒体处理服务器等等,不同功能的服务器性能优化的重点可能不一样,前面的文章都是也是在这些角度去整理的。
除了这些之外,今天再加一个linux内核调优,其实它和linux服务器性能调优是分不开的,因为linux服务器上系统内核是桥梁、是连接服务器硬件和软件的桥梁,linux服务器性能调优、绕不开内核调优。
所以就有这个公式: linux服务器调优 = 监控 + 调优( 内核调优 + 硬件服务器调优 + 软件调优)
linux服务器性能优化都是根据监控情况,从内核调优、硬件服务器调优(CPU、内存、存储、网络)、软件调优(操作系统、中间件、应用软件)等方面入手,去做具体分析和论证,然后给出解决方案。
切记不要粗略的将这些独立分开去优化,整体分析和调优,效果会更好。优化的目标是提高系统的整体性能,在同等条件下降低资源消耗,提升系统的稳定性、可用性。
常用的linux内核参数整理:科普文:linux服务器性能调优之内核参数-CSDN博客
单独
1.CPU调度优化
CPU调度是Linux系统内核的核心功能之一,它负责将CPU资源分配给不同的进程。合理的CPU调度策略能够显著提高系统的响应速度和吞吐量。在优化CPU调度时,我们可以考虑以下几个方面:
(1)调整进程优先级:通过调整进程的优先级,可以让重要的进程获得更多的CPU资源,从而提高系统的整体性能。
通过nice和chrt命令修改进程优先级,调度策略,参考如下:
科普文:Linux服务器性能调优之CPU调度策略和可调参数-CSDN博客
(2)使用多核CPU:充分利用多核CPU的并行处理能力,可以提高系统的并发性能。
Nginx服务器上,可以将Nginx的work进程和cup内核绑定,减少切换,提升性能。
bash
# 修改Apache配置文件
vi /etc/httpd/conf/httpd.conf
# 找到以下两行,修改为合适的值
StartServers 8 # 初始启动的进程数
MaxRequestWorkers 150 # 最大的并发请求处理数
user nginx nginx; # 启动Nginx⼯作进程的⽤⼾和组
worker_processes [number | auto]; # 启动Nginx⼯作进程的数量
worker_cpu_affinity 00000001 00000010 00000100 00001000;
# 将Nginx⼯作进程绑定到指定的CPU核⼼,默认Nginx是不进⾏进程绑定的,
# 绑定并不是意味着当前nginx进程独 占以⼀核⼼CPU,但是可以保证此进程不会运⾏在其他核⼼上,
# 这就极⼤减少了nginx的⼯作进程在不同的cpu核 ⼼上的来回跳转,减少了CPU对进程的资源分配与回收以及内存管理等,
#因此可以有效的提升nginx服务器的性 能。 此处CPU有四颗核心。也可写成:
#worker_cpu_affinity 0001 0010 0100 1000;
#cpu的亲和能偶使nginx对于不同的work工作进程绑定到不同的cpu上面去。就能够减少在work间不#断切换cpu,把进程通常不会在处理器之间频繁迁移,进程迁移的频率小,来减少性能损耗。
#每个 worker 的线程可以把一个 cpu 的性能发挥到极致。所以 worker 数和服务器的 cpu 数相#等是最为适宜的。设少了会浪费 cpu,设多了会造成 cpu 频繁切换上下文带来的损耗(3)调整调度器策略:内核通过调度器(Scheduler)来控制进程的执行顺序和资源分配,从而实现进程的多任务处理能力。Linux系统提供了多种调度器策略,如CFS(Completely Fair Scheduler)、Deadline等。
使用任务调度器来优化CPU负载。Linux系统提供了多个任务调度器,如cron、at和anacron等。可以使用这些调度器来安排任务在系统闲时运行,避免在高负载期间执行计算密集型任务。通过合理安排任务的执行时间,可以减少系统的CPU负载,提高性能。
参考:科普文:Linux服务器性能调优之CPU调度策略和可调参数-CSDN博客
(4)启用CPU缓存: 启用CPU缓存可以提高CPU的性能,减少内存的访问次数。在CentOS上,我们可以通过调整一些参数来启用或优化CPU缓存。
bash
# 查看CPU缓存策略
cat /sys/devices/system/cpu/cpu*/cpufreq/cpuinfo_cache_policy
# 设置CPU缓存策略为Write Back
for i in /sys/devices/system/cpu/cpu*/cpufreq/cpuinfo_cache_policy; do echo writeback > $i; done
# 设置缓存内存调度策略为负载均衡
echo 1 > /proc/sys/vm/page-cluster(5)NUMA优化: CPU尽可能访问本地内存
java服务器:jdk15之后可以选择ZGC垃圾回收器
bash
ZGC是支持NUMA的(UMA即Uniform Memory Access Architecture,NUMA就是Non Uniform Memory Access Architecture),
在进行小页面分配时会优先从本地内存分配,当不能分配时才会从远端的内存分配。
对于中页面和大页面的分配,ZGC并没有要求从本地内存分配,而是直接交给操作系统,由操作系统找到一块能满足ZGC页面的空间。
ZGC这样设计的目的在于,对于小页面,存放的都是小对象,从本地内存分配速度很快,
且不会造成内存使用的不平衡,而中页面和大页面因为需要的空间大,如果也优先从本地内存分配,极易造成内存使用不均衡,反而影响性能。数据库服务器:禁用numa
bash
1)Oracle数据库层面关闭:
_enable_NUMA_optimization=false (11g中参数为_enable_NUMA_support)
2)启动MySQL的时候,关闭NUMA特性:
numactl --interleave=all mysqld
指定numa也就其弊端,当服务器还有内存的时候,发现它已经在开始使用swap了,甚至已经导致机器出现停滞的现象。这个就有可能是由于numa的限制,如果一个进程限制它只能使用自己的numa节点的内存,那么当自身numa node内存使用光之后,就不会去使用其他numa node的内存了,会开始使用swap,甚至更糟的情况,机器没有设置swap的时候,可能会直接死机。
所以数据库服务器不适合开启numa。
操作系统层面关闭NUMA
有如下方法:
1)BIOS中关闭NUMA设置
2)在操作系统中关闭,
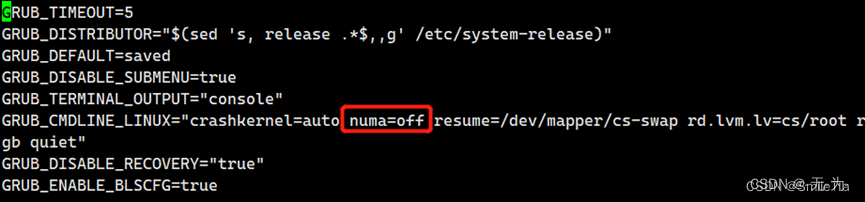
在RHEL 4, RHEL 5, RHEL 6 中,在/boot/grub/grub.conf文件中添加numa=off,如下所示:
title Red Hat Enterprise Linux AS (2.6.9-55.EL)
root (hd0,0)
kernel /vmlinuz-2.6.9-55.EL ro root=/dev/VolGroup00/LogVol00 rhgb quiet numa=off
initrd /initrd-2.6.9-55.EL.img
在RHEL 7 中,需要修改/etc/default/grub文件,添加numa=off,并且需要重建grub,然后重启OS:
[root@18cRac1 software]# cat /etc/default/grub
GRUB_TIMEOUT=5
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
GRUB_DEFAULT=saved
GRUB_DISABLE_SUBMENU=true
GRUB_TERMINAL_OUTPUT="console"
GRUB_CMDLINE_LINUX="rhgb quiet transparent_hugepage=never numa=off"
GRUB_DISABLE_RECOVERY="true"
[root@18cRac1 software]# grub2-mkconfig -o /boot/grub2/grub.cfg
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-3.10.0-862.el7.x86_64
Found initrd image: /boot/initramfs-3.10.0-862.el7.x86_64.img
Found linux image: /boot/vmlinuz-0-rescue-4c7b16d0887748f883ee1a722ec96352
Found initrd image: /boot/initramfs-0-rescue-4c7b16d0887748f883ee1a722ec96352.img
done
[root@18cRac1 software]#编辑/etc/default/grub,在 GRUB_CMDLINE_LINUX里添加 numa=off,然后重启服务器。
(6)中断负载均衡: irpbalance,将中断处理过程自动负载均衡到各个CPU上
(7)cpu调速器:服务器先不考虑节能,性能最大化优先。
bash
# 查看当前的CPU调度策略
cat /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
# 将CPU调度策略设置为performance
for i in /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor; do echo performance > $i; done
Performance:性能优先的governor,直接将cpu频率设置为policy->{min,max}中的最大值。
Powersave:功耗优先的governor,直接将cpu频率设置为policy->{min,max}中的最小值。
Userspace:由用户空间程序通过scaling_setspeed文件节点修改频率。
Ondemand:根据CPU的当前使用率,动态的调节CPU频率。scheduler通过调用ondemand注册进来的钩子函数来触发系统负载的估算(异步的)。它以一定的时间间隔对系统负载情况进行采样。按需动态调整CPU频率, 如果的CPU当前使用率超过设定阈值,就会立即达到最大频率运行,等执行完毕就立即回到最低频率。好处是调频速度快,但问题是调的不够精确。
Conservative:类似Ondemand,不过频率调节的会平滑一下,不会有忽然调整为最大值又忽然调整为最小值的现象。区别在于:当系统CPU 负载超过一定阈值时,Conservative的目标频率会以某个步长步伐递增;当系统CPU 负载低于一定阈值时,目标频率会以某个步长步伐递减。同时也需要周期性地去计算系统负载。
Interactive:由Android提出的机制,未被linux kernel社区接纳,在AOSP的linux分支上存在了较长时间。它针对CPU密集的任务的调频策略会比较激进。因为它在每一个 CPU 上都注册了一个 idle notifier。当 CPU 退出 idle 时,去检查然后决策是否需要调整频率,非idle时仍然需要依赖timer去定时采样,才能知道系统负载信息。
schedutil:本文要讨论的重点,后续章节展开。(8)僵尸进程:进程状态Z Zombie,僵尸进程,表示进程实际上已经结束,但是父进程还没有回收它的资源;
2.内存管理优化
内存管理是Linux系统内核的另一个重要功能。合理的内存管理策略能够降低系统的内存消耗,提高系统的稳定性和性能。在优化内存管理时,我们可以考虑以下几个方面:
可参考:科普文:linux服务器性能调优之内核参数-CSDN博客
(1)调整内存分配策略:通过调整内存分配策略,可以减少内存碎片的产生,提高内存的使用效率。比如,可以使用内存池、大页(HugePage)等。尽量使用缓存和缓冲区来。
(2)使用内存压缩技术:内存压缩技术可以将内存中的数据进行压缩,从而释放更多的内存空间。这对于内存资源紧张的系统来说尤为重要。
(3)优化Swap空间:最好禁止 Swap。如果必须开启 Swap,降低 swappiness 的值,减少内存回收时 Swap 的使用倾向。
(4)限制OOMKIller:通过 /proc/pid/oom_adj ,调整核心应用的 oom_score。这样,可以保证即使内存紧张,核心应用也不会被 OOM杀死。
(5)访问数据。比如,可以使用堆栈明确声明内存空间,来存储需要缓存的数据;或者用Redis 这类的外部缓存组件,优化数据的访问。
(6)使用 cgroups 等方式限制进程的内存使用情况。这样,可以确保系统内存不会被异常进程耗尽。
查看系统缓存命中情况的工具:
- cachestat 提供了整个操作系统缓存的读写命中情况。
- cachetop 提供了每个进程的缓存命中情况。
bash
cachestat 的运行界面,以 1 秒的时间间隔,输出了 3 组缓存统计数据:
$ cachestat 1 3
TOTAL MISSES HITS DIRTIES BUFFERS_MB CACHED_MB
2 0 2 1 17 279
2 0 2 1 17 279
2 0 2 1 17 279
可以看到,cachestat 的输出其实是一个表格。每行代表一组数据,而每一列代表不同的缓存统计指标。这些指标从左到右依次表示:
TOTAL ,表示总的 I/O 次数;
MISSES ,表示缓存未命中的次数;
HITS ,表示缓存命中的次数;
DIRTIES, 表示新增到缓存中的脏页数;
BUFFERS_MB 表示 Buwers 的大小,以 MB 为单位;
CACHED_MB 表示 Cache 的大小,以 MB 为单位。
cachetop 的运行界面:
$ cachetop
11:58:50 Buffers MB: 258 / Cached MB: 347 / Sort: HITS / Order: ascending
PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT%
13029 root python 1 0 0 100.0% 0.0%
它的输出跟 top 类似,默认按照缓存的命中次数(HITS)排序,展示了每个进程的缓存命中情况。具体到每一个指标,这里的 HITS、MISSES 和 DIRTIES ,跟 cachestat 里的含义一样,分别代表间隔时间内的缓存命中次数、未命中次数以及新增到缓存中的脏页数。
而 READ_HIT 和 WRITE_HIT ,分别表示 读 和 写 的缓存命中率。3.文件系统优化
文件系统是Linux系统中用于存储和管理数据的重要组件。优化文件系统可以提高数据的读写速度和系统的整体性能。
可参考:科普文:linux I/O原理、监控、和调优思路-CSDN博客
在优化文件系统时,我们可以考虑以下几个方面:
(1)选择合适的文件系统类型:Linux系统支持多种文件系统类型,如Ext4、XFS、Btrfs等。根据实际应用场景选择合适的文件系统类型,可以充分发挥系统的性能优势。
bash
文件系统为 XFS,Ext4 依然是可以使用的文件系统方案。
XFS:支持1PB的文件系统,单个文件大小限制为8EB。
Ext4:支持50TB的文件系统,单个文件大小限制为16TB。
XFS 适用场景:
没有特定业务场景
大型服务器
大存储设备
大文件
多线程 I/O
ext4 适用场景:
小文件
单线程 I/O
受限制的 I/O 能力(under 1000 IOPS)
受限制的带宽(under 200MB/s)
绑定 CPU 的业务
支持离线缩减(2)调整文件系统挂载选项:通过调整文件系统挂载选项,可以优化数据的读写性能和系统的稳定性。例如,可以启用写缓存、调整I/O调度算法等。
bash
文件系统挂载属性
通用挂载属性:
atime:授权内核更新文件访问时间
relatime:如果文件或目录被修改,则更新文件的访问时间,否则,系统每天更新一次访问时间,而不是实时更新,默认该选项在XFS和ext4文件系统上是启用的。
noatime:不更新文件访问时间
nodiratime:不更新目录的访问时间
XFS 挂载选项
默认RHEL中已经预定义了一些挂载参数,但是还有一些参数需要根据具体的应用场景决定是否开启。
inode64: 将inodes放在离数据近的地方,以减少磁盘寻道时间。
logbsize=32K:log buffer size,默认值为32KB,可以修改为64K,128K,256K,logbsize=64K
ext4 挂载选项:
i_version:开启64位inode支持功能,对于扩展元数据属性很有用,默认该属性是禁用的。
journal_ioprio=: 定义journal(日志) I/O的优先级,范围0-7,0的优先级最高(3)使用SSD硬盘:SSD硬盘具有读写速度快、耐久性高等优点,使用SSD硬盘可以显著提高文件系统的性能。
(4)文件系统内核参数调优:对于磁盘I/O,Linux提供了cfq, deadline和noop三种调度策略;
虚拟机上的磁盘服务器:建议采用比较简单的noop,毕竟数据实际上怎么落盘取决于虚拟化那一层。
数据库服务器:这类数据存储系统不要使用cfq(时序数据库可能会有所不同。不过也有说从来没见过deadline比cfq差的情况)
bash
cat /sys/block/sda/queue/scheduler
echo deadline > /sys/block/sda/queue/scheduler
# cat /sys/block/sda/queue/scheduler
[noop] deadline cfq
(方括号里面的是当前选定的调度策略)
对于磁盘I/O,Linux提供了cfq, deadline和noop三种调度策略
cfq: 这个名字是Complete Fairness Queueing的缩写,它是一个复杂的调度策略,
按进程创建多个队列,试图保持对多个进程的公平(这就没考虑读操作和写操作的不同耗时)
deadline: 这个策略比较简单,只分了读和写两个队列
(这显然会加速读取量比较大的系统),叫这个名字是内核为每个I/O操作都给出了一个超时时间
noop: 这个策略最简单,只有单个队列,只有一些简单合并操作(5)管理文件系统日志,同时将数据和日志分离:有日志的文件系统,可以加速数据恢复的效率。任何时候文件系统发生数据变化时,就会记录日志,当完成I/O操作后,再将日志记录删除。
因此,当计算机突然断电,需要进行数据恢复时,我们仅需要检查日志(必要时可以使用日志对数据进行恢复)和受日志影响的那部分文件系统,而不需要检查整个文件系统。
bash
XFS文件系统提供了一个norecovery 挂载选项,当使用此选项挂载文件系统时,日志会被禁用,挂载XFS文件系统时禁用自动恢复(recovery)过程。如果文件系统的数据不干净(not cleanly),会出现数据一致性问题,有些文件或目录可能无法访问。使用norecovery选项挂载文件系统仅可以以只读方式挂载。
mount -o norecovery,ro /dev/<device> <mountpoint>
1
Ext3/Ext4文件系统的日志,可以分为三种工作模式,可以在mount挂载时,使用data=模式选项进行定义。文件在ext4文件系统中分两部分存储:metadata和data,metadata和data的日志是分开管理的。
默认模式为 ordered
ordered:在这种模式下,只记录元数据的日志,而不记录数据的日志。当进行文件系统操作时,文件系统会先将需要修改的数据写入磁盘,然后再写入相应的元数据的日志。这样可以确保在写入元数据的日志之前,对应的数据已经持久化到磁盘上。这种模式提供了较好的数据一致性和良好的性能。
writeback:在这种模式下,只记录元数据的日志,而不记录数据的日志。与ordered模式不同,文件系统在进行文件系统操作时,会先将修改的数据写入内存缓存(而不是直接写入磁盘),然后再写入相应的元数据的日志。这种模式具有较高的性能,因为数据写入到内存缓存速度更快,但它也带来了较低的数据一致性,因为数据可能尚未刷新到磁盘上。
journal:在这种模式下,会提供完整的数据和元数据的日志记录。所有新的数据首先会被写入日志,然后再写入其最终位置。这种模式下的数据一致性最好,因为在发生崩溃或系统故障时,可以回放日志以恢复数据和元数据的一致性。然而,相对于前两种模式,journal模式的性能较差,因为每个写操作都需要先写入日志。
日志和数据分离
默认XFS和ext4文件系统被创建时,日志会被放置在与文件系统相关的设备上,当出现大量随机写操作时,磁盘的IO压力比较大,我们可以通过将日志与数据分离的方式,来降低磁盘的IO压力,提高数据读写性能。
格式化挂载时分离
创建XFS文件系统时,可以使用logdev选项指定日志设备:
使用-l(小写L)指定日志选项,通过logdev设置日志磁盘为sdd1, sdc1为主文件系统磁盘
mkfs -t xfs -l logdev=/dev/sdd1 /dev/sdc1
1
在mount挂载时,也必须指定日志磁盘的位置:
mount -o logdev=/dev/sdd1 /dev/sdc1 /mnt
1
Ext4文件系统指定独立日志磁盘的方式:
和XFS不一样,ext4文件系统不能在mount挂载的时候指定独立的日志设备
创建日志磁盘,block size为4KiB
mkfs -t ext4 -O journal_dev -b 4096 /dev/sdd1
1
创建主文件系统sdc1,并指定日志设备为sdd1
mkfs -t ext4 -J device=/dev/sdd1 -b 4096 /dev/sdc1
1
注意:
ext4扩展日志文件系统要求,日志文件系统的 block 大小必须与主文件系统的block大小一致!最佳实践是推荐在做主文件系统时同时创建日志文件系统。
已存在日志的ext4系统做日志数据分离
假设sdc1是4G数据盘,sdd1是128M日志设备
将一个已经存在的ext4系统中的日志转换为独立的日志设备,首先需要查看现有文件系统的block大小:
tune2fs 是一个用于调整和修改 Ext2、Ext3 和 Ext4 文件系统参数的命令行工具。通过使用 tune2fs,您可以更改文件系统的各种属性和选项,以满足特定的需求。
┌──[root@liruilongs.github.io]-[/var/lib/libvirt/images]
└─$tune2fs -l /dev/sdc1
Block size: 4096
1
2
3
创建相同大小的日志文件系统,在 /dev/sdd1 上创建一个 Ext4 文件系统,并启用日志功能
[root@serverX ~]# mkfs -t ext4 -O journal_dev /dev/sdd1
1
卸载文件系统:这将卸载 /dev/sdc1 文件系统,以便进行后续的文件系统调整。
[root@serverX ~]# umount /dev/sdc1
1
修改文件系统特性:从 /dev/sdc1 文件系统中移除现有的日志特性,以便为其添加新的日志设备。
[root@serverX ~]# tune2fs -O '^has_journal' /dev/sdc1
1
添加日志设备:为 /dev/sdc1 文件系统添加一个日志设备,并使用 /dev/sdd1 作为日志设备。
[root@serverX ~]# tune2fs -j -J device=/dev/sdd1 /dev/sdc1
#-j 添加日志设备,-J 指定日志设备的参数4.网络性能优化
网络性能是Linux系统的重要指标之一。优化网络性能可以提高系统的吞吐量和响应速度,从而满足日益增长的业务需求。
内核调整可参考:科普文:linux服务器性能调优之内核参数-CSDN博客
在优化网络性能时,我们可以考虑以下几个方面:
(1)调整TCP/IP参数:TCP/IP协议栈是Linux系统网络性能的关键因素。通过调整TCP/IP参数,可以优化网络的传输效率和稳定性。例如,可以调整TCP窗口大小、拥塞控制算法等。
(2)使用网络压缩技术:网络压缩技术可以将网络中的数据进行压缩,从而减少网络带宽的占用。这对于带宽资源紧张的系统来说尤为重要。
(3)优化网络硬件:选择高性能的网络硬件可以提高系统的网络性能。例如,可以使用千兆网卡、万兆网卡等高性能网络设备。
5.性能调优工具说明
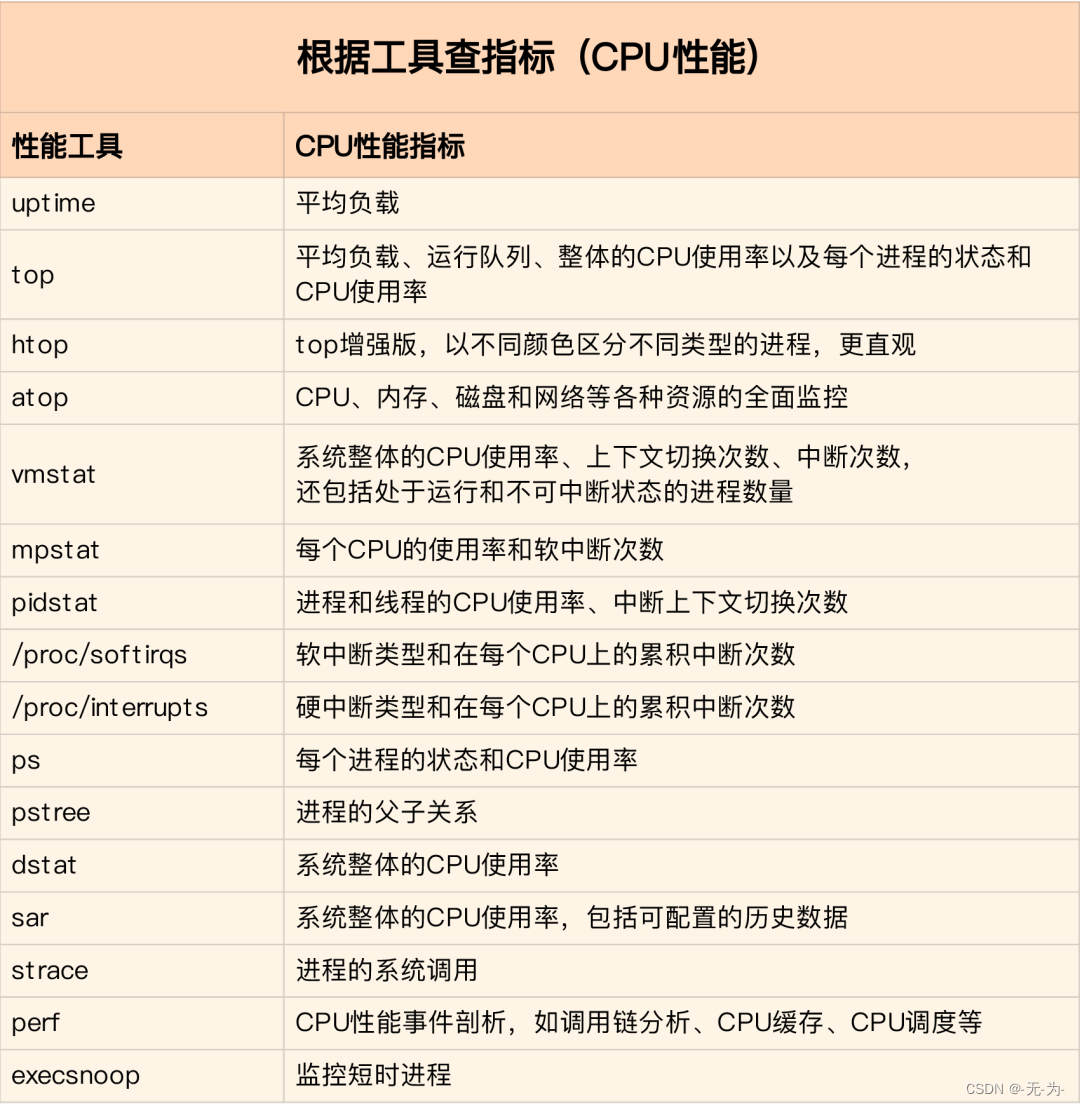
先运行几个支持指标较多的工具, 如top/vmstat/pidstat,根据它们的输出可以得出是哪种类型的性能问题. 定位到进程后再用strace/perf分析调用情况进一步分析. 如果是软中断导致用/proc/softirqs
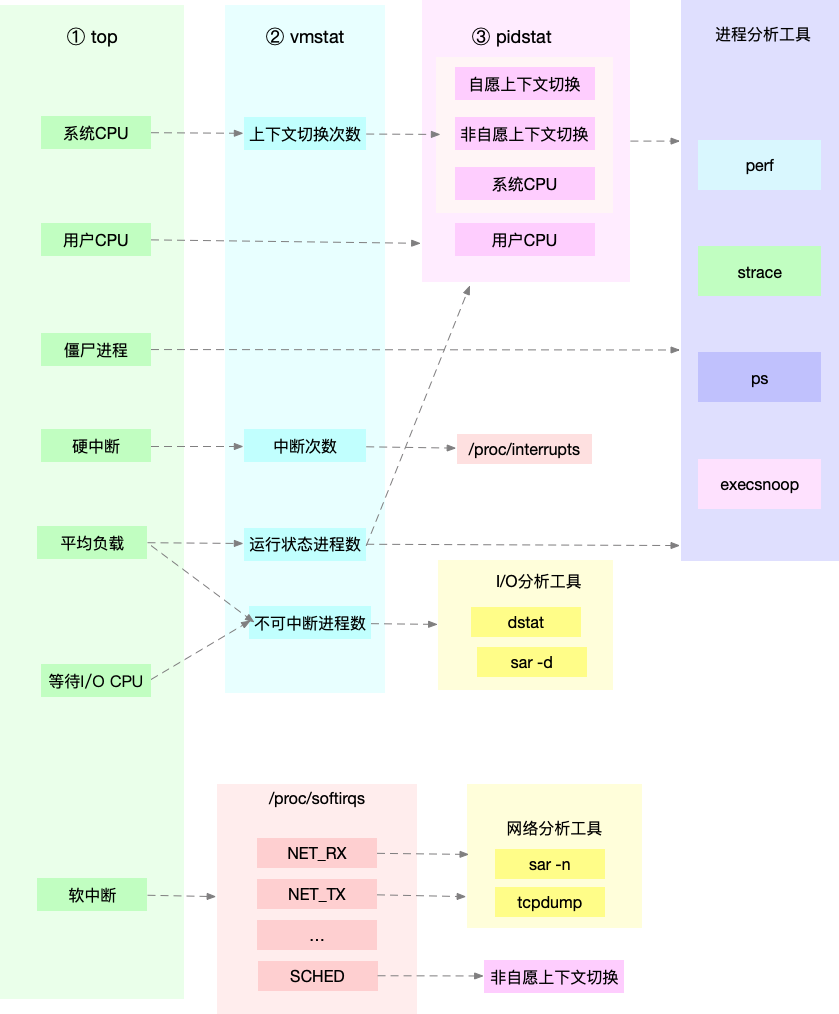
根据不同的性能指标来找合适的工具:

在生产环境中往往开发者没有权限安装新的工具包,只能最大化利用好系统中已经安装好的工具. 因此要了解一些主流工具能够提供哪些指标分析.